Command Palette
Search for a command to run...
REDSearcher : un cadre évolutif et économique pour les agents de recherche à horizon long
REDSearcher : un cadre évolutif et économique pour les agents de recherche à horizon long
Résumé
Les grands modèles linguistiques évoluent progressivement d’outils généraux de traitement des connaissances vers des solveurs de problèmes concrets dans le monde réel, mais leur optimisation pour des tâches de recherche approfondie demeure un défi. Le principal goulot d’étranglement réside dans la très faible densité des trajectoires de recherche de haute qualité ainsi que des signaux de récompense, conséquence de la difficulté à construire de manière évolutive des tâches à horizon long, ainsi que du coût élevé des simulations intensives impliquant des appels d’outils externes. Pour relever ces défis, nous proposons REDSearcher, un cadre unifié qui conçoit conjointement la synthèse de tâches complexes, l’entraînement intermédiaire et l’entraînement postérieur afin d’optimiser de manière évolutive les agents de recherche. Plus précisément, REDSearcher introduit les améliorations suivantes : (1) Nous formulons la synthèse de tâches comme une optimisation sous contraintes duals, où la difficulté de la tâche est précisément contrôlée par la topologie du graphe et la dispersion des preuves, permettant ainsi la génération évolutive de tâches complexes et de haute qualité. (2) Nous introduisons des requêtes enrichies par des outils afin d’encourager une utilisation proactive des outils, plutôt que simplement une récupération passive d’informations. (3) Lors de l’entraînement intermédiaire, nous renforçons de manière significative les capacités fondamentales de l’agent — connaissance, planification et appel de fonctions — réduisant ainsi considérablement le coût lié à la collecte de trajectoires de haute qualité pour l’entraînement ultérieur. (4) Nous avons mis en place un environnement simulé local permettant des itérations algorithmiques rapides et à faible coût pour les expériences d’apprentissage par renforcement. Sur des benchmarks de recherche d’agents, tant à base de texte que multimodaux, notre approche atteint des performances de pointe. Afin de faciliter les recherches futures sur les agents de recherche à horizon long, nous mettrons à disposition 10 000 trajectoires complexes de recherche textuelle de haute qualité, 5 000 trajectoires multimodales, ainsi qu’un ensemble de 1 000 requêtes RL textuelles, accompagnés du code source et des points de contrôle des modèles.
One-sentence Summary
The REDSearcher team proposes a unified framework for optimizing search agents by co-designing task synthesis, mid-training, and post-training, using graph-constrained task generation and tool-augmented queries to reduce reliance on costly real-world rollouts, achieving SOTA across text and multimodal benchmarks while releasing 16K trajectories and code.
Key Contributions
- REDSearcher addresses the scarcity of high-quality search trajectories by synthesizing complex tasks via dual constraints—graph treewidth for logical complexity and evidence dispersion—enabling scalable generation of long-horizon reasoning problems that demand iterative planning and cross-document synthesis.
- It introduces tool-augmented queries and mid-training reinforcement of core capabilities (knowledge, planning, function calling) to promote proactive tool use and reduce the cost of collecting high-quality trajectories, while a local simulated environment enables rapid, low-cost RL experimentation.
- Evaluated on text-only and multimodal benchmarks, REDSearcher achieves state-of-the-art performance and releases 10K text, 5K multimodal search trajectories, and 1K RL queries to support future research on deep search agents.
Introduction
The authors leverage large language models to tackle long-horizon search tasks—where agents must plan, retrieve, and synthesize information across multiple steps and sources—but note that prior work struggles with sparse high-quality training data and prohibitive costs from live tool interactions. Existing datasets often lack structural complexity and rely on simplistic, linear reasoning, while real-world search demands handling cyclic or fully coupled constraints that require maintaining entangled hypotheses. REDSearcher addresses this by co-designing task synthesis, mid-training, and reinforcement learning: it generates complex tasks using treewidth-guided graph topology and evidence dispersion, injects tool-augmented queries to promote proactive tool use, strengthens core subskills early to reduce rollout costs, and deploys a simulated environment for rapid RL iteration. The result is a scalable, cost-efficient framework that achieves state-of-the-art performance on both text and multimodal search benchmarks, backed by public releases of 16K high-quality trajectories and training artifacts.
Dataset
-
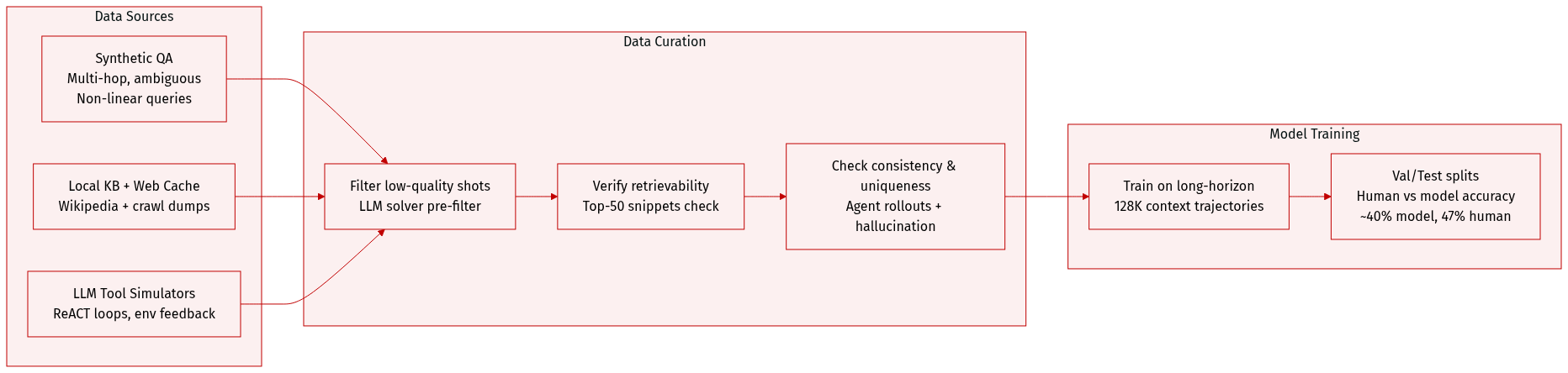
The authors construct a synthetic dataset to train deep search agents capable of handling multi-hop, ambiguous, and non-linear queries—tasks that demand iterative tool use and evidence synthesis, which existing open-source datasets lack.
-
The dataset is generated via a scalable, controllable synthesis pipeline that combines signals from local knowledge bases and cached webpages, intentionally increasing difficulty through fuzzing and complex constraints.
-
To ensure quality and challenge, the authors apply a five-stage verifier pipeline:
- LLM solver pre-filter: removes instances solvable without tools.
- Retrievability check: filters out questions whose answers don’t appear in top-50 search snippets.
- Hallucination/inconsistency check: uses an LLM verifier to detect contradictions between evidence and question-answer pairs.
- Agent rollout verification: runs strong tool-using agents across multiple rollouts; keeps instances where at least one rollout succeeds and records pass rate as confidence.
- Answer uniqueness check: discards instances with plausible alternative answers to reduce ambiguity.
-
A quality study confirms 85%+ of 500 human-verified instances are logically consistent and grounded; a strong model (DeepSeek-V3.2) achieves ~40% accuracy, while humans solve 47% within 30 minutes—validating the dataset’s realistic difficulty.
-
For training, the authors generate multi-turn tool-calling data simulating ReACT loops using LLMs to create tool sets, queries, and environmental feedback—avoiding costly real API calls.
-
Long-horizon interaction trajectories (up to 128K context) are synthesized using a local simulated web environment built from Wikipedia and web crawl dumps, ensuring solvability and enabling training on complex, multi-step search tasks.
-
The dataset includes highly intricate, real-world-inspired questions requiring cross-domain reasoning, such as identifying record pressing plants, healthcare facilities, racing events, and historical sites—all grounded in synthesized but plausible evidence.
-
No cropping is applied; metadata is constructed implicitly through the synthesis pipeline, embedding grounding signals (e.g., KB triples, cached passages) and confidence metrics (e.g., agent pass rates) for each instance.
Method
The authors leverage a structured, multi-phase training framework to develop REDSearcher, a tool-augmented agent capable of deep, long-horizon search across text and multimodal domains. The architecture is built upon a scalable task synthesis pipeline, a two-stage mid-training regimen, and a post-training phase that combines supervised fine-tuning with reinforcement learning. Each component is designed to address the sparsity of supervision and the computational cost of real-world interaction.
The core of the method begins with the scalable task synthesis pipeline, which generates complex, verifiable QA pairs by constructing reasoning graphs with controlled structural and distributional complexity. As shown in the figure below, the pipeline initiates with a seed entity set drawn from Wikipedia, from which a directed acyclic graph (DAG) is built using both structured Wikidata relations and web-based hyperlink traversal. This graph is then enriched by an LLM-driven agent to introduce cycles and interlocking constraints, increasing the treewidth and forcing the solver to maintain multiple hypotheses. Subgraph sampling extracts multiple reasoning contexts from each master graph, and an LLM generates natural-language questions anchored to these topologies. A critical innovation is the tool-enforced query evolution: static entities are replaced with operational constraints (e.g., routing queries or citation-based lookups) that require external tool invocation, ensuring that successful completion is contingent on tool use.
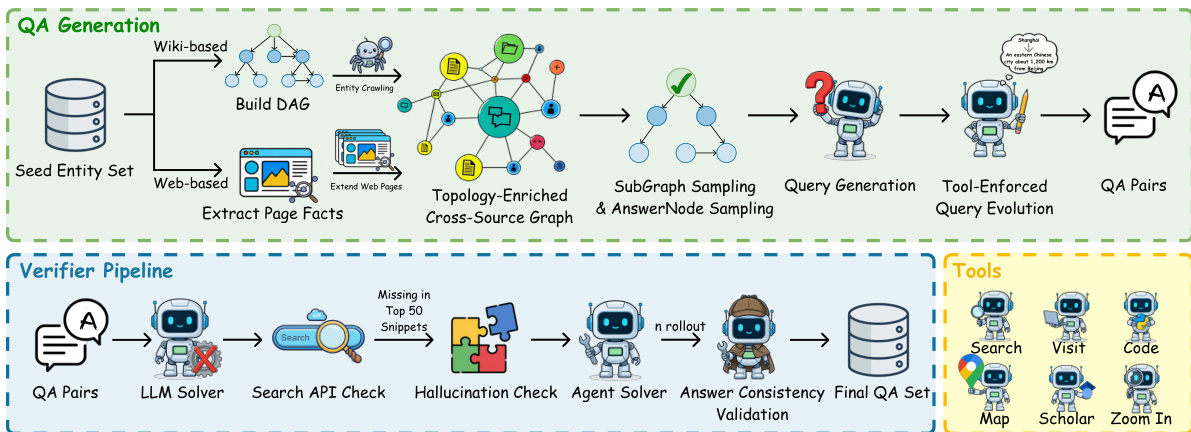
To ensure quality and difficulty, a verifier pipeline filters out solvable instances. The LLM solver checks for hallucinations and API retrievability, while an agent solver performs n-rollouts to validate answer consistency. Only QA pairs that survive this multi-stage filtering are retained for training. For multimodal tasks, the pipeline injects visual constraints by anchoring intermediate nodes to images and enforcing cross-modal dependencies, ensuring that visual understanding is necessary for task completion.
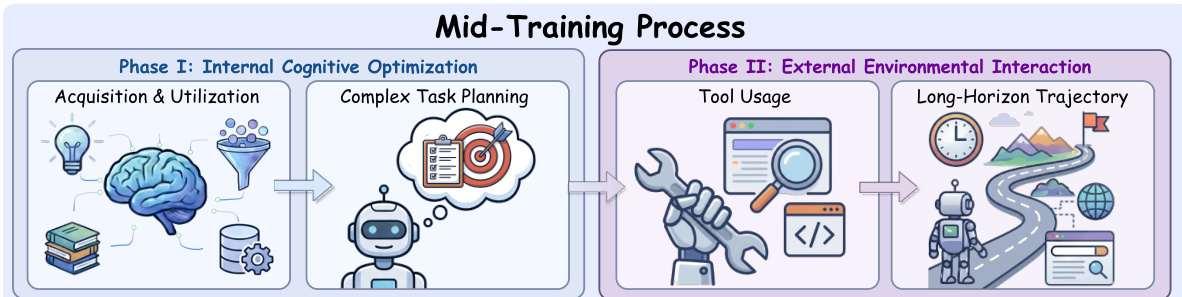
The training process is divided into two major phases: mid-training and post-training. As illustrated in the framework diagram, the model begins from an open-source LLM checkpoint and progresses through atomic capability acquisition (Stage 1, 32K context) and composite capability development (Stage 2, 128K context) during mid-training. This is followed by agentic supervised fine-tuning (SFT) and reinforcement learning (RL) in the post-training phase.

Mid-training is further decomposed into two phases. Phase I focuses on internal cognitive optimization: intent-anchored grounding, which teaches the model to extract relevant facts from noisy web pages under specific query intents, and hierarchical planning, which enables decomposition of ambiguous goals into concrete subtasks. Phase II introduces external environmental interaction, where the model learns to execute tool calls and maintain state across long-horizon trajectories. This staged approach allows the model to warm-start with foundational skills before engaging in costly real-world rollouts.
In post-training, the model undergoes supervised fine-tuning on high-quality ReAct-style trajectories generated in real-world environments using five tool interfaces: search, visit, Python interpreter, Google Scholar, and Google Maps. The SFT objective masks environment observations to prevent gradient contamination. Subsequently, agentic reinforcement learning is applied using GRPO with verifiable rewards. The reward is binary (0/1) based on answer correctness, and advantages are normalized within groups of rollouts per question to stabilize training. To accelerate experimentation, a functionally equivalent simulation environment is used during RL, which mimics real APIs while ensuring evidence completeness and injecting realistic noise. The simulation environment is built from cached web data and includes URL obfuscation to prevent model bias. Asynchronous rollouts and a two-tier load balancing strategy are employed to handle the computational demands of long trajectories.
The entire framework is designed to scale efficiently: task synthesis reuses graphs to amortize LLM costs, mid-training avoids real-world interaction until necessary, and RL leverages a curated, agent-verified query set to ensure clean learning signals. The result is a deep-search agent that can iteratively acquire evidence, maintain hypotheses, and synthesize information across multiple sources and modalities.
Experiment
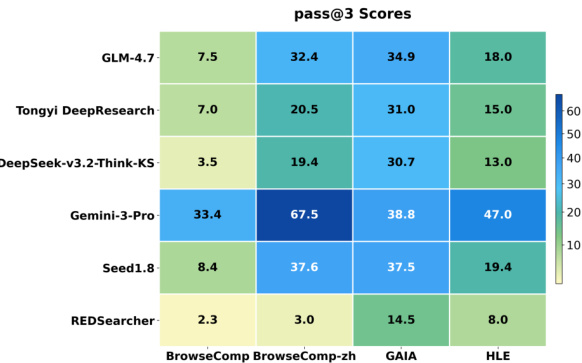
- REDSearcher sets a new state-of-the-art among open-source 30B-parameter agents, outperforming both open and proprietary models on complex benchmarks like GAIA, demonstrating superior parameter efficiency and deep research capability.
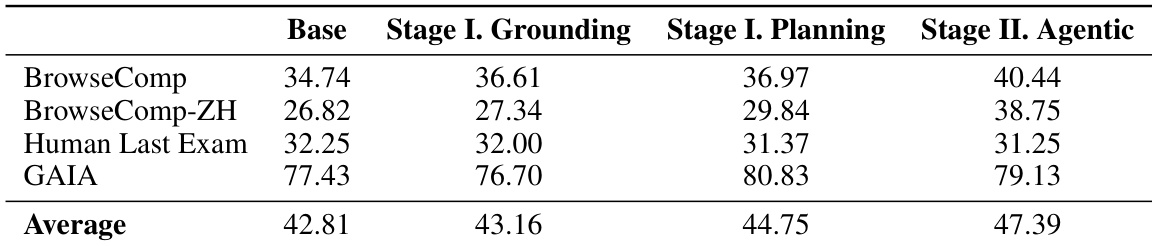
- Mid-training stages progressively enhance performance: Stage I improves grounding and planning, especially on GAIA; Stage II enables robust tool use and long-horizon execution, significantly boosting performance on BrowseComp-ZH.
- Reinforcement learning further refines capabilities, improving overall scores and reducing tool usage by 10.4% without sacrificing accuracy, indicating more efficient and strategic search behavior.
- Tool-use analysis reveals REDSearcher relies minimally on parametric knowledge, excelling only when tools are enabled—highlighting strong planning, evidence synthesis, and iterative reasoning over memorization.
- Multimodal experiments show strong performance across vision-language benchmarks, outperforming large proprietary models and a Qwen3-VL baseline, with capabilities transferring well to text-only tasks.
- Analysis of tool usage patterns shows adaptive behavior: simpler tasks require fewer turns, while complex ones involve more decomposition, reflection, and verification; RL training reduces unnecessary search steps, especially on easier benchmarks.
The authors use a staged mid-training approach to progressively enhance the model’s agentic capabilities, with each stage building upon the last to improve performance across multiple benchmarks. Results show consistent gains in average scores as the model advances through grounding, planning, and agentic interaction phases, particularly on complex tasks like GAIA and BrowseComp-ZH. This structured training strategy effectively bridges the gap between understanding and action, enabling more robust and goal-consistent behavior in deep search scenarios.
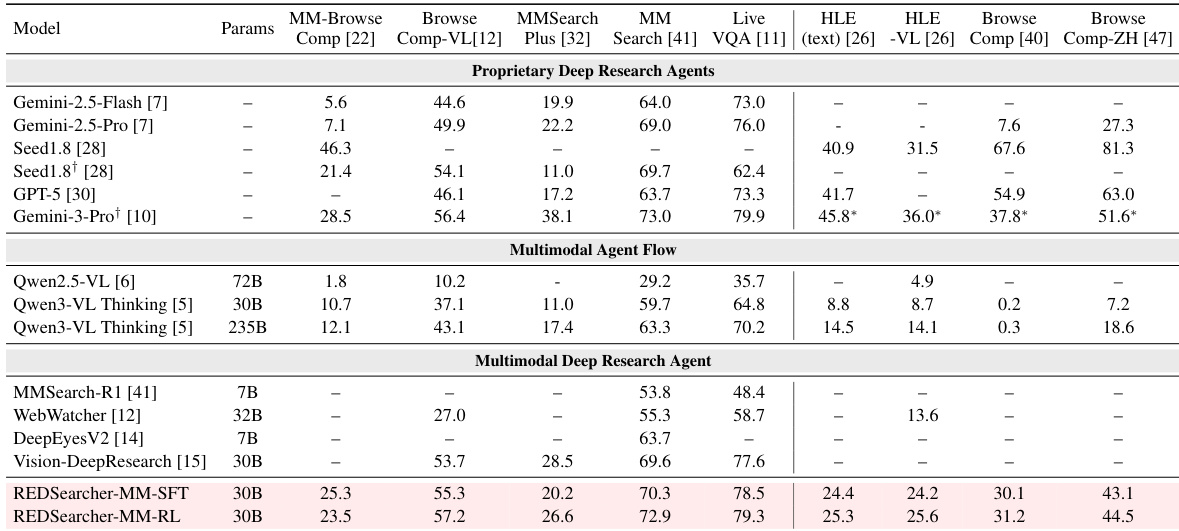
The authors evaluate their multimodal search agent, REDSearcher-MM, across diverse benchmarks and find it outperforms both proprietary and open-source baselines, particularly on complex tasks requiring visual grounding and long-horizon reasoning. Results show consistent gains after reinforcement learning, with improved efficiency in tool usage and stronger performance on challenging multimodal benchmarks like MM-BrowseComp and LiveVQA. The model also demonstrates robust transferability, maintaining strong results on text-only tasks despite being optimized for multimodal inputs.
The authors use a 30B-parameter model with context management to achieve state-of-the-art performance among open-source agents, outperforming larger proprietary models on key benchmarks including GAIA. Results show that their approach delivers superior deep research capabilities through efficient tool use and multimodal reasoning, even when compared to significantly larger baselines. Reinforcement learning further enhances performance by refining search efficiency and reducing redundant tool calls without sacrificing accuracy.
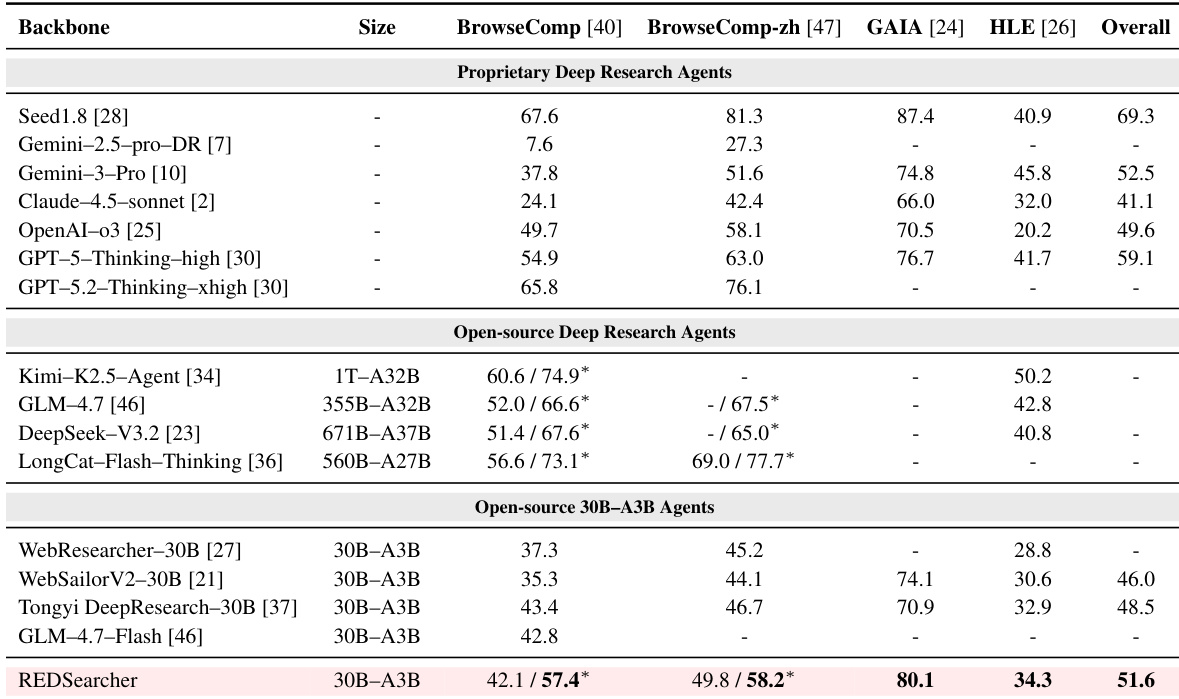
The authors use a 30B-parameter model with context management to achieve state-of-the-art performance among open-source agents, outperforming larger proprietary models on complex reasoning benchmarks like GAIA. Results show that progressive mid-training stages and reinforcement learning significantly improve long-horizon search efficiency, reducing tool calls while maintaining or increasing accuracy. The model also demonstrates strong multimodal search capabilities, effectively integrating visual and textual evidence across diverse benchmarks.
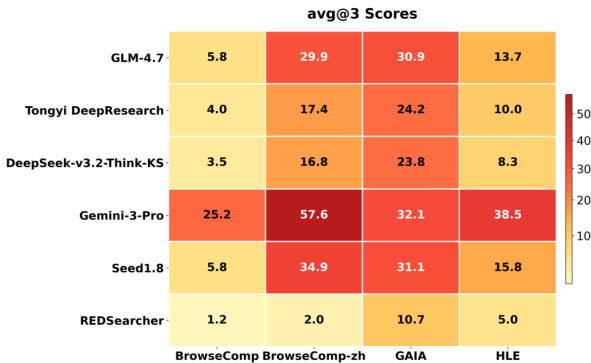
The authors use REDSearcher to evaluate performance across multiple challenging benchmarks, including BrowseComp, GAIA, and HLE, comparing it against both open-source and proprietary models. Results show that REDSearcher achieves competitive or superior scores relative to larger proprietary systems, particularly excelling on GAIA, which tests complex agentic reasoning. The model’s strong performance is attributed to its architecture and training methodology, including context management and reinforcement learning, which enhance efficiency and long-horizon task execution.