Command Palette
Search for a command to run...
RLinf-Co : Co-entraînement Sim-Réel Basé sur l'Apprentissage par Renforcement pour les Modèles VLA
RLinf-Co : Co-entraînement Sim-Réel Basé sur l'Apprentissage par Renforcement pour les Modèles VLA
Liangzhi Shi Shuaihang Chen Feng Gao Yinuo Chen Kang Chen Tonghe Zhang Hongzhi Zhang Weinan Zhang Chao Yu Yu Wang
Résumé
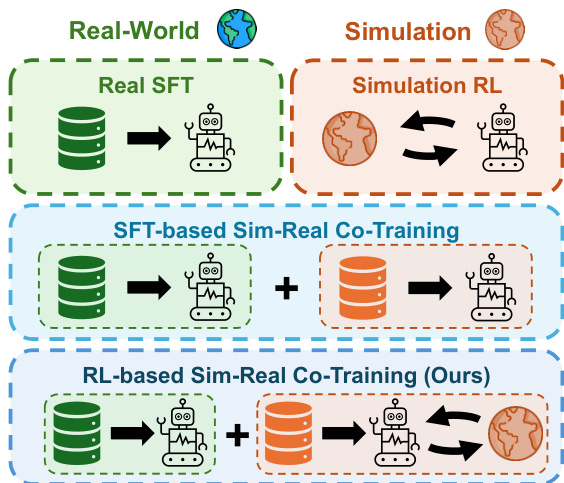
La simulation offre une méthode évolutif et à faible coût pour enrichir l’entraînement des modèles vision-langage-action (VLA), réduisant ainsi la dépendance aux démonstrations coûteuses réalisées sur robots réels. Toutefois, la plupart des méthodes existantes de co-entraînement simulation-réel reposent sur un ajustement fin supervisé (SFT), qui traite la simulation comme une source statique de démonstrations et ne tire pas parti des interactions en boucle fermée à grande échelle. En conséquence, les gains observés dans le monde réel et la généralisation restent souvent limités. Dans cet article, nous proposons un cadre de co-entraînement simulation-réel basé sur l’apprentissage par renforcement (RL-Co), qui exploite pleinement l’interaction dans la simulation tout en préservant les performances dans le monde réel. Notre méthode suit une architecture générique en deux étapes : nous initialisons d’abord la politique par SFT sur un mélange de données réelles et simulées, puis nous la raffinons par apprentissage par renforcement dans l’environnement simulé, tout en ajoutant une perte supervisée auxiliaire sur les données réelles afin d’ancrer la politique et atténuer le phénomène d’oubli catastrophique. Nous évaluons notre cadre sur quatre tâches de manipulation sur table réelles, en utilisant deux architectures VLA représentatives, OpenVLA et π_{0.5}, et observons des améliorations constantes par rapport à l’ajustement fin uniquement sur données réelles et aux méthodes de co-entraînement basées sur SFT, incluant une augmentation de +24 % du taux de succès dans le monde réel pour OpenVLA et de +20 % pour π_{0.5}. Au-delà d’un taux de succès plus élevé, le co-entraînement par RL permet une généralisation renforcée aux variations de tâches inédites et une efficacité substantiellement améliorée des données réelles, offrant ainsi une voie pratique et évolutif pour exploiter la simulation afin d’améliorer le déploiement de robots réels.
One-sentence Summary
Researchers from Tsinghua, HIT, Peking, CMU, and Shanghai AI Lab propose RL-Co, an RL-based sim-real co-training framework for VLA models like OpenVLA and π₀.₅, which uses interactive simulation with real-data regularization to boost real-world success by up to 24%, enhance generalization, and reduce real-data needs.
Key Contributions
- RLinf-Co introduces a two-stage sim-real co-training framework for VLA models that combines supervised fine-tuning on mixed real/sim data with reinforcement learning in simulation, using real-world data as an auxiliary loss to prevent catastrophic forgetting and maintain real-robot capabilities.
- The method addresses the limitation of static demonstration-based co-training by leveraging scalable closed-loop interaction in simulation, enabling more robust policy optimization while preserving generalization to real-world task variations.
- Evaluated on four real-world tabletop tasks with OpenVLA and π₀.₅, RLinf-Co achieves +24% and +20% real-world success rate gains over SFT-based co-training, while improving data efficiency and generalization to unseen scenarios.
Introduction
The authors leverage reinforcement learning to enhance vision-language-action (VLA) models through a sim-real co-training framework that actively exploits simulation’s interactive potential, unlike prior methods that treat simulation as a static source of demonstrations. While existing co-training approaches improve performance by mixing real and simulated data under supervised fine-tuning, they fail to address compounding errors and lack closed-loop policy refinement—limiting real-world generalization and data efficiency. The authors’ main contribution is RL-Co, a two-stage method that first warm-starts the policy with mixed real-sim SFT, then fine-tunes it via RL in simulation while using real-world data as an auxiliary supervised signal to prevent catastrophic forgetting. This yields consistent gains in real-world success rates, stronger generalization to novel task variations, and significantly reduced reliance on real-world demonstrations—offering a scalable, practical path for deploying VLA models on physical robots.
Dataset
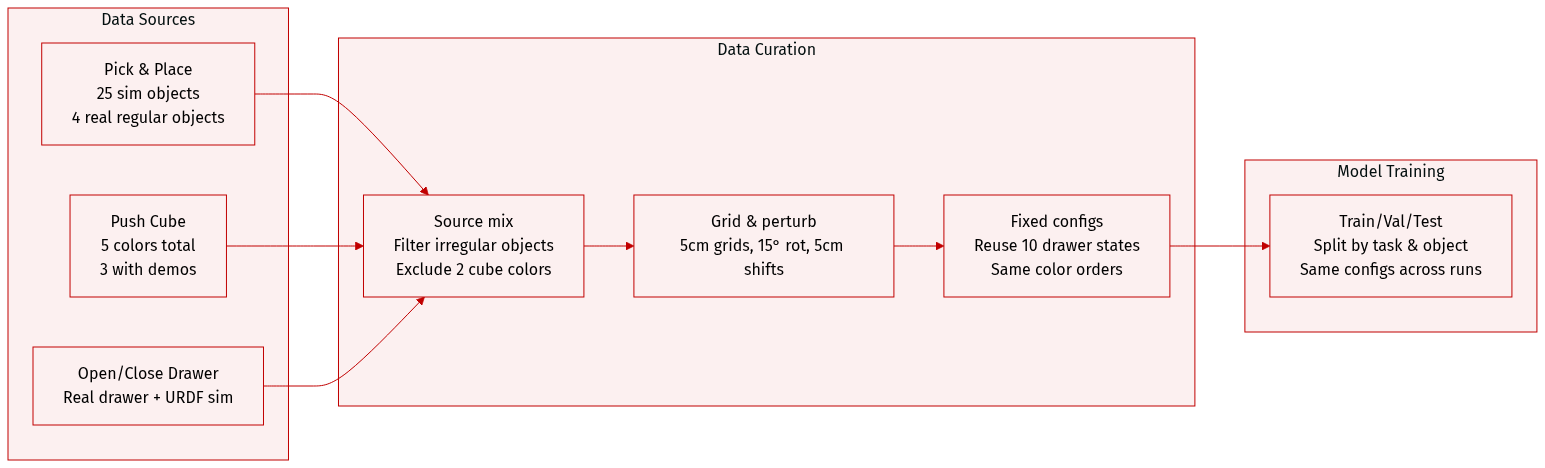
The authors use a dataset composed of four table-top manipulation tasks—Pick and Place, Push Cube, Open Drawer, and Close Drawer—evaluated in both simulation and real-world settings. Key details per subset:
-
Pick and Place:
- Simulation: 25 objects from Liu et al. [42].
- Real world: Two categories—regular-shaped (toy fruits/vegetables) and irregular-shaped (bowls, gloves). Irregular objects are excluded from expert demonstrations. For in-distribution testing, four regular-shaped objects are selected.
- Initial states: Bowl placed in 10×20 cm region; object in 20×25 cm region. Both discretized into 5 cm grids; same configurations reused across methods.
-
Push Cube:
- Simulation and real world: Five colored cubes. Expert demos collected for only three (purple, yellow, pink); orange and green excluded.
- Evaluation: Randomly selects three colors from five. Cubes spaced 15 cm apart, then perturbed within 5×5 cm region. Same color permutations and spatial configs used across experiments.
-
Open/Close Drawer:
- Real world: Physical drawer shown in Fig. 10.
- Simulation: URDF model matching real drawer geometry.
- Initial states: Drawer front edge placed in orange region (Fig. 11) with up to 15° rotational perturbation. Open drawer starts ~10 cm open. Ten predefined configurations shared across evaluations.
-
Robot Initial State:
- Default: Franka Panda initialized in fixed pose (Fig. 8).
- Generalization (Pick and Place only): Four objects with fixed object positions. TCP perturbed via ±30° rotation + 5 cm translation (forward, backward, left, right, up)—five total perturbations per object, as in Table III. Other environment settings unchanged.
The data is used for training and evaluation with fixed initial configurations to ensure fair comparison. No cropping is applied; metadata includes object types, task-specific regions, perturbations, and demonstration exclusions. All real-world objects are visually documented in Fig. 10, and initial placement regions are visualized in Fig. 11.
Method
The authors leverage a two-stage sim-real co-training framework to adapt vision-language-action (VLA) policies for robotic manipulation tasks. The method is designed to bridge the sim-to-real gap by combining supervised fine-tuning (SFT) with reinforcement learning (RL) in simulation, while preserving real-world behavioral fidelity through auxiliary supervision.
Refer to the framework diagram, which illustrates the overall architecture. The process begins with a digital-twin setup: for each real-world task Treal, a corresponding simulation task Tsim is constructed, sharing the same robot embodiment, action space, and language instruction, but differing in visual texture and dynamics. Both tasks are modeled as Partially Observable Markov Decision Processes (POMDPs), with the VLA policy πθ conditioned on a history of H observations and a language instruction l to predict a sequence of h future actions:
at:t+h−1∼πθ(at:t+h−1∣oΩt−H+1:t,l).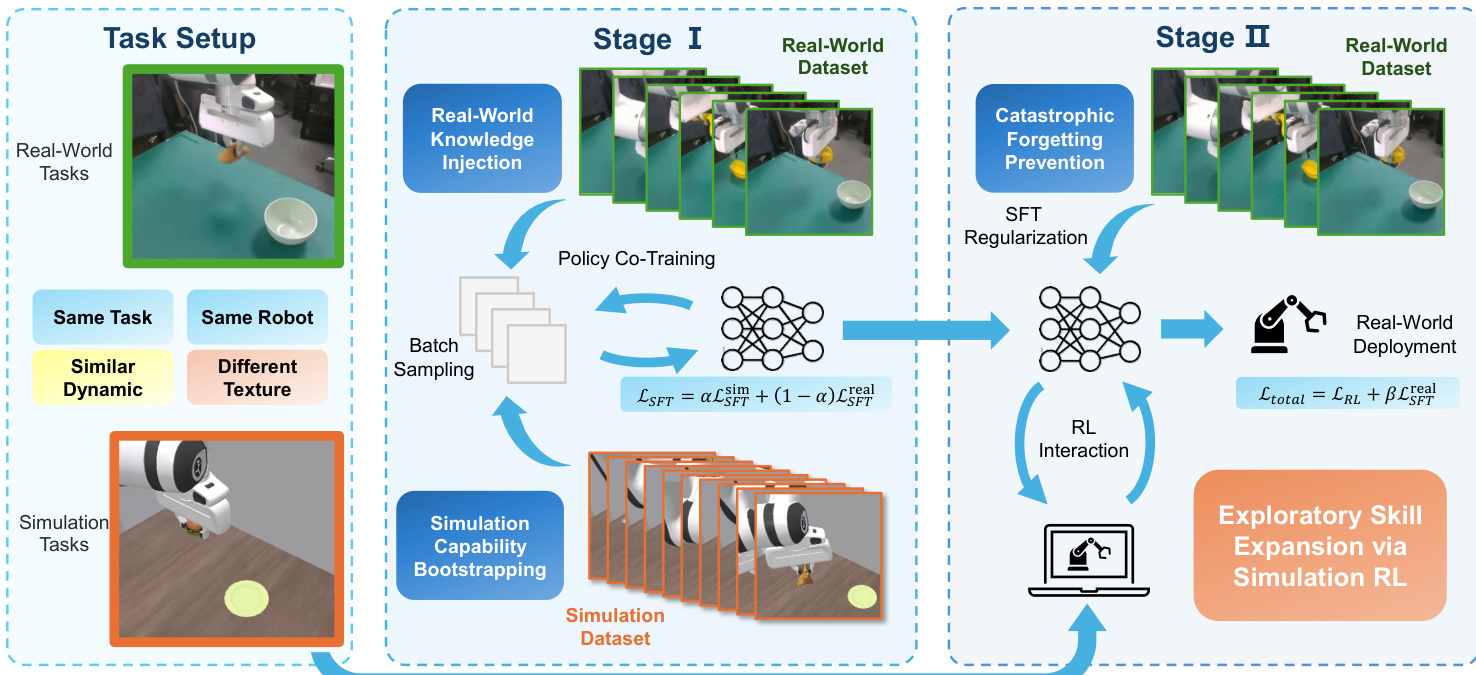
In Stage I, the authors initialize the policy via SFT-based co-training. Starting from a pre-trained VLA policy πθ, they jointly optimize it on a mixture of real-world and simulated demonstration datasets Dreal and Dsim. The loss function is a weighted combination:
LSFT(θ)=αLSFT(θ;Dsim)+(1−α)LSFT(θ;Dreal),where α∈[0,1] controls the proportion of simulated data sampled during training. This stage serves dual purposes: injecting real-world knowledge early to ensure deployability, and bootstrapping simulation competence to enable effective RL in the next stage.
Stage II introduces the core innovation: RL-based sim-real co-training with real-regularized RL. While the policy interacts with the simulation environment to maximize expected discounted return via RL, the authors augment the standard RL loss LRL with an auxiliary SFT loss computed on the real-world dataset:
Ltotal=LRL+βLSFT(θ;Dreal),where β balances exploration in simulation against preservation of real-world behavior. This regularization prevents catastrophic forgetting during RL fine-tuning, ensuring that the policy retains its real-world capabilities while expanding its skill set through simulated interaction. The framework is agnostic to the specific RL algorithm used and can be integrated with a wide range of policy update strategies.
As shown in the figure below, the entire pipeline transitions from real-world knowledge injection and simulation capability bootstrapping in Stage I, to exploratory skill expansion via simulation RL in Stage II, with real-world deployment as the final objective. The authors emphasize that this structured approach enables scalable policy improvement without sacrificing real-world performance.
Experiment
- RL-Co consistently outperforms real-world-only SFT and SFT-based sim-real co-training across diverse manipulation tasks, demonstrating stronger real-world deployment performance.
- The method significantly enhances generalization under distribution shifts, including unseen objects and states, by leveraging RL to develop more robust and transferable behaviors.
- Ablation studies confirm the necessity of both SFT initialization (with simulated data) and real-world regularization during RL fine-tuning; removing either component severely degrades performance.
- RL-Co achieves superior data efficiency, matching or exceeding baseline performance with only a fraction of real-world demonstration data—often as little as 10% of what baselines require.
- Hyperparameter analysis shows that co-training ratio and regularization weight meaningfully influence outcomes, but RL-Co consistently improves over SFT baselines regardless of tuning.
- Simulation data is critical for enabling efficient RL optimization, while real-world supervision anchors the policy and prevents catastrophic forgetting during simulation-based training.
Results show that RL-Co significantly improves generalization under distribution shifts compared to real-only training and SFT-based co-training, maintaining higher success rates when faced with unseen objects or initial states. The method demonstrates stronger robustness, with notably smaller performance drops in out-of-distribution settings, indicating that reinforcement learning enhances the policy’s ability to transfer beyond supervised training data.

The authors use RL-Co to combine simulated interaction with real-world supervision, achieving consistently higher real-world success rates across multiple manipulation tasks compared to real-only training or SFT-based co-training. Results show that RL-Co not only improves performance but also enhances generalization under unseen conditions and significantly reduces the amount of real-world data required for effective training. Ablation studies confirm that both stages of the framework—SFT initialization and real-world-regularized RL fine-tuning—are essential for stable and efficient learning.

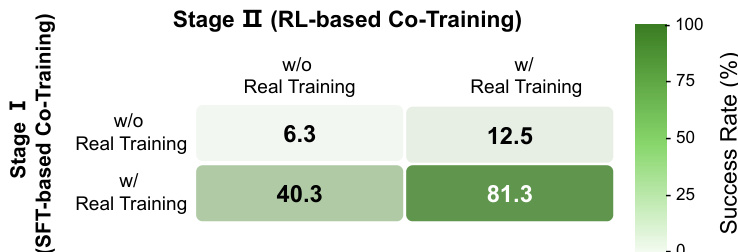
The authors use a two-stage framework combining supervised fine-tuning and reinforcement learning to improve real-world robot performance. Results show that including real-world data in both stages is critical, with the full RL-Co approach achieving an 81.3% success rate, far surpassing variants that omit real-data supervision in either stage. This highlights the necessity of real-world grounding throughout training to prevent performance collapse and enable effective sim-to-real transfer.