Command Palette
Search for a command to run...
VESPO : Optimisation Variationnelle de Politique Douce au Niveau de la Séquence pour une Formation Stable des LLM en Mode Hors-Échantillonnage
VESPO : Optimisation Variationnelle de Politique Douce au Niveau de la Séquence pour une Formation Stable des LLM en Mode Hors-Échantillonnage
Guobin Shen Chenxiao Zhao Xiang Cheng Lei Huang Xing Yu
Résumé
La stabilité de l'entraînement reste un défi central dans l'apprentissage par renforcement (RL) appliqué aux grands modèles linguistiques (LLM). La stagnation de la politique (policy staleness), l'entraînement asynchrone et les incohérences entre les moteurs d'entraînement et d'inférence entraînent toutes une divergence entre la politique d'action et la politique courante, ce qui expose le processus d'entraînement au risque d'effondrement. L'échantillonnage par importance offre une correction rigoureuse face à ce décalage de distribution, mais souffre d'une variance élevée ; les solutions existantes, telles que le clipping au niveau des jetons ou la normalisation au niveau des séquences, manquent d'une fondation théorique unifiée. Nous proposons Variational sEquence-level Soft Policy Optimization (VESPO). En intégrant une réduction de variance dans une formulation variationnelle sur les distributions de proposition, VESPO dérive un noyau de redimensionnement explicite qui agit directement sur les poids d'importance au niveau des séquences, sans nécessiter de normalisation en fonction de la longueur. Des expériences menées sur des benchmarks de raisonnement mathématique montrent que VESPO maintient un entraînement stable même avec des ratios de stagnation allant jusqu'à 64× et une exécution entièrement asynchrone, tout en apportant des gains constants aussi bien sur des modèles à densité que sur des modèles Mixture-of-Experts. Le code est disponible à l'adresse suivante : https://github.com/FloyedShen/VESPO
One-sentence Summary
Researchers from a single institution propose VESPO, a variational method that stabilizes RL training for LLMs by reducing variance in importance sampling via a closed-form sequence-level kernel, outperforming prior approaches under extreme staleness and asynchronous conditions across dense and MoE models.
Key Contributions
- VESPO introduces a variational formulation that explicitly reduces variance in off-policy RL for LLMs, deriving a closed-form reshaping kernel for sequence-level importance weights without relying on length normalization or heuristic clipping.
- The method preserves token dependencies and avoids bias from normalization, enabling stable training under extreme staleness (up to 64×) and fully asynchronous execution, with compatibility across both dense and Mixture-of-Experts architectures.
- Evaluated on mathematical reasoning benchmarks, VESPO consistently improves performance and training stability compared to existing token- and sequence-level IS baselines, offering a theoretically grounded alternative to ad hoc weight transformations.
Introduction
The authors leverage reinforcement learning to stabilize off-policy training for large language models, where policy staleness and asynchronous updates cause distribution shifts that risk training collapse. Prior methods rely on heuristic token-level clipping or sequence-level normalization to control importance sampling variance, but these introduce bias or fail to preserve sequence structure. VESPO introduces a variational framework that derives a closed-form reshaping kernel operating directly on sequence-level weights, reducing variance without length normalization or approximation. It enables stable training under extreme staleness and asynchronous conditions, delivering consistent gains across both dense and MoE architectures.
Method
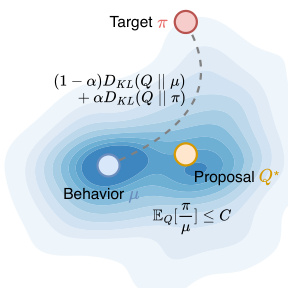
The authors leverage a variational framework to derive a principled importance weight transformation for off-policy policy gradient optimization in autoregressive language models. Their method, VESPO (Variational Sequence-Level Soft Policy Optimization), reinterprets any reshaping function φ(W) as inducing an implicit proposal distribution Q that mediates between the behavior policy μ and the target policy π, while enforcing variance constraints.
Refer to the framework diagram, which visualizes the variational objective: the proposal Q* is optimized to lie in a region that balances proximity to both μ and π, subject to a constraint on the expected importance weight under Q. The dual KL objective (1−α)DKL(Q∥μ)+αDKL(Q∥π) pulls Q toward the sampling distribution μ for efficiency and toward the target π for bias reduction. The constraint EQ[W]≤C ensures the variance of the estimator remains bounded, preventing the explosive growth typical of uncorrected sequence-level importance sampling.
The closed-form solution for the optimal proposal yields the reshaping function ϕ(W)=Wαexp(−λW), which combines a power-law scaling with exponential suppression to smoothly attenuate extreme weights. In practice, the authors adopt a shifted variant ϕ(W)=Wc1exp(c2(1−W)) to ensure ϕ(1)=1, preserving the scale of on-policy updates. This kernel is applied asymmetrically: distinct hyperparameters (c1,c2) are used for positive and negative advantages, allowing stronger suppression of low-weight samples when the advantage is negative, which helps prevent over-penalization of trajectories the policy already disfavors.
The gradient estimator is implemented in REINFORCE style, with the reshaping weight detached from the computation graph to serve purely as a scaling factor. To ensure numerical stability, all computations—including the sequence-level log-ratio logW=∑t(logπθ(yt∣x,y<t)−logμ(yt∣x,y<t)) and the log-transformed reshaping term c1logW+c2(1−W)—are performed in log-space, with exponentiation deferred until the final step. This avoids overflow from extreme importance weights while requiring no additional memory beyond storing per-token log-probabilities under both policies.
Experiment
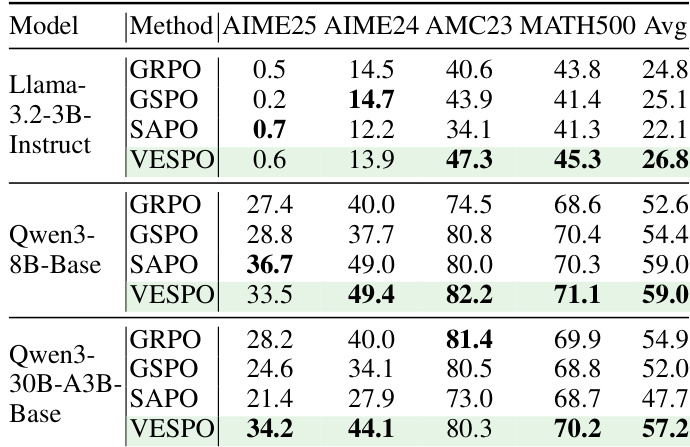
- VESPO consistently outperforms baselines across multiple model scales and mathematical reasoning benchmarks, particularly excelling on MoE models where train-inference mismatch and policy staleness are amplified.
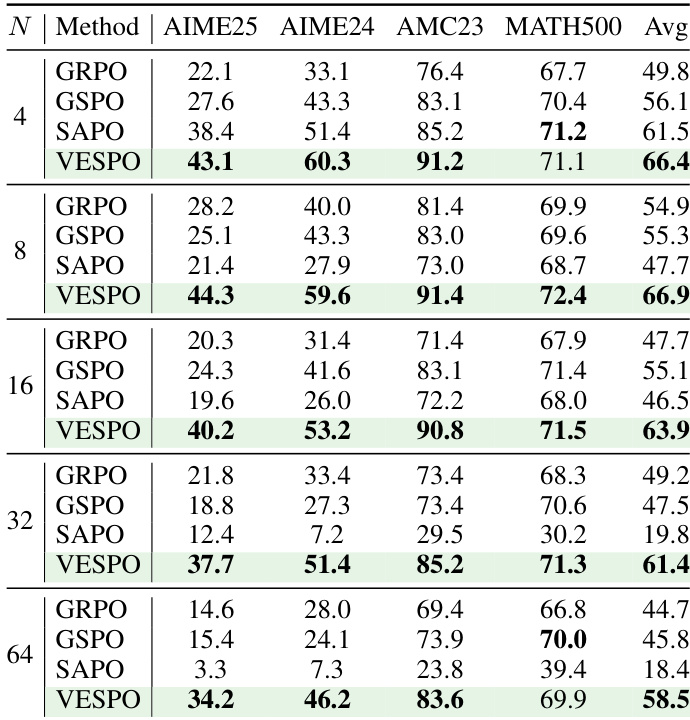
- It demonstrates exceptional robustness to policy staleness across varying degrees of off-policy updates (N=4 to 64), maintaining stable training dynamics and high accuracy where other methods degrade or collapse.
- Under fully asynchronous training, VESPO sustains stable convergence while baselines exhibit instability, reward collapse, or suboptimal performance due to stale rollouts.
- VESPO tolerates train-inference mismatch without specialized fixes, matching or exceeding the stability of methods augmented with engineering solutions like Routing Replay or Truncated Importance Sampling.
- Ablations confirm that VESPO’s sequence-level design without length normalization avoids length bias and training collapse, unlike normalized variants.
- Its asymmetric hyperparameter design for positive and negative advantages balances suppression and learning signal, proving critical for stability and performance.
The authors evaluate VESPO under varying degrees of policy staleness and find it consistently outperforms baselines across all staleness levels, maintaining stable training and strong downstream accuracy even at extreme settings like N=64. Unlike GRPO, GSPO, and SAPO—which degrade or collapse under higher staleness—VESPO’s design avoids length bias and stabilizes updates through asymmetric importance weight suppression. Results confirm VESPO’s robustness to distribution shifts from both policy staleness and train-inference mismatch, particularly benefiting MoE models where such shifts are amplified.
The authors evaluate VESPO against several baselines across multiple model scales and mathematical reasoning benchmarks, finding that VESPO consistently achieves the highest average accuracy in all settings. Results show that VESPO’s performance advantage is most pronounced in larger MoE models, where it mitigates instability caused by distribution shifts from policy staleness and train-inference mismatch. The method’s stability and effectiveness stem from its sequence-level soft suppression of extreme importance weights and asymmetric hyperparameter design, which prevent training collapse and maintain consistent learning dynamics.