Command Palette
Search for a command to run...
Quand mémoriser et quand s’arrêter : une mémoire récurrente à grille pour le raisonnement à longue portée
Quand mémoriser et quand s’arrêter : une mémoire récurrente à grille pour le raisonnement à longue portée
Leheng Sheng Yongtao Zhang Wenchang Ma Yaorui Shi Ting Huang Xiang Wang An Zhang Ke Shen Tat-Seng Chua
Résumé
Bien que le raisonnement sur des contextes longs soit essentiel pour de nombreuses applications du monde réel, il reste un défi majeur pour les grands modèles linguistiques (LLM), qui subissent une dégradation de performance avec l’augmentation de la longueur du contexte. Des travaux récents, comme MemAgent, ont tenté de relever ce défi en traitant le contexte par blocs dans une boucle de type RNN, tout en mettant à jour une mémoire textuelle destinée à la réponse finale. Toutefois, cette mise à jour récurrente naïve présente deux inconvénients critiques : (i) la mémoire peut rapidement exploser, car elle se met à jour de manière indiscriminée, même sur des blocs dépourvus de preuves ; et (ii) la boucle ne dispose pas d’un mécanisme de sortie, entraînant des calculs inutiles même après la collecte d’une quantité suffisante de preuves. Pour surmonter ces limites, nous proposons GRU-Mem, un modèle intégrant deux portes contrôlées par le texte afin d’assurer un raisonnement long-contexte plus stable et plus efficace. Plus précisément, dans GRU-Mem, la mémoire n’est mise à jour que lorsque la porte de mise à jour est ouverte, et la boucle récurrente s’arrête immédiatement dès que la porte de sortie est activée. Pour doter le modèle de ces capacités, nous introduisons deux signaux de récompense, ( r^{\text{update}} ) et ( r^{\text{exit}} ), au sein d’un cadre d’apprentissage par renforcement end-to-end, récompensant respectivement les comportements corrects de mise à jour et d’arrêt. Des expériences sur diverses tâches de raisonnement à long contexte démontrent l’efficacité et l’efficience de GRU-Mem, qui surpassent généralement MemAgent sans modification, avec une accélération de la phase d’inférence pouvant atteindre 400 %.
One-sentence Summary
Researchers from ByteDance Seed, NUS, and USTC propose GRU-Mem, a gated memory agent that stabilizes long-context reasoning in LLMs via controlled updates and early exits, outperforming MemAgent with up to 400% faster inference while reducing memory bloat and redundant computation.
Key Contributions
- GRU-Mem addresses key limitations of prior recurrent memory methods like MemAgent by introducing two text-controlled gates—an update gate that prevents memory explosion by updating only on relevant chunks, and an exit gate that halts computation once sufficient evidence is gathered.
- The model is trained end-to-end via reinforcement learning with two distinct reward signals, rupdate and rexit, which explicitly guide the agent to learn when to update memory and when to terminate the loop.
- Evaluated on long-context QA tasks, GRU-Mem outperforms vanilla MemAgent while achieving up to 400% faster inference speed, demonstrating both improved accuracy and computational efficiency.
Introduction
The authors leverage recurrent memory architectures to tackle long-context reasoning, where LLMs must locate sparse evidence across millions of tokens—a challenge known as the “needle in a haystack” problem. Prior work like MemAgent processes context chunk-by-chunk but suffers from uncontrolled memory growth and no early exit, wasting computation even after sufficient evidence is found. Their main contribution, GRU-Mem, introduces two text-controlled gates—an update gate to selectively refresh memory and an exit gate to terminate processing early—trained via end-to-end reinforcement learning with distinct reward signals for each behavior. This yields both higher accuracy and up to 400% faster inference compared to vanilla MemAgent.
Method
The authors leverage a gated recurrent memory framework, GRU-Mem, to address the instability and inefficiency inherent in vanilla recurrent long-context reasoning. The core innovation lies in augmenting the memory agent with two text-controlled binary gates — an update gate (UG) and an exit gate (EG) — which dynamically regulate memory evolution and workflow termination. This design draws inspiration from gating mechanisms in GRUs, aiming to mitigate memory explosion and enable early exit when sufficient evidence is gathered.
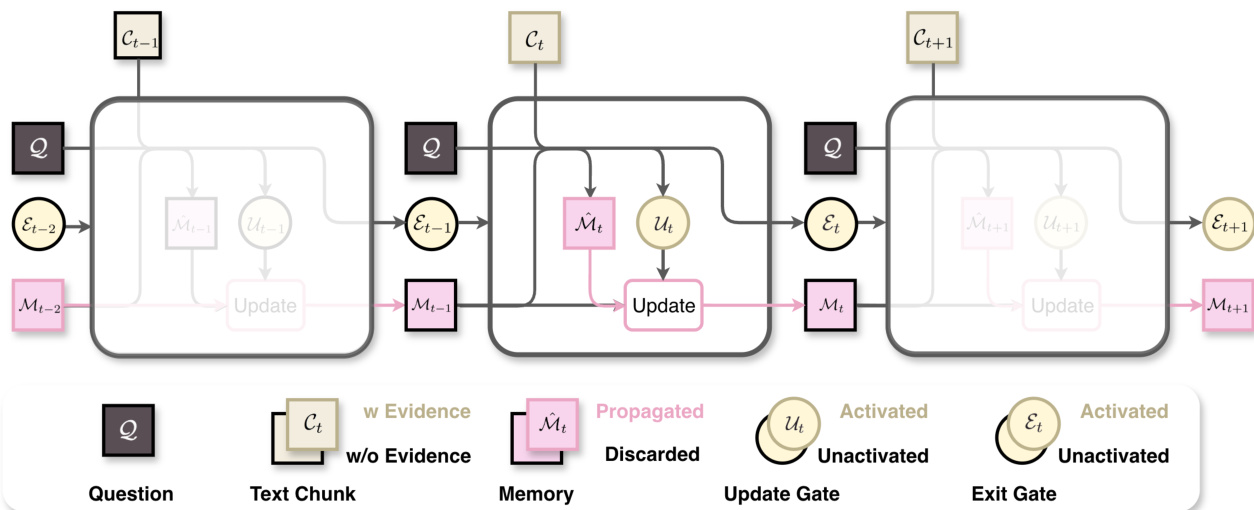
The workflow begins by splitting the long context C into T fixed-size chunks {C1,⋯,CT}. At each step t, the memory agent ϕθ, conditioned on the question Q, current chunk Ct, and previous memory Mt−1, generates three outputs: a candidate memory M^t, an update gate status Ut, and an exit gate status Et. This is formalized as:
Ut,M^t,Et=ϕθ(Q,Ct,Mt−1).The update gate determines whether to overwrite the memory: if Ut is True, Mt←M^t; otherwise, Mt←Mt−1. The exit gate controls workflow continuation: if Et is True, the loop terminates and the answer agent ψθ immediately generates the final answer A^ from Mt and Q. This selective update and conditional termination are critical for maintaining memory stability and reducing unnecessary computation.
Refer to the framework diagram, which illustrates how the update gate discards irrelevant candidate memories and how the exit gate halts processing once the last evidence is encountered, preventing memory explosion and avoiding redundant chunk processing.
To enforce this structured behavior, the memory agent is constrained to output in a predefined format. As shown in the prompt specification, the agent must first reason within tags, then emit yes or no to activate or deactivate the update gate, followed by the candidate memory within tags, and finally continue or end to control the exit gate. This structured output ensures parseability and enforces the gating logic during inference.
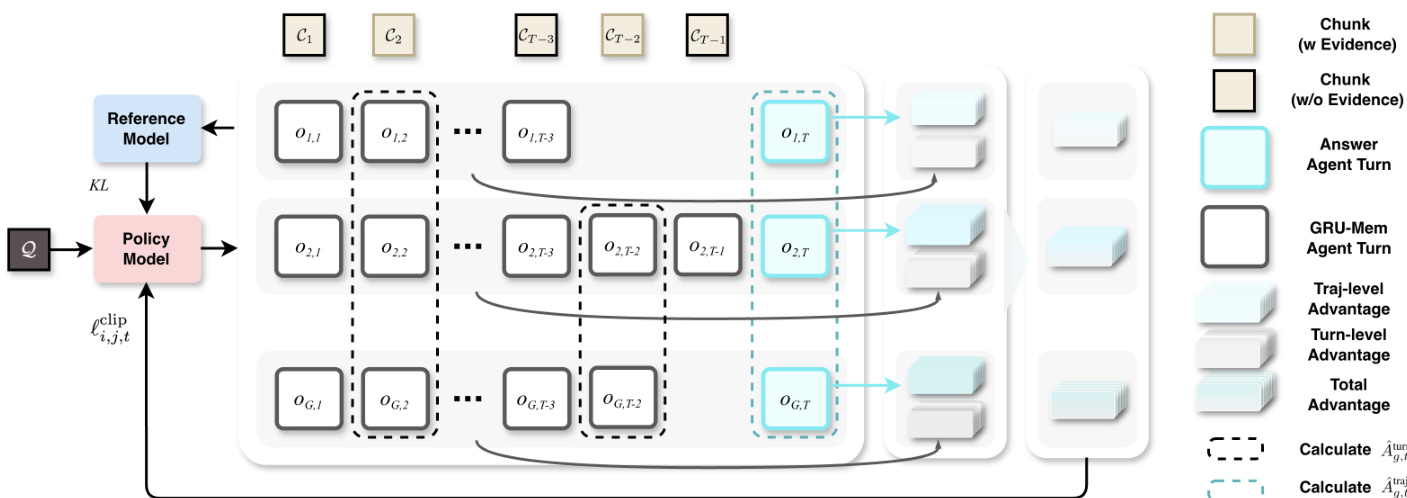
Training is conducted end-to-end via reinforcement learning, extending the Multi-Conv DAPO algorithm. The policy model is optimized using a composite loss that incorporates multiple reward signals: outcome reward for answer correctness, update reward for accurate gate activation per turn, exit reward for terminating at the correct evidence chunk, and format reward for adhering to the structured output. The advantage calculation is disentangled into trajectory-level and turn-level components, which are combined with a hyperparameter α to balance global and local optimization signals. This dual advantage structure stabilizes training by separately evaluating the impact of gate decisions across turns and trajectories.
As shown in the advantage calculation diagram, the policy model receives feedback from both the trajectory-level advantage (comparing across entire workflows) and the turn-level advantage (comparing gate decisions at each step), enabling fine-grained control over the gating behavior.

During inference, the authors provide flexibility by supporting two modes: with exit gate (w EG) and without exit gate (w/o EG). The w EG mode terminates early when Et is True, while the w/o EG mode processes all chunks regardless of gate status, accommodating tasks requiring full context traversal. This dual-mode inference ensures adaptability across diverse long-context reasoning scenarios.
Experiment
- GRU-Mem outperforms vanilla MemAgent across diverse QA and NIAH tasks, especially on out-of-distribution and multi-key benchmarks, with greater stability under long contexts and smaller model sizes.
- GRU-Mem achieves substantial inference speedups—up to 400% faster with early exit—without sacrificing accuracy, thanks to efficient memory management and adaptive termination.
- The update gate curbs memory explosion by selectively updating only evidence-relevant chunks, while the exit gate enables early termination when evidence is found early, improving flexibility in unbalanced evidence scenarios.
- Ablation studies show that α=0.9 balances update accuracy and reward stability; RL training further boosts performance, especially on harder tasks, by refining gating behaviors during training.
- Training dynamics reveal rapid learning of correct formatting and exit behavior, with response length and exit deviation stabilizing over time as the model learns to update and stop precisely.
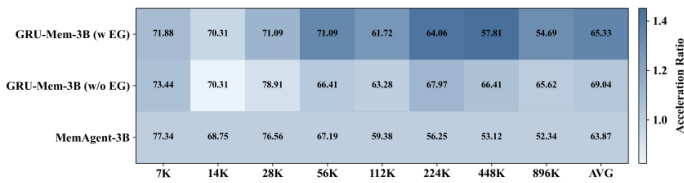
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show GRU-Mem maintains strong performance on out-of-distribution tasks while achieving up to 2x faster inference without early exit and even greater acceleration when early exit is enabled. The method’s gating mechanisms help control memory growth and enable timely termination, contributing to stable and efficient long-context reasoning.
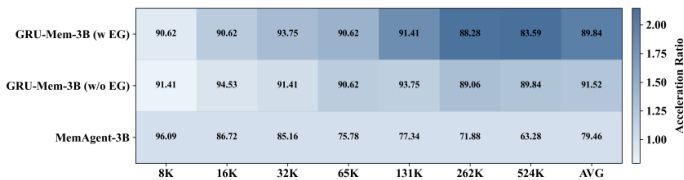
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show GRU-Mem achieves up to 400% faster inference with early exit mechanisms while maintaining or improving task performance, especially on out-of-distribution and multi-key tasks. The gating mechanisms enable more selective memory updates and earlier termination, reducing computational overhead without sacrificing accuracy.
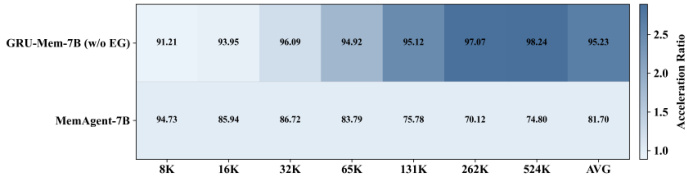
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show that GRU-Mem achieves up to 2x faster inference without sacrificing performance, particularly benefiting from its gating mechanisms that control memory updates and early exit decisions. The model maintains stable performance even as context scales, with efficiency improvements becoming more pronounced at longer lengths.
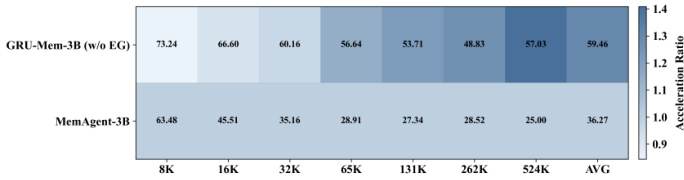
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show that GRU-Mem with early exit achieves up to 4x faster inference while maintaining or improving task performance, especially under longer contexts. The efficiency gains are more pronounced as context size increases, indicating better scalability for long-context reasoning tasks.
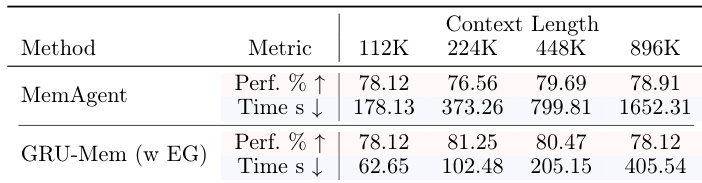
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show GRU-Mem maintains stronger performance on out-of-distribution tasks and achieves up to 400% faster inference with early exit mechanisms, while also stabilizing memory growth through gated updates. The method proves particularly effective under long-context and evidence-unbalanced scenarios, with performance improvements scaling with context size.