Command Palette
Search for a command to run...
LLaDA2.1 : Accélération de la diffusion de texte par édition de tokens
LLaDA2.1 : Accélération de la diffusion de texte par édition de tokens
Résumé
Bien que LLaDA2.0 ait mis en évidence le potentiel d’échelle des modèles de diffusion par blocs de niveau 100B ainsi que leur parallélisation intrinsèque, l’équilibre délicat entre vitesse de décodage et qualité de génération est demeuré une frontière inatteignable. Aujourd’hui, nous présentons LLaDA2.1, un changement de paradigme conçu pour dépasser ce compromis. En intégrant de manière fluide l’édition Token-to-Token (T2T) au schéma conventionnel Mask-to-Token (M2T), nous introduisons un schéma de décodage conjoint et configurable basé sur des seuils. Cette innovation structurelle donne naissance à deux personnalités distinctes : le Mode Vitesse (S Mode), qui réduit audacieusement le seuil M2T afin de contourner les contraintes traditionnelles tout en s’appuyant sur T2T pour affiner la sortie ; et le Mode Qualité (Q Mode), qui privilégie des seuils conservateurs afin d’assurer des performances supérieures sur les benchmarks, avec une dégradation de l’efficacité maîtrisée. Poursuivant cette évolution, soutenue par une fenêtre contextuelle étendue, nous mettons en œuvre le premier cadre d’apprentissage par renforcement (RL) à grande échelle spécifiquement conçu pour les dLLMs, ancré dans des techniques spécialisées d’estimation stable des gradients. Cette alignement non seulement affûte la précision du raisonnement, mais aussi améliore la fidélité à l’instruction, comblant ainsi l’écart entre la dynamique de diffusion et les intentions humaines complexes. Nous concluons cette étude par la mise à disposition de LLaDA2.1-Mini (16B) et de LLaDA2.1-Flash (100B). Sur 33 benchmarks rigoureux, LLaDA2.1 affiche des performances solides sur les tâches et une vitesse de décodage fulgurante. Malgré son volume de 100B, il atteint sur les tâches de codage des performances remarquables : 892 TPS sur HumanEval+, 801 TPS sur BigCodeBench et 663 TPS sur LiveCodeBench.
One-sentence Summary
Ant Group, Zhejiang University, Westlake University, and Southern University of Science and Technology researchers propose LLaDA2.1, a 100B diffusion LLM that breaks the speed-quality trade-off via joint T2T/M2T decoding modes and RL alignment, achieving 892 TPS on HumanEval+ while maintaining strong benchmark performance.
Key Contributions
- LLaDA2.1 introduces a joint Token-to-Token and Mask-to-Token decoding scheme with configurable thresholds, enabling two operational modes—Speedy Mode for aggressive parallel generation and Quality Mode for high-fidelity output—thereby resolving the long-standing trade-off between decoding speed and generation quality in discrete diffusion LLMs.
- The model integrates the first large-scale Reinforcement Learning framework tailored for dLLMs, using an ELBO-based Block-level Policy Optimization method to stabilize gradient estimation, which enhances reasoning precision and instruction-following fidelity without compromising the parallel decoding architecture.
- Evaluated across 33 benchmarks, LLaDA2.1-Flash (100B) achieves state-level throughput—892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench—while maintaining strong task performance, demonstrating that editability enables extreme efficiency without sacrificing quality.
Introduction
The authors leverage discrete diffusion language models (dLLMs) to overcome the rigid trade-off between decoding speed and generation quality inherent in traditional autoregressive or mask-to-token frameworks. Prior work struggled with token-level inconsistencies in parallel decoding and lacked mechanisms to dynamically correct errors without sacrificing efficiency. LLaDA2.1 introduces a joint Token-to-Token (T2T) and Mask-to-Token (M2T) decoding scheme with configurable thresholds, enabling two operational modes: Speedy Mode for high throughput and Quality Mode for precision. They further enhance reasoning and instruction alignment via a novel RL framework (EBPO) tailored for editable state evolution, all while maintaining model size and training data constraints. The result is a scalable, editable diffusion architecture that delivers state-of-the-art speed—up to 892 TPS on coding benchmarks—without compromising fidelity.
Method
The authors leverage a novel “Draft-and-Edit” decoding paradigm to mitigate exposure bias in diffusion-based large language models (dLLMs), enabling iterative refinement of parallel token generation while preserving speed. This approach departs from conventional absorbing-state diffusion models by introducing dual dynamic update sets—Unmasking Set Γt and Editing Set Δt—governed by configurable probability thresholds τmask and τedit. At each timestep t, the model identifies positions for unmasking or editing based on the top-candidate token vti=argmaxvpθ(v∣xt), formalized as:
Γt={i∣xti=[MASK] and pθ(vti∣xt)>τmask},Δt={i∣xti=vti and pθ(vti∣xt)>τedit},The state transition applies updates strictly on the union Γt∪Δt:
xt−1i={vtixtiif i∈Γt∪Δt,otherwise.This mechanism allows the model to retrospectively correct errors introduced during parallel generation, balancing speed and quality. The decoding behavior can be tuned via threshold settings: aggressive unmasking enables rapid drafting (S Mode), while conservative thresholds support cautious drafting with iterative refinement (Q Mode). Refer to the framework diagram illustrating the contrast between traditional mask-to-token decoding and the proposed editable paradigm.
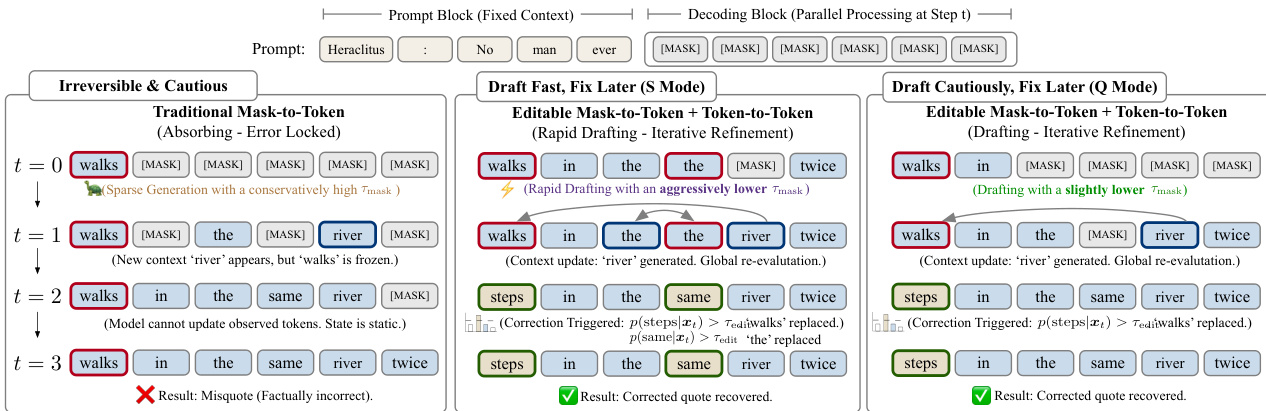
To align the model with this inference paradigm, the authors employ a unified Mixture of Mask-to-Token (M2T) and Token-to-Token (T2T) training objective across both Continual Pre-Training (CPT) and Supervised Fine-Tuning (SFT). The M2T stream trains the model to generate initial drafts from masked contexts, while the T2T stream teaches it to recover correct tokens from perturbed inputs, thereby developing editing capability. Multi-turn Forward (MTF) data augmentation further exposes the model to diverse editing scenarios, enhancing its ability to revise artifacts. The training pipeline culminates in Stage 3, where Reinforcement Learning (RL) is applied via EBPO (ELBO-based Block-level Policy Optimization), which approximates the intractable sequence-level log-likelihood using block-conditional probabilities computed in parallel under a Block-Causal Mask M. The policy update maximizes a clipped surrogate objective:
JEBPO(θ)=Ex,y∼πθold[min(ρ(y∣x)A^,clip(ρ(y∣x),1−ϵlow,1+ϵhigh)A^)],where ρ(y∣x) is estimated via:
logρ(y∣x)≈n=1∑Nwnb=1∑B(logpθ(yb∣zn,x;M)−logpθold(yb∣zn,x;M)).As shown in the figure below, the training and inference workflows are tightly coupled: the model is trained under dual M2T/T2T supervision and then deployed with threshold-controlled unmasking and correction actions during inference.
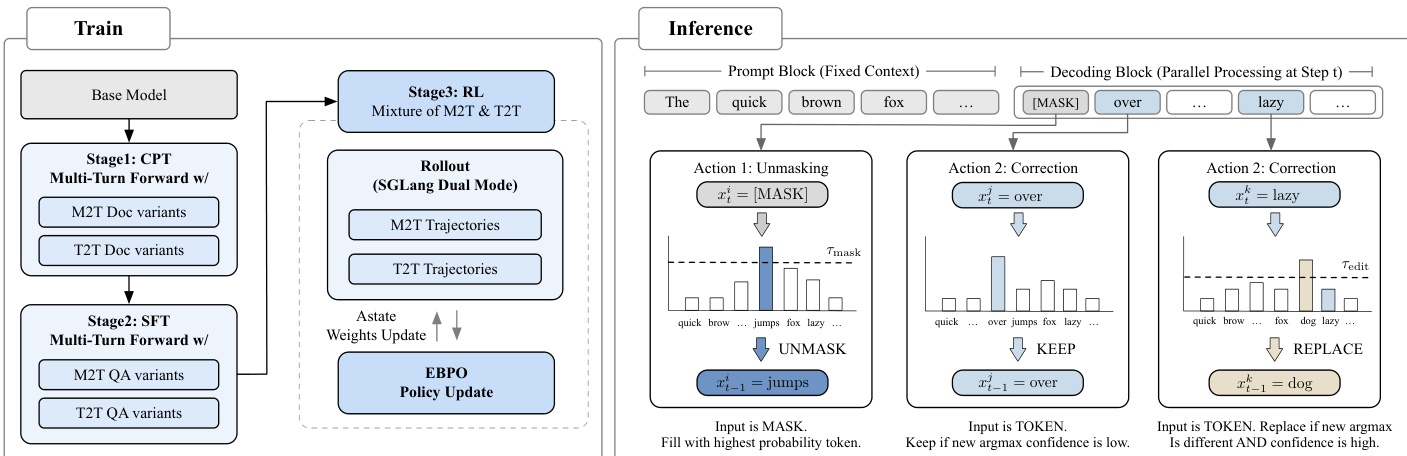
During inference, the decoding algorithm combines threshold-based unmasking with explicit correction. In single-block mode, tokens are generated under τmask, and local edits are applied before finalization. The Multiple Block Editing (MBE) extension allows revisiting and revising prior blocks based on newly decoded content, enabling global consistency. Infrastructure optimizations—including Alpha-MoE megakernels, per-block FP8 quantization, and block-wise causal masked attention—further accelerate inference, particularly for long contexts, while radix caching and batching support ensure scalability.
Experiment
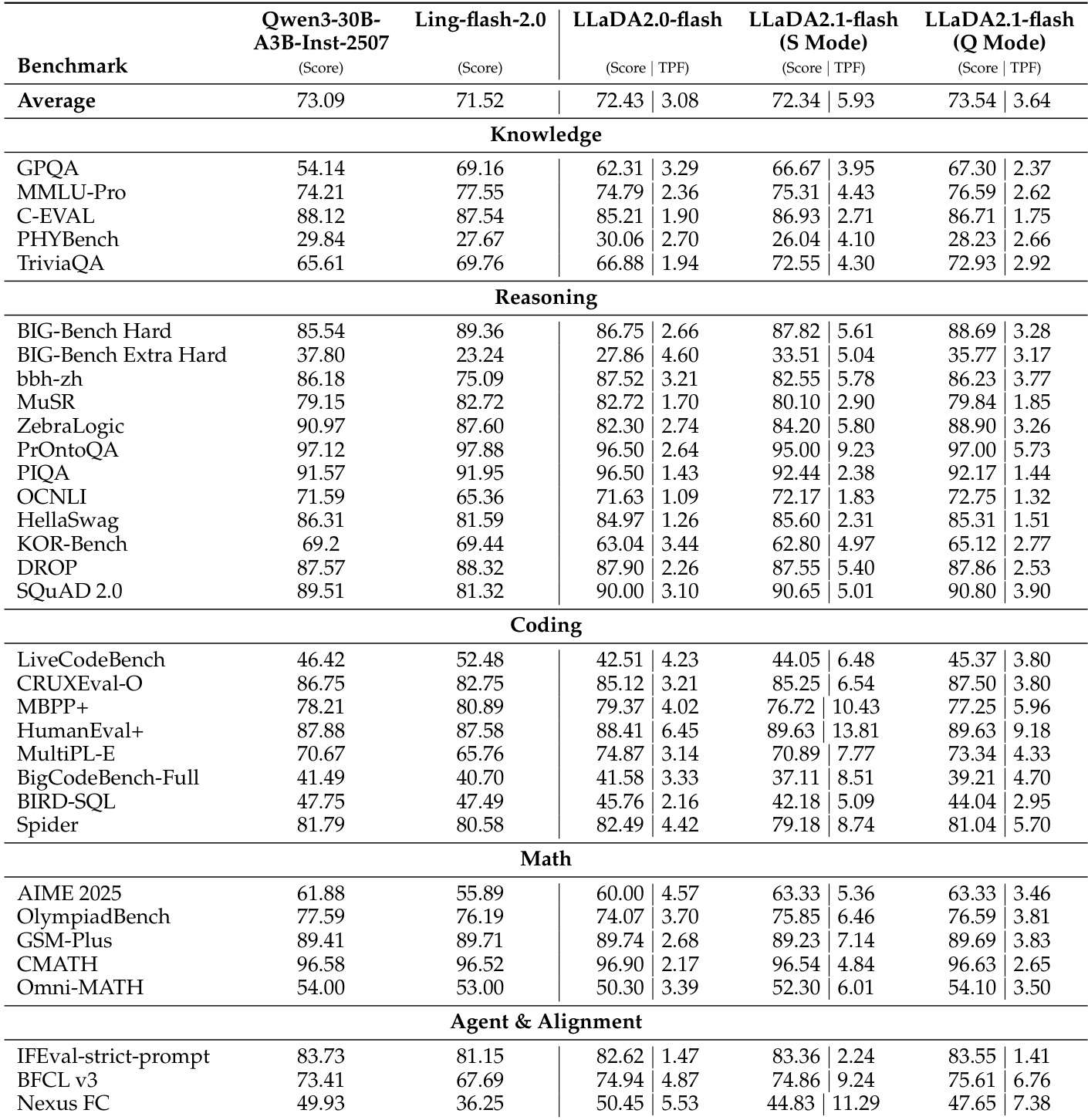
- LLaDA2.1 demonstrates a clear speed-accuracy tradeoff: S Mode prioritizes inference speed with minor quality loss, especially effective in structured domains like coding and math, while Q Mode preserves higher accuracy for general chat tasks.
- Multi-Block Editing consistently improves performance on reasoning and coding benchmarks by correcting local errors and enhancing global consistency, with only modest throughput reduction.
- Quantized variants of LLaDA2.1 achieve peak throughput (TPS) up to 1586.93 on HumanEval+, showing strong speed advantages over prior models like LLaDA2.0, Ling, and Qwen3, particularly in code domains.
- Despite theoretical parallelism advantages, diffusion language models exhibit higher error rates than autoregressive models; timely editing is critical to maintain speed and confidence during inference.
- LLaDA2.1’s editing mechanism lowers decoding thresholds and enables faster inference, but balancing initial draft speed with structural quality remains a key challenge, especially under aggressive masking settings.
- The model is still experimental, with edge cases and artifacts (e.g., stuttering) requiring careful parameter tuning; future work aims to integrate editing into reinforcement learning for stronger self-correction.
The authors use LLaDA2.1 in two modes—S Mode for speed and Q Mode for quality—and find that while S Mode reduces accuracy slightly, it significantly increases throughput, especially in coding and math tasks. Results show that Q Mode consistently outperforms S Mode in overall score, indicating a clear tradeoff between inference speed and output quality across domains. Multi-Block Editing further improves performance on reasoning and coding benchmarks with only a modest throughput cost, suggesting iterative refinement helps maintain quality without sacrificing efficiency.
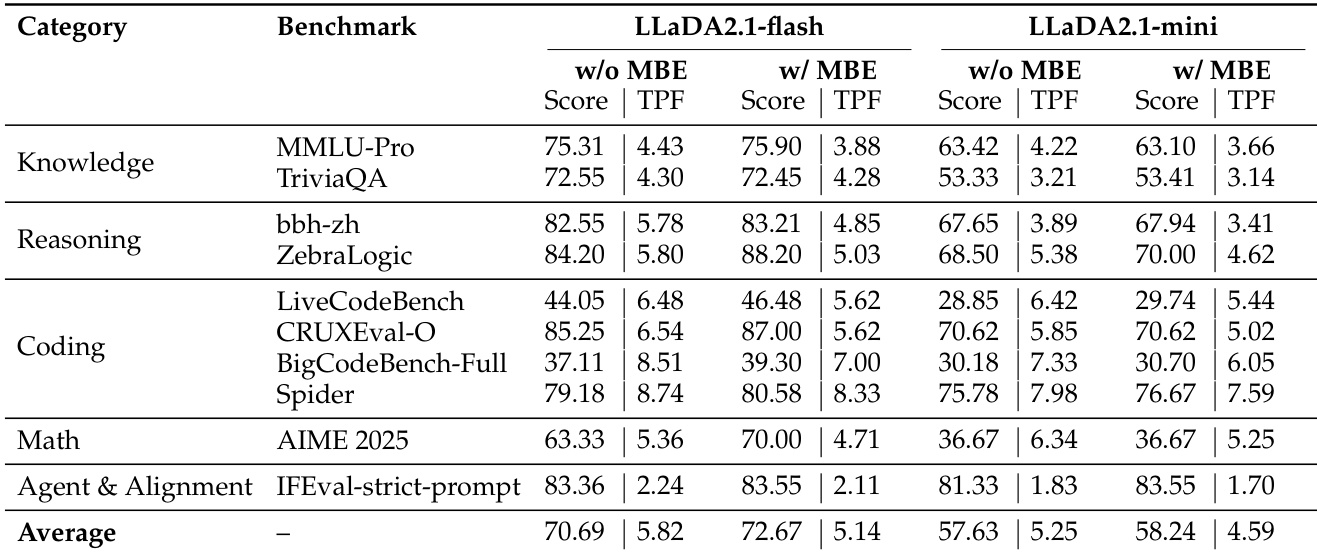
The authors evaluate LLaDA2.1-flash and LLaDA2.1-mini with and without Multi-Block Editing (MBE) across multiple benchmarks, finding that MBE consistently improves scores at the cost of reduced throughput. Results show the largest gains occur in reasoning and coding tasks, where iterative refinement enhances output quality while maintaining acceptable decoding efficiency. Overall, the tradeoff between speed and accuracy is managed effectively through mode selection and editing, with structured domains benefiting most from aggressive speed optimizations.
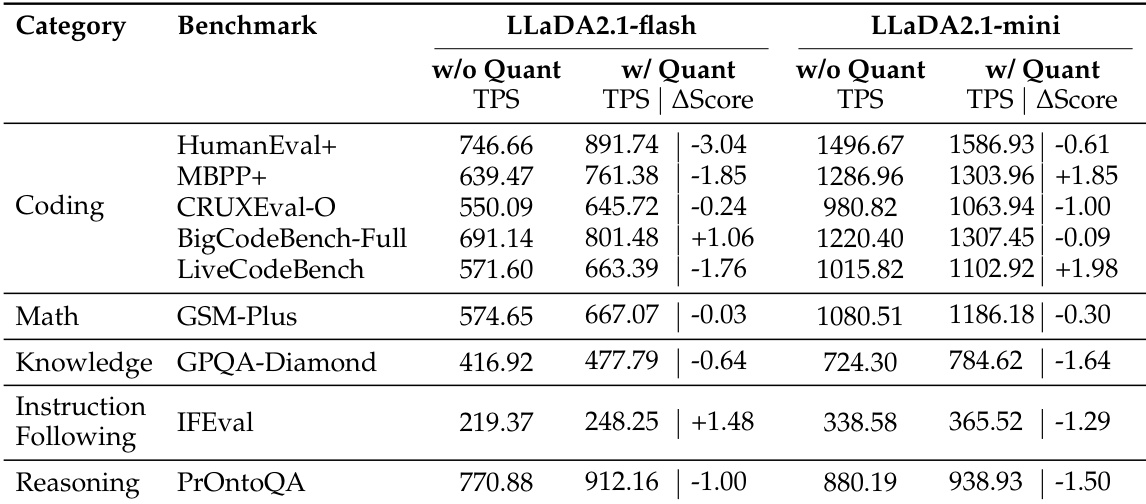
The authors evaluate LLaDA2.1-flash and LLaDA2.1-mini across multiple domains, showing that quantization generally boosts throughput while causing minor score fluctuations, with coding tasks benefiting most in speed and instruction following showing mixed accuracy impacts. Results indicate a clear speed-accuracy tradeoff, where higher throughput in quantized settings often comes at the cost of slight performance degradation, though some benchmarks like MBPP+ and LiveCodeBench see score improvements. The model’s performance varies by domain, suggesting that optimal configuration depends on task type, with structured domains like coding tolerating higher speed settings better than general instruction following.
The authors evaluate LLaDA2.1-mini under two modes, finding that while S Mode boosts inference speed at the cost of some accuracy, Q Mode restores or exceeds prior performance levels with moderate throughput. Results show consistent gains in coding and reasoning tasks under Q Mode, while knowledge and math benchmarks reveal a tradeoff where speed improvements in S Mode come with score reductions. Overall, the model demonstrates that adaptive mode selection can balance speed and accuracy depending on task type.
