Command Palette
Search for a command to run...
Théorie de l'espace : les Foundation Models peuvent-ils construire des croyances spatiales par l'exploration active ?
Théorie de l'espace : les Foundation Models peuvent-ils construire des croyances spatiales par l'exploration active ?
Résumé
Voici la traduction de votre texte en français, réalisée selon les standards de rigueur scientifique et de fluidité rédactionnelle requis :L'intelligence incarnée spatiale (spatial embodied intelligence) opère souvent dans des conditions d'observabilité partielle, où les agents doivent agir pour acquérir les informations manquantes plutôt que de consommer passivement des observations complètes. Dans de tels contextes, la progression dépend de la sélection active d'actions informatives capables de réduire l'incertitude et de soutenir la construction d'une compréhension spatiale. Bien que les modèles de fondation multimodaux (multimodal foundation models) aient démontré des performances solides dans les tâches de perception et de raisonnement multimodal passif, leur capacité à soutenir une exploration active et autodirigée sous observabilité partielle n'a pas encore fait l'objet d'une étude systématique. En particulier, il reste à déterminer si ces modèles peuvent décider de ce qu'ils doivent observer ensuite, et selon quelles modalités, afin de construire et de maintenir une croyance spatiale (spatial belief) cohérente au fil du temps.Par conséquent, nous proposons le concept de THEORY OF SPACE, défini comme la capacité d'un agent à acquérir activement des informations par le biais d'une exploration autodirigée et active, et à construire, réviser et exploiter une croyance spatiale à partir d'observations séquentielles et partielles. Nous implémentons le THEORY OF SPACE à l'aide d'un benchmark comprenant des environnements textuels et visuels. Plutôt que de résoudre des tâches spécifiques, l'objectif est une exploration pilotée par la curiosité (curiosity-driven exploration) afin de bâtir une croyance spatiale complète et précise.
One-sentence Summary
The authors propose THEORY OF SPACE, defining an agent's ability to construct, revise, and exploit a spatial belief through self-directed active exploration under partial observability, and implement this via a benchmark with textual and visual environments where foundation models engage in curiosity-driven exploration to build a complete, accurate spatial belief from sequential, partial observations rather than solving specific tasks.
Key Contributions
- This work defines THEORY OF SPACE as the capacity of foundation models to actively acquire information and construct a coherent spatial belief through self-directed exploration under partial observability. The framework shifts spatial evaluation from answering questions at fixed views to building and maintaining revisable world models over time.
- A new multimodal benchmark implements this concept using parallel text- and vision-based worlds that allow for controlled diagnosis of failures across symbolic versus perceptual observation streams. The system requires agents to externalize evolving cognitive maps and uncertainty, making spatial belief measurable rather than implicit during task-agnostic exploration.
- Empirical results demonstrate that active exploration creates a significant bottleneck where perception errors and belief instability lead to global map corruption. Analysis of belief probes shows that models exhibit strong inertia when revising obsolete priors, particularly in vision-based updates regarding orientation and facing.
Introduction
Spatial embodied intelligence operates under partial observability, necessitating active action selection to construct spatial understanding. While multimodal foundation models perform well on passive perception tasks, existing benchmarks rarely assess their ability to support self-directed exploration or maintain coherent spatial beliefs over time. Prior work often conflates exploration efficiency with specific task goals or treats internal cognitive states as opaque. To address this, the authors introduce THEORY OF SPACE, a framework that evaluates an agent's capacity to actively acquire information and revise internal spatial beliefs without relying on specific downstream tasks. They implement a benchmark featuring text and vision environments and develop spatial belief probing to externalize and measure the quality of the agent's cognitive map. This methodology exposes critical limitations in current models, including performance degradation during active exploration and an inability to overwrite obsolete spatial priors.
Dataset
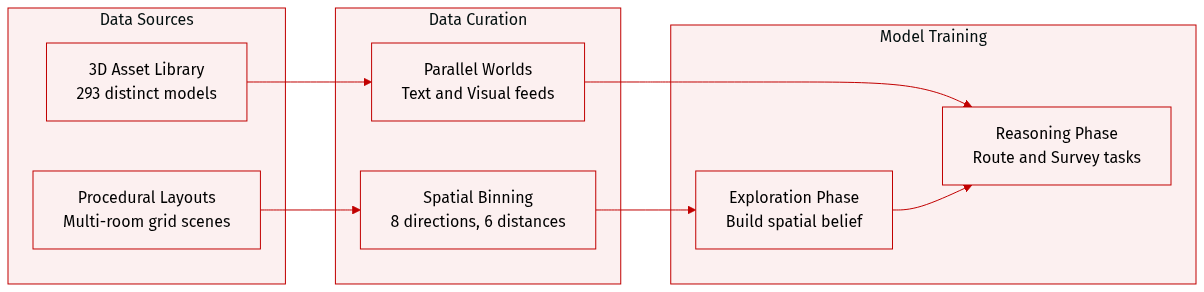
- Dataset Composition and Sources: The authors utilize procedurally generated multi-room indoor layouts on an N by M grid rather than static real-world data. Visual assets are sourced from the Objaverse library and rendered using the ThreeDWorld simulator.
- Key Details for Subsets: The environment supports parallel Text and Visual Worlds. The Visual World provides ego-centric RGB images at 384 by 384 resolution using a library of 293 distinct 3D models. To ensure diversity, each object type appears at most once within a single scene. The Text World offers symbolic observations with discretized bins for direction and distance.
- Usage in the Study: The benchmarking process divides interaction into an Exploration Phase for belief construction and a Reasoning Phase for spatial tasks. Agents interact via a Gym-style interface using high-level actions like Observe and Rotate. Evaluation tasks employ open-ended questions to measure Route and Survey knowledge while minimizing knowledge leakage.
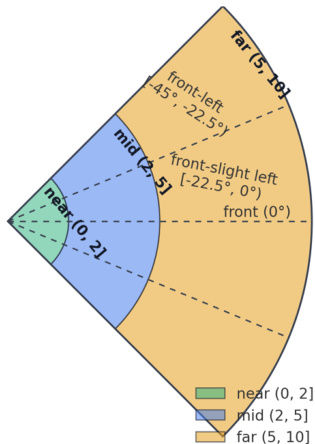
- Processing and Metadata Construction: Spatial relationships are discretized into eight 45-degree bins for allocentric direction and five labels for egocentric views within a 90-degree field of view. Distance is categorized into six bins ranging from same to very far. The visual setting includes reference images to calibrate perception of unit distance and angular cones.
Method
The authors formalize the Theory of Space as the capacity to manipulate a probabilistic belief Bt through three core operations: Construct, Revise, and Exploit. The overall framework involves an agent navigating a partially observable environment to perform active exploration and update its internal spatial belief, as illustrated in the framework diagram.
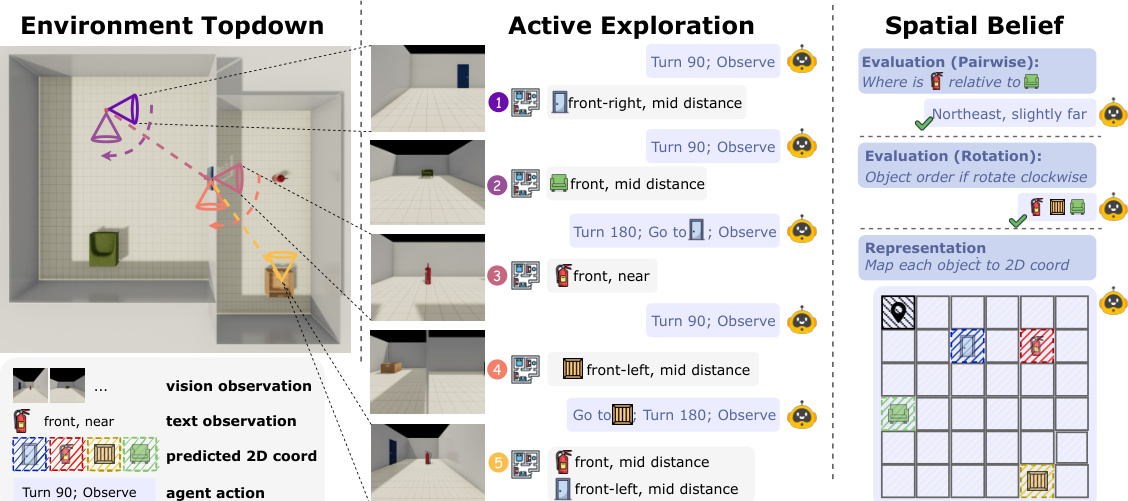
The agent operates within a discretized observation space to facilitate reasoning. Visual and textual observations are mapped to specific distance bins (near, mid, far) and angular sectors (e.g., front-left, front-right), providing a structured input for the model, as shown in the figure below.
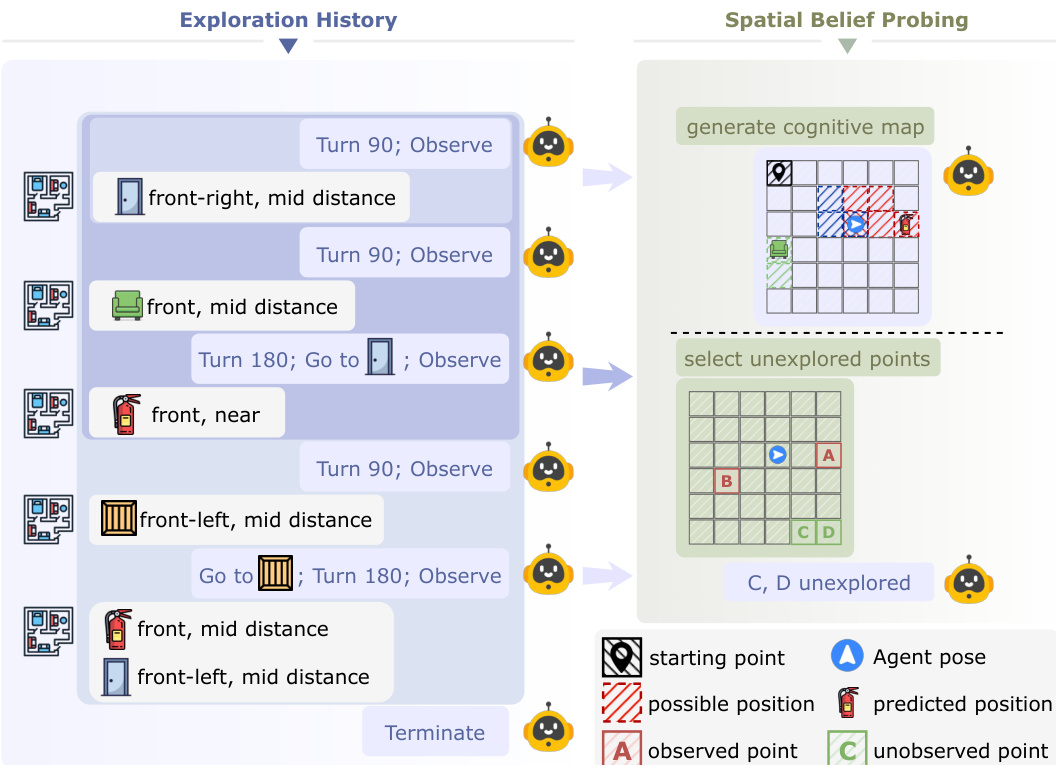
To diagnose how foundation models manage these beliefs, the method employs an explicit probing mechanism. The agent processes its exploration history to generate a structured cognitive map and identify unexplored regions, effectively externalizing its internal spatial representation, as depicted in the figure below.
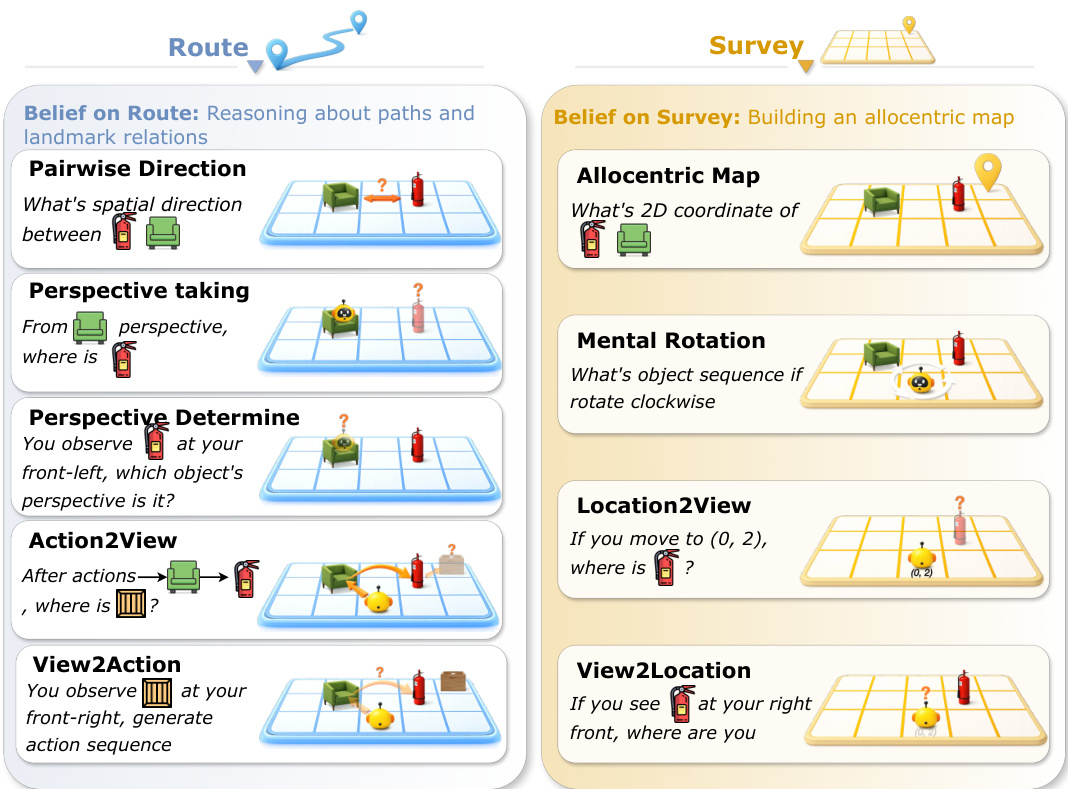
The assessment of belief exploitation is categorized into two primary tasks: Belief on Route and Belief on Survey. The former evaluates egocentric, path-based reasoning and landmark relations, while the latter assesses allocentric, map-like understanding and global spatial inference, as detailed in the figure below.
Finally, the agent is guided by a comprehensive set of prompts that define the exploration goals, action constraints, and formatting rules. These prompts ensure the agent adheres to the spatial reasoning tasks and provides structured outputs, as shown in the figure below.

Experiment
The evaluation framework assesses spatial cognition through active exploration and passive comprehension settings across both text and vision modalities, utilizing standardized proxy agents to isolate reasoning capabilities from exploration efficiency. Results indicate a significant modality gap where text-based performance consistently exceeds vision-based reasoning, while active exploration strategies generally underperform passive comprehension due to incomplete information coverage and higher action costs. Diagnostic probing of cognitive maps highlights that visual agents suffer from unstable belief updates and difficulty overwriting obsolete priors during environmental shifts.
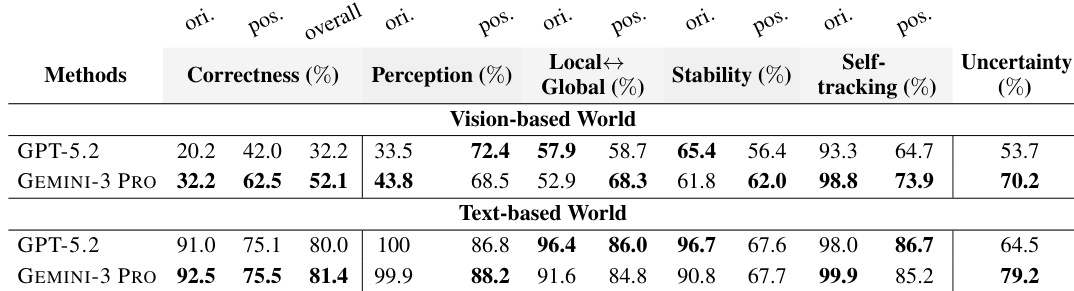
The provided data compares the active exploration exploitation performance of GPT-5.2 and GEMINI-3 PRO in text and vision environments. GEMINI-3 PRO achieves higher performance than GPT-5.2 across both modalities. Additionally, the results show that performance in the vision setting is higher than in the text setting for both models. GEMINI-3 PRO outperforms GPT-5.2 in both text and vision tasks. Vision-based performance metrics exceed those of the text-based setting. The performance gap between the two models is larger in the vision modality.

The evaluation highlights a substantial performance disparity between text-based and vision-based environments, with accuracy metrics significantly higher in text settings. In vision-based tasks, GEMINI-3 PRO consistently outperforms GPT-5.2 across correctness and perception categories, while GPT-5.2 demonstrates higher stability in text-based scenarios. Both models face significant challenges with orientation estimation in visual environments, where scores are notably lower than positional accuracy. Text-based environments yield substantially higher correctness and perception scores compared to vision-based environments. GEMINI-3 PRO achieves superior overall correctness and perception in vision-based tasks compared to GPT-5.2. Orientation accuracy is significantly lower than positional accuracy in vision-based settings for both models.
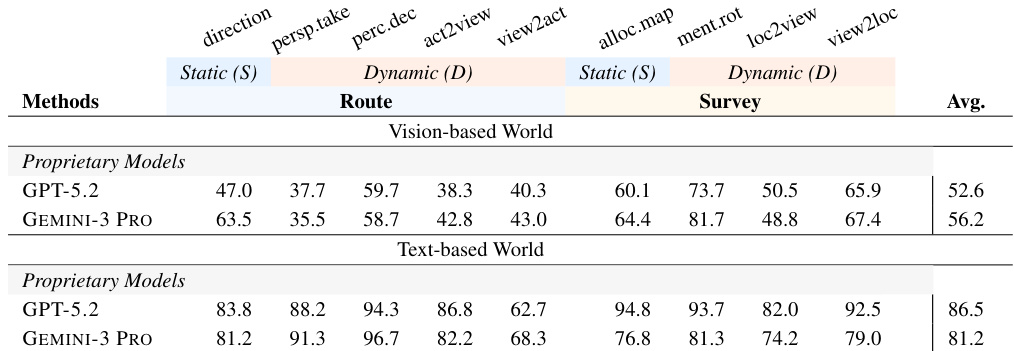
The data compares proprietary models on spatial reasoning tasks across vision-based and text-based environments, highlighting a significant modality gap where text performance is superior. GEMINI-3 PRO achieves higher average scores in the vision-based setting, while GPT-5.2 demonstrates stronger performance in the text-based setting. Text-based reasoning tasks yield significantly higher accuracy scores than vision-based tasks for both models. GEMINI-3 PRO outperforms GPT-5.2 in the vision-based world across the majority of spatial reasoning metrics. GPT-5.2 achieves a higher overall average than GEMINI-3 PRO in the text-based world environment.
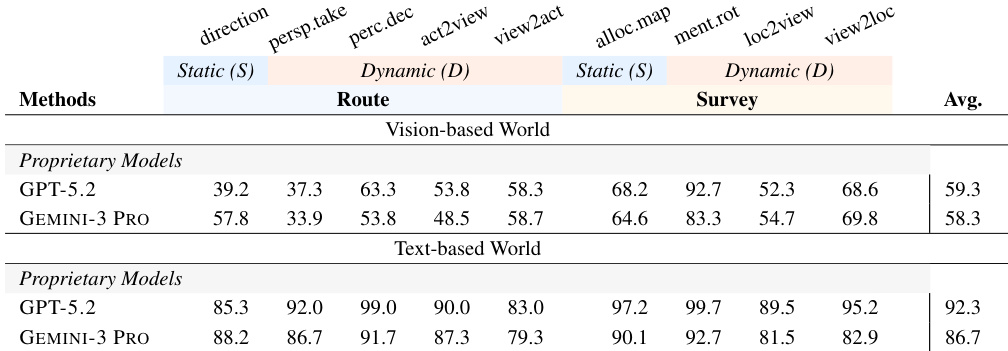
The authors evaluate proprietary models on spatial reasoning tasks divided into Route and Survey categories across vision and text environments. Results show a significant modality gap where text-based performance substantially exceeds vision-based performance for all tasks. GPT-5.2 demonstrates the highest overall average scores in both modalities within this specific evaluation setup. Text-based environments yield significantly higher accuracy across all spatial reasoning tasks compared to vision-based settings. GPT-5.2 achieves higher average performance than GEMINI-3 PRO in both text and vision modalities in this evaluation. Perception and mental rotation tasks exhibit a sharp decline in effectiveness when transitioning from text to visual inputs.
The authors evaluate spatial reasoning capabilities in multi-room environments, comparing 2-room and 4-room configurations across text and vision modalities. Results show that increasing environmental complexity leads to a decline in overall performance and significantly widens the gap between passive comprehension and active exploration success. GEMINI-3 PRO demonstrates greater robustness in active tasks within complex layouts compared to GPT-5.2, although both models perform substantially better in text-based settings than vision-based ones. Performance metrics decline and the discrepancy between passive and active results grows as the number of rooms increases. GEMINI-3 PRO maintains higher active exploration accuracy relative to passive performance in 4-room settings compared to GPT-5.2. Vision-based environments consistently result in lower accuracy scores compared to text-based environments for both models.
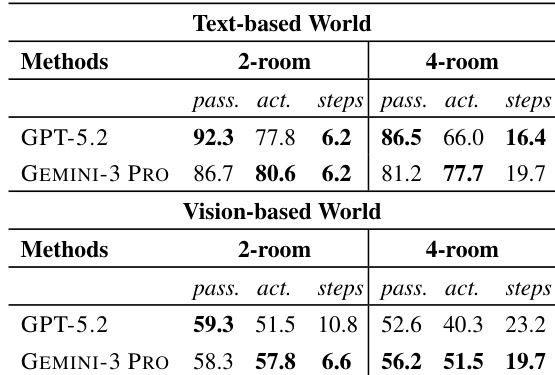
The evaluation compares GPT-5.2 and GEMINI-3 PRO on spatial reasoning and active exploration tasks across text and vision modalities with increasing environmental complexity. A consistent finding across all setups is that text-based performance substantially exceeds vision-based accuracy for both models. Performance outcomes vary by evaluation context, with GEMINI-3 PRO leading in visual robustness and GPT-5.2 excelling in specific text-based or overall configurations.