Command Palette
Search for a command to run...
DreamDojo : un modèle mondial robotique généraliste issu de vidéos humaines à grande échelle
DreamDojo : un modèle mondial robotique généraliste issu de vidéos humaines à grande échelle
Résumé
La capacité à simuler les conséquences d’actions dans divers environnements révolutionnera le développement à grande échelle d’agents généralistes. Toutefois, modéliser ces dynamiques mondiales, en particulier pour des tâches de robotique habile, soulève des défis importants en raison d’une couverture limitée des données et d’un manque d’étiquettes d’actions. Dans cette optique, nous introduisons DreamDojo, un modèle fondamental du monde qui apprend des interactions variées et un contrôle habile à partir de 44 000 heures de vidéos humaines en perspective subjective. Notre ensemble de données représente à ce jour le plus grand jeu de données vidéo dédié au préentraînement de modèles du monde, couvrant une large gamme de scénarios quotidiens avec des objets et des compétences diversifiés. Pour pallier la rareté des étiquettes d’actions, nous proposons l’utilisation d’actions latentes continues comme actions proxy unifiées, améliorant ainsi le transfert des connaissances d’interaction à partir de vidéos non étiquetées. Après une phase de post-entraînement sur des données cibles issues de robots à petite échelle, DreamDojo démontre une compréhension solide des lois physiques et une maîtrise précise des actions. Nous avons également conçu un pipeline de distillation permettant d’accélérer DreamDojo jusqu’à une vitesse en temps réel de 10,81 FPS, tout en améliorant davantage la cohérence contextuelle. Ce travail ouvre la voie à plusieurs applications majeures basées sur des modèles du monde génératifs, notamment la téléopération en temps réel, l’évaluation de politiques et la planification basée sur modèle. Une évaluation systématique sur plusieurs benchmarks exigeants hors distribution (OOD) confirme l’importance de notre méthode pour simuler des tâches ouvertes et riches en contacts, ouvrant ainsi la voie à des modèles du monde robotiques généralistes.
One-sentence Summary
Researchers from NVIDIA, HKUST, UC Berkeley, and others propose DREAMDoJO, a foundation world model trained on 44k hours of egocentric videos, using latent actions to overcome label scarcity and enabling real-time, physics-aware robotic simulation for teleoperation and planning in open-world tasks.
Key Contributions
- DREAMDoJO is a foundation world model pretrained on 44k hours of egocentric human videos, the largest dataset to date for this task, enabling zero-shot generalization to unseen objects and environments by leveraging consistent physics across human and robot interactions.
- To overcome the scarcity of action labels, it introduces continuous latent actions as unified proxy actions, allowing self-supervised learning of fine-grained controllability and physics from unlabeled videos, which significantly improves transfer to dexterous robot tasks after minimal post-training.
- A novel distillation pipeline accelerates the model to 10.81 FPS at 640×480 resolution while enhancing long-horizon consistency, enabling real-time applications like teleoperation and model-based planning, validated on challenging out-of-distribution benchmarks.
Introduction
The authors leverage large-scale human video data to train DREAMDoJO, a foundation world model capable of simulating dexterous robotic tasks in open, unseen environments. Prior video world models struggle with high-dimensional robot actions and limited, expert-only datasets, which restrict generalization and counterfactual reasoning. To overcome sparse action labels, they introduce continuous latent actions as unified proxies, enabling scalable, self-supervised learning of physics and controllability from 44k hours of egocentric human videos—the largest such dataset to date. Their distillation pipeline accelerates inference to 10.81 FPS while preserving visual quality and long-horizon consistency, unlocking real-time applications like teleoperation and model-based planning.
Dataset
-
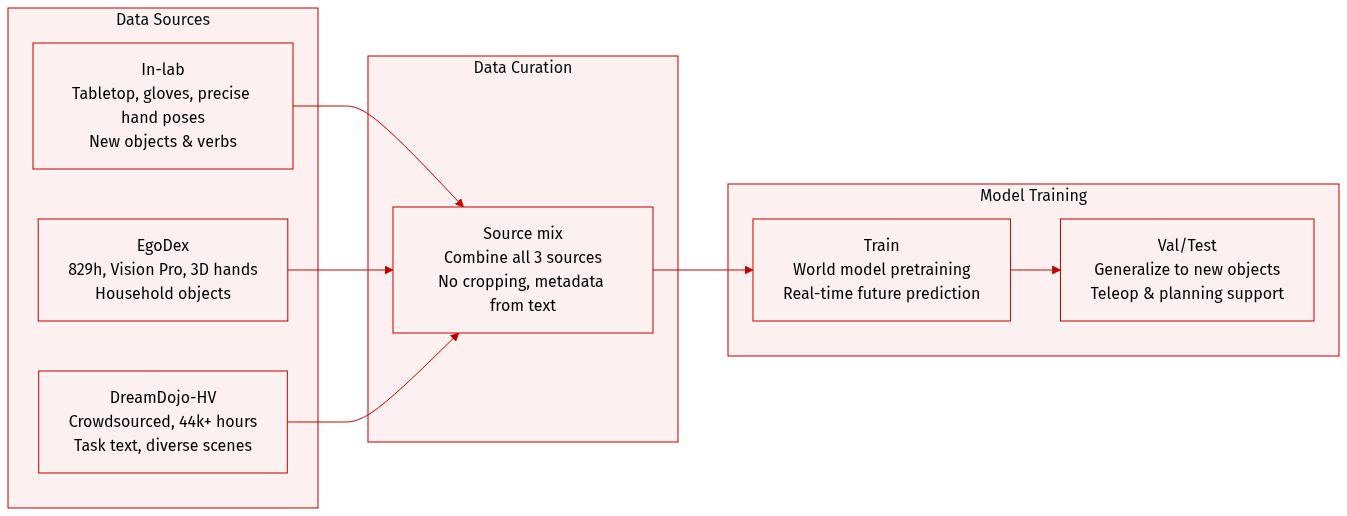
The authors use DreamDojo-HV, a 44,711-hour egocentric video dataset, to pretrain a world model capable of generalizing across objects, tasks, and environments. It is the largest human interaction dataset for this purpose to date.
-
The dataset combines three sources:
- In-lab: Lab-collected tabletop interactions using Manus gloves and Vive trackers for precise hand pose capture; enables direct retargeting to GR-1 robot actions and includes novel objects/verbs.
- EgoDex: 829 hours of public egocentric videos from Apple Vision Pro, with 3D hand/finger tracking and diverse household objects to expand object variety.
- DreamDojo-HV (in-house): Crowdsourced videos covering loco-manipulation skills across household, industrial, retail, educational, and administrative settings; each clip includes task text annotations.
-
The full dataset includes 9,869 unique scenes, 6,015 unique tasks, and 43,237 unique objects — 15x longer, 96x more skills, and 2,000x more scenes than prior world model datasets.
-
For training, the authors mix these subsets without explicit ratios mentioned, but emphasize scale and diversity drive performance gains. No cropping strategy is described; metadata is built from task text annotations per clip and scene/task/object identifiers.
-
The dataset enables real-time future prediction with continuous actions, supports teleoperation, and allows online model-based planning without real-world deployment.
Method
The authors leverage a three-phase training pipeline to build DREAMDoJO, a world model capable of simulating robot interactions from human video data and adapting to target embodiments. The overall framework begins with pretraining on diverse egocentric human datasets, followed by post-training on robot-specific data, and concludes with a distillation stage to enable real-time autoregressive generation. Refer to the framework diagram for a high-level overview of this pipeline.
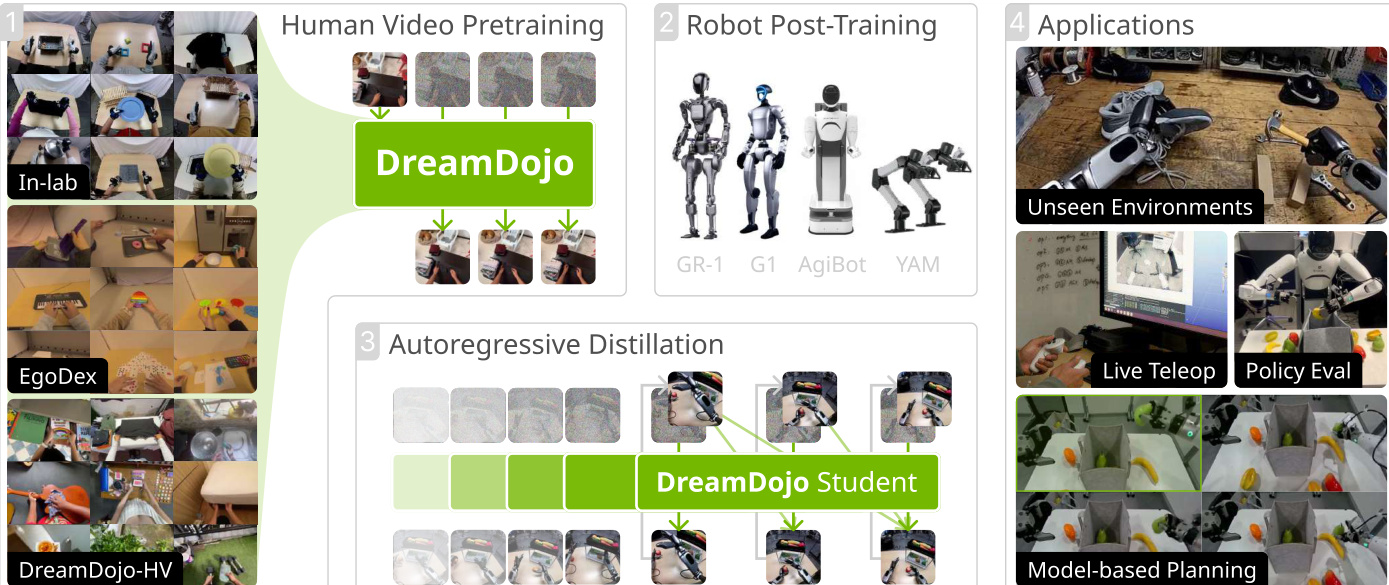
At the core of the architecture is the Cosmos-Predict2.5 model, a latent video diffusion model operating in the continuous latent space produced by the WAN2.2 tokenizer. The model conditions on text, frames, and actions via cross-attention and adaptive layer normalization, trained using flow matching loss. To enhance action controllability — critical for robotic applications — the authors introduce two key architectural modifications. First, they transform absolute robot joint poses into relative actions by rebaselining each latent frame’s input to the pose at its start (every 4 timesteps), which reduces modeling complexity and improves generalization. Second, to respect causality, they inject actions into latent frames in chunks of 4 consecutive actions, rather than as a global condition, thereby eliminating future action leakage and improving learning efficiency.
To enable pretraining on unlabeled human videos, the authors introduce a latent action model based on a spatiotemporal Transformer VAE. This model extracts compact, disentangled action representations from consecutive video frames ft:t+1, producing a latent action a^t that the decoder uses — along with ft — to reconstruct ft+1. The training objective combines reconstruction loss and KL regularization to enforce an information bottleneck, ensuring the latent encodes only the most critical motion. As shown in the figure below, this latent action model successfully captures human actions and enables cross-embodiment generalization, allowing the same action representation to be used across diverse robotic platforms.

During pretraining, the authors condition each latent frame on chunked latent actions projected via a lightweight MLP, initialized with zero weights to preserve pretrained physics knowledge. They further enhance temporal coherence by augmenting the standard flow matching loss with a temporal consistency loss that penalizes discrepancies in velocity differences between consecutive latent frames:
Ltemporal(θ)=E[i=1∑K−1(zi+1−zi)−(vi+1−vi))2].The final training objective is a weighted sum of the flow matching and temporal consistency losses:
Lfinal(θ)=Lflow(θ)+λLtemporal(θ),with λ=0.1 in practice.
For post-training on target robots, the authors reinitialize the first layer of the action MLP to match the robot’s action space and finetune the entire model. This stage enables adaptation to specific embodiments — such as GR-1, G1, AgiBot, and YAM — using only limited robot data, while preserving the generalization benefits of pretraining.
Finally, to enable real-time applications like live teleoperation and model-based planning, the authors distill the foundation model into an autoregressive student model. This involves replacing bidirectional attention with causal attention and reducing the denoising steps from 50 to 4. The distillation proceeds in two stages: a warmup phase where the student regresses to teacher-generated ODE trajectories, and a distillation phase where the student generates autoregressively and is supervised via a KL-based distribution matching loss. To mitigate compounding error, the student is trained to generate longer rollouts than the teacher, with supervision applied via randomly sampled windows.
Experiment
- Latent action conditioning enables significantly better transfer from human videos compared to action-free pretraining, nearly matching ideal ground-truth action settings.
- Incorporating diverse human datasets during pretraining improves generalization to novel physical interactions and counterfactual actions.
- Architectural enhancements—including relative actions, chunked injection, and temporal consistency loss—substantially boost simulation accuracy and action controllability.
- The distillation pipeline yields a lightweight, real-time model that maintains high fidelity over long-horizon rollouts while offering better context awareness and robustness to occlusions.
- DREAMDoJO demonstrates strong out-of-distribution generalization, especially in edited or novel environments, validated through human preference evaluations.
- Downstream applications show DREAMDoJO reliably evaluates policies, enables effective model-based planning with significant performance gains, and supports real-time teleoperation.
Results show that incorporating more diverse human video datasets during pretraining consistently improves performance across out-of-distribution scenarios and counterfactual actions. The DREAMDoJO-14B variant achieves the strongest overall scores, particularly in SSIM and LPIPS metrics, indicating better structural and perceptual fidelity in generated videos. Adding the DreamDojo-HV dataset to the pretraining mixture further boosts generalization, especially on novel interactions not seen in robot training data.

The authors use latent action conditioning to bridge the performance gap between action-free pretraining and ideal ground-truth action setups, achieving near-parity with retargeted actions in simulation quality. Results show that latent actions significantly improve transfer from human videos while remaining scalable and practical without requiring specialized motion capture hardware.
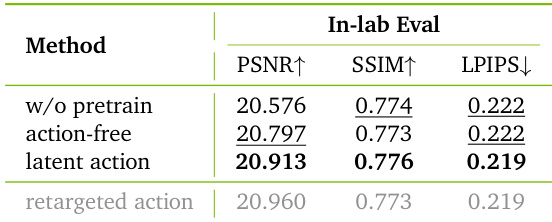
The authors evaluate architectural and loss design choices by incrementally applying relative actions, chunked injection, and temporal consistency loss to a base model. Results show that each modification contributes to improved simulation quality on both expert and counterfactual trajectories, with the full combination achieving the best performance across all metrics. This confirms that precise action controllability and temporal coherence are critical for accurate dynamics prediction.

The authors use latent action conditioning to bridge the performance gap between action-free pretraining and ideal ground-truth action setups, achieving near-parity with MANO-based conditioning in simulation quality. Results show that latent actions significantly improve transfer from human videos while remaining scalable and practical without requiring specialized motion capture hardware.
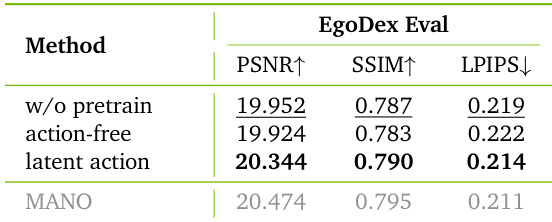
The authors use latent action conditioning to bridge the gap between human video pretraining and robot action execution, achieving performance close to ideal setups that require precise motion capture. Results show that pretraining with latent actions significantly improves simulation quality across diverse evaluation benchmarks compared to action-free or no pretraining, particularly in out-of-distribution scenarios. This approach enables scalable and effective transfer of human interaction knowledge to robotic systems without relying on specialized hardware for action labeling.
