Command Palette
Search for a command to run...
DFlash : Diffusion par blocs pour le décodage spéculatif Flash
DFlash : Diffusion par blocs pour le décodage spéculatif Flash
Jian Chen Yesheng Liang Zhijian Liu
Résumé
Les grands modèles linguistiques autoregressifs (LLM) offrent de solides performances, mais nécessitent une décodage intrinsèquement séquentiel, entraînant une latence élevée lors de l'inférence et une utilisation médiocre des GPU. Le décodage spéculatif atténue ce goulot d'étranglement en utilisant un modèle de brouillon rapide dont les sorties sont vérifiées en parallèle par le LLM cible ; toutefois, les méthodes existantes reposent encore sur un brouillon autoregressif, qui reste séquentiel et limite les gains de vitesse réels. Les modèles de diffusion pour LLM offrent une alternative prometteuse en permettant une génération parallèle, mais les modèles de diffusion actuels peinent généralement à atteindre les performances des modèles autoregressifs. Dans cet article, nous introduisons DFlash, un cadre de décodage spéculatif qui utilise un modèle de diffusion par blocs léger pour le brouillon parallèle. En générant les jetons de brouillon en une seule passe avant et en conditionnant le modèle de brouillon sur des caractéristiques contextuelles extraites du modèle cible, DFlash permet un brouillon efficace produisant des sorties de haute qualité et des taux d’acceptation élevés. Les expériences montrent que DFlash atteint une accélération sans perte dépassant 6x sur une variété de modèles et de tâches, offrant jusqu’à 2,5 fois plus de gain de vitesse que la méthode de décodage spéculatif de pointe actuelle, EAGLE-3.
One-sentence Summary
Jian Chen, Yesheng Liang, and Zhijian Liu from Z-Lab introduce DFlash, a speculative decoding framework using a lightweight block diffusion model for parallel drafting, achieving over 6× lossless acceleration and outperforming EAGLE-3 by 2.5× via context-conditioned, single-pass generation.
Key Contributions
- DFlash introduces a speculative decoding framework that uses a lightweight block diffusion model to draft tokens in parallel, overcoming the sequential bottleneck of autoregressive drafting while maintaining lossless output quality.
- It conditions the draft model on context features extracted from the target LLM, enabling high-acceptance-rate drafts through a single forward pass, effectively turning the draft model into a diffusion adapter that leverages the target’s reasoning.
- Evaluated across multiple models and benchmarks including Qwen3-8B, DFlash achieves over 6× acceleration and up to 2.5× higher speedup than EAGLE-3, demonstrating superior efficiency under realistic serving conditions.
Introduction
The authors leverage speculative decoding to accelerate autoregressive LLM inference by replacing the traditional sequential draft model with a lightweight block diffusion model. While prior speculative methods like EAGLE-3 still rely on autoregressive drafting—limiting speedups to 2–3×—and diffusion LLMs alone suffer from quality degradation or high step counts, DFlash sidesteps these issues by using the target model’s hidden features to condition the diffusion drafter. This allows parallel generation of high-quality draft blocks in a single forward pass, achieving up to 6× lossless speedup and outperforming EAGLE-3 by 2.5×, while keeping memory and compute overhead low.
Method
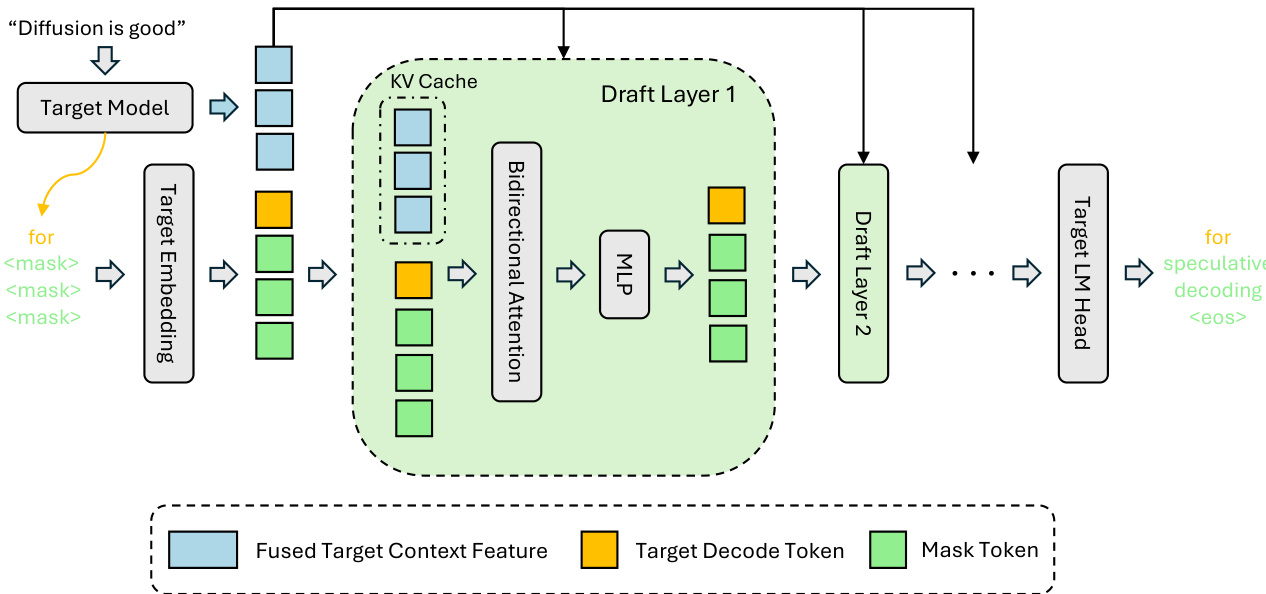
The authors leverage a diffusion-based speculative decoding framework called DFlash, which decouples drafting latency from the number of generated tokens by performing parallel block-wise generation. This architecture enables the use of deeper, more expressive draft models without incurring the linear latency penalty typical of autoregressive drafters. The core innovation lies in the tight integration of target model context features into the draft model’s internal state via persistent Key-Value (KV) cache injection, ensuring consistent conditioning across all draft layers.
During inference, the target model first performs a prefill pass to generate the initial token. From this pass, hidden representations are extracted from a stratified set of layers—spanning shallow to deep—and fused through a lightweight projection layer into a compact context feature vector. This fused feature is then injected into the Key and Value projections of every draft layer, where it is stored in the draft model’s KV cache and reused across all drafting iterations. This design ensures that contextual information from the target model remains strong and undiluted throughout the draft network, enabling acceptance length to scale with draft depth. As shown in the framework diagram, the draft model processes a sequence composed of target decode tokens (yellow), mask tokens (green), and fused target context features (blue), with bidirectional attention within each block and conditioning via the injected KV cache.
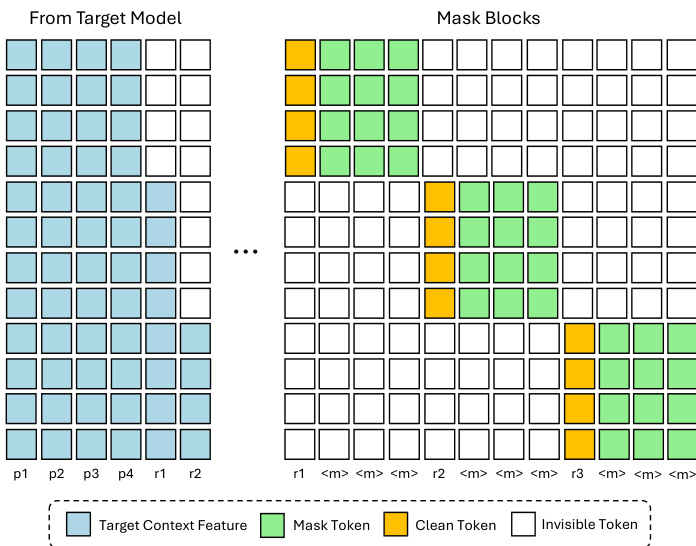
Training is structured to mirror inference behavior. The draft model is trained to denoise masked blocks conditioned on the frozen target model’s hidden features. Rather than uniformly partitioning the response into blocks, DFlash randomly samples anchor tokens from the response and constructs each block to begin with an anchor, masking the subsequent positions. This mimics the speculative decoding process, where the draft model always conditions on a clean token produced by the target model. All blocks are concatenated into a single sequence and processed jointly using a sparse attention mask that enforces causal consistency: tokens attend bidirectionally within their own block and to the injected target context features, but not across blocks. This allows efficient multi-block training in a single forward pass.
To accelerate convergence and prioritize early token accuracy—which disproportionately affects acceptance length—the authors apply an exponentially decaying loss weight per token position k within a block:
wk=exp(−γk−1),where γ controls the decay rate. Additionally, the draft model shares its token embedding and language modeling head with the target model, keeping them frozen during training. This reduces trainable parameters and aligns the draft model’s representation space with the target, effectively turning it into a lightweight diffusion adapter. For long-context training, the number of masked blocks per sequence is fixed, and anchor positions are resampled per epoch, enabling efficient data augmentation without unbounded computational cost.
Experiment
- DFlash consistently outperforms EAGLE-3 across math, code, and chat tasks, achieving up to 5.1x speedup over autoregressive decoding while maintaining higher acceptance length with lower verification overhead.
- It demonstrates strong efficiency gains in reasoning mode and real-world serving scenarios via SGLang, reducing deployment cost without sacrificing output quality.
- Ablation studies confirm that DFlash’s performance is robust to training data choices and benefits from deeper draft models (5–8 layers) and more target hidden features, though optimal layer count balances drafting cost and quality.
- Block size significantly impacts performance: models trained on larger blocks generalize well to smaller inference blocks, enabling potential dynamic scheduling for efficiency.
- Training enhancements—such as position-dependent loss decay and random anchor sampling—improve convergence and acceptance length.
- Target context features are critical; removing them leads to only modest gains, underscoring their role in effective diffusion-based drafting.
The authors use DFlash to accelerate inference across math, code, and chat tasks, achieving higher speedups and acceptance lengths when sampling is enabled compared to standard greedy decoding. Results show that sampling improves both efficiency and draft quality, particularly on Math500 and HumanEval, indicating that stochastic generation enhances speculative drafting performance. This suggests that incorporating sampling during inference can meaningfully boost the practical throughput of diffusion-based speculative decoding.
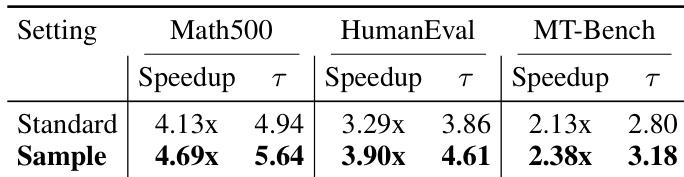
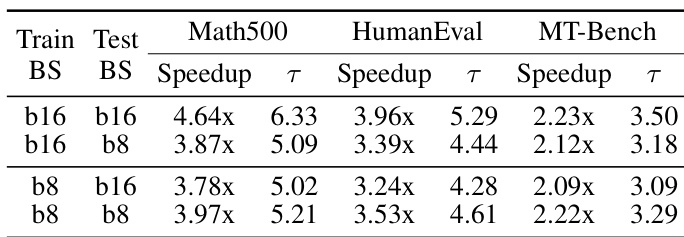
The authors evaluate DFlash draft models under varying training and inference block sizes, finding that models trained with larger block sizes (e.g., 16) achieve higher acceptance lengths and speedups, especially when inference block size matches training size. Models trained on larger blocks also generalize well to smaller inference block sizes, but not vice versa, suggesting flexibility in deployment settings. This behavior supports dynamic block-size scheduling to optimize efficiency under different computational constraints.
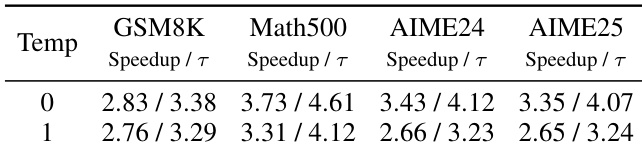
The authors evaluate DFlash on math reasoning tasks using LLaMA-3.1-8B-Instruct under greedy and non-greedy decoding, showing consistent speedups over the autoregressive baseline across GSM8K, Math500, AIME24, and AIME25. Results indicate that while higher temperature reduces both speedup and acceptance length, DFlash maintains strong performance, demonstrating robustness to sampling variability. These findings highlight the method’s effectiveness in accelerating complex reasoning tasks without sacrificing output quality.
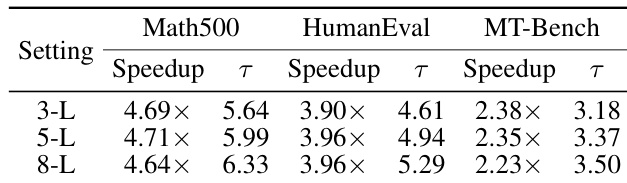
The authors evaluate draft models with varying numbers of layers and find that a 5-layer configuration achieves the best balance between drafting quality and computational efficiency, yielding the highest overall speedup. While deeper models (8 layers) produce longer accepted sequences, their increased drafting cost reduces net performance gains. The results highlight that optimal draft model depth depends on the trade-off between acceptance length and inference latency.
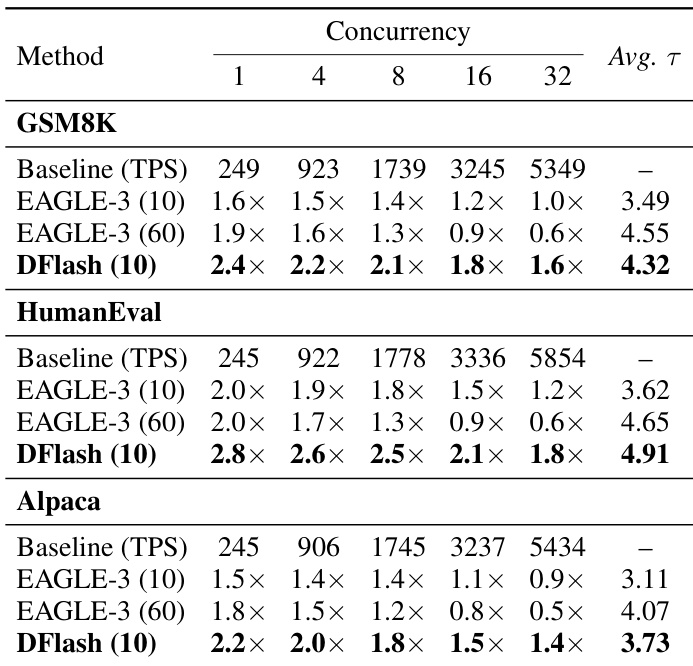
The authors use DFlash to accelerate inference on LLaMA-3.1-8B-Instruct across multiple tasks and concurrency levels, comparing it against EAGLE-3 with varying tree sizes. Results show DFlash consistently achieves higher speedups and better acceptance lengths than both EAGLE-3 configurations, particularly at lower concurrency, demonstrating its efficiency and robustness in practical deployment settings.