Command Palette
Search for a command to run...
WAXAL : UN CORPUS DE PAROLE MULTILINGUE À GRANDE ÉCHELLE POUR LES LANGUES AFRICAINES
WAXAL : UN CORPUS DE PAROLE MULTILINGUE À GRANDE ÉCHELLE POUR LES LANGUES AFRICAINES
Résumé
Les avancées de la technologie de la parole ont majoritairement favorisé les langues à ressources abondantes, creusant une fracture numérique significative pour les locuteurs de la plupart des langues d'Afrique subsaharienne. Pour combler cet écart, nous présentons WAXAL, un corpus de parole à grande échelle et librement accessible couvrant 24 langues représentant plus de 100 millions de locuteurs. Ce corpus se compose de deux volets principaux : un jeu de données pour la reconnaissance automatique de la parole (ASR) comprenant environ 1 250 heures de parole naturelle transcrite, provenant d'un panel diversifié de locuteurs, et un jeu de données pour la synthèse vocale (TTS) regroupant plus de 235 heures d'enregistrements de haute qualité réalisés par un seul locuteur lisant des textes phonétiquement équilibrés. Cet article décrit en détail notre méthodologie de collecte, d'annotation et de contrôle de qualité, qui a impliqué des partenariats avec quatre organisations académiques et communautaires africaines. Nous proposons un aperçu statistique exhaustif du corpus et discutons de ses limites potentielles ainsi que des considérations éthiques qu'il soulève. Les jeux de données WAXAL sont mis à disposition sur https://huggingface.co/datasets/google/WaxalNLP sous la licence permissive CC-BY-4.0, afin de stimuler la recherche, de permettre le développement de technologies inclusives et de servir de ressource essentielle à la préservation numérique de ces langues.
One-sentence Summary
To address the significant digital divide for Sub-Saharan African languages, WAXAL provides a large-scale, openly accessible speech corpus of 24 languages representing over 100 million speakers, consisting of approximately 1,250 hours of transcribed natural speech for Automated Speech Recognition and over 235 hours of high-quality single-speaker recordings reading phonetically balanced scripts for Text-to-Speech, developed in partnership with four African academic and community organizations and released under a CC-BY-4.0 license to catalyze research, enable inclusive technology development, and support digital preservation.
Key Contributions
- We introduce WAXAL, a large-scale speech dataset for 24 Sub-Saharan African languages representing over 100 million speakers. The collection comprises an Automated Speech Recognition (ASR) dataset with approximately 1,250 hours of transcribed natural speech and a Text-to-Speech (TTS) dataset with over 235 hours of high-quality recordings.
- We detail a methodology for data collection, annotation, and quality control established through partnerships with four African academic and community organizations. This process supports the inclusion of diverse speakers and maintains quality control standards for the resulting speech resources.
- The datasets are released at https://huggingface.co/datasets/google/WaxalNLP under a permissive CC-BY-4.0 license to catalyze research and enable the development of inclusive technologies. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations.
Introduction
Automatic speech recognition systems often lack sufficient training data for African languages, which limits technological accessibility and inclusivity in these regions. Existing datasets frequently do not offer the scale or multilingual diversity required for robust model performance across the continent. The authors introduce WAXAL, a large-scale multilingual African language speech corpus designed to address this resource gap. They also emphasize that releasing any large-scale human data requires careful consideration of its limitations and ethical implications.
Dataset
-
Dataset Composition and Sources
- The authors present WAXAL, a large-scale speech dataset covering 24 Sub-Saharan African languages spoken by over 100 million people.
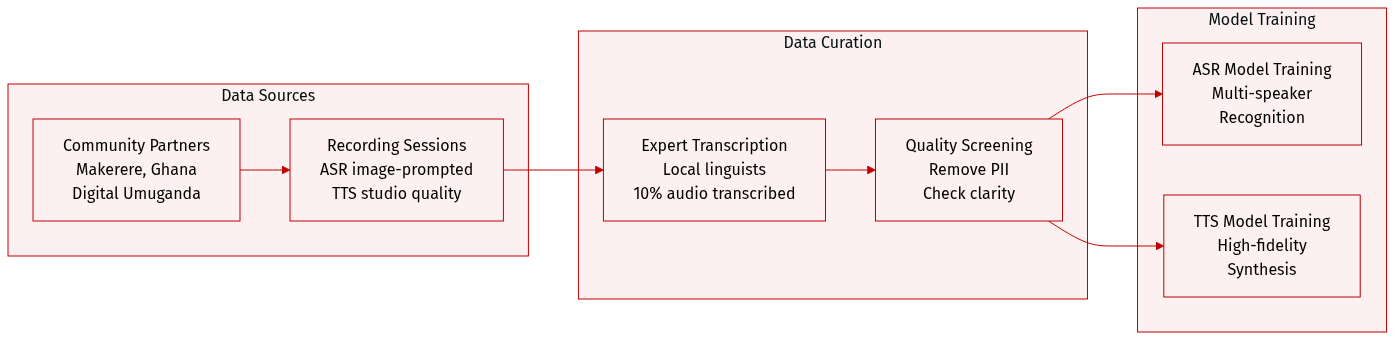
- Collection efforts were conducted in partnership with four African academic and community organizations, such as Makerere University and the University of Ghana.
- The entire collection is released under a CC-BY-4.0 license to encourage academic and commercial research.
-
Key Details for Each Subset
- ASR Subset: Includes approximately 1,250 hours of transcribed natural speech across 14 languages. Recordings were image-prompted to capture spontaneous speech with a minimum duration of 15 seconds.
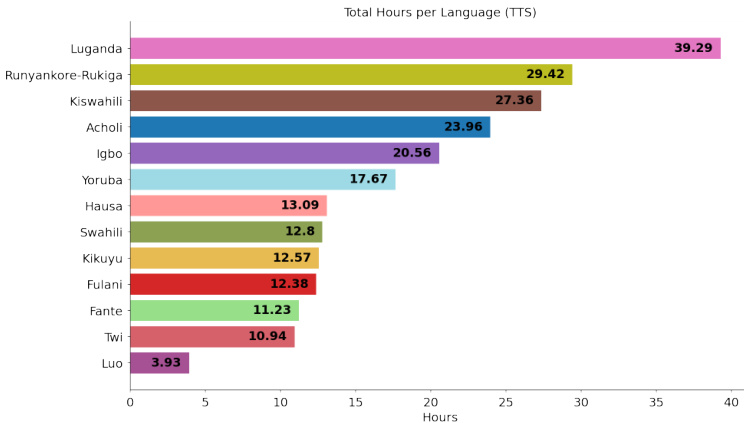
- TTS Subset: Comprises over 180 hours of studio-quality recordings from 72 voice actors across 10 languages. Speakers read phonetically balanced scripts in professional environments.
- File Statistics: The released ASR data occupies 1.7 TB, while the TTS data totals 99 GB.
-
Data Usage and Processing
- Intended Use: The ASR data is suitable for training and evaluating multi-speaker recognition models, whereas the TTS data is designed for high-fidelity voice synthesis.
- Annotation Strategy: Transcriptions were created by local linguistic experts using local scripts or English transliteration. Only 10% of the total collected audio was transcribed for the release.
- Metadata Construction: The dataset includes speaker demographics such as age, gender, and recording environment (e.g., indoor, outdoor).
- Quality Control: The authors removed personally identifiable information and screened audio for clarity, language accuracy, and appropriate content.