Command Palette
Search for a command to run...
Vision-DeepResearch Benchmark : Repenser la recherche visuelle et textuelle pour les grands modèles linguistiques multimodaux
Vision-DeepResearch Benchmark : Repenser la recherche visuelle et textuelle pour les grands modèles linguistiques multimodaux
Résumé
Les modèles linguistiques à grande échelle multimodaux (MLLM) ont fait des progrès significatifs dans les tâches de réponse à des questions visuelles (VQA) et soutiennent désormais des systèmes de recherche approfondie visuelle (Vision-DeepResearch) qui utilisent des moteurs de recherche pour des investigations factuelles complexes impliquant à la fois des éléments visuels et textuels. Toutefois, l’évaluation de ces capacités de recherche visuelle et textuelle reste difficile, et les benchmarks existants présentent deux limites majeures. Premièrement, ces benchmarks ne sont pas centrés sur la recherche visuelle : les réponses qui devraient nécessiter une recherche visuelle sont souvent révélées par des indices textuels croisés présents dans les questions, ou peuvent être déduites à partir des connaissances préalables intégrées aux MLLM actuels. Deuxièmement, les scénarios d’évaluation sont trop idéalisés : du côté de la recherche d’images, l’information requise peut souvent être obtenue par un matching quasi parfait avec l’image complète, tandis que du côté de la recherche textuelle, les questions sont trop directes et insuffisamment exigeantes. Pour remédier à ces problèmes, nous proposons le benchmark Vision-DeepResearch (VDR-Bench), composé de 2 000 instances de VQA. Toutes les questions ont été élaborées à travers un processus rigoureux de curation en plusieurs étapes et une revue experte minutieuse, conçu pour évaluer le comportement des systèmes de recherche approfondie visuelle dans des conditions réalistes du monde réel. En outre, afin de compenser les capacités insuffisantes de récupération visuelle des MLLM actuels, nous proposons une stratégie simple de recherche par découpage itératif (multi-round cropped-search). Cette approche s’est révélée efficace pour améliorer les performances des modèles dans des scénarios réalistes de récupération visuelle. Globalement, nos résultats offrent des orientations pratiques pour la conception de futurs systèmes multimodaux de recherche approfondie. Le code sera publié à l’adresse suivante : https://github.com/Osilly/Vision-DeepResearch.
One-sentence Summary
The authors from Shenzhen Loop Area Institute and collaborating institutions propose Vision-DeepResearch, a benchmark rethinking visual-textual search for multimodal LLMs, introducing novel evaluation metrics that better capture real-world retrieval challenges beyond prior static datasets.
Key Contributions
- We identify critical limitations in existing multimodal search benchmarks, including reliance on text-only cues and idealized whole-image retrieval that fail to reflect real-world visual search challenges.
- We introduce VDR-Bench, a 2,000-instance benchmark built via a multi-stage curation pipeline requiring genuine visual search and multi-hop reasoning, with human verification to eliminate shortcut solutions.
- We propose a multi-round cropped-search workflow that improves visual retrieval accuracy by iteratively localizing entities, validated through experiments showing significant performance gains on realistic scenarios.
Introduction
The authors leverage advances in multimodal large language models to address the growing need for systems that can perform deep, real-world visual-textual research—combining image understanding, web search, and multi-hop reasoning. Existing benchmarks fall short because they allow models to bypass genuine visual search via text-based shortcuts or rely on idealized, near-perfect image matching, failing to reflect the noisy, iterative nature of real visual retrieval. To fix this, they introduce VDR-Bench, a 2,000-instance benchmark built through a human-verified pipeline that enforces visual-first reasoning and cross-modal evidence gathering. They also propose a multi-round cropped-search workflow that improves performance by iteratively refining visual queries, offering a practical path toward more robust multimodal agents.
Dataset

The authors use VDR-Bench, a benchmark of 2,000 multi-hop Visual Question Answering (VQA) instances across 10 diverse visual domains, to evaluate deep research and entity-level retrieval performance. Here’s how the dataset is built and used:
-
Sources & Composition:
- Images are sourced from multiple public datasets, pre-filtered for resolution and visual richness using Qwen3-VL-235B-A22B-Instruct to retain only those with multiple entities and realistic scenes.
- Each sample is built around a manually cropped salient region (e.g., object, logo, landmark) used as a visual query for web-scale image search.
- Final samples combine visual evidence, retrieved entities, and multi-hop reasoning chains grounded in external knowledge graphs.
-
Key Subset Details:
- Step 0: Multi-domain image pre-filtering removes low-res images; Qwen3-VL-235B-A22B-Instruct selects high-quality, entity-rich scenes.
- Step 1: Human annotators crop salient regions; each crop triggers a web visual search to retrieve candidate images.
- Step 2: Candidate entities (persons, brands, locations) are extracted from search result titles/captions. Qwen3-VL-235B-A22B-Instruct filters inconsistent matches, followed by human verification to ensure entities can’t be trivially found via full-image search.
- Step 3: Gemini-2.5-Pro generates seed VQA pairs tied to verified entities. Human reviewers ensure questions require visual grounding and have unique, unambiguous answers.
- Step 4: Knowledge-graph random walks expand questions into multi-hop reasoning tasks (e.g., “What city is the HQ of the company whose logo appears?”).
- Step 5: Automated solvability checks confirm answers can be derived from the recorded visual search + KG path; human annotators remove questions with text-only shortcuts or ambiguous reasoning.
-
Model Usage & Training Setup:
- VDR-Bench is used for evaluation only — no training split is mentioned.
- Questions are designed to force agents to retrieve and reason over visual entities, not rely on prior knowledge.
- The benchmark emphasizes both final answer accuracy and entity-level retrieval success.
-
Processing & Metadata:
- Each sample includes: the original image, cropped region, visual search results, verified entity names, knowledge-graph expansion path, and multi-hop question.
- Metadata tracks the full reasoning trajectory — including search queries, retrieved entities, and KG hops — to support evaluation.
- Two metrics are used:
- Answer Accuracy: Evaluated via Qwen3-VL-30B-A3B-Instruct as judge model using a standardized prompt.
- Entity Recall (ER): Measures whether the agent’s retrieved entity set matches the gold entity sequence semantically (not via string match), using an LLM-as-judge to accept valid reasoning paths and synonyms.
Experiment
- Existing Vision-DeepResearch benchmarks often fail to enforce visual-search-centric reasoning, as many questions can be answered using text search or model priors alone, revealing significant textual cue leakage.
- Current evaluation settings are overly idealized, relying on near-exact image matches that bypass real-world challenges like iterative localization, entity refinement, and cross-modal verification.
- On the new VDR-Bench, models perform poorly without search tools, confirming the necessity of active visual and textual retrieval for accurate answers.
- Open-source models with weaker prior knowledge outperform closed-source counterparts when equipped with search tools, indicating that effective tool use matters more than pre-trained knowledge alone.
- Multi-turn visual forcing enhances performance by promoting iterative region cropping and cross-modal verification, highlighting the value of structured visual grounding in complex reasoning tasks.
The authors evaluate multiple vision-language models under controlled search settings to isolate the contributions of visual and textual retrieval. Results show that enabling multi-turn visual forcing consistently improves performance across domains, indicating that iterative refinement and cross-modal verification are critical for effective visual deep research. Open-source models, particularly larger ones, demonstrate strong search-driven reasoning despite weaker prior knowledge, suggesting that tool usage strategy matters more than parametric memory alone.
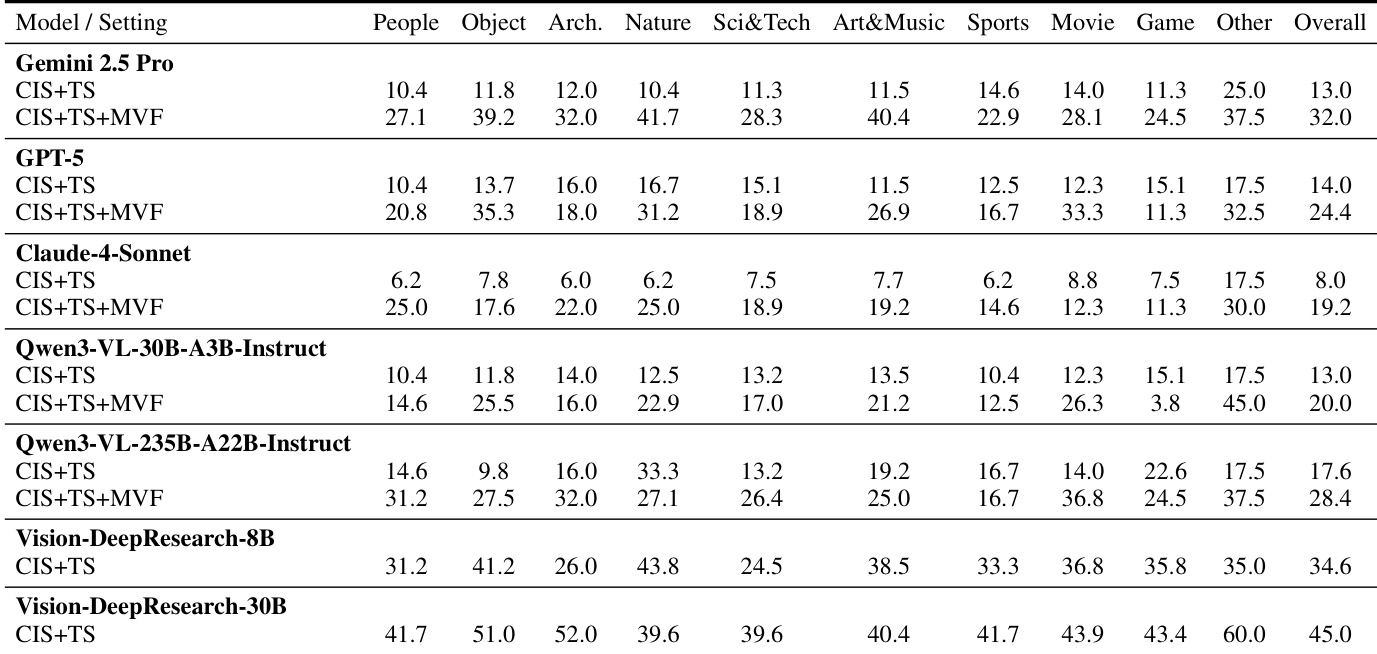
The authors use controlled experiments to show that many existing vision-based benchmarks can be solved effectively without visual search, relying instead on text retrieval or model priors, which undermines their validity for evaluating true visual reasoning. Results show that performance often improves more with text search than with whole-image search, indicating widespread textual cue leakage and an overreliance on language-based knowledge. In contrast, the new VDR-Bench requires active search and demonstrates that model scale and search tool usage, not just prior knowledge, are critical for visual deep-research performance.
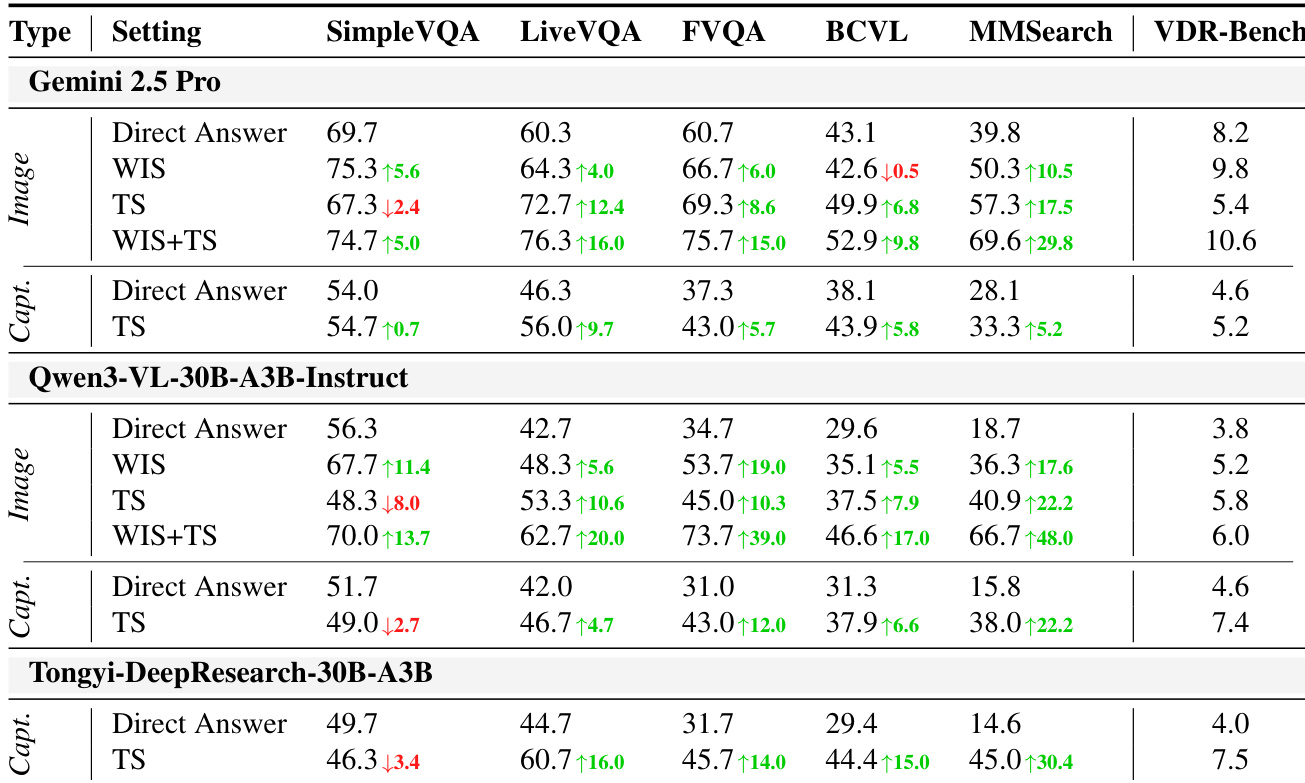
The authors evaluate multiple vision-language models under controlled search conditions to assess their reliance on visual versus textual evidence. Results show that performance improves significantly when models use both cropped-image and text search, with further gains from multi-turn visual forcing, indicating that effective visual reasoning requires iterative refinement and cross-modal verification. Notably, models with weaker prior knowledge often outperform stronger ones when search tools are enabled, suggesting that search strategy matters more than pre-trained knowledge for visual deep-research tasks.
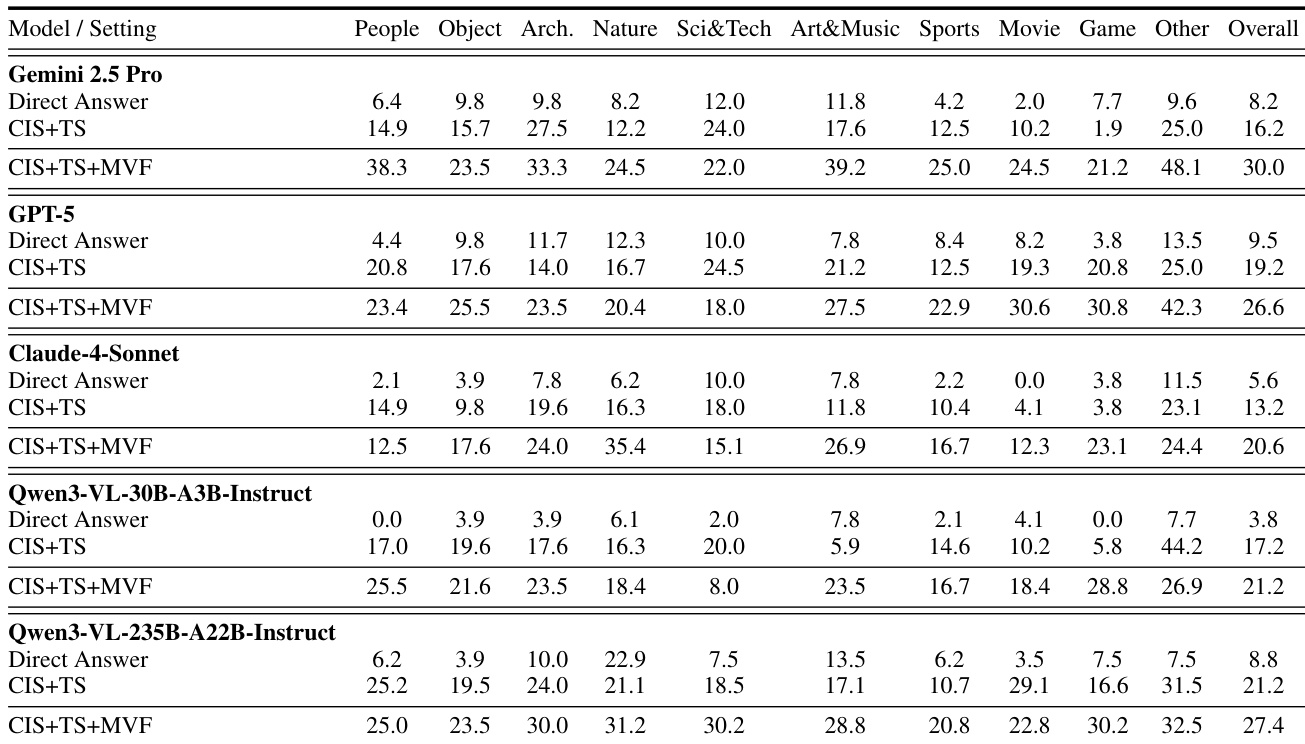
The authors evaluate multiple vision-language models on a new benchmark designed to enforce visual-search-centric reasoning, finding that performance improves significantly when models use both cropped-image and text search tools. Results show that models with weaker prior knowledge often outperform larger closed-source models in search-driven tasks, suggesting that effective tool use matters more than pre-trained knowledge alone. The highest scores are achieved by models that actively engage with visual evidence through iterative search, highlighting the importance of designing benchmarks that require genuine visual grounding rather than textual shortcuts.