Command Palette
Search for a command to run...
La recherche sur les modèles mondiaux n'est pas simplement une injection de connaissances mondiales dans des tâches spécifiques.
La recherche sur les modèles mondiaux n'est pas simplement une injection de connaissances mondiales dans des tâches spécifiques.
Résumé
Les modèles du monde sont apparus comme une frontière critique de la recherche en intelligence artificielle, visant à améliorer les grands modèles en leur intégrant des dynamiques physiques et des connaissances sur le monde. L’objectif central consiste à permettre aux agents de comprendre, prédire et interagir avec des environnements complexes. Toutefois, le paysage actuel de la recherche reste fragmenté, les approches étant principalement centrées sur l’incorporation de connaissances mondiales dans des tâches isolées, telles que la prédiction visuelle, l’estimation 3D ou l’ancrage symbolique, plutôt que de définir une structure unifiée ou un cadre général. Bien que ces intégrations spécifiques à des tâches permettent d’améliorer les performances, elles manquent souvent de cohérence systématique nécessaire à une compréhension holistique du monde. Dans ce papier, nous analysons les limites de ces approches fragmentées et proposons une spécification de conception unifiée pour les modèles du monde. Nous suggérons qu’un modèle du monde robuste ne doit pas être une collection désordonnée de capacités, mais un cadre normatif intégrant de manière intrinsèque l’interaction, la perception, le raisonnement symbolique et la représentation spatiale. Ce travail vise à offrir une perspective structurée afin de guider les recherches futures vers des modèles du monde plus généraux, plus robustes et fondés sur des principes rigoureux.
One-sentence Summary
The authors from multiple institutions propose a unified framework for world models, integrating interaction, perception, symbolic reasoning, and spatial representation to overcome fragmented task-specific approaches, aiming to guide AI toward more general and principled environmental understanding.
Key Contributions
- The paper identifies a critical fragmentation in current world model research, where methods focus on injecting world knowledge into isolated tasks like visual prediction or 3D estimation, leading to performance gains but lacking systematic coherence for holistic world understanding.
- It proposes a unified design specification for world models, defining them as normative frameworks that integrally combine interaction, perception, symbolic reasoning, and spatial representation to enable agents to actively understand and respond to complex environments.
- Through analysis of LLMs, video generation, and embodied AI systems, the work demonstrates the limitations of task-specific approaches and outlines essential components—Interaction, Reasoning, Memory, Environment, and Multimodal Generation—to guide future development toward general, robust world simulation.
Introduction
The authors leverage the growing interest in world models—systems designed to simulate physical dynamics and enable agents to interact intelligently with complex environments—to critique the current fragmented research landscape. Most existing approaches inject world knowledge into isolated tasks like video generation or 3D estimation, relying on task-specific data and fine-tuning, which yields short-term performance gains but fails to produce coherent, physics-aware understanding or long-term consistency. Their main contribution is a unified design specification for world models that integrates interaction, perception, reasoning, memory, and multimodal generation into a normative framework, aiming to guide future research toward general, robust, and principled models capable of active exploration and real-world adaptation.
Method
The authors leverage a unified world model framework designed to overcome the fragmentation of task-specific models by integrating perception, reasoning, memory, interaction, and generation into a cohesive, closed-loop architecture. This framework is structured around five core modules, each addressing a critical capability required for holistic world understanding and adaptive interaction.
The interaction module serves as the unified perceptual and operational interface between users, the environment, and the model. It accepts multimodal inputs—including text, images, video, audio, and 3D point clouds—and processes diverse operational signals such as natural language instructions, embodied commands, or low-level motion controls. As shown in the figure below, this module unifies the encoding and scheduling of heterogeneous data streams to produce structured input for downstream components.
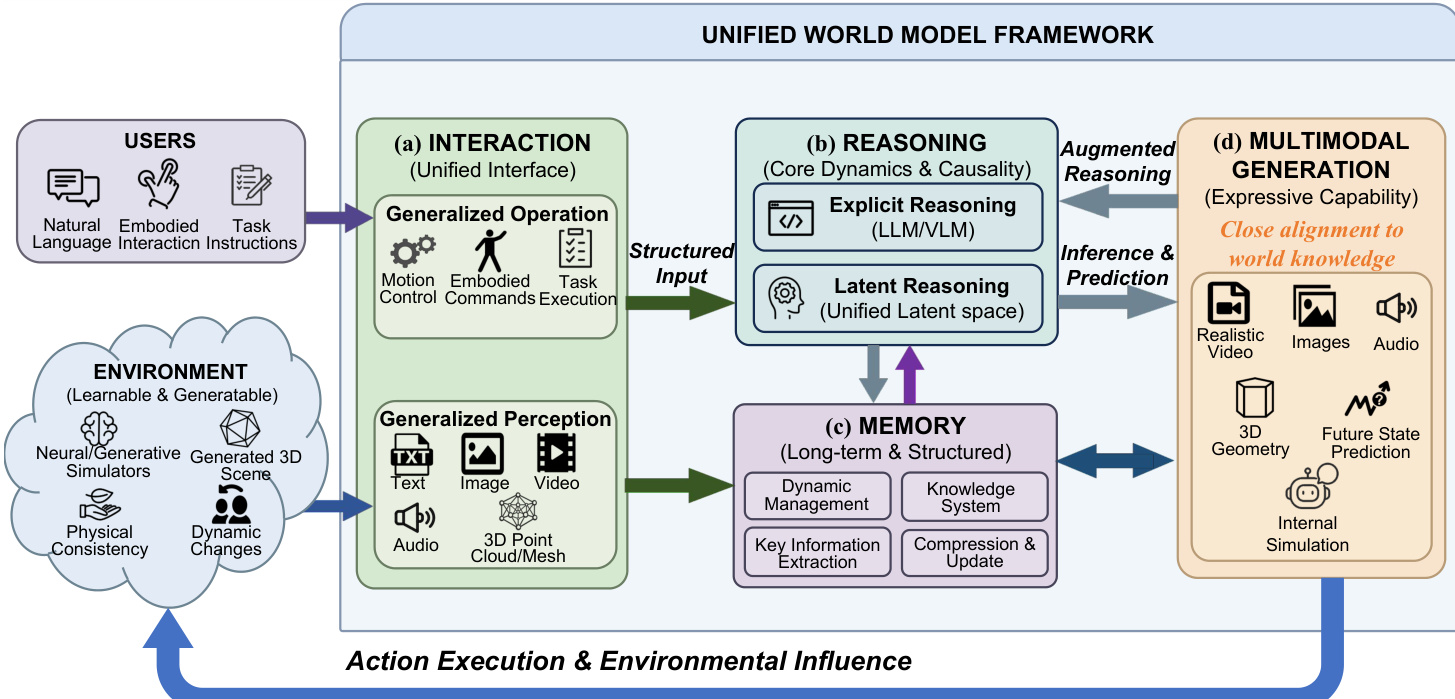
The reasoning module is responsible for inferring dynamics and causality from the structured inputs. It supports two complementary paradigms: explicit reasoning, which leverages LLMs/VLMs to generate textual reasoning chains for symbolic planning and physical law inference; and latent reasoning, which operates directly in a unified latent space to preserve sub-symbolic, continuous physical details. The module dynamically selects or combines these approaches based on task requirements, ensuring both interpretability and fidelity in complex scenarios.
Memory is implemented as a structured, dynamic knowledge system capable of managing multimodal, high-concurrency interaction streams. It extends beyond sequential storage by incorporating mechanisms for categorization, association, and fusion of experiential data. The memory module also performs key information extraction and compression to maintain efficiency, while continuously updating and purging redundant content to preserve relevance and timeliness.
The environment component is not merely a passive simulator but an active, learnable, and generative entity. It supports both physical and simulated interactions, with an emphasis on generative 3D scene synthesis and procedural content creation to bridge the sim-to-real gap. This enables training on near-infinite, physically consistent environments, enhancing the model’s generalization to open-world scenarios.
Finally, multimodal generation enables the model to synthesize realistic outputs—including video, images, audio, and 3D geometry—based on internal states and predictions. This capability is tightly coupled with reasoning and memory, forming a closed loop where generated content supports planning, self-augmentation, and verification of world understanding. For example, in navigation tasks, the model can generate a 3D scene from the agent’s perspective to simulate and validate its strategy before execution.
Together, these modules form a tightly integrated system that continuously perceives, reasons, remembers, acts, and generates, enabling robust, adaptive, and human-aligned interaction with complex, dynamic environments.