Command Palette
Search for a command to run...
TTCS : Synthèse de programme d'apprentissage en temps de test pour l'évolution autonome
TTCS : Synthèse de programme d'apprentissage en temps de test pour l'évolution autonome
Chengyi Yang Zhishang Xiang Yunbo Tang Zongpei Teng Chengsong Huang Fei Long Yuhan Liu Jinsong Su
Résumé
L’apprentissage à l’époque de test (Test-Time Training, TTT) offre une voie prometteuse pour améliorer la capacité de raisonnement des grands modèles linguistiques (LLM) en adaptant le modèle à l’aide uniquement des questions de test. Toutefois, les méthodes existantes peinent face aux problèmes de raisonnement complexes pour deux raisons principales : les questions de test brutes sont souvent trop difficiles pour produire des pseudo-étiquettes de haute qualité, et la taille limitée des jeux de test rend les mises à jour en continu en ligne sujettes à une instabilité. Pour surmonter ces limitations, nous proposons TTCS, un cadre d’apprentissage à l’époque de test à évolution co-intrinsèque. Plus précisément, TTCS initialise deux politiques à partir d’un même modèle pré-entraîné : un générateur de questions et un solveur de raisonnement. Ces deux politiques évoluent par optimisation itérative : le générateur produit progressivement des variantes de questions de plus en plus complexes conditionnellement aux questions de test, créant ainsi un curriculum structuré adapté au niveau actuel du solveur, tandis que le solveur s’actualise lui-même grâce à des récompenses de cohérence interne calculées à partir de plusieurs réponses échantillonnées sur les questions originales et les questions synthétiques. De manière cruciale, les retours du solveur guident le générateur à produire des questions alignées avec le niveau actuel du modèle, et les variantes de questions générées stabilisent à leur tour l’apprentissage en temps de test du solveur. Des expériences montrent que TTCS renforce de manière cohérente la capacité de raisonnement sur des benchmarks mathématiques exigeants et se transfère à des tâches générales sur différentes architectures de LLM, mettant ainsi en évidence une voie évolutivement scalable pour la construction dynamique de curricula en temps de test destinés à des modèles auto-évoluant. Notre code et les détails d’implémentation sont disponibles à l’adresse suivante : https://github.com/XMUDeepLIT/TTCS.
One-sentence Summary
Researchers from Xiamen University, Washington University in St. Louis, and Renmin University propose TTCS, a co-evolving test-time training framework that dynamically generates tailored question variants to stabilize and enhance LLM reasoning, outperforming prior methods on math and general benchmarks through self-consistent feedback loops.
Key Contributions
- TTCS addresses key limitations in test-time training for complex reasoning by tackling unreliable pseudo-labels and sparse learnable samples, which hinder effective adaptation on difficult questions like those in AIME24.
- The framework introduces a co-evolving pair of policies—a synthesizer that generates capability-aligned question variants and a solver that updates via self-consistency rewards—optimized iteratively using GRPO to stabilize and guide self-evolution.
- Experiments demonstrate consistent gains on challenging mathematical benchmarks and general-domain tasks across multiple LLM backbones, validating TTCS as a scalable method for dynamic curriculum construction at test time.
Introduction
The authors leverage test-time training to enhance large language models’ reasoning without external labels, but existing methods falter on hard problems due to unreliable pseudo-labels and sparse, overly difficult test samples. Prior approaches like TTRL rely on majority voting, which often reinforces wrong answers when models struggle, and lack intermediate training steps to bridge capability gaps. TTCS introduces a co-evolving framework with two policies—a synthesizer that generates curriculum-aligned question variants and a solver that updates via self-consistency rewards—creating a dynamic, capability-matched training loop that stabilizes learning and improves performance on challenging math and general reasoning tasks.
Dataset

The authors use a diverse set of benchmarks to evaluate reasoning and generalization capabilities, organized into three categories:
-
Competition-Level Mathematics:
- AMC23: Problems from the American Mathematics Competitions, used to identify mathematical talent.
- AIME24&25: 2024 and 2025 versions of the American Invitational Mathematics Examination, selected for their multi-step reasoning demands.
-
Standard Mathematical Benchmarks:
- MATH-500: A curated 500-problem subset of the MATH dataset for efficient evaluation of core math problem-solving.
- Minerva: A broad collection of STEM problems spanning multiple difficulty levels.
- OlympiadBench: A comprehensive set of Olympiad-level problems from international competitions.
-
General-Domain Benchmarks:
- BBEH: Big Bench Extra Hard, targeting tasks where language models typically underperform.
- MMLU-Pro: A challenging multi-task benchmark stressing advanced language understanding and reasoning.
- SuperGPQA: Graduate-level questions designed to scale LLM evaluation across complex domains.
The paper does not specify training splits, mixture ratios, or preprocessing steps for these datasets — they are used exclusively for evaluation. No cropping, metadata construction, or dataset-specific processing is described.
Method
The authors leverage a co-evolving test-time training framework called Test-Time Curriculum Synthesis (TTCS), which integrates two distinct but interdependent agents: a Synthesizer policy and a Solver policy. Both agents are initialized from the same pretrained language model and iteratively refine each other through a closed-loop optimization process grounded in Group Relative Policy Optimization (GRPO). The overall architecture is designed to dynamically adapt the solver to the test distribution by generating capability-aligned synthetic questions that serve as curriculum variants, while simultaneously training the solver to self-evolve using self-supervised signals derived from its own outputs.
As shown in the framework diagram, the Synthesizer is responsible for generating synthetic questions conditioned on each test question. This is achieved via a structured prompt template that enforces semantic preservation of the original reasoning structure while varying surface-level elements such as objects, settings, or constraints. The generated synthetic questions are then evaluated by the Solver, which samples multiple responses per question and computes a self-consistency score based on majority voting. This score serves as a proxy for the question’s difficulty relative to the solver’s current capability. The Synthesizer is then updated via GRPO using a composite reward function that combines a capability-adaptive component—peaked at self-consistency scores near 0.5, where learning signals are maximized—with similarity penalties that discourage redundancy and near-duplicate generation. This ensures the synthesizer progressively shifts its output distribution toward questions that lie at the solver’s capability frontier, balancing learnability with novelty.
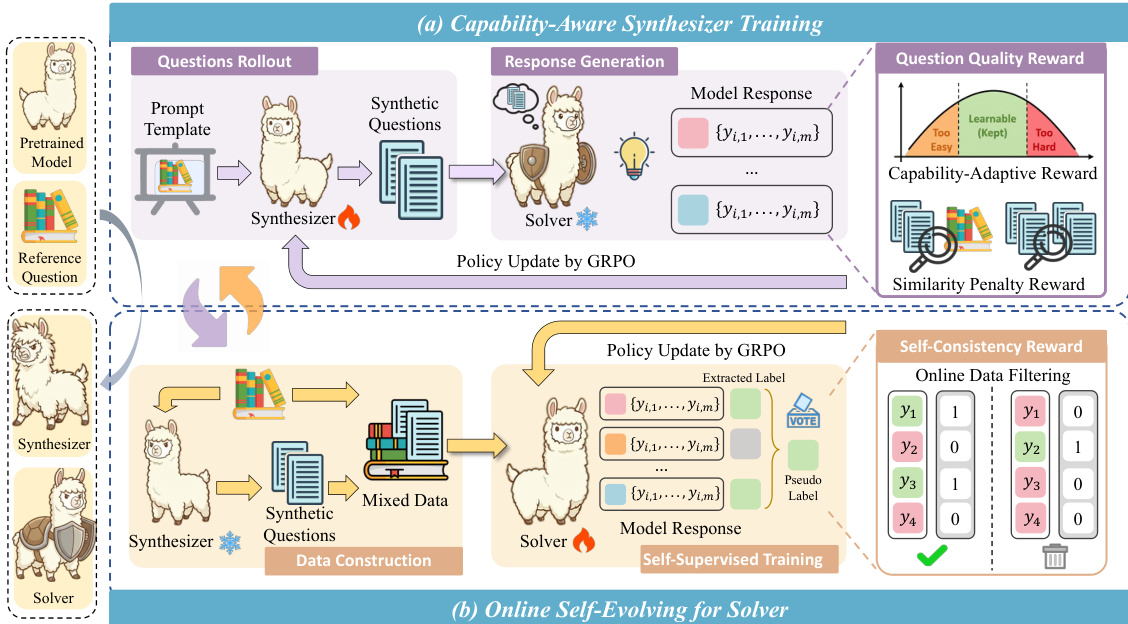
Concurrently, the Solver is trained on a mixed dataset comprising both original test questions and synthetic variants generated by the Synthesizer. At each iteration, the Solver samples multiple responses per question and derives pseudo-labels via majority voting. A binary self-consistency reward is assigned to each response based on agreement with the consensus. To ensure training stability and prevent degeneration, an online filtering mechanism retains only those questions whose self-consistency scores fall within a narrow band around 0.5, effectively selecting samples that provide maximal gradient signal under GRPO. The Solver is then updated via GRPO using these filtered, self-supervised rewards, allowing it to incrementally master increasingly challenging variants while remaining grounded in the original test distribution. The iterative nature of this process ensures that the Synthesizer’s curriculum adapts to the Solver’s evolving proficiency, creating a feedback loop that drives continuous improvement without access to ground-truth labels.
Experiment
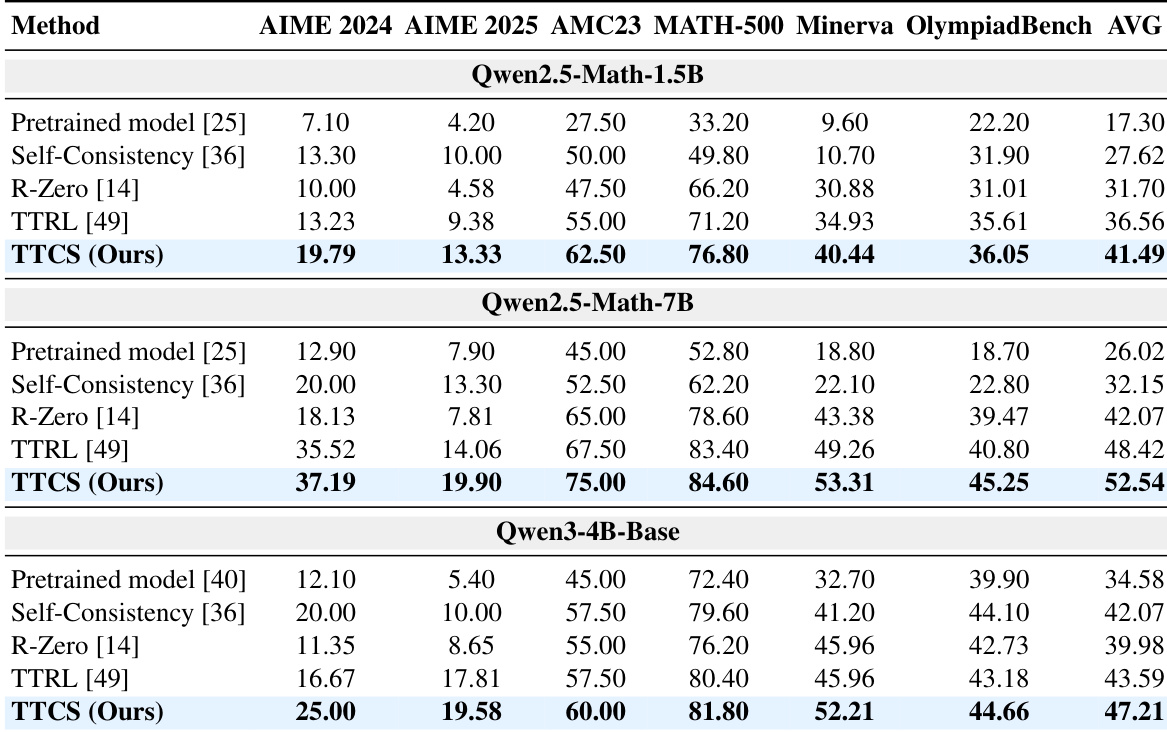
- TTCS significantly boosts reasoning performance across math benchmarks, outperforming static models, self-consistency, and test-time training methods like TTRL and R-Zero, especially on challenging tasks such as AIME24/25.
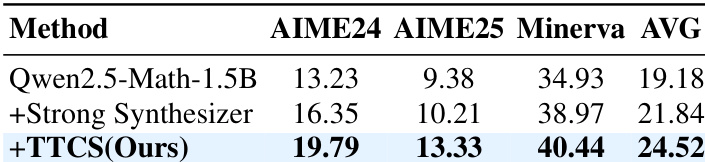
- The framework’s co-evolutionary design—where a synthesizer dynamically generates curriculum-aligned problems—proves more effective than using a stronger but static question generator, highlighting the value of adaptive training.
- TTCS generalizes well beyond its training domain, improving performance on general reasoning benchmarks (e.g., MMLU-Pro, SuperGPQA) and unseen math datasets, indicating acquisition of transferable reasoning logic.
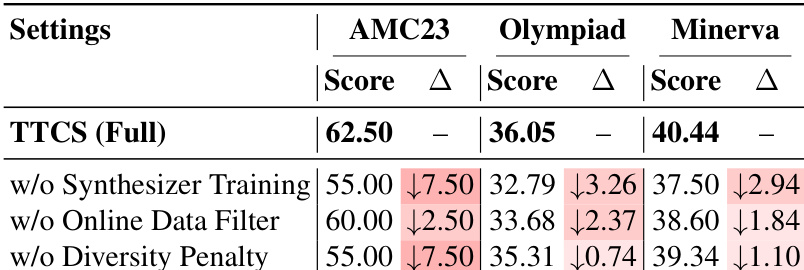
- Ablation studies confirm that dynamic synthesizer training, online data filtering, and diversity penalties are essential for effective self-evolution; removing any component degrades performance.
- TTCS remains effective with limited test data, amplifying sparse supervision through synthesized curriculum, and demonstrates progressive improvement in question complexity and diversity over training iterations.
The authors use TTCS to enhance mathematical reasoning by dynamically generating curriculum questions during test time, leading to substantial performance gains over static and self-consistency baselines. Results show that TTCS significantly improves accuracy on challenging benchmarks like AIME24 and AIME25, even when starting from smaller models, by adapting question difficulty and diversity to the solver’s evolving capabilities. The method outperforms stronger static synthesizers, confirming that adaptive co-evolution is more critical than raw model size for effective test-time learning.
The authors use TTCS to dynamically generate and refine training questions during test time, enabling the model to adapt its reasoning capabilities progressively. Results show that removing key components—such as synthesizer training, online data filtering, or diversity penalties—consistently degrades performance across benchmarks, confirming that each element contributes meaningfully to the framework’s effectiveness. This indicates that adaptive curriculum design and selective data curation are critical for sustained improvement in test-time self-evolution.
The authors use TTCS to dynamically generate and refine intermediate problems during test time, enabling models to progressively improve their reasoning capabilities beyond static baselines. Results show consistent and substantial gains across multiple model sizes and mathematical benchmarks, particularly on challenging tasks like AIME, where TTCS outperforms methods relying solely on test-set pseudo-labels. The framework’s co-evolutionary design, which adapts question difficulty and diversity in real time, proves more effective than using stronger but static synthesizers or passive inference-time scaling.