Command Palette
Search for a command to run...
Youtu-VL : Libérer le potentiel visuel grâce à une supervision unifiée vision-langage
Youtu-VL : Libérer le potentiel visuel grâce à une supervision unifiée vision-langage
Résumé
Malgré les progrès significatifs réalisés par les modèles vision-langage (VLM), les architectures actuelles présentent souvent des limites dans la conservation des informations visuelles fines, entraînant une compréhension multimodale de résolution grossière. Nous attribuons cette faiblesse à un paradigme d’entraînement sous-optimal inhérent aux VLM dominants, qui manifeste un biais d’optimisation dominé par le texte en concevant les signaux visuels non pas comme des cibles de supervision, mais comme des entrées conditionnelles passives. Pour atténuer ce problème, nous proposons Youtu-VL, un cadre fondé sur le paradigme de supervision autoregressive unifiée vision-langage (VLUAS), qui repense fondamentalement l’objectif d’optimisation, passant de « vision comme entrée » à « vision comme cible ». En intégrant directement les tokens visuels dans le flux de prédiction, Youtu-VL applique une supervision autoregressive unifiée aussi bien aux détails visuels qu’au contenu linguistique. En outre, nous étendons ce paradigme à des tâches centrées sur la vision, permettant à un VLM standard de mener à bien des tâches visuelles sans nécessiter d’ajouts spécifiques à la tâche. Des évaluations empiriques étendues montrent que Youtu-VL atteint des performances compétitives tant sur des tâches multimodales générales que sur des tâches centrées sur la vision, établissant ainsi une base solide pour le développement d’agents visuels généralistes complets.
One-sentence Summary
The Youtu-VL team introduces Youtu-VL, a vision-language model that shifts from text-dominant to unified autoregressive supervision, treating visual tokens as prediction targets to preserve fine-grained details and enable standard architectures to perform vision-centric tasks without task-specific modules, achieving competitive performance across multimodal and dense perception benchmarks.
Key Contributions
- Youtu-VL addresses the text-dominant optimization bias in Vision-Language Models by introducing Vision-Language Unified Autoregressive Supervision (VLUAS), which treats visual tokens as predictive targets rather than passive inputs to recover fine-grained visual understanding.
- The framework enables standard VLM architectures to natively perform vision-centric tasks without task-specific modules by integrating visual and linguistic prediction into a single autoregressive stream, expanding functional scope while maintaining architectural simplicity.
- Empirical evaluations show Youtu-VL achieves competitive performance across general multimodal and vision-centric benchmarks, demonstrating that unified supervision supports comprehensive generalist visual agent capabilities without auxiliary heads or decoders.
Introduction
The authors leverage a unified autoregressive supervision paradigm to address the text-dominant bias in existing Vision-Language Models, which often treat visual inputs as passive cues rather than predictive targets. Prior models struggle to retain fine-grained visual detail and require task-specific modules for vision-centric tasks, limiting their generality. Youtu-VL restructures training to predict visual tokens alongside text, enabling a single architecture to handle both multimodal and vision-only tasks competitively—without auxiliary heads—while laying groundwork for generalist visual agents.
Dataset

The authors use a multimodal dataset composed of vision-centric, captioning, OCR, STEM, and GUI data, sourced from open datasets, internal collections, and synthetic pipelines. Below is a concise breakdown:
-
Vision-Centric Data
- Combines open-source datasets (e.g., RefCOCO, ADE20K, Cityscapes) with synthetic data generated via automated annotation and LLM-augmented pipelines.
- Tasks include grounding, detection, segmentation, pose estimation, and depth estimation.
- For segmentation, masks are mapped to text labels and tokenized; invalid regions are ignored during loss.
- Depth data uses linear or log-uniform quantization (1–1000 bins); labels are dequantized for evaluation.
- Augmentations include random cropping, padding, resizing, color jitter, and cutout; some tasks use 1.2x padding + 1280px resize for segmentation.
- Open-world synthesis uses two branches: detection/segmentation (via grounding models + data binding) and depth (via pseudo-labeling + quantization). Copy-paste strategy places transparent objects on backgrounds.
-
Image Caption & Knowledge Data
- Starts with 5T tokens from open-source image-text pairs, filtered via CLIP scores, NSFW removal, and resolution checks.
- Enhanced via:
- Concept-balanced sampling using bilingual ontology and CLIP retrieval for general concepts, keyword matching for named entities.
- Rare class mining via JEPA-based semantic density scores to capture long-tail examples.
- Knowledge-injected recaptioning: LLMs rewrite sparse captions into dense, grounded descriptions.
- Final dataset: 1T tokens after MD5 deduplication and repetition filtering.
-
OCR Data
- Combines human-labeled datasets with synthetic data from PDFs, charts, and text corpora.
- Synthesis pipeline:
- LLMs generate diverse questions; VLMs produce detailed, step-by-step answers.
- Logic-consistency refinement: LLMs validate reasoning; VLMs regenerate opaque responses.
- Rendering engine adds typographical noise, backgrounds, blur, and affine transforms to simulate real-world conditions.
-
STEM Data
- Covers diagrams, charts, physics, chemistry, and engineering schematics.
- Three-stage pipeline:
- Multi-dimensional filtering (visual relevance, answer correctness, reasoning completeness).
- Synthesis + consistency verification: VLMs regenerate answers; LLMs verify alignment or enforce invariance across perturbed queries.
- Visual-grounded question expansion: Fine-tuned VLM predicts questions from images + answers; LLMs extract entities from captions to generate educational queries.
- Simulates real-world use via dynamic text rendering onto images.
-
GUI Data
- Dual-stream pipeline:
- Single-turn grounding: Aggregates open-source UI datasets; filtered via LLM-as-judge ensemble for label correctness.
- Long-horizon trajectories: Synthesized via sandbox systems across desktop/mobile/web; privacy-controlled.
- Reward-guided hybrid verification: Top trajectories undergo human annotation; rest used for continual pre-training.
- Dual-stream pipeline:
-
SFT & RL Data Curation
- SFT: High-quality samples mined from pre-training corpus via VLM scoring + keyword taxonomy balancing; open-source datasets rewritten by VLMs into paragraph-level responses.
- RL:
- Task categorization into vision, STEM, OCR, VQA, instruction-following.
- Verifiability-driven filtering: Prioritizes objective, deterministic samples; excludes multiple-choice/true-false.
- Consensus-based QA validation using multiple models.
- Complexity calibration: Discards samples where 8 SFT model responses are all correct.
-
Processing & Metadata
- Grounding: Uses bounding box or polygon outputs; open-world prompts support flexible phrasing in English/Chinese.
- Segmentation: Labels shuffled per image; RLE-encoded masks; post-processing via DenseCRF or sigmoid + threshold (for open sets).
- Depth: Prompt precedes image; quantized bins dequantized to real depth; focal length normalized to 2000px.
- All data undergoes task-specific augmentations; cropping and resizing vary by task and resolution.
Method
The authors leverage a novel framework, Youtu-VL, built upon the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally reorients the training objective from a text-dominant approach to a generative unification of vision and language. This paradigm shift treats visual signals not as passive inputs conditioned on text, but as active targets for autoregressive prediction, thereby mitigating the text-dominant optimization bias that typically leads to the loss of fine-grained visual details. The core architecture, as illustrated in the framework diagram, integrates a vision encoder, a vision-language projector, and a large language model (LLM) to form a unified system. The vision encoder, based on SigLIP-2, processes images at native resolution and employs 2D Rotary Position Embedding (RoPE) and window attention for efficient and spatially aware feature extraction. Its output is then compressed and projected into the LLM's token space by a Spatial Merge Projector, which concatenates adjacent 2×2 patch features and applies a two-layer MLP. The LLM, a self-developed Youtu-LLM, is extended to incorporate a unified vision-language vocabulary. This is achieved through a multi-stage training process where a specialized Synergistic Vision Tokenizer is first trained to construct a visual codebook, forming the visual portion of the unified vocabulary Vunified. This tokenizer fuses high-level semantic concepts from SigLIP-2 with low-level geometric structures from DINOv3 using a cross-attention mechanism, ensuring the resulting discrete codes preserve both semantic and spatial information. The unified autoregressive objective, LVLUAS, is then applied, which is a weighted sum of textual and visual prediction losses, enabling the model to simultaneously reconstruct both linguistic and visual content. 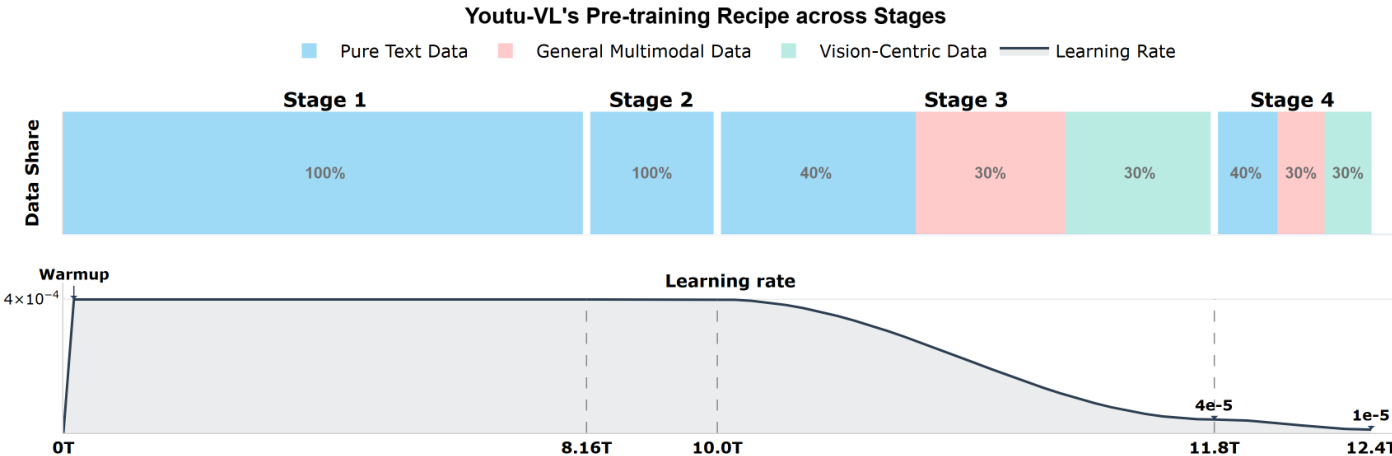
The framework's design enables vision-centric predictions from a standard architecture without task-specific modules. For text-based prediction tasks like object detection and visual grounding, the model generates precise bounding boxes directly as textual tokens using an axis-specific vocabulary with absolute pixel coordinates, eliminating the need for normalization. For dense prediction tasks such as semantic segmentation and depth estimation, the model leverages its native logit representations. The authors propose a multi-label next-token prediction (NTP-M) objective to supervise these tasks. This approach models the probability of each token in the vocabulary independently, allowing for multi-label supervision where a single image patch can be associated with multiple semantic labels and tasks. To address the severe class imbalance inherent in such a large vocabulary, a robust NTP-M loss is employed that decouples positive and negative sample processing. It calculates the mean loss for all valid positive samples and computes the average loss only for the top-k relevant negative samples, ranked by their predicted probabilities, to prevent gradient dilution and enhance convergence. 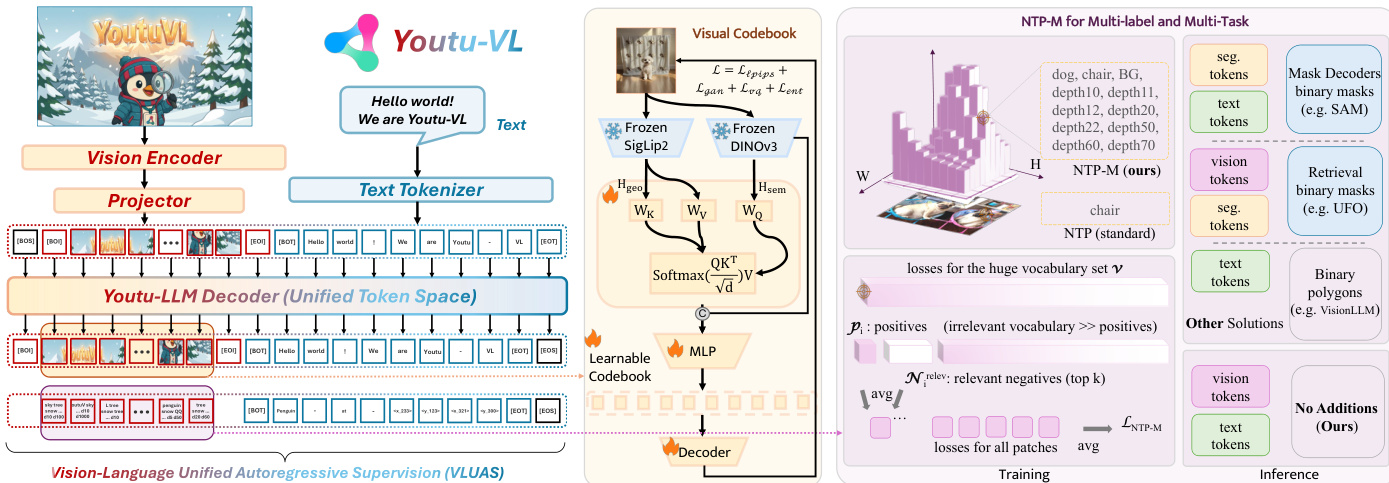
The training process follows a progressive, four-stage recipe. Stages 1 and 2 focus on language backbone pre-training using pure text data to establish a strong linguistic foundation. Stage 3, multimodal foundation pre-training, introduces a diverse mixture of image-caption pairs and vision-centric data, training all components end-to-end to acquire broad world knowledge and cross-modal understanding. Stage 4, versatile task adaptation, specializes the model on a wide range of tasks using a high-quality multimodal instruction dataset, enabling it to generalize effectively to diverse user instructions. This pipeline is supported by a dual-stream supervision strategy during Stages 3 and 4, combining the autoregressive visual reconstruction loss for general multimodal data with the specialized NTP-M loss for vision-centric data. 
Experiment
- VLUAS pre-training paradigm outperforms text-dominant baselines across 27 multimodal benchmarks, avoiding early saturation and achieving superior data efficiency in Stages 3 and 4.
- Scaling analysis on 2.4T tokens confirms VLUAS follows neural scaling laws (α ≈ 0.102 in Stage 3, α ≈ 0.079 in Stage 4), with performance rising from 0.43 to >0.74 average score.
- Vision token supervision enhances visual representation quality, yielding sharper object separation and semantic structure in PCA visualizations compared to models without such supervision.
- On vision-centric tasks, Youtu-VL achieves 91.8% avg on RefCOCO (vs. 89.4% InternVL-3.5-4B), 47.1% mAP on COCO detection (vs. 46.7% GiT), and 54.2 mIoU on ADE20K segmentation (vs. 47.8% GiT).
- In dense prediction, Youtu-VL attains 90.4 δ1 on NYUv2 depth estimation (vs. 86.8% DepthLLM-3B) and 80.7% mIoU on RefCOCO referring segmentation (vs. 80.0% UFO).
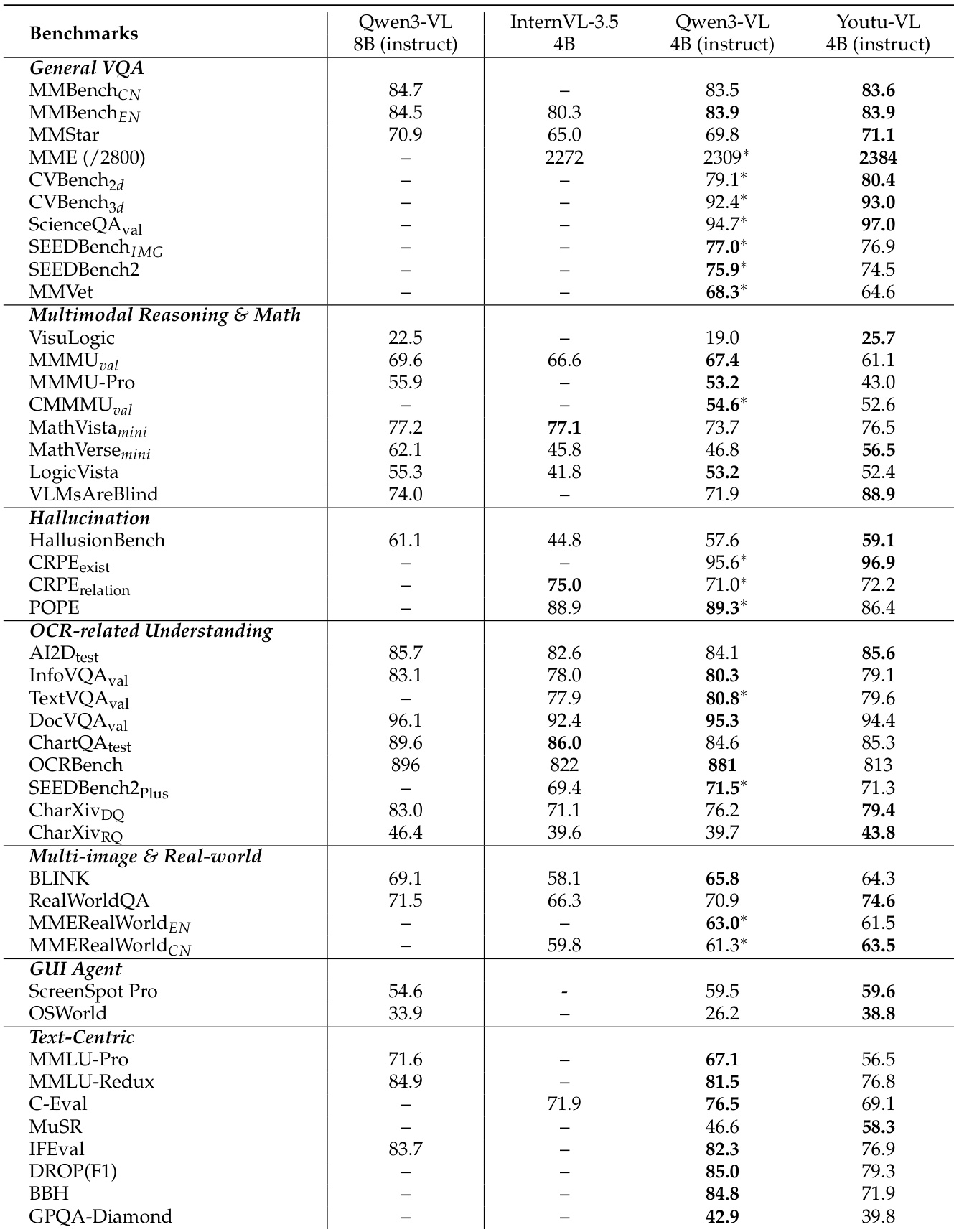
- On general multimodal tasks, Youtu-VL scores 83.9 on MMBench-EN, 88.9% on VLMs Are Blind, 56.5% on MathVerse, and 74.6 on RealWorldQA, outperforming peers in hallucination suppression (59.1% on HallusionBench).
- GUI agent evaluation shows SoTA 38.8% success rate on OSWorld, demonstrating robust grounding-to-action mapping and error resilience in multi-turn computer use.
- Youtu-VL matches or exceeds specialist models in object counting (88.6% on CountBench), pose estimation (89.1% [email protected] on MPII), and classification (89.3% Top-1 on ImageNet-ReaL), without task-specific heads or fine-tuning.
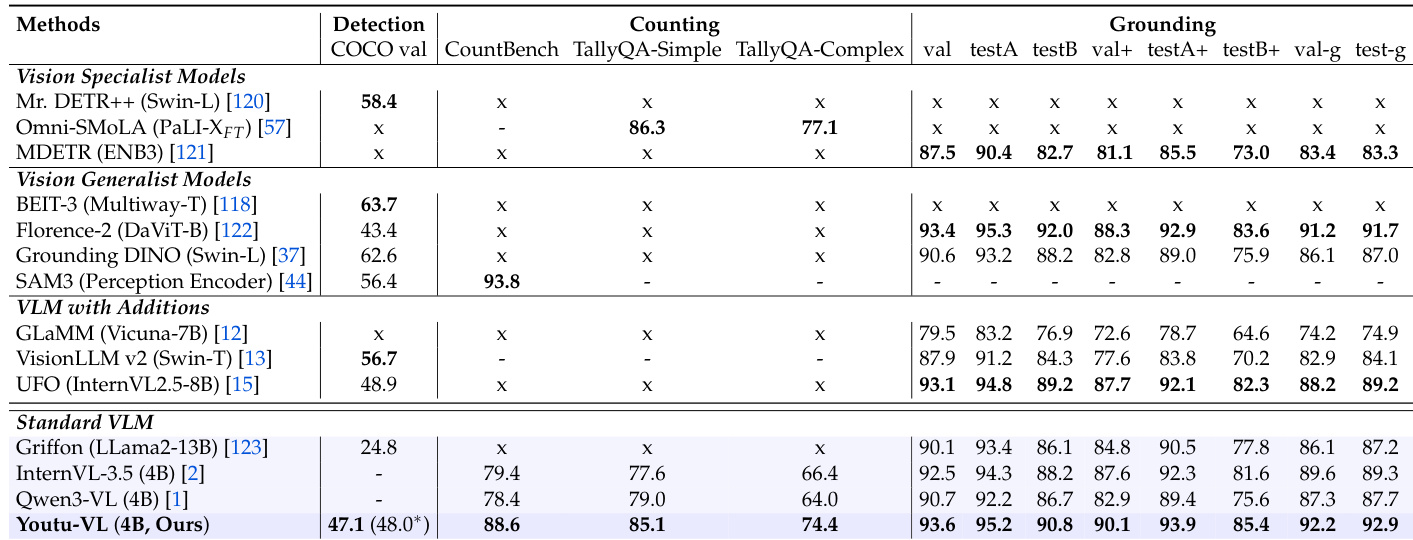
The authors compare Youtu-VL against various vision specialist, generalist, and multimodal models across detection, counting, and grounding tasks. Results show that Youtu-VL achieves competitive performance in detection (47.1 mAP on COCO) and leads in counting (88.6 on CountBench), while also outperforming many models in grounding tasks, particularly on RefCOCO splits.
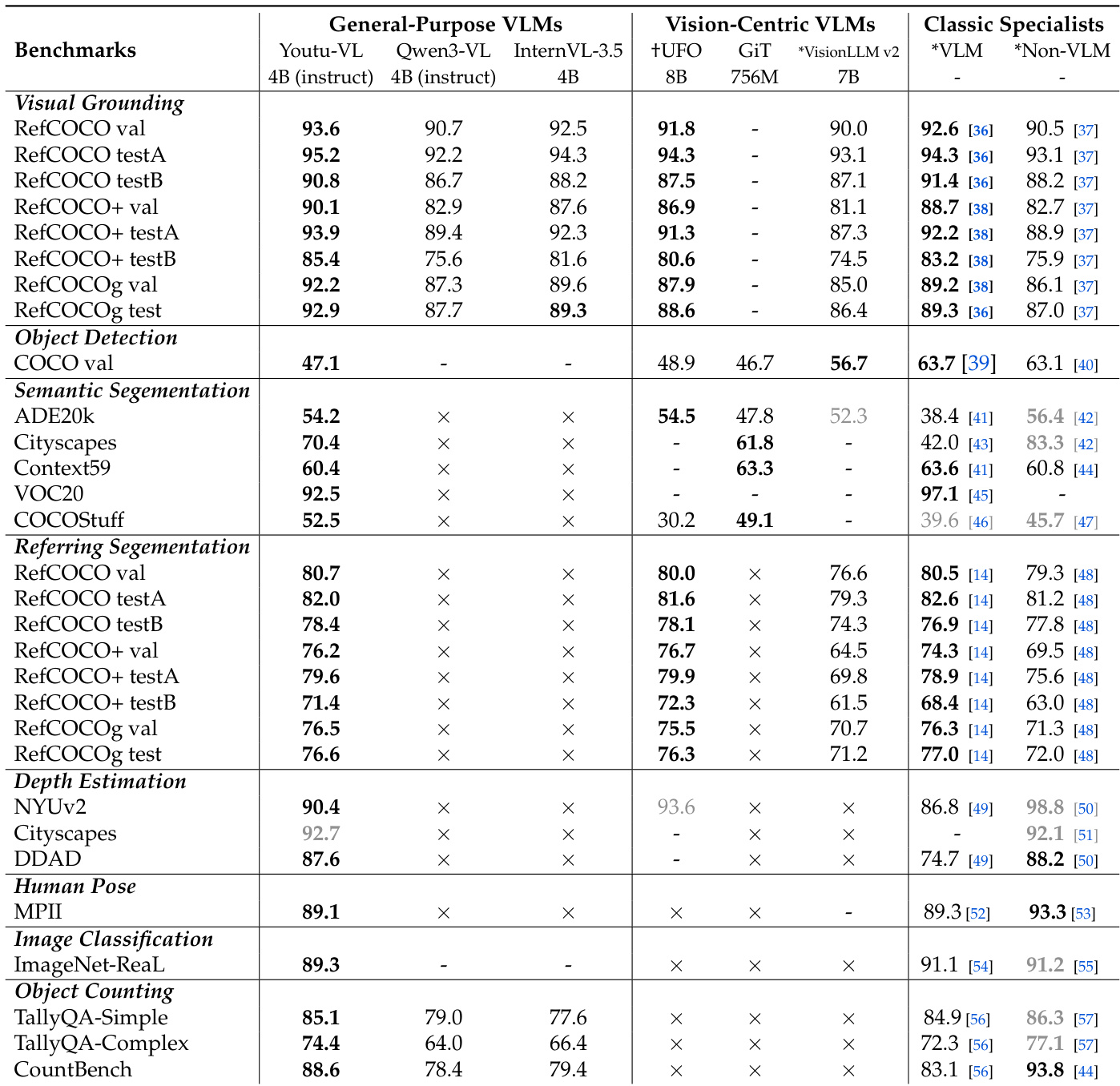
The authors use a comprehensive evaluation framework to compare Youtu-VL against general-purpose VLMs, vision-centric VLMs, and classic specialists across a wide range of vision-centric tasks. Results show that Youtu-VL achieves state-of-the-art or competitive performance in tasks such as visual grounding, object detection, semantic segmentation, and depth estimation, while demonstrating strong capabilities in object counting and human pose estimation. The model outperforms or matches specialized models in many areas, particularly in dense prediction tasks where most general-purpose VLMs are not applicable, highlighting its versatility and effectiveness as a unified vision-language model.
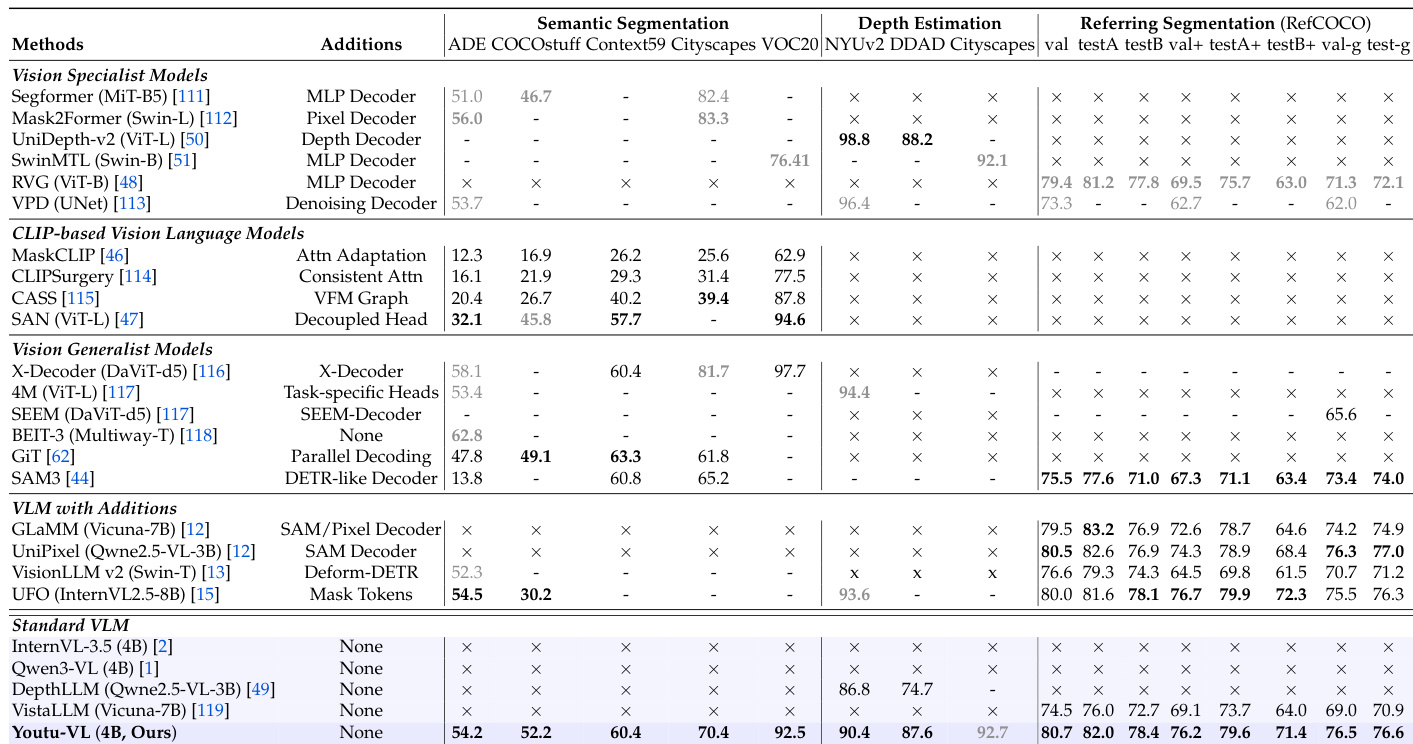
The authors use a comprehensive evaluation framework to compare Youtu-VL against various vision-centric and generalist models across dense prediction tasks. The table shows that Youtu-VL achieves strong performance in semantic segmentation and depth estimation without requiring task-specific additions like extra decoders or tokens, outperforming many vision generalist and CLIP-based models. This indicates that Youtu-VL effectively leverages its standard VLM architecture to handle complex visual tasks, demonstrating both versatility and high capability in dense prediction.
The authors use a comprehensive evaluation framework to compare Youtu-VL against state-of-the-art models across a wide range of multimodal tasks. Results show that Youtu-VL achieves competitive or superior performance on most benchmarks, particularly excelling in vision-centric tasks such as visual grounding, object detection, and semantic segmentation, while also demonstrating strong capabilities in multimodal reasoning, OCR, and GUI agent tasks.