Command Palette
Search for a command to run...
Vers une Perception VLM au Niveau de Pixél par Prédiction Simple de Points
Vers une Perception VLM au Niveau de Pixél par Prédiction Simple de Points
Résumé
Nous présentons SimpleSeg, une approche remarquablement simple mais extrêmement efficace pour doter les Modèles Linguistiques Multimodaux de Grande Échelle (MLLM) d'une perception native au niveau des pixels. Notre méthode reformule la segmentation comme un problème simple de génération de séquences : le modèle prédit directement des séquences de points (coordonnées textuelles) définissant les contours des objets, entièrement dans son espace linguistique. Pour garantir une fidélité élevée, nous introduisons un pipeline d'entraînement en deux étapes basé sur le SFoRL, où l'apprentissage par renforcement, récompensé par un score d'intersection sur union (IoU), affine les séquences de points afin qu'elles correspondent précisément aux contours de référence. Nous constatons que l'architecture standard des MLLM possède une capacité intrinsèque forte pour la perception de bas niveau, qui peut être libérée sans recourir à une architecture spécialisée. Sur des benchmarks de segmentation, SimpleSeg atteint des performances comparables, voire souvent supérieures, à celles des méthodes reposant sur des conceptions complexes et spécifiques à la tâche. Ce travail démontre que la compréhension spatiale précise peut émerger à partir d'une simple prédiction de points, remettant en question la nécessité prévalente de composants auxiliaires et ouvrant la voie à des VLM (Modèles Visuels et Linguistiques) plus unifiés et performants. Page d'accueil : https://simpleseg.github.io/
One-sentence Summary
Researchers from Moonshot AI and Nanjing University propose SimpleSeg, a minimalist method enabling MLLMs to perform pixel-level segmentation via point-sequence prediction in language space, enhanced by SFT→RL training with IoU reward, outperforming complex architectures and demonstrating that spatial understanding emerges naturally from standard models.
Key Contributions
- SimpleSeg enables MLLMs to perform pixel-level segmentation by predicting sequences of textual coordinates that outline object boundaries, eliminating the need for specialized decoders or auxiliary components while operating entirely within the language space.
- The method introduces a two-stage SFT→RL training pipeline, where reinforcement learning with an IoU-based reward refines point sequences to match ground-truth contours, unlocking the MLLM’s latent capacity for fine-grained perception without architectural changes.
- On benchmarks like refCOCO, SimpleSeg matches or exceeds the performance of complex, task-specific approaches, demonstrating strong generalization across domains and resolutions while preserving interpretability and compositional reasoning.
Introduction
The authors leverage standard Multimodal Large Language Models (MLLMs) to achieve pixel-level segmentation by treating it as a sequence generation task—predicting textual coordinates that trace object boundaries, all within the model’s native language space. Prior methods either add complex, task-specific decoders that break architectural unity or serialize masks as text, which sacrifices resolution and interpretability. SimpleSeg’s main contribution is a minimalist, decoder-free approach that unlocks high-fidelity perception through a two-stage SFT→RL training pipeline, using IoU-based rewards to refine point sequences. This reveals that MLLMs inherently possess fine-grained spatial reasoning capabilities, which can be activated without architectural modifications, enabling unified, interpretable, and generalizable pixel-level understanding across diverse visual domains.
Dataset

- The authors use large-scale open-source and web data for pre-training, primarily LAION and Coyo, with all samples annotated via their pipeline from Section 3.1.
- For SFT, they build an 800k-sample dataset from the train splits of refCOCO, refCOCO+, refCOCOg, and refCLEF, following Text4Seg’s processing protocol.
- For RL, they derive a 400k-sample prompt set from the same RefCOCO series, maintaining consistent data sourcing.
- All benchmark results in Tables 1 and 2 use models trained only on SFT and RL stages (RefCOCO datasets), to ensure fair comparison with SOTA methods.
- Pre-training with web data (LAION/Coyo) is reserved for scaling and ablation analysis, shown in Table 3.
- Metadata includes image-level descriptions paired with polygon coordinates, as shown in the SimpleSeq example: object descriptions followed by pixel-accurate polygon lists.
Method
The authors leverage a simple yet effective framework, SimpleSeg, which equips a vanilla multimodal large language model (MLLM) with native pixel-level perception through a points prediction mechanism. The core design centers on representing segmentation outputs as explicit sequences of 2D coordinates, or point trajectories, which are generated entirely within the language space. This approach is decoder-free and architecture-agnostic, enabling a unified interface for handling points, bounding boxes, and masks as textual outputs. The framework operates by predicting a sequence of normalized coordinates that trace the boundary of a target object, thereby avoiding the need for dense per-pixel encodings. This representation offers interpretability, composability with other text-based inputs, and a controllable token budget that scales linearly with the number of vertices rather than the image resolution.
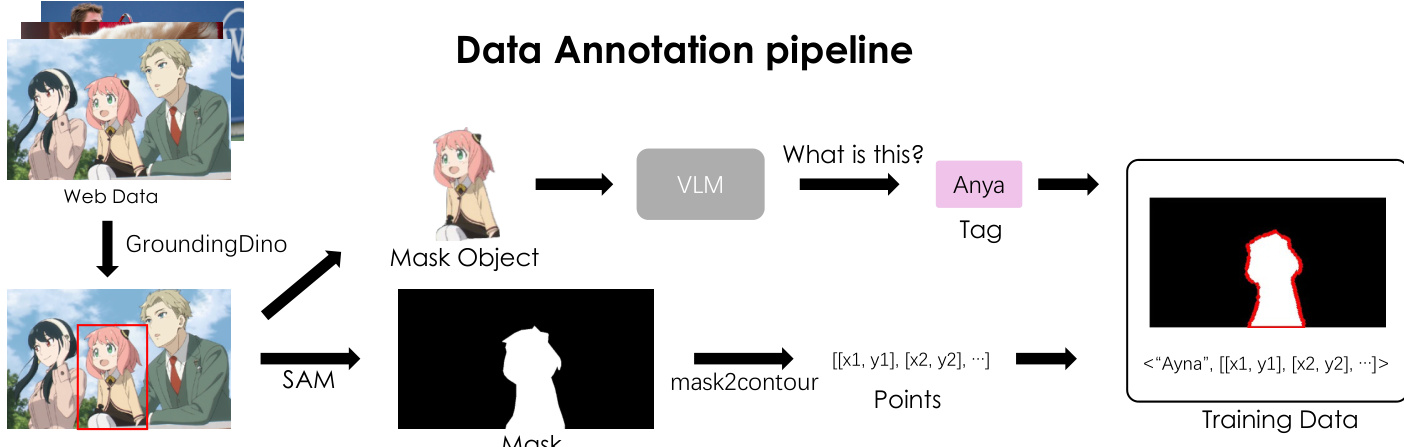
The data annotation pipeline, as illustrated in the figure below, is designed to scale the framework using large-scale web data. It begins with web data, which is processed by Grounding-DINO for object detection to identify instances. The detected objects are then passed to SAM to generate segmentation masks. These binary masks are converted into polygonal contours using a contour extraction algorithm, which enforces a consistent clockwise traversal order and optionally applies sparsification. The resulting point sequences are combined with textual descriptions, generated by a vision-language model (VLM), to form structured training data. This pipeline enables the creation of diverse instruction-response pairs for training, where the model learns to generate the appropriate point trajectory given a textual prompt.

The task formulation treats all outputs—points, bounding boxes, and masks—as text tokens within a unified interface. Masks are represented as point trajectories, where the boundary is sparsely sampled into a sequence of normalized coordinates. This is formalized using a minimal JSON-like grammar to constrain the output format, ensuring well-formed and parseable sequences. The framework supports a variety of grounding queries, such as predicting a bounding box from a text description or generating a polygon from a point. This design multiplies supervision sources by recombining weak labels, such as extracting points or boxes from masks, and standardizes outputs for instruction tuning and reinforcement learning.
The training pipeline consists of two stages. The first stage is supervised fine-tuning (SFT), which cold-starts the model by curating instruction-response pairs for tasks like text-to-point, text-to-bbox, and text/point-to-mask. This stage teaches the model to generate correct output formats, including proper coordinate syntax, closing brackets, and consistent ordering, while learning basic grounding priors. The second stage employs reinforcement learning (RL) to optimize sequence-level, location-aware objectives. The authors adopt GSPO as the RL algorithm, using a rule-based reward system. This system includes a Mask IoU reward, which measures the intersection over union between the predicted and ground-truth mask, a MSE Distance IoU reward that penalizes centroid misalignment, and a Format reward that enforces correct output structure. This RL stage allows the model to discover alternative valid trajectories, improving boundary fidelity and closure without overfitting to specific annotations.
Experiment
- Validated on Qwen2.5-VL-7B and Kimi-VL using 32 GPUs, Muon optimizer, and polygon serialization with sparsification tolerance ε; SFT and RL stages optimized with specific learning rates and GSPO.
- Achieved state-of-the-art 87.2 [email protected] on Referring Expression Comprehension (REC), outperforming Text4Seg despite no mask refiner; on RES, matched decoder-based methods with superior decoder-free performance.
- Ablation shows SFT alone yields ~60–65.5 gIoU; RL adds +9.7–10.5 gIoU, confirming IoU-based rewards improve polygon accuracy and token efficiency; pre-training boosts SFT+RL by 13.0 gIoU on refCOCO.
- Optimal ε balances token length and geometric fidelity: 221 tokens (ε=0.005) yields peak cIoU; too few (78 tokens) or too many (859 tokens) degrade performance.
- Clockwise point ordering is critical for valid polygon generation; unordered or alternative sequences cause chaotic outputs and reduced token efficiency.
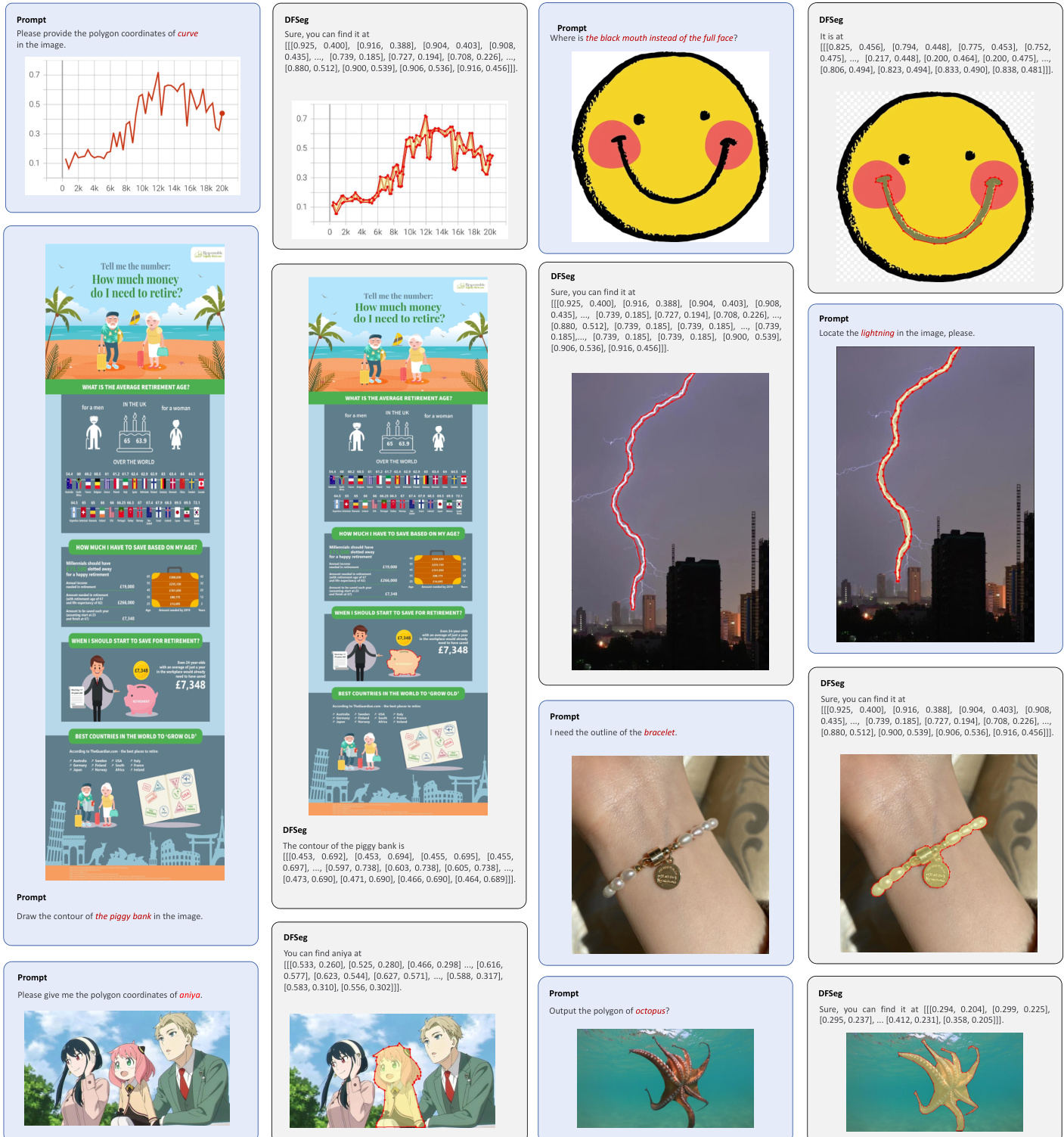
- Extended to SAM-like tasks (point→mask, bbox→mask, text→bbox) with strong generalization, demonstrated via visual results in appendix.
- Limitations: struggles with high-resolution, curved objects and sharp corners under aggressive sparsification; future work should include boundary F-score and vertex-wise metrics.
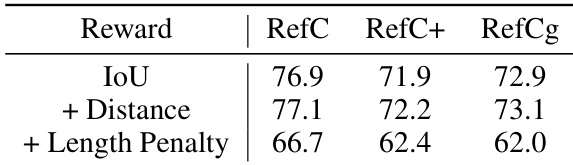
Results show that adding a distance reward improves performance across all datasets, increasing the gIoU score by approximately 0.2. However, incorporating a length penalty degrades performance, indicating that hard constraints on sequence length are detrimental to segmentation accuracy.
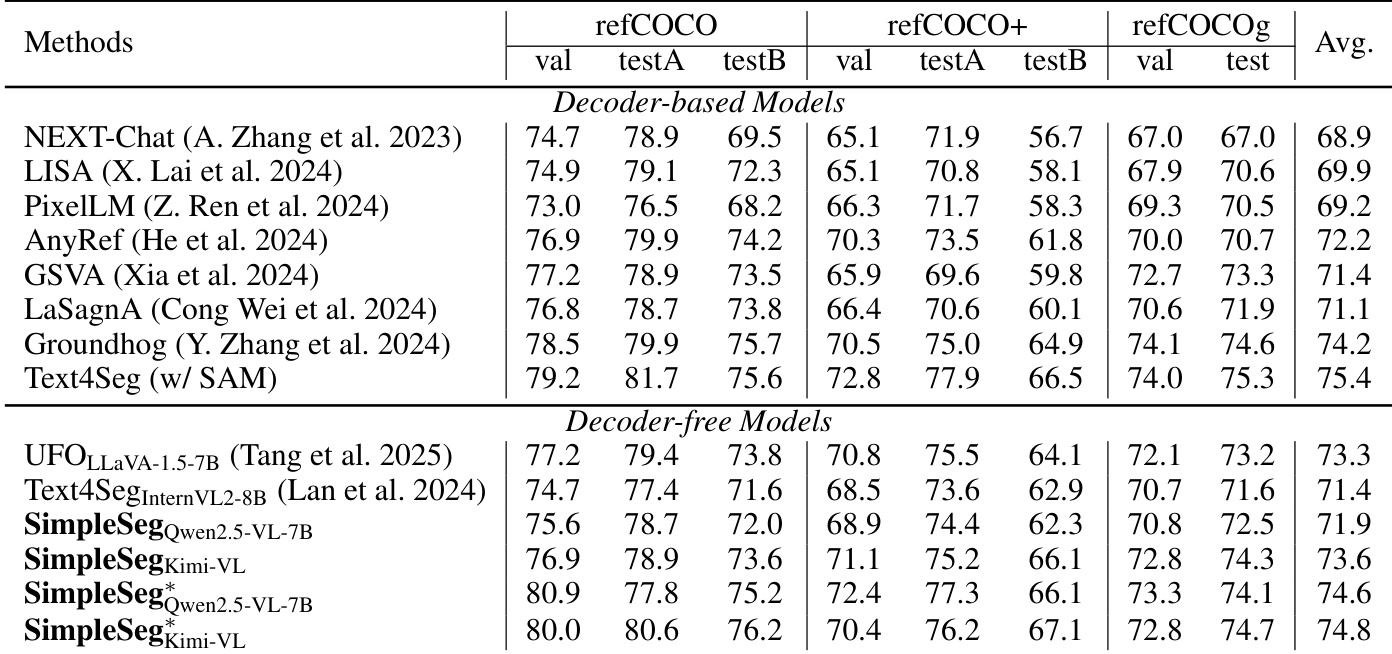
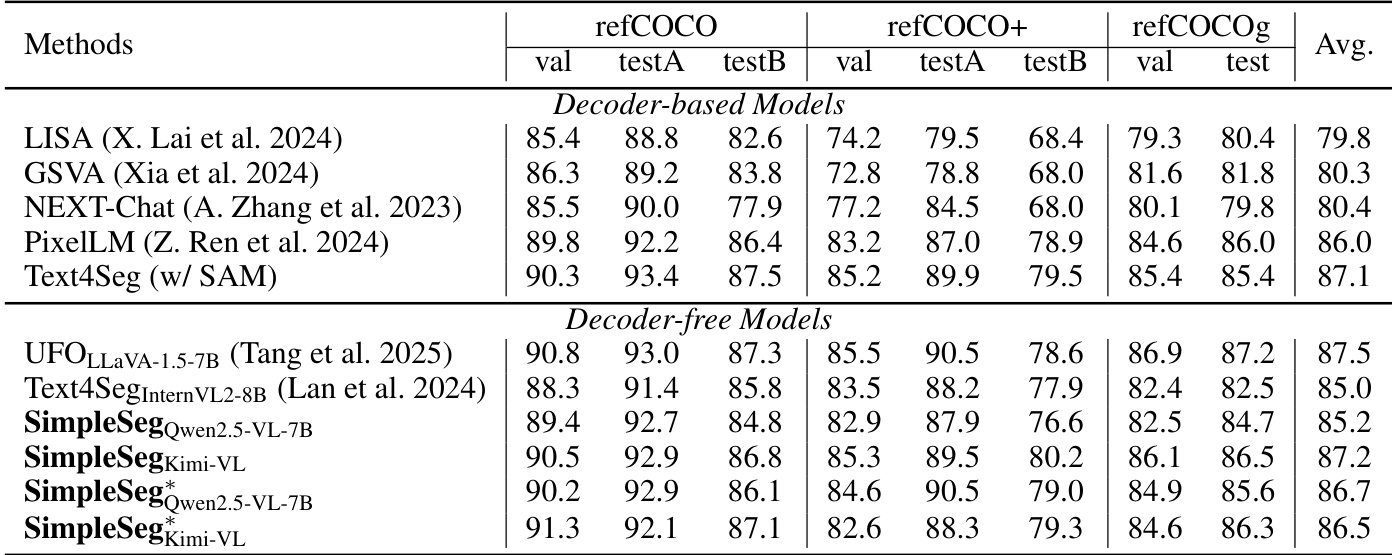
Results show that SimpleSeg achieves competitive performance on referring expression segmentation benchmarks, outperforming other decoder-free models and matching or exceeding decoder-based methods. The authors use a minimalist, decoder-free approach that leverages a large language model to generate polygon coordinates, demonstrating strong fine-grained perception without architectural modifications.
The authors use the Enhanced Muon optimizer with a max learning rate of 5e-5, a min learning rate of 2e-6, and a cosine decay scheduler with a warm-up ratio of 0.03. Training is conducted with a global batch size of 256 and 800k samples per epoch over one total epoch.
Results show that the combination of supervised fine-tuning and reinforcement learning significantly improves performance on referring expression segmentation, with the full training pipeline achieving the highest scores across all datasets. The ablation study indicates that reinforcement learning provides the largest gain, while pre-training alone is ineffective without subsequent fine-tuning.

Results show that SimpleSeg achieves competitive performance on referring expression segmentation benchmarks, outperforming decoder-free models and matching or exceeding decoder-based methods. The model's strong results across refCOCO, refCOCO+, and refCOCOg datasets demonstrate its effective fine-grained perception without architectural modifications.