Command Palette
Search for a command to run...
Un modèle fondamental VLA pragmatique
Un modèle fondamental VLA pragmatique
Résumé
Offrant un potentiel considérable pour la manipulation robotique, un modèle fondamental Vision-Language-Action (VLA) performant doit être capable de généraliser fidèlement à travers diverses tâches et plateformes tout en assurant une efficacité économique (par exemple, en termes de données et d’heures de calcul GPU nécessaires à l’adaptation). À cette fin, nous avons développé LingBot-VLA, basé sur environ 20 000 heures de données réelles provenant de 9 configurations populaires de robots à deux bras. Grâce à une évaluation systématique menée sur 3 plateformes robotiques, chacune accomplissant 100 tâches avec 130 épisodes post-entraînement par tâche, notre modèle démontre une supériorité nette par rapport aux solutions concurrentes, illustrant ainsi des performances solides et une généralisation étendue. Nous avons également mis en place une bibliothèque logicielle efficace, capable de traiter 261 échantillons par seconde par GPU dans une configuration d’entraînement à 8 GPU, offrant une accélération de 1,5 à 2,8 fois (selon le modèle de base VLM utilisé) par rapport aux bibliothèques existantes dédiées aux VLA. Ces caractéristiques assurent que notre modèle est particulièrement adapté au déploiement dans des environnements réels. Pour stimuler le progrès du domaine de l’apprentissage robotique, nous mettons à disposition librement le code source, le modèle de base et les données de benchmark, en mettant l’accent sur la mise en œuvre de tâches plus exigeantes et sur la promotion de normes d’évaluation rigoureuses.
One-sentence Summary
Robbyant researchers propose LingBot-VLA, a Vision-Language-Action foundation model trained on 20,000 real-world robot hours across 9 platforms, achieving state-of-the-art generalization via Mixture-of-Transformers and spatial-aware depth alignment, plus 1.5–2.8× faster training throughput, enabling scalable, deployable robotic manipulation.
Key Contributions
- LingBot-VLA is trained on 20,000 hours of real-world dual-arm robot data from 9 platforms, demonstrating that VLA performance scales favorably with data volume and shows no saturation at this scale, enabling stronger generalization across tasks and embodiments.
- The model achieves state-of-the-art results in a rigorous real-world evaluation across 3 robotic platforms, completing 100 diverse tasks with 130 episodes each, outperforming competitors and establishing a new benchmark for multi-platform VLA assessment.
- An optimized training codebase delivers 261 samples per second per GPU on an 8-GPU setup, offering 1.5–2.8× speedup over existing VLA frameworks, reducing computational cost and accelerating deployment-ready model development.
Introduction
The authors leverage Vision-Language-Action (VLA) foundation models to enable robots to perform diverse manipulation tasks from natural language instructions, aiming to bridge the gap between large-scale pre-training and real-world deployment. Prior work lacks systematic evaluation on real robots at scale and suffers from inefficient training codebases that bottleneck data scaling and multi-platform testing. Their main contribution is LingBot-VLA, trained on 20,000 hours of real-world dual-arm robot data across 9 platforms, which demonstrates consistent performance gains with data scale and achieves state-of-the-art generalization across 3 robotic embodiments on 100 tasks. They also release an optimized training codebase delivering 1.5–2.8x speedup over existing frameworks, enabling faster iteration and lower costs while promoting open science through public release of code, models, and benchmarks.
Dataset

-
The authors use a large-scale pre-training dataset built from teleoperated data across 9 dual-arm robot platforms, including AgiBot G1, AgileX, Galaxea R1Lite/Pro, Realman Rs-02, Leju KUAVO 4 Pro, Oinglong, ARX Lift2, and Bimanual Franka—each with varying DoF arms, camera setups, and gripper configurations.
-
For language labeling, human annotators segment multi-view robot videos into clips aligned with atomic actions, trimming static start/end frames. They then use Qwen3-VL-235B-A22B to generate precise task and sub-task instructions for each clip.
-
For the GM-100 benchmark, 150 raw trajectories per task are collected via teleoperation across three platforms; the top 130 (by task completion, smoothness, and protocol adherence) are retained. Objects are standardized per GM-100 specs, and object poses are randomized per trajectory to boost environmental diversity.
-
Teleoperation follows strict guidelines: maintain end-effector clearance, slow motion during contact, and ensure distinct start/end visual states. Automated filtering removes technical anomalies, followed by manual review using multi-view video to exclude off-protocol or cluttered episodes.
-
The test set includes ~50% atomic actions not among the top 100 most frequent training actions, ensuring strong generalization evaluation. Word clouds in Figures 3a and 3b visualize action category distributions across train/test splits.
-
All trajectories are processed to align with GM-100 task specs, and metadata includes standardized object info, randomized poses, and quality-ranked trajectory labels. No cropping is mentioned; processing focuses on segmentation, filtering, and instruction annotation.
Method
The authors leverage a Mixture-of-Transformers (MoT) architecture to integrate a pre-trained vision-language model (VLM) with an action generation module, forming the core of LingBot-VLA. This framework processes vision-language and action modalities through distinct transformer pathways, which are coupled via a shared self-attention mechanism to enable layer-wise unified sequence modeling. The VLM, specifically Qwen2.5-VL, encodes multi-view operational images and task instructions, while the action expert processes proprioceptive sequences including initial states and action chunks. This design ensures that high-dimensional semantic priors from the VLM guide action generation across all layers while minimizing cross-modal interference through modality-specific processing. 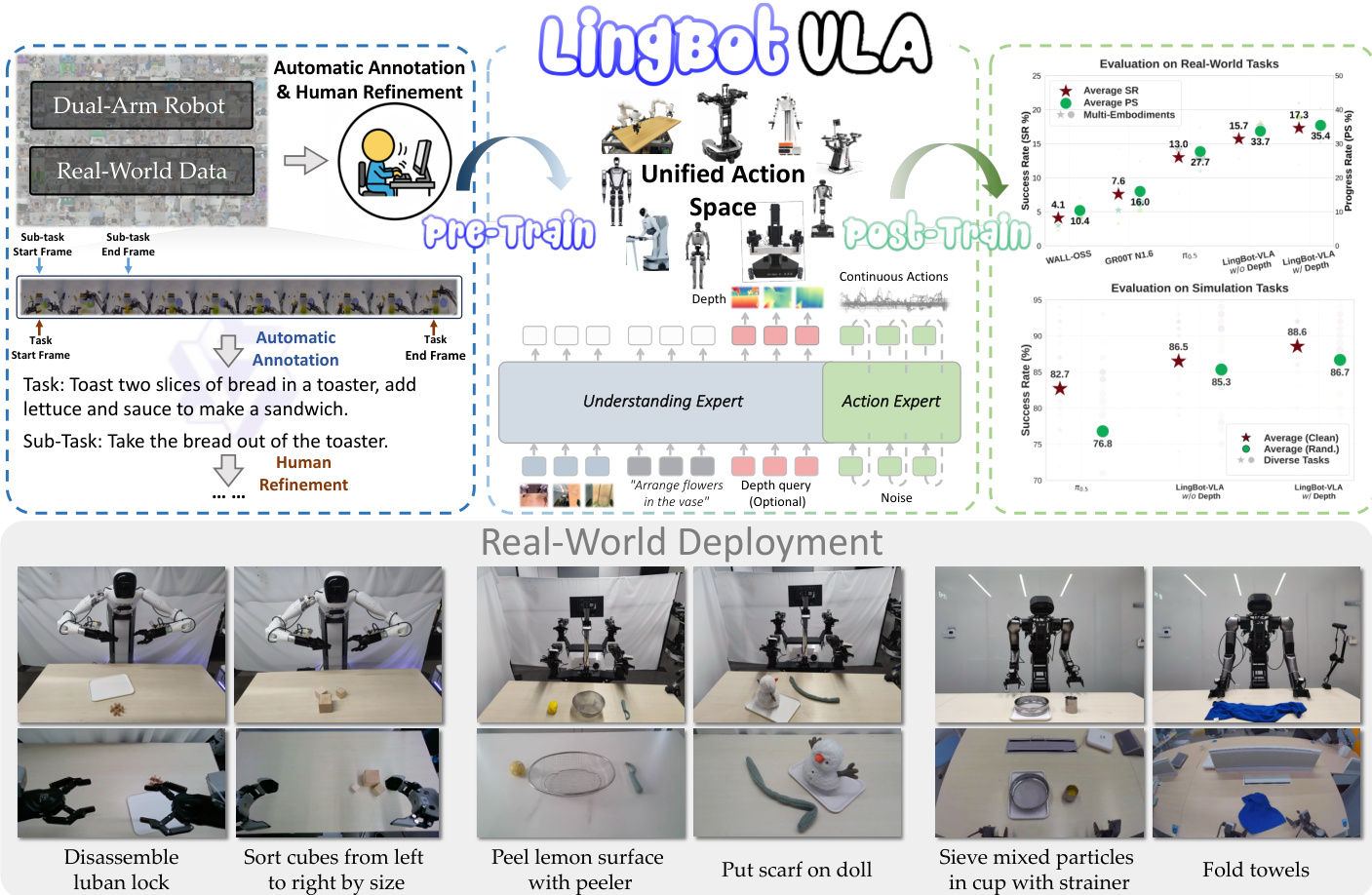
The joint modeling sequence at timestamp t is constructed by concatenating the observation context Ot and the action chunk At. The observation context is defined as Ot=[It1,It2,It3,Tt,st], incorporating tokens from three-view operational images of dual-arm robots, the task instruction Tt, and the robot state st. The action sequence is denoted as At=[at,at+1,…,at+T−1], where T is the action chunk length, set to 50 during pre-training. The training objective is to model the conditional distribution p(At∣Ot) using Flow Matching, which enables smooth and continuous action modeling for precise robotic control.
For a flow timestep s∈[0,1], the intermediate action At,s is defined through linear interpolation between the ground-truth action At and Gaussian noise ϵ∼N(0,I), resulting in At,s=sAt+(1−s)ϵ. The conditional distribution of At,s is formulated as p(At,s∣At)=N(sAt,(1−s)I). The action expert vθ is trained to predict the conditional vector field by minimizing the Flow Matching objective:
LFM=Es∼U[0,1],At,ϵ∥vθ(At,s,Ot,s)−(At−ϵ)∥2,where the target velocity is derived from the ideal vector field At−ϵ.
To ensure proper information flow, blockwise causal attention is implemented for the joint sequence [Ot,At]. The sequence is partitioned into three functional blocks: [It1,It2,It3,Tt], [st], and [at,at+1,…,at+T−1]. A causal mask restricts attention such that tokens within each block can only attend to themselves and preceding blocks, while tokens within the same block use bidirectional attention. This prevents information leakage from future action tokens into observation representations.
To enhance spatial awareness and execution robustness, a vision distillation approach is adopted. Learnable queries [Qt1,Qt2,Qt3] corresponding to the three-view images are processed by the VLM and aligned with depth tokens [Dt1,Dt2,Dt3] from LingBot-Depth. This alignment is achieved by minimizing the distillation loss Ldistill:
Ldistill=EOt∣Proj(Qt)−Dt∣,where Proj(⋅) is a projection layer using cross-attention for dimensional alignment. This integration infuses geometric information into the model, improving perception for complex manipulation tasks.
Experiment
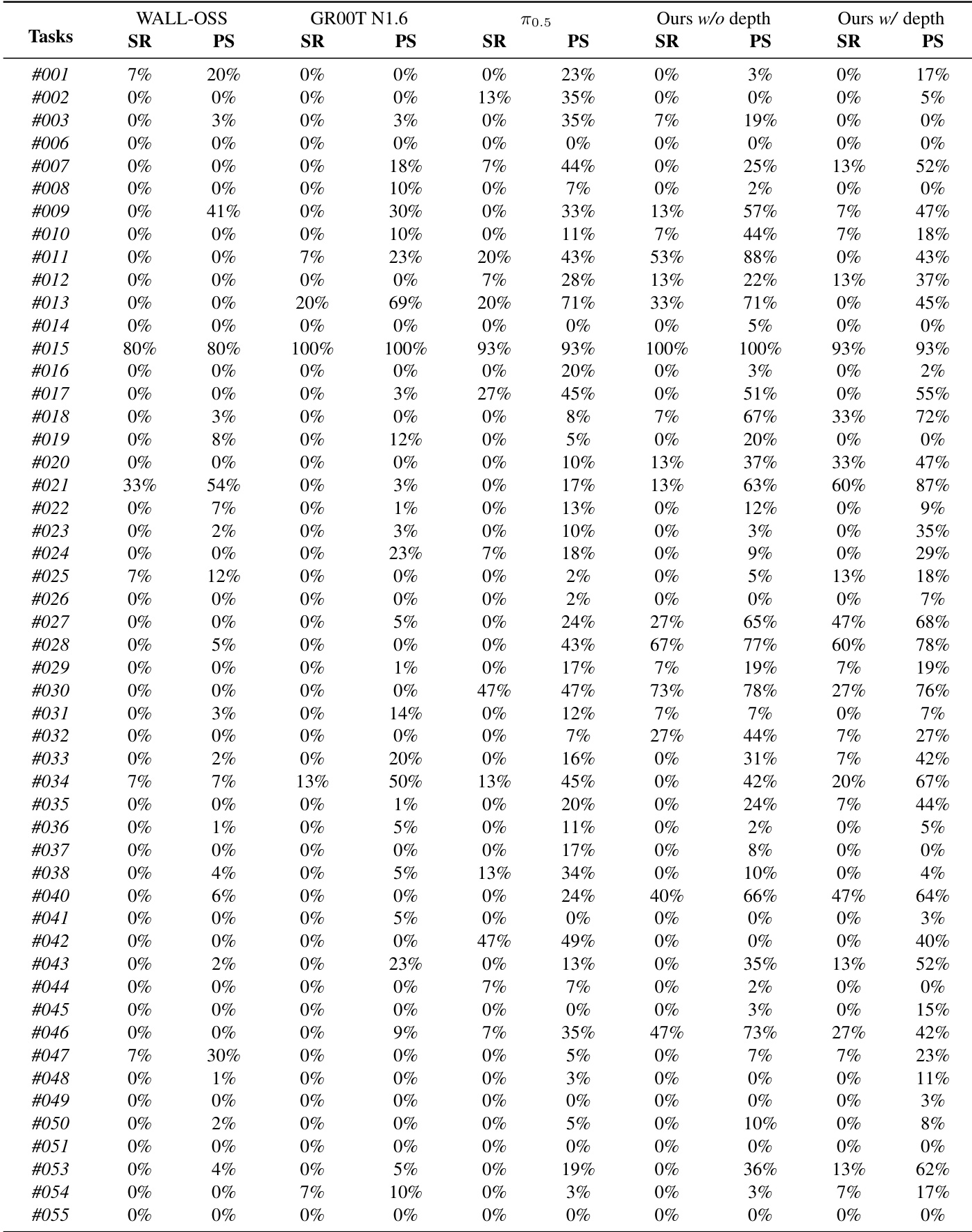
- Evaluated LingBot-VLA across 25 robots on 3 platforms (AgileX, Agibot G1, Galaxea R1Pro) using GM-100 benchmark (100 tasks, 39K demos), achieving 22.5K controlled trials vs. 3 baselines under identical conditions.
- On real-world GM-100, LingBot-VLA w/ depth outperformed π0.5 by +4.28% SR and +7.76% PS averaged across platforms; surpassed WALL-OSS and GR00T N1.6 consistently, with GR00T showing platform-specific gains due to pre-training alignment.
- In RoboTwin 2.0 simulation, LingBot-VLA w/ depth exceeded π0.5 by +5.82% SR (clean) and +9.92% SR (randomized), leveraging depth-enhanced spatial priors for robust multi-task generalization.
- Training throughput analysis showed LingBot’s codebase achieved fastest sample/s across Qwen2.5-VL-3B-π and PaliGemma-3B-pt-224-π, scaling efficiently up to 256 GPUs and outperforming StarVLA, Dexbotic, and OpenPI.
- Scaling experiments revealed consistent SR and PS gains as pre-training data increased from 3K to 20K hours, with cross-platform alignment confirming robust generalization.
- Data-efficiency tests on Agibot G1 showed LingBot-VLA with only 80 demos/task outperformed π0.5 using 130 demos/task, with performance gap widening as data increased.
The authors use a large-scale real-world benchmark to evaluate LingBot-VLA against three state-of-the-art baselines across three robotic platforms, with results showing that LingBot-VLA without depth outperforms WALL-OSS and GR00T N1.6 in both success rate and progress score. By incorporating depth information, LingBot-VLA with depth achieves a 4.28% higher success rate and a 7.76% higher progress score on average compared to π₀.₅ across all platforms.
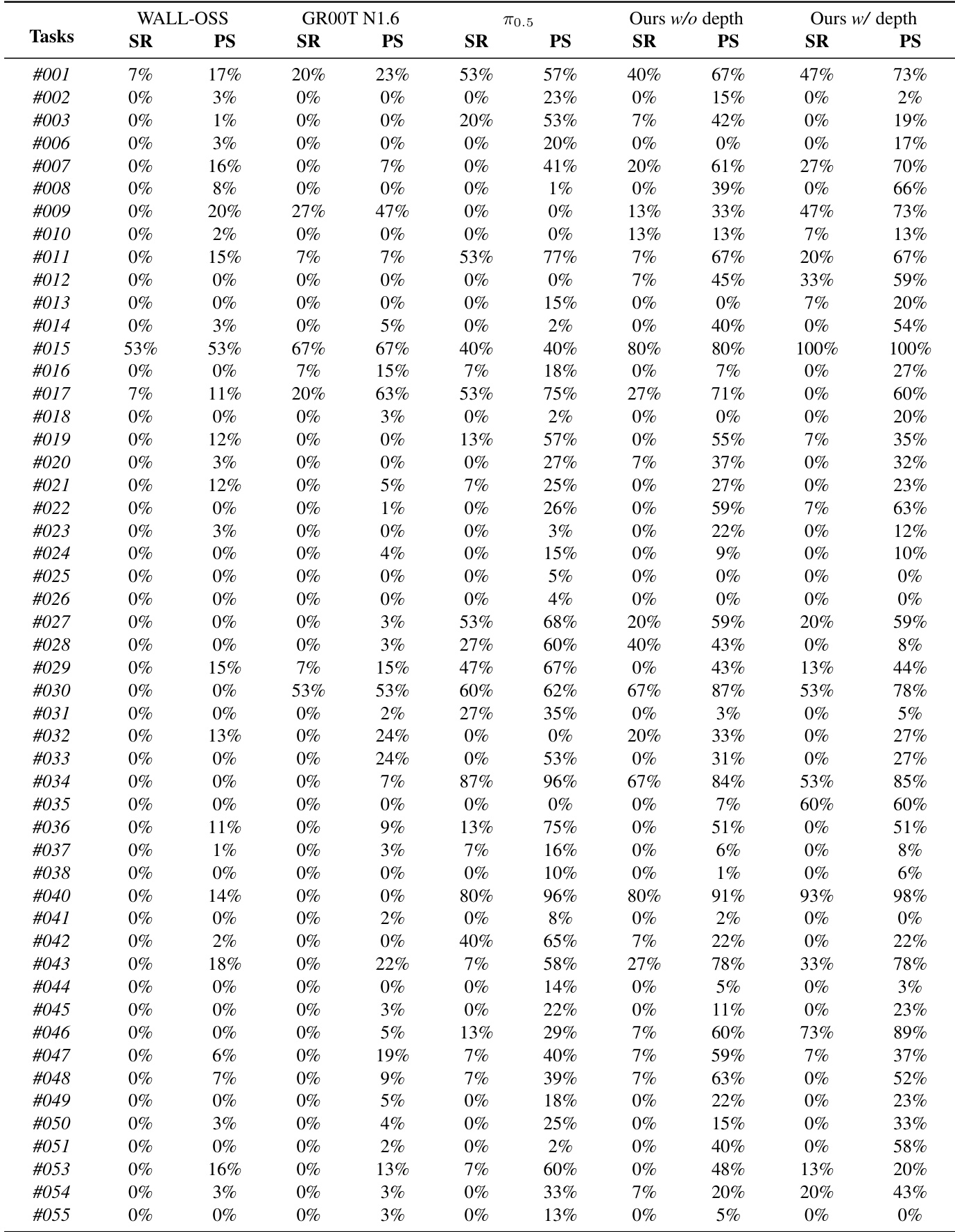
The authors use a data-efficient post-training experiment on the Agibot G1 platform to compare LingBot-VLA with the π₀.₅ baseline, showing that LingBot-VLA achieves higher success and progress rates with fewer demonstrations. Results show that LingBot-VLA outperforms π₀.₅ even when trained on only 80 demonstrations per task, and the performance gap widens as the number of demonstrations increases, demonstrating superior data efficiency.
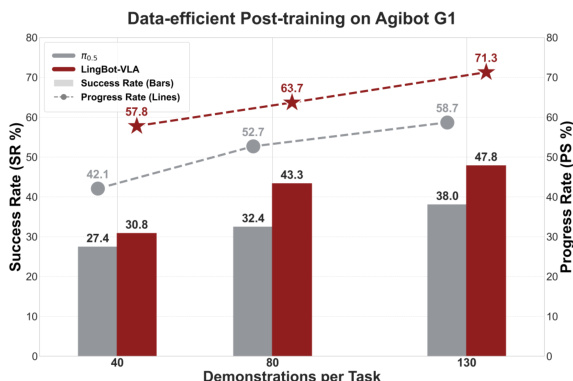
Results show that LingBot-VLA outperforms the π0.5 baseline across all platforms, with the variant incorporating depth information achieving the highest average success rate of 86.68%. The authors use a controlled evaluation protocol to ensure fair comparisons, demonstrating that depth-based spatial information significantly improves real-world task performance.
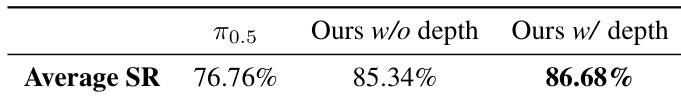
Results show that LingBot-VLA outperforms all baselines across the three robotic platforms in both success rate and progress score, with the variant incorporating depth information achieving the highest performance. The model demonstrates strong generalization, as evidenced by consistent improvements over the baselines on each platform and in the average across all embodiments.

The authors use a large-scale real-world benchmark to evaluate LingBot-VLA against three state-of-the-art baselines across three robotic platforms, with results showing that LingBot-VLA without depth outperforms WALL-OSS and GR00T N1.6 in both success rate and progress score. By incorporating depth information, LingBot-VLA with depth achieves a 4.28% higher success rate and a 7.76% higher progress score than π₀.₅ across all platforms, demonstrating improved performance through enhanced spatial understanding.