Command Palette
Search for a command to run...
daVinci-Dev : Agent-native Mid-training pour l'ingénierie logicielle
daVinci-Dev : Agent-native Mid-training pour l'ingénierie logicielle
Résumé
Récemment, la frontière des capacités des grands modèles linguistiques (LLM) s’est déplacée du génération de code en une seule étape vers une ingénierie logicielle agente — un paradigme dans lequel les modèles naviguent, modifient et testent de manière autonome des dépôts logiciels complexes. Bien que les méthodes post-entraînement soient devenues la norme pour les agents de code, l’entraînement intermédiaire agent (mid-training, MT) sur de grandes échelles de données reflétant des flux de travail agents réels reste largement sous-exploité, en dépit de son potentiel d’instauration de comportements fondamentaux agents de manière plus scalable que l’apprentissage par renforcement coûteux. Un défi central dans la mise en œuvre d’un entraînement intermédiaire agent efficace réside dans le désalignement de distribution entre les données d’entraînement statiques et l’environnement dynamique, riche en feedback, du développement logiciel réel. Pour y remédier, nous présentons une étude systématique de l’entraînement intermédiaire agent, établissant à la fois les principes de synthèse de données et la méthodologie d’entraînement permettant un développement efficace d’agents à grande échelle. Au cœur de notre approche se trouve le concept de données natives à l’agent — une supervision fondée sur deux types complémentaires de trajectoires : les trajectoires contextuellement natives, qui préservent l’intégralité du flux d’information subi par l’agent, offrant une couverture large et une diversité élevée ; et les trajectoires environnementalement natives, collectées à partir de dépôts exécutables où les observations proviennent d’appels réels d’outils et d’exécutions de tests, assurant ainsi une profondeur et une authenticité d’interaction. Nous validons les capacités agentes du modèle sur SWE-Bench Verified. Nous démontrons notre supériorité par rapport à la recette précédente d’entraînement intermédiaire en ingénierie logicielle open-source Kimi-Dev, dans deux scénarios post-entraînement utilisant un modèle de base aligné et un cadre agente, tout en utilisant moins de la moitié des tokens d’entraînement intermédiaire (73,1 milliards). En plus de cet avantage relatif, nos meilleurs modèles, respectivement de 32B et 72B paramètres, atteignent des taux de résolution de 56,1 % et 58,5 %, ce qui représente une avancée significative dans la performance des agents logiciels autonomes.
One-sentence Summary
Researchers from SII, SJTU, and GAIR propose agentic mid-training with agent-native data—combining contextually and environmentally native trajectories—to overcome distribution mismatches in LLM software agents, outperforming KIMI-DEV with fewer tokens and achieving SOTA on SWE-Bench Verified while boosting general code and science benchmarks.
Key Contributions
- We introduce agent-native data for agentic mid-training, combining contextually-native trajectories for broad coverage and environmentally-native trajectories from executable repos for authentic interaction, addressing the distribution mismatch between static data and dynamic development workflows.
- Our method achieves state-of-the-art resolution rates of 56.1% (32B) and 58.5% (72B) on SWE-Bench Verified using less than half the mid-training tokens (73.1B) compared to prior open recipes like KIMI-DEV, despite starting from non-coder Qwen2.5-Base models.
- Beyond agentic tasks, our models show improved performance on general code generation and scientific benchmarks, and we plan to open-source datasets, recipes, and checkpoints to enable broader research in scalable agentic LLM training.
Introduction
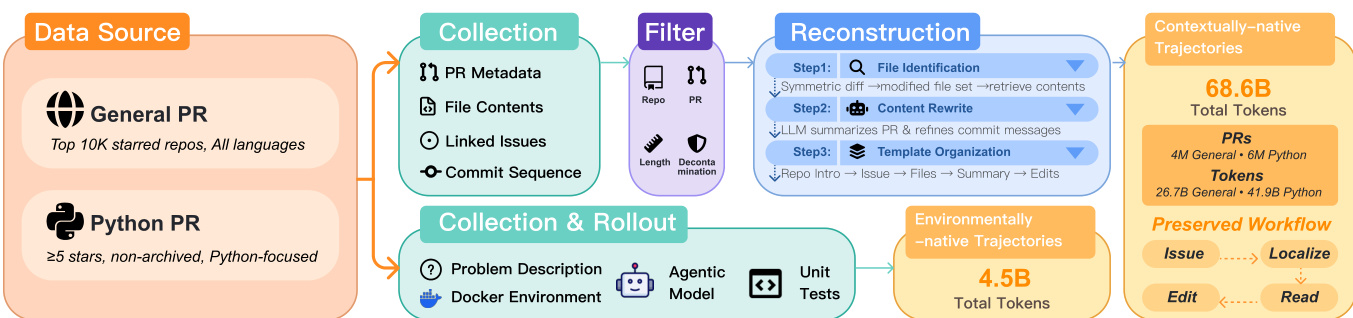
The authors leverage agentic mid-training to address the growing need for LLMs that can autonomously navigate, edit, and validate code across complex repositories—a shift beyond single-function generation toward real-world software engineering. Prior work relies heavily on post-training with limited, curated trajectories, which suffer from data scarcity, lack of dynamic feedback, and an inability to instill foundational agentic reasoning early. Existing mid-training data also fails to mirror the iterative, tool-driven workflows of actual development, creating a distribution mismatch between static training samples and live agent behavior. Their main contribution is a systematic framework for agent-native mid-training, combining two trajectory types: contextually-native data (68.6B tokens) that reconstructs developer decision flows from PRs, and environmentally-native data (3.1B tokens) derived from real test executions. This approach achieves state-of-the-art results on SWE-Bench Verified with 56.1% and 58.5% resolution rates on 32B and 72B models—surpassing prior open recipes like KIMI-DEV while using less than half the training tokens—and improves generalization across code and scientific benchmarks.
Dataset

The authors construct agent-native data to bridge the gap between static training data and interactive deployment, using two complementary trajectory types: contextually-native (from GitHub PRs) and environmentally-native (from agent rollouts in real environments).
-
Dataset Composition and Sources
- Contextually-native trajectories come from GitHub Pull Requests, preserving full development workflows including issue descriptions, file contents, and edits.
- Environmentally-native trajectories are generated by running agents (GLM-4.6) in Dockerized environments derived from real PRs, capturing test feedback and iterative edits.
-
Key Details by Subset
- Contextually-native (D^ctx):
- Two subsets:
- D_gen^ctx (26.7B tokens): from top 10,000 most-starred repos across all languages; includes XML-like tags, reviews, and developer comments.
- D_py^ctx (41.9B tokens): Python-focused, from 740K repos with ≥5 stars; uses Markdown + search-replace edits; filters to 1–5 Python files per PR.
- Both subsets exclude bot PRs, merged PRs only, and decontaminate SWE-Bench Verified repos.
- LLM (Qwen3-235B) enhances PR summaries and commit messages for clarity.
- Length capped at 32K tokens; retains >90% of Python PRs.
- Two subsets:
- Environmentally-native (D^env):
- Two subsets based on test outcomes:
- D_pass^env (0.7B tokens, 18.5K trajectories): all tests pass.
- D_fail^env (2.4B tokens, 55.5K trajectories): tests fail; provides debugging signals.
- Generated via SWE-AGENT in Docker environments; upsampled 3x during training.
- Trajectories capped at 128K tokens; total 3.1B tokens (~4.5B effective).
- Two subsets based on test outcomes:
- Contextually-native (D^ctx):
-
How the Data Is Used
- Mid-training (MT) is staged: first on D_gen^ctx, then on D_py^ctx (or D_py^ctx + D_env).
- For supervised fine-tuning (SFT), the authors use D_pass^env or D^SWE-smith (0.11B tokens), trained for 5 epochs.
- D^ctx + D^env combined totals 73.1B tokens; used sequentially to first build broad knowledge, then specialize.
-
Processing and Metadata
- Contextual samples are structured to mirror agent workflow: localization (file paths), reading (file contents), editing (diffs or search-replace), and reasoning (LLM summaries).
- Environmentally-native data records full action-observation sequences: edits, test runs, errors, and tool outputs.
- Decontamination: SWE-Bench Verified PRs removed; HumanEval/EvalPlus checked via 13-gram overlap.
- Format differences: general subset uses XML with reviews; Python subset uses Markdown with search-replace edits and LLM-generated reasoning headers.
Method
The authors leverage a multi-stage training framework designed to develop an agent capable of performing complex software engineering tasks through iterative interaction with a codebase. The overall architecture is structured around two primary data streams: contextually native trajectories and environment-native trajectories, which are processed through distinct training phases to build agent capabilities. Contextually native trajectories originate from real-world pull requests (PRs) and are enriched with metadata such as issue descriptions, commit messages, and code changes, forming a diverse dataset that captures the natural workflow of software development. These trajectories are used to train the agent to understand and generate contextually appropriate actions. Environment-native trajectories, on the other hand, are derived from real execution environments, where the agent interacts with a Docker-based setup to perform tasks such as localization, editing, testing, and revision. This stream ensures that the agent learns from authentic feedback loops, including test results and compiler errors, which are critical for refining its behavior. The integration of these two data streams enables the model to develop both contextual awareness and practical execution skills.
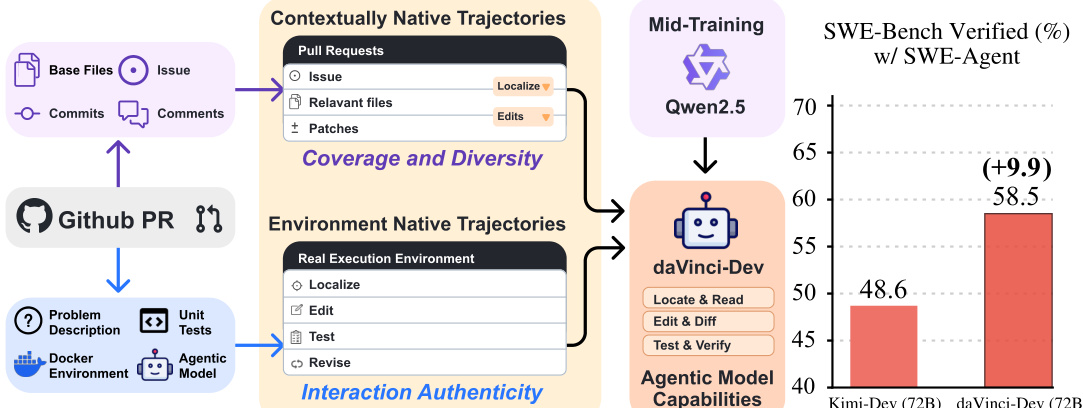
The training process begins with data collection from two primary sources: general PRs from top 10K starred repositories across all languages and Python-focused PRs with at least five stars and non-archived status. This data is processed through a pipeline that includes collection, filtering, and reconstruction. During collection, metadata such as PR descriptions, file contents, and linked issues are extracted. The filtering stage removes low-quality or redundant data, while reconstruction involves steps like file identification, content rewriting, and template organization to generate structured, high-quality training samples. The reconstructed data is then used to create contextually native trajectories, which are further refined into environment-native trajectories by incorporating real execution feedback. This ensures that the agent learns not only from static code snippets but also from dynamic, real-world interactions.

The model architecture is designed to support both static code corpora and factorized subtask training. In the static code corpora approach, isolated code snippets are used to teach the model what code looks like, but not how to navigate or modify it. This is contrasted with factorized subtask training, where the model is trained separately on localization and editing tasks. The localization stage predicts relevant files based on an issue, while the editing stage generates patches given the identified files. This factorization allows the model to learn the dependencies between localization and editing, although it assumes perfect file retrieval and lacks execution or test feedback during inference. The contextually native approach unifies localization and editing into a single sample, training the model on the exact context available at inference time. This approach captures real tool invocations with authentic outputs and ensures that test feedback drives iterative refinement, making the training more realistic and effective.
Experiment
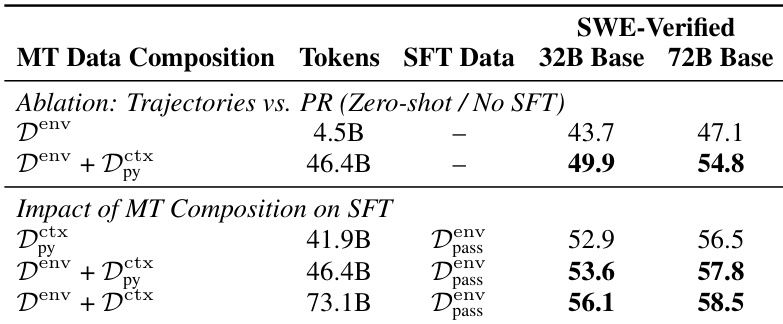
- Agent-native mid-training boosts performance across SFT regimes: on 72B, weak SFT improves from 38.0% to 46.4% with only context data (D^ctx), matching Kimi-Dev with half the tokens; strong SFT reaches 58.2%, outperforming RL-tuned Kimi-Dev; adding environment data (D^env) lifts it to 58.5%.
- Benefits scale to 32B: D^ctx improves weak SFT by 4.7% and strong SFT by 1.1%; D^ctx + D^env achieves 56.1%, 3.1% above strong SFT baseline.
- daVinci-Dev-72B (58.5%) and daVinci-Dev-32B (56.1%) outperform open baselines on SWE-Bench Verified, including state-of-the-art at 32B scale despite starting from non-coder base models.
- Generalizes beyond SWE: improves HumanEval, EvalPlus, GPQA, and SciBench, showing agentic training transfers to code generation and scientific reasoning via decision-making patterns.
- Token-efficient: 68.6B tokens (D^ctx) + 4.5B effective tokens (D^env) surpass Kimi-Dev’s 150B-token recipe, due to closer alignment with test distribution and authentic trajectories.
- Contextual data amplifies trajectory learning: zero-shot 72B improves +7.7% when PR context is added to trajectories; mid-training on trajectories also boosts final SFT performance by 1.3%.
- Scales predictably: log-linear performance gain with training steps (R²≈0.90), no saturation observed; 72B reaches 54.9%, 32B reaches 49.9% on D^ctx + D^env.
- Data scalability: Python PR subset from 1.3e7 PRs; potential to scale to 3e8 PRs across 1e9 repos; executable tasks via automated pipelines offer deeper, verifiable supervision.
The authors use a mid-training approach with contextually-native and environmentally-native data to improve performance on SWE-Bench Verified, achieving 58.5% for the 72B model and 56.1% for the 32B model, surpassing prior open methods. Results show that their method is effective across different model scales and SFT regimes, with the strongest performance coming from scaling the contextually-native data foundation.
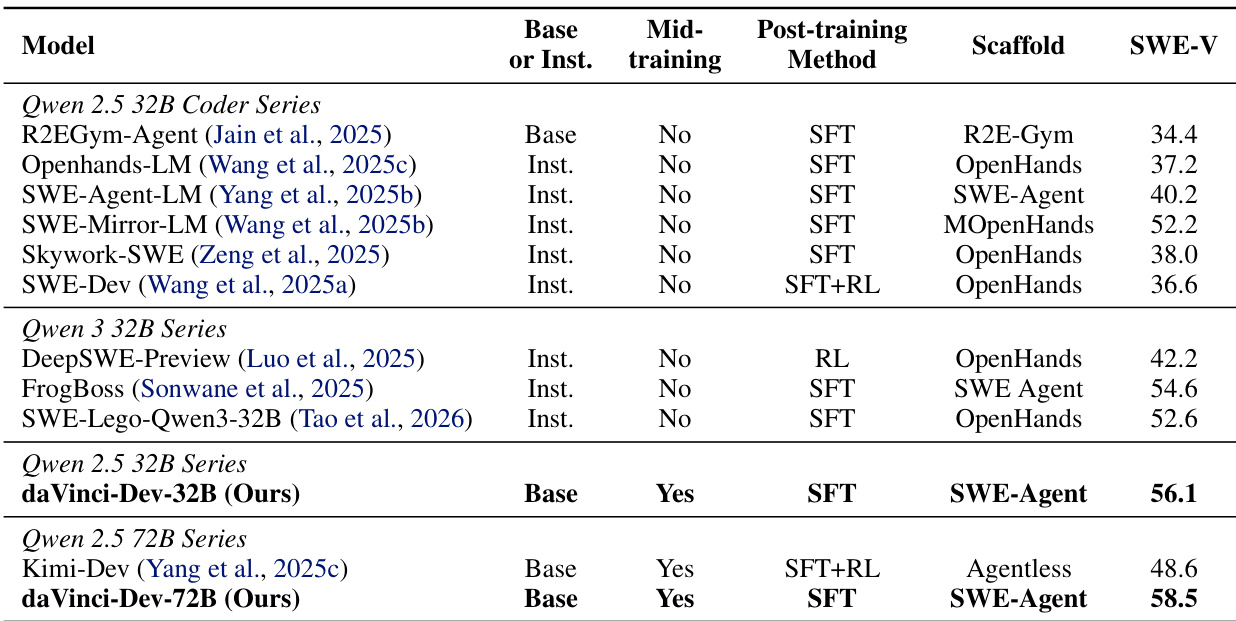
The authors use mid-training with contextually-native and environmentally-native data to improve performance on SWE-Bench Verified, achieving 58.5% on the 72B model and 56.1% on the 32B model, surpassing prior methods. Results show that combining these data types enhances generalization and enables efficient, scalable learning, with the strongest performance coming from large-scale contextually-native supervision.
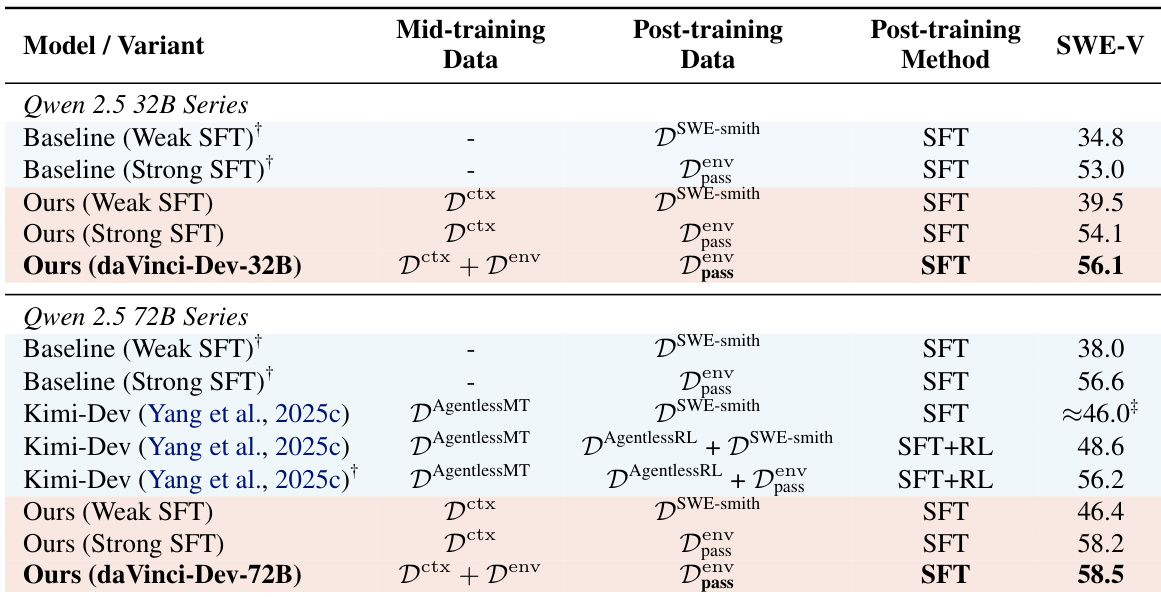
Results show that combining contextually-native and environmentally-native data during mid-training improves performance on SWE-Bench Verified, with the full combination achieving 58.5% on the 72B model and 56.1% on the 32B model. The authors find that contextually-native data is essential for grounding trajectories, and that including trajectories in mid-training enhances performance even when fine-tuning is later applied.
The authors use a mid-training (MT) approach with contextually-native and environmentally-native data to improve model performance on both scientific and code benchmarks. Results show that their MT Mix method significantly boosts performance across all evaluated tasks, with gains of up to +23.26% on HumanEval and +12.46% on GPQA-Main, indicating strong generalization beyond software engineering.
