Command Palette
Search for a command to run...
LLM-in-Sandbox Évoque une Intelligence Agente Générale
LLM-in-Sandbox Évoque une Intelligence Agente Générale
Daixuan Cheng Shaohan Huang Yuxian Gu Huatong Song Guoxin Chen Li Dong Wayne Xin Zhao Ji-Rong Wen Furu Wei
Résumé
Nous introduisons LLM-in-Sandbox, une approche qui permet aux modèles linguistiques massifs (LLM) d’explorer un environnement de développement virtuel (c’est-à-dire un « sandbox » de code, ou ordinateur virtuel), afin d’activer des capacités d’intelligence générale dans des domaines autres que le codage. Nous démontrons d’abord que les LLM puissants, sans entraînement supplémentaire, possèdent déjà des capacités de généralisation leur permettant d’utiliser efficacement le sandbox de code pour des tâches non codées. Par exemple, les LLM accèdent spontanément à des ressources externes afin d’acquérir de nouvelles connaissances, exploitent le système de fichiers pour gérer des contextes longs, et exécutent des scripts pour satisfaire des exigences de formatage. Nous montrons également que ces capacités agencées peuvent être renforcées par un apprentissage par renforcement spécifique à LLM-in-Sandbox (LLM-in-Sandbox-RL), qui utilise uniquement des données non agencées pour entraîner les modèles à explorer l’environnement de sandbox. Des expériences montrent que LLM-in-Sandbox, tant dans un cadre sans entraînement préalable qu’après entraînement postérieur, parvient à une généralisation robuste couvrant des domaines tels que les mathématiques, la physique, la chimie, la biomédecine, la compréhension de contextes longs et le respect d'instructions. Enfin, nous analysons l’efficacité de LLM-in-Sandbox sous l’angle computationnel et systémique, et mettons librement à disposition le code sous forme de package Python afin de faciliter son déploiement dans des environnements réels.
One-sentence Summary
Researchers from Renmin University, Microsoft Research, and Tsinghua University propose LLM-in-Sandbox, enabling LLMs to autonomously use code sandboxes for non-code tasks—enhancing reasoning via RL without agentic data—yielding robust gains in science, long-context, and instruction-following tasks, with open-source deployment support.
Key Contributions
- LLM-in-Sandbox enables large language models to leverage a virtual code sandbox for non-code tasks without additional training, demonstrating spontaneous use of file systems, external resources, and script execution to solve problems in domains like math, science, and long-context understanding.
- The authors introduce LLM-in-Sandbox Reinforcement Learning, which trains models using only non-agenetic data to improve sandbox exploration, boosting performance across both agentic and vanilla modes while generalizing to out-of-domain tasks.
- The system achieves up to 8x reduction in token usage for long contexts, maintains competitive throughput, and is open-sourced as a Python package compatible with major inference backends to support real-world deployment.
Introduction
The authors leverage a code sandbox—a virtual computer environment—to unlock general agentic intelligence in large language models (LLMs), enabling them to handle non-code tasks like math, science, and long-context reasoning without task-specific training. Prior approaches often treat LLMs as static text generators or limit tool use to predefined APIs, failing to exploit the full versatility of computational environments. The authors’ main contribution is LLM-in-Sandbox, which grants models open-ended access to external resources, file systems, and code execution, plus LLM-in-Sandbox-RL, a reinforcement learning method that trains models using only general non-agenetic data to master sandbox exploration—boosting performance across domains while reducing token usage and enabling real-world deployment via an open-source Python package.
Dataset

The authors use six diverse non-code evaluation benchmarks, each tailored for specific domains and evaluation methods:
-
Mathematics: 30 AIME25 problems (olympiad-level), repeated 16 times each. Prompt includes step-by-step reasoning and boxed final answers. Evaluated with Math-Verify (HuggingFace, 2025).
-
Physics: 650 UGPhysics problems (50 per of 13 undergraduate subjects). Evaluated via LLM judge (Qwen3-30B-A3B-Instruct-2507, Yang et al., 2025a).
-
Chemistry: 450 ChemBench questions (50 per of 9 sub-domains). Evaluated by exact match.
-
Biomedicine: 500 text-based MedXpertQA multiple-choice questions. Evaluated by exact match.
-
Long-Context Understanding: 100 AA-LCR questions requiring multi-document reasoning (avg. 100K tokens per doc set). Each problem repeated 4 times. Documents stored in sandbox at /testbed/documents/. Evaluated with LLM-based checker (Qwen3-235B-A22B-Instruct-2507, Yang et al., 2025a).
-
Instruction Following: 300 single-turn IFBench questions across 58 constraints. Evaluated in loose mode using official code to handle formatting variations.
-
Software Engineering: 500 verified SWE-bench tasks (code generation, debugging, comprehension). Evaluated with official rule-based script. Uses R2E-Gym sandbox and OpenHands-style prompts with toolset from Section 2.2.
For sandbox capability analysis, the authors classify model actions using pattern matching on Python and bash code blocks. Capability usage rate = (turns with matched patterns) / (total turns). Classification rules are detailed in Table 15.
Method
The authors leverage a code sandbox environment to enable large language models (LLMs) to perform general-purpose tasks through interactive, multi-turn reasoning and action cycles. The framework is built upon a lightweight, general-purpose sandbox implemented as an Ubuntu-based Docker container, which provides the model with terminal access and full system capabilities while ensuring isolation from the host system. This environment is equipped with a minimal toolset designed to realize core computational functions: executeBASH for executing arbitrary terminal commands, str_replace_editor for file manipulation, and submit for signaling task completion. The sandbox's design emphasizes generalizability and scalability by maintaining a constant footprint of approximately 1.1 GB, in contrast to task-specific environments that may require up to 6 TB of storage, enabling efficient large-scale inference and training.
The LLM-in-Sandbox workflow extends the ReAct framework, where the model iteratively generates tool calls based on the task prompt and environmental feedback. As shown in Algorithm 1, the process begins with sandbox configuration, followed by a loop in which the model generates a tool call, executes it within the sandbox, and receives an observation. This interaction continues until the model calls submit or reaches a maximum turn limit. The workflow supports flexible input/output handling by leveraging the sandbox's file system: inputs can be provided via the prompt or as files in the /testbed/documents/ directory, while outputs are directed to a designated location, such as /testbed/answer.txt, ensuring a clean separation between exploration and final results.
To train LLMs to effectively utilize the sandbox, the authors propose LLM-in-Sandbox-RL, a reinforcement learning approach that combines sandbox-based training with general-domain data. The training data consists of context-based tasks sourced from diverse domains, including encyclopedia, fiction, academic tests, and social media, where each instance includes background materials and a task objective. The sandbox configuration stores these contexts as files, with strategies to increase task difficulty, such as splitting multi-document contexts into separate files or supplementing single-file contexts with distractors. This setup encourages the model to actively explore the environment to locate relevant information, naturally learning to leverage its capabilities.
The task setup involves sampling one task as the testing task, using prior related tasks as in-context examples in the prompt. The model is instructed to write the final answer to a designated output file, such as /testbed/answer.txt, and the result is extracted upon completion. The RL training framework adopts outcome-based rewards, with the key difference being that trajectory generation occurs in LLM-in-Sandbox mode, allowing the model to learn from sandbox interactions. The system prompt guides the model to use computational tools, derive answers through program execution, and explore freely within the safe, isolated environment. The prompt specifies the working directory, input and output paths, and includes important notes and encouraged approaches to ensure proper interaction with the sandbox tools.
Experiment
- LLM-in-Sandbox improves performance across general domains (Math, Physics, Chemistry, Biomedicine, Long-Context, Instruction Following), with gains up to +24.2% on Qwen3-Coder for Math; weaker models like Qwen3-4B-Instruct show no benefit or decline.
- Strong models effectively use sandbox capabilities: computation (43.4% in Math), external resources (18.4% in Chemistry), and file management (high in Long-Context); weak models exhibit low usage (<3%) and inefficient exploration.
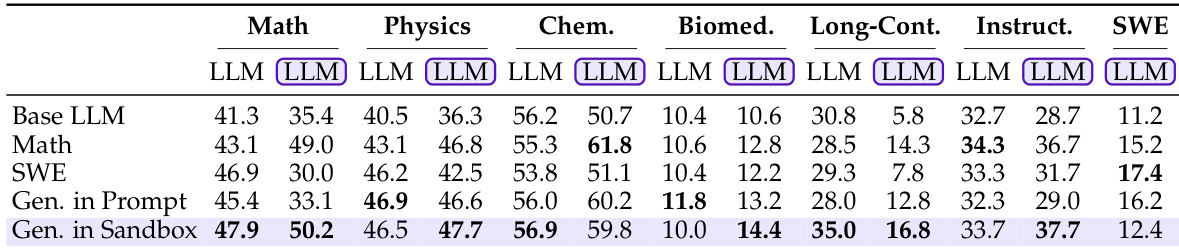
- Storing long-context documents in sandbox (vs. prompt) boosts performance for Claude, DeepSeek, and Kimi; Qwen3-4B performs worse, indicating need for training in file-based navigation.
- LLM-in-Sandbox-RL training generalizes across domains, model sizes, and inference modes: Qwen3-4B improves from 10.0 to 14.4 in Biomed and 33.7 to 37.7 in Instruction Following; even LLM mode benefits due to transferred reasoning patterns.
- Training with context placed in sandbox (vs. prompt) yields superior generalization, as active exploration enhances capability utilization.
- Post-training, models show increased sandbox usage (external resources, file ops, computation) and reduced turns (Qwen3-4B from 23.7 to 7.0), while vanilla LLM outputs gain structural organization and verification behaviors.
- Computationally, LLM-in-Sandbox reduces token usage by up to 8x in long-context tasks and averages 0.5–0.8x total tokens vs. LLM mode; environment tokens (37–51%) are fast to process, enabling competitive throughput (up to 2.2x speedup for MiniMax).
- Infrastructure is lightweight: single ~1.1GB Docker image, ~50MB idle / ~200MB peak memory per sandbox; 512 concurrent sandboxes consume only 5% of 2TB system RAM.
- LLM-in-Sandbox enables non-text outputs: generates interactive maps (.html), posters (.png/.svg), videos (.mp4), and music (.wav/.mid) via autonomous tool installation and execution, demonstrating cross-modal and file-level capabilities beyond text generation.
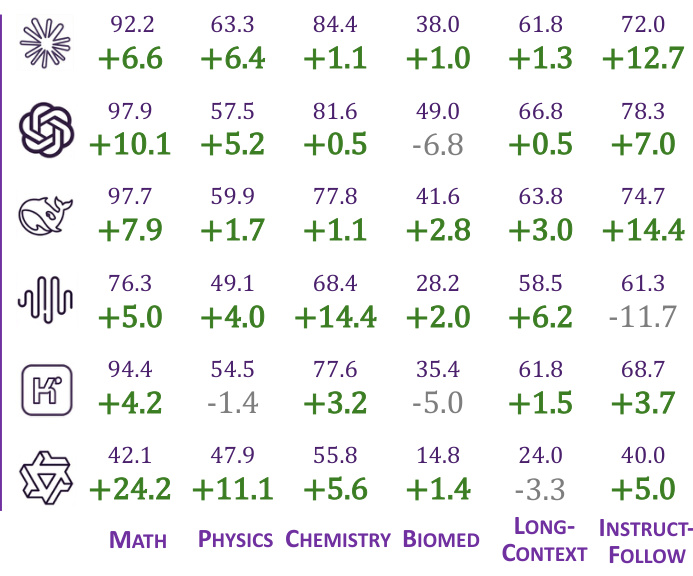
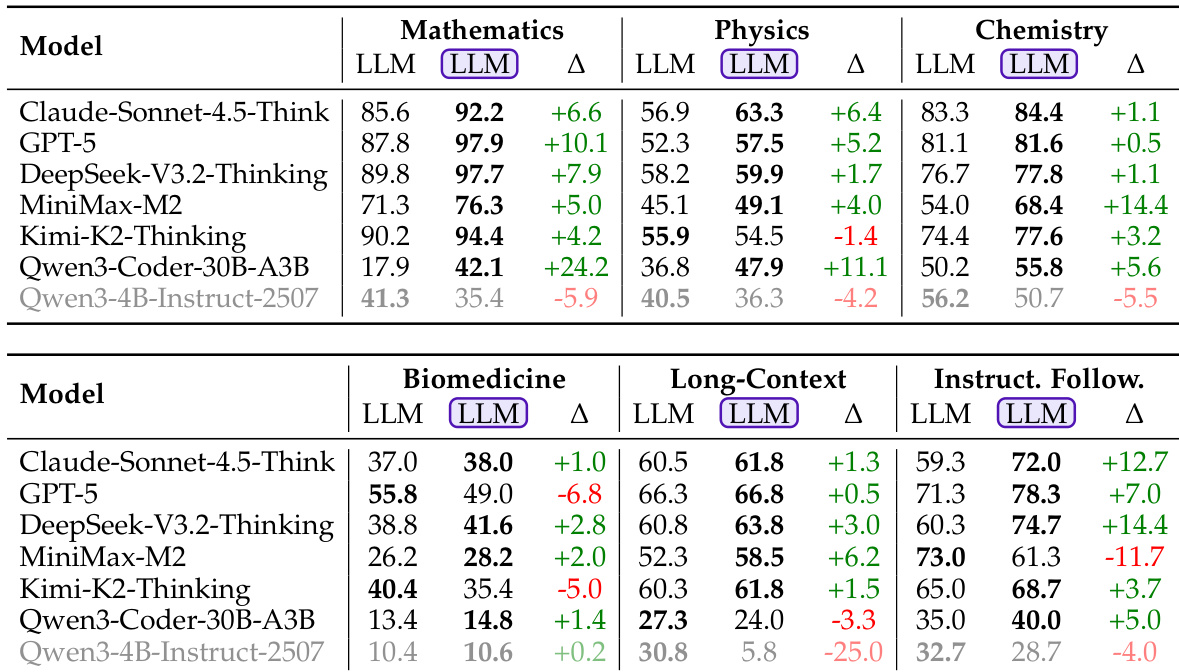
Results show that LLM-in-Sandbox significantly improves performance across most domains compared to vanilla LLM generation, with the largest gains observed in Mathematics (+24.2%) and Instruction Following (+14.4%). However, the model Qwen3-4B-Instruct performs worse in most domains, indicating that weaker models fail to effectively leverage the sandbox environment.
The authors use different inference configurations for each model, with variations in temperature, top-p, min-p, top-k, repetition penalty, and backend. The configurations are tailored to each model's specifications, with some models using API-based backends and others using SGLang or vLLM, and the maximum generation length per turn is capped at 65,536 tokens except for Claude-Sonnet-4.5-Think, which is limited to 64,000 tokens due to API constraints.
Results show that LLM-in-Sandbox consistently improves performance across most domains compared to vanilla LLM generation, with the largest gains observed in Mathematics and Long-Context tasks. The improvements are particularly significant for strong models, while weaker models like Qwen3-4B-Instruct show little to no benefit and sometimes perform worse.
Results show that strong agentic models consistently benefit from LLM-in-Sandbox across all evaluated domains, with performance improvements ranging from +1.0% to +24.2% compared to vanilla LLM generation. However, weaker models like Qwen3-4B-Instruct-2507 show significant declines in performance, particularly in Long-Context and Chemistry tasks, indicating that effective sandbox utilization depends on the model's inherent capabilities.
Results show that LLM-in-Sandbox-RL training significantly improves reasoning patterns in both strong and weak models, increasing the use of verification and structural organization in vanilla LLM mode outputs. The Qwen3-Coder-30B-A3B model sees a modest gain in verification (0.77 to 0.88) and a larger increase in structure (10.30 to 16.12), while the Qwen3-4B-Instruct-2507 model shows substantial improvements in both metrics, with verification rising from 20.22 to 36.91 and structure from 19.13 to 20.64.
