Command Palette
Search for a command to run...
EvoCUA : Évolution d'agents d'utilisation informatique par apprentissage à partir d'expériences synthétiques évolutives
EvoCUA : Évolution d'agents d'utilisation informatique par apprentissage à partir d'expériences synthétiques évolutives
Résumé
Le développement d’agents natifs d’utilisation informatique (CUA) marque une avancée significative dans le domaine de l’intelligence artificielle multimodale. Toutefois, leur potentiel est actuellement freiné par les limites imposées par l’augmentation statique des données. Les paradigmes existants, fondés principalement sur l’imitation passive de jeux de données statiques, peinent à capturer les dynamiques causales complexes inhérentes aux tâches informatiques à horizon long. Dans ce travail, nous introduisons EvoCUA, un modèle agissant natif pour l’utilisation informatique. Contrairement à l’imitation statique, EvoCUA intègre la génération de données et l’optimisation de politique dans un cycle évolutif autonome et auto-soutenable. Pour pallier le manque de données, nous avons conçu un moteur de synthèse vérifiable capable de générer de manière autonome des tâches diversifiées, associées à des validateurs exécutables. Pour permettre l’acquisition à grande échelle d’expériences, nous avons mis au point une infrastructure évolutive orchestrant des dizaines de milliers de simulations asynchrones dans des environnements sandbox. Sur la base de ces trajectoires massives, nous proposons une stratégie d’apprentissage itératif évolutif, permettant une internalisation efficace de l’expérience acquise. Ce mécanisme régule dynamiquement les mises à jour de la politique en identifiant les limites de capacité : il renforce les routines réussies tout en transformant les trajectoires d’échec en sources riches de supervision grâce à une analyse d’erreurs et une auto-correction. Les évaluations empiriques sur le benchmark OSWorld montrent que EvoCUA atteint un taux de succès de 56,7 %, établissant ainsi un nouveau record d’état de l’art open-source. Notamment, EvoCUA surpasse significativement le meilleur modèle open-source précédent, OpenCUA-72B (45,0 %), et dépasse même des modèles fermés de pointe tels que UI-TARS-2 (53,1 %). Plus important encore, nos résultats soulignent la généralisabilité de cette approche : le paradigme évolutif fondé sur l’apprentissage par expérience permet des gains de performance constants sur des modèles fondamentaux de tailles variées, ouvrant ainsi une voie robuste et évolutivement scalable pour le progrès des capacités des agents natifs.
One-sentence Summary
Researchers from Meituan, Fudan, Tongji, and HKUST propose EvoCUA, a self-evolving computer-use agent that breaks static data limits via autonomous task synthesis and scalable rollouts, achieving 56.7% success on OSWorld—surpassing prior open- and closed-source models—while generalizing across foundation model scales.
Key Contributions
- EvoCUA introduces a self-sustaining evolutionary paradigm for computer-use agents that replaces static imitation with dynamic experience generation and policy optimization, addressing the limitations of passive dataset scaling in long-horizon GUI tasks.
- The system features a verifiable synthesis engine that generates executable tasks with built-in validators and a scalable infrastructure enabling tens of thousands of asynchronous sandbox rollouts, ensuring grounded, high-throughput interaction data.
- Evaluated on OSWorld, EvoCUA-32B achieves 56.7% success—surpassing OpenCUA-72B (45.0%) and UI-TARS-2 (53.1%)—and demonstrates generalizable gains across foundation model scales through its error-driven, iterative learning strategy.
Introduction
The authors leverage a new paradigm for training computer use agents that moves beyond static imitation to an evolving cycle of synthetic experience generation and policy refinement. Prior approaches rely on fixed datasets that fail to capture the causal dynamics of real-world GUI interactions, limiting scalability and generalization. EvoCUA overcomes this by introducing a verifiable synthesis engine that generates executable tasks with built-in validators, a scalable infrastructure enabling tens of thousands of concurrent sandbox rollouts, and an iterative learning strategy that transforms failure trajectories into supervision signals. This approach achieves 56.7% success on the OSWorld benchmark, outperforming prior open-source and closed-source models, and proves generalizable across foundation model sizes.
Dataset

-
The authors construct a structured task space using a hierarchical taxonomy of desktop applications (e.g., Excel, Word, browsers) to decompose complex tasks into atomic capabilities like formula editing or data sorting, enabling compositional generalization.
-
They synthesize diverse scenarios via hybrid resource injection: parametric generators create structured documents (Word, Excel, PDF) with randomized variables (names, prices, dates), while non-parametric injection adds real-world internet content (images, slides) to simulate visual and structural noise.
-
A three-stage pipeline generates and filters data: (1) Task Space Construction defines domains and personas; (2) Agentic Dual-Stream Synthesis uses a VLM to co-generate instructions and validators via feedback loops; (3) Rigorous Quality Assurance filters outputs using sandbox rollouts, reward models, manual checks, and tri-fold decontamination to remove semantic, configuration, and evaluator overlaps with benchmarks.
-
The prior dataset 𝒟_prior is built by unifying action space (mouse, keyboard, control primitives) and structuring thought space (goal clarification, observation consistency, self-verification, reflection, reasoning-augmented termination) to enforce grounded, interpretable reasoning.
-
Trajectories are synthesized using vision-language models (e.g., Qwen3-VL) with hindsight reasoning: reasoning traces are generated retrospectively to align with known execution paths, ensuring cognitive coherence with physical actions.
-
For training, multi-turn trajectories are split into single-turn samples. The input context retains full multimodal data (screenshots, actions, reasoning) for the last five steps; earlier history is compressed into text. Loss is computed only on the current step’s reasoning and action.
-
The training mixture includes general-purpose data (STEM, OCR, visual grounding, text reasoning) scaled to match the volume of decomposed trajectory samples, preserving foundational capabilities while bootstrapping task-specific skills.
Method
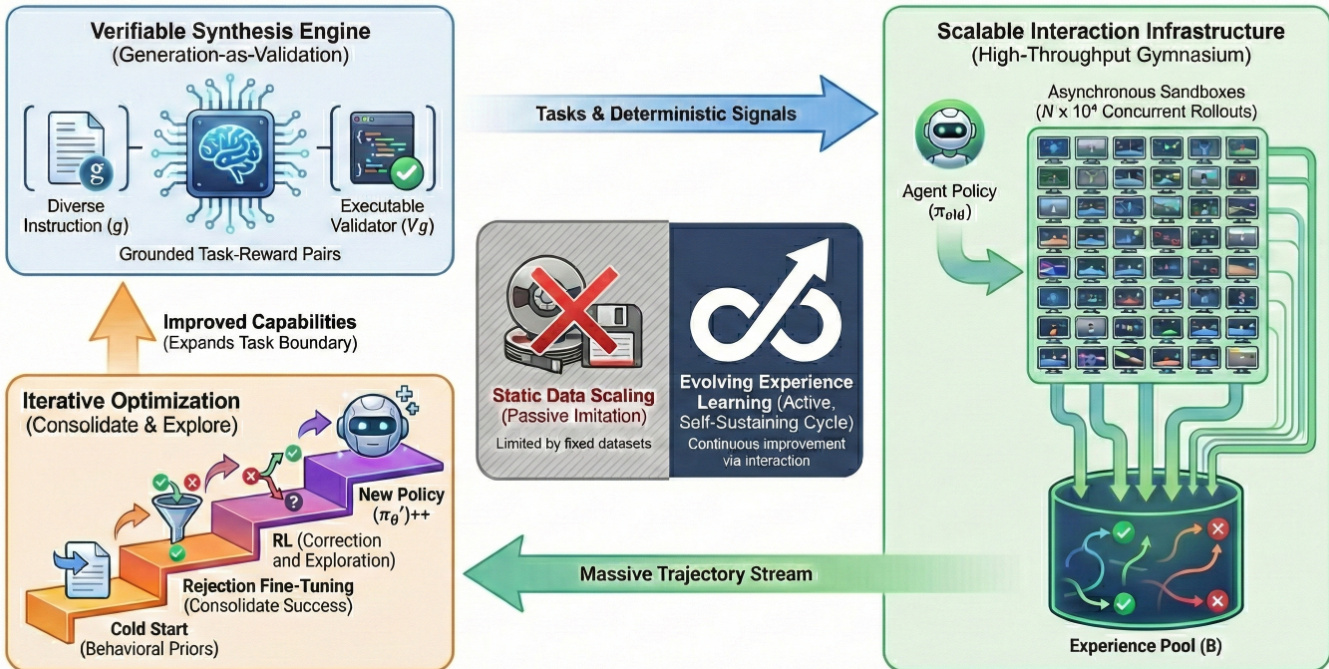
The framework of EvoCUA is structured around a dynamic, iterative learning paradigm that transitions from static imitation to active, experience-driven optimization. The overall architecture, as illustrated in the framework diagram, integrates three core components: a Verifiable Synthesis Engine, a Scalable Interaction Infrastructure, and an Evolving Experience Learning cycle. The process begins with the generation of high-quality, verifiable task-reward pairs through a synthesis engine, which feeds into a high-throughput interaction gymnasium. This infrastructure supports massive-scale, asynchronous rollouts, generating a continuous stream of interaction trajectories that are aggregated into an experience pool. The policy is then refined through a multi-stage optimization process that includes a supervised cold start, rejection sampling fine-tuning, and reinforcement learning, forming a self-sustaining loop of capability expansion.
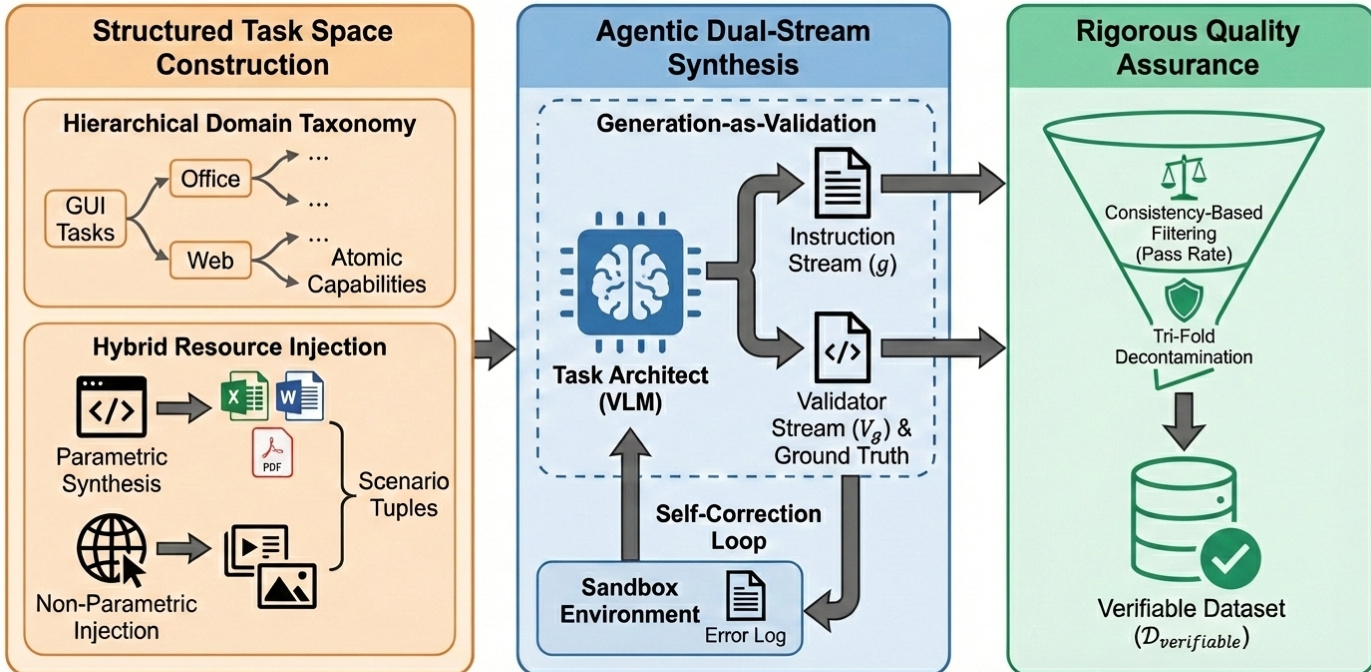
The Verifiable Synthesis Engine, detailed in the second figure, is responsible for generating task-reward pairs that are both semantically grounded and executable. This engine operates through a cascaded process involving structured task space construction, agentic dual-stream synthesis, and rigorous quality assurance. The structured task space is built upon a hierarchical domain taxonomy that categorizes tasks into GUI, Office, Web, and Atomic Capabilities, enabling systematic task generation. This is augmented by hybrid resource injection, which combines parametric synthesis (e.g., code snippets) with non-parametric injection (e.g., real-world documents and images) to create diverse scenario tuples. The core synthesis process is an agentic workflow where a foundation Vision-Language Model (VLM) acts as a task architect, simultaneously generating a natural language instruction (g) and a corresponding executable validator (Vg). This dual-stream generation is validated through a closed-loop feedback mechanism, where the generated code is executed in a sandbox environment, and the results are used to refine the output. This "generation-as-validation" paradigm ensures that the reward signal is derived from a strict verification of the final state, bypassing the ambiguity of semantic matching.
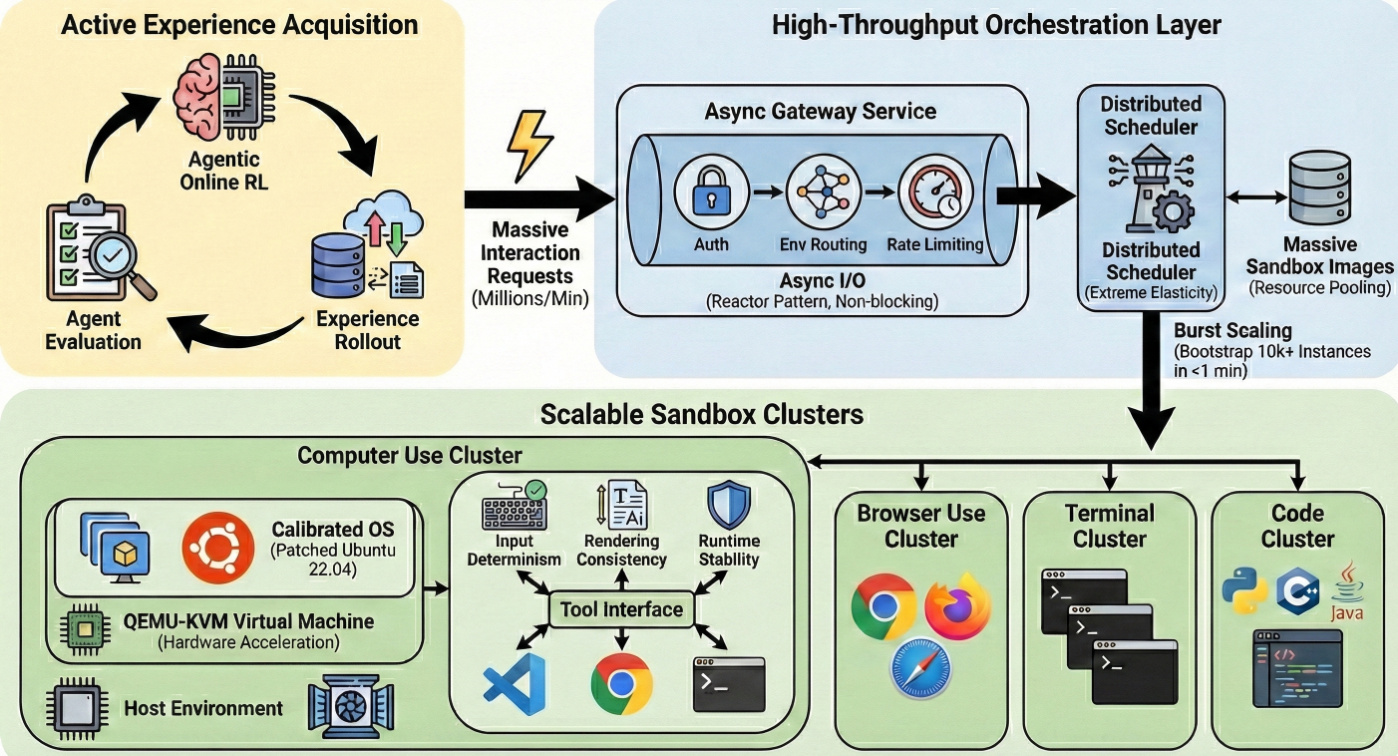
The Scalable Interaction Infrastructure, depicted in the third figure, is the backbone of the system, enabling the massive-scale generation of interaction data. This infrastructure is built on a microservices architecture designed for high throughput and low latency. It consists of an asynchronous gateway service, based on the reactor pattern, which handles millions of interaction requests per minute with non-blocking I/O, ensuring that long-running environment executions do not block critical routing logic. This gateway routes requests to a distributed scheduler, which manages the lifecycle of massive sandbox images. The scheduler leverages distributed sharding and resource pooling to achieve high-efficiency node scheduling and supports burst scaling, capable of bootstrapping tens of thousands of sandbox instances within one minute. This rapid instantiation ensures that the environment scaling strictly matches the training demand of on-policy reinforcement learning. The infrastructure is further supported by a hybrid virtualization architecture, where QEMU-KVM virtual machines are encapsulated within Docker containers, providing both security and near-native performance. The environment is calibrated with a customized OS image based on Ubuntu 22.04, which includes specific kernel and userspace patches to ensure input determinism, rendering consistency, and runtime stability.
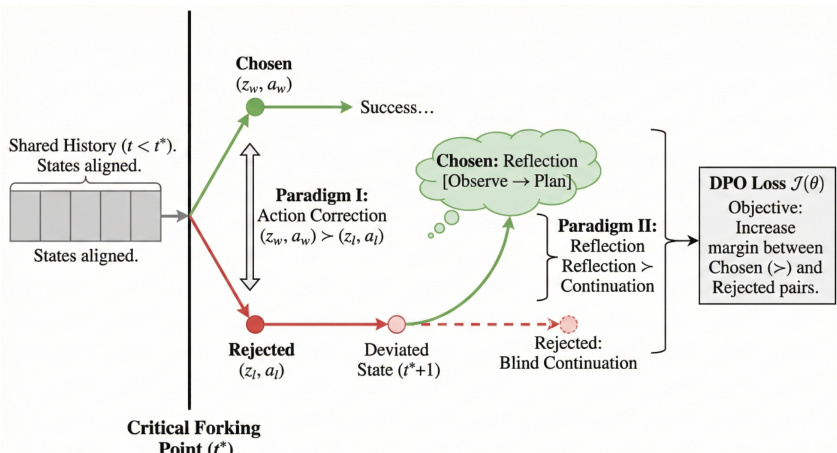
The Evolving Experience Learning paradigm, illustrated in the fourth figure, is the core optimization engine that transforms raw interaction data into a refined policy. This process is structured into three progressive stages. The first is a supervised cold start, which establishes behavioral priors by training on a small set of high-quality trajectories. The second stage is Rejection Sampling Fine-Tuning (RFT), which consolidates successful experiences by generating high-quality trajectories through dynamic compute budgeting and denoising them to maximize the signal-to-noise ratio. The final stage is reinforcement learning, which rectifies failures and explores complex dynamics. This is achieved through a Step-Level Direct Preference Optimization (DPO) strategy that targets critical forking points. Given a failed rollout and a successful reference, the system identifies the first timestamp where the agent's action diverges from the reference, despite the environmental states remaining functionally equivalent. This isolates the specific response that caused the agent to leave the optimal solution manifold. Two paradigms are then constructed: Paradigm I (Action Correction) replaces the rejected error with an optimal chosen response, and Paradigm II (Reflection) addresses the state immediately after the error by training the agent to halt and generate a reasoning chain that observes the unexpected screen state and formulates a remedial plan. The policy is optimized using a DPO loss function that maximizes the margin between effective and ineffective strategies.
Experiment
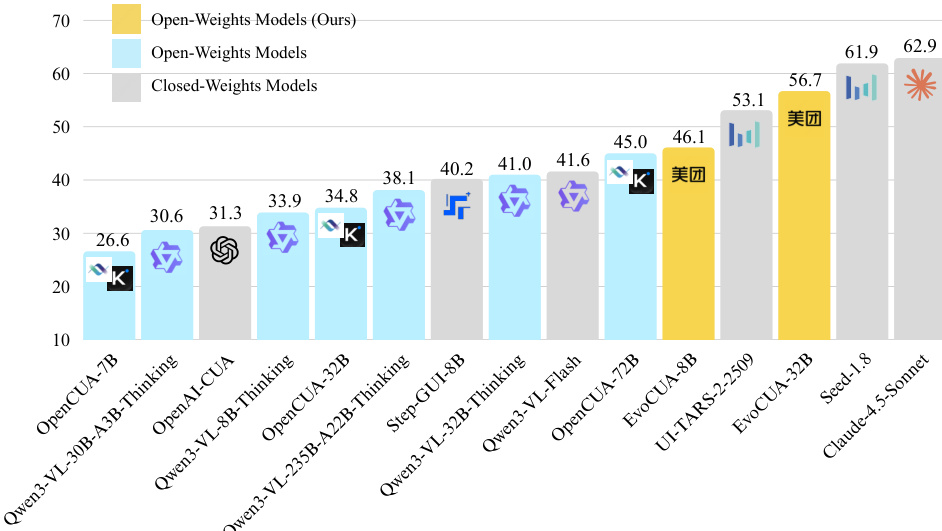
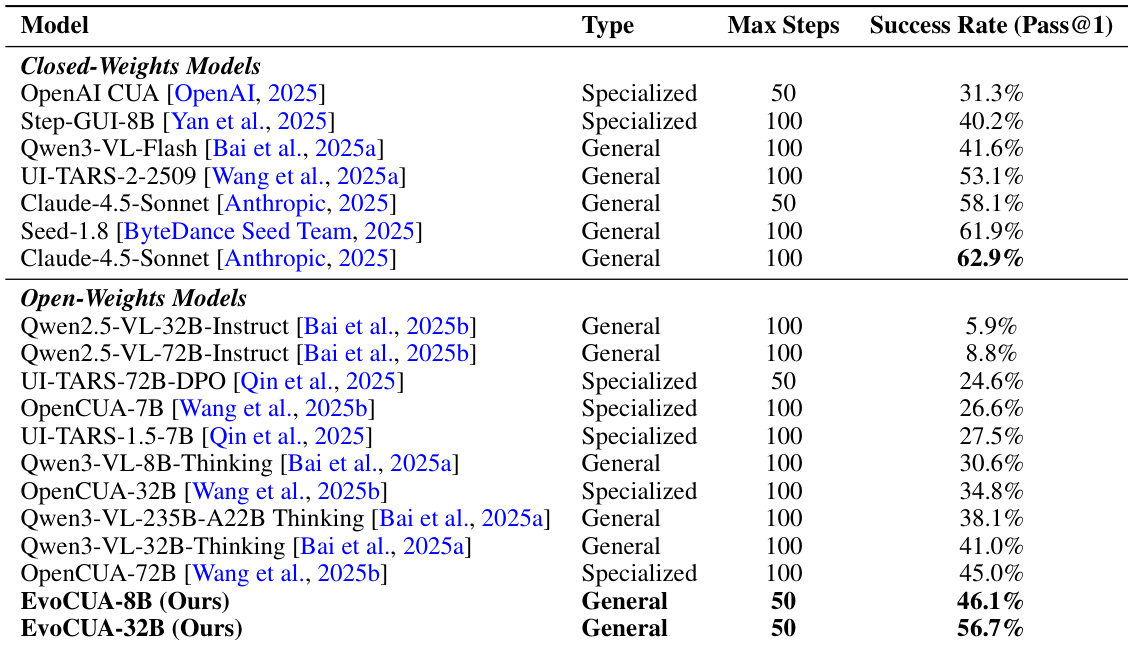
- EvoCUA-32B achieves 56.7% success rate on OSWorld, top among open-weights models, surpassing OpenCUA-72B (45.0%) by +11.7% and outperforming closed-weights UI-TARS-2-2509 (53.1%) by +3.6% under 50-step constraint.
- EvoCUA-8B (46.1%) exceeds OpenCUA-72B and Step-GUI-8B (40.2%) by +5.9%, confirming efficacy of evolving experience learning on smaller scales.
- Offline grounding and general VLM benchmarks show stable or improved performance on OpenCUA-72B backbone, but EvoCUA-32B exhibits declines on ScreenSpot-Pro and MMMU due to data distribution mismatch with Qwen3-VL-Thinking.
- Ablation studies confirm cumulative gains: unified action space (+4.84%), cold start (+2.62%), RFT (+3.13%), DPO (+3.21%), and iterative cycles (+1.90%) drive consistent improvement on Qwen3-VL-32B-Thinking.
- On OpenCUA-72B, RFT alone yields +8.12% gain over baseline, demonstrating scalability and robustness of the paradigm across model sizes.
- Scaling analysis shows EvoCUA-32B maintains +4.93% gain at Pass@16 and +16.25% improvement from 15 to 50 inference steps; experience scaling via multi-round RFT on 1M samples achieves +8.12 pp.
- Trajectory Inspector validates synthetic data quality through frame-by-frame alignment of reasoning, observation, and action, confirming logical consistency in complex tasks like spreadsheet operations.
The authors use the OSWorld benchmark to evaluate EvoCUA, showing that EvoCUA-32B achieves a 56.7% success rate, securing the top rank among open-weights models and outperforming larger baselines like OpenCUA-72B by 11.7 percentage points. This result demonstrates significant improvements in online agentic capability, with EvoCUA-32B narrowing the gap to closed-weights models and achieving competitive performance under a stricter 50-step constraint.
The authors use an ablation study to analyze the contribution of each component in the EvoCUA-32B model, showing that each stage of the evolutionary cycle provides significant monotonic improvements. Results show that the unified action space and cold start contribute +4.84% and +2.62% respectively, while rejection fine-tuning and DPO yield +3.13% and +3.21% gains, with an additional +1.90% from iterative training, confirming the self-sustaining nature of the learning paradigm.

The authors evaluate EvoCUA's performance on offline grounding and general multimodal capabilities, showing that the EvoCUA-32B variant experiences a decline in specific metrics like ScreenSpot-Pro and MMMU compared to the Qwen3-VL-32B-Thinking baseline, primarily due to a mismatch in data distribution and patterns. In contrast, EvoCUA-72B maintains or slightly improves performance across benchmarks, confirming the effectiveness of the training strategy when the base model's data distribution is aligned.

The authors use the OSWorld-Verified benchmark to evaluate EvoCUA, showing that EvoCUA-32B achieves a success rate of 56.7% under a 50-step constraint, outperforming all other open-weights models and narrowing the gap with top closed-weights models. EvoCUA-8B also surpasses larger models like OpenCUA-72B, demonstrating the effectiveness of the evolving experience learning paradigm in improving performance across different model scales.
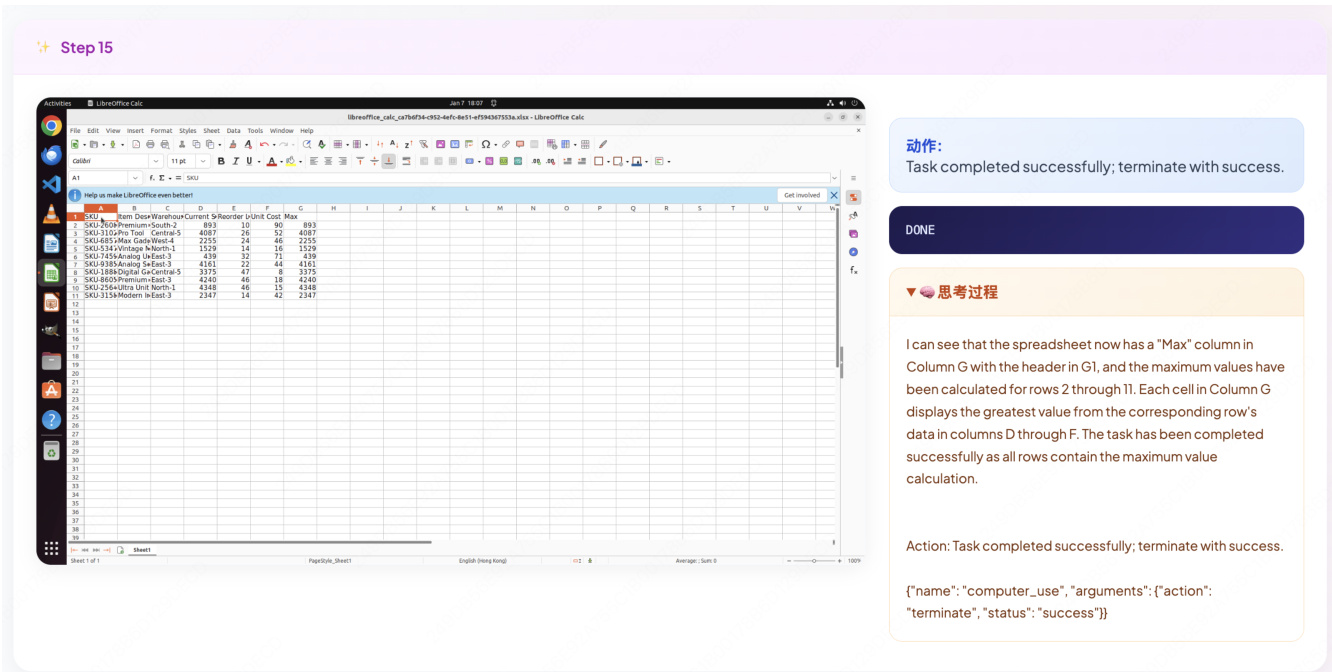
The authors use EvoCUA to perform a long-horizon spreadsheet task, successfully finding the maximum value per row and placing it in a new column. Results show the model completes the task with a successful termination, confirming the effectiveness of its reasoning and action execution in a realistic GUI environment.