Command Palette
Search for a command to run...
FutureOmni : Évaluation de la prévision de l'avenir à partir d'un contexte omni-modal pour les LLM multimodaux
FutureOmni : Évaluation de la prévision de l'avenir à partir d'un contexte omni-modal pour les LLM multimodaux
Qian Chen Jinlan Fu Changsong Li See-Kiong Ng Xipeng Qiu
Résumé
Bien que les modèles linguistiques à grande échelle multimodaux (MLLM) démontrent une perception omni-modale forte, leur capacité à prédire des événements futurs à partir de signaux audiovisuels reste largement explorée. En effet, les benchmarks existants se concentrent principalement sur la compréhension rétrospective. Pour combler cet écart, nous introduisons FutureOmni, le premier benchmark conçu pour évaluer la prédiction du futur dans des environnements audiovisuels à travers une approche omni-modale. Les modèles évalués doivent effectuer des raisonnements causaux et temporels transmodaux, ainsi qu’exploiter efficacement leurs connaissances internes afin de prévoir des événements futurs. FutureOmni est construit à l’aide d’un pipeline évolutif assisté par un grand modèle linguistique (LLM) et intégrant une interaction humaine, et comprend 919 vidéos ainsi que 1 034 paires de questions à choix multiples réparties sur 8 domaines principaux. Les évaluations menées sur 13 modèles omni-modaux et 7 modèles uniquement vidéo révèlent que les systèmes actuels peinent fortement à prédire le futur à partir de données audiovisuelles, en particulier dans les scénarios riches en discours, où la meilleure précision atteinte est de 64,8 % par Gemini 3 Flash. Pour atténuer cette limitation, nous avons constitué un jeu de données d’instruction-tuning de 7 000 échantillons et proposé une stratégie d’entraînement appelée Omni-Modal Future Forecasting (OFF). Les évaluations sur FutureOmni ainsi que sur des benchmarks populaires audiovisuels et vidéo uniquement montrent que OFF améliore significativement la prédiction du futur et la généralisation. Nous mettons publiquement à disposition tout le code (https://github.com/OpenMOSS/FutureOmni) ainsi que les jeux de données (https://huggingface.co/datasets/OpenMOSS-Team/FutureOmni).
One-sentence Summary
Researchers from Fudan University, Shanghai Innovation Institute, and National University of Singapore introduce FutureOmni, the first benchmark for audio-visual future forecasting, and propose the Omni-Modal Future Forecasting (OFF) strategy with a 7K-sample dataset to improve cross-modal temporal reasoning, significantly boosting performance on future event prediction tasks.
Key Contributions
- We introduce FutureOmni, the first benchmark for evaluating multimodal LLMs on future event forecasting from audio-visual inputs, requiring cross-modal causal and temporal reasoning across 919 videos and 1,034 QA pairs spanning 8 domains.
- Evaluations on 20 models reveal that even top-performing systems like Gemini 3 Flash achieve only 64.8% accuracy, highlighting significant limitations in current omni-modal future prediction—especially in speech-heavy contexts.
- We propose the Omni-Modal Future Forecasting (OFF) training strategy with a 7K-sample instruction-tuning dataset, which improves future forecasting performance and generalization on FutureOmni and other benchmarks, as evidenced by attention visualizations and cross-domain gains.
Introduction
The authors leverage the growing capabilities of multimodal large language models (MLLMs) to tackle a critical gap: forecasting future events from joint audio-visual inputs, which matters for real-world applications like autonomous driving where sound and sight must be fused to anticipate outcomes. Prior benchmarks focus on retrospective reasoning or ignore audio, leaving models untested on cross-modal causal prediction—especially in speech-heavy contexts. Their main contribution is FutureOmni, the first benchmark for omni-modal future forecasting, paired with a 7K-sample instruction-tuning dataset and an Omni-Modal Future Forecasting (OFF) training strategy that boosts model performance and generalization across domains.
Dataset

The authors use a curated dataset called FutureOmni, built from YouTube videos, to evaluate multimodal future forecasting. Here’s how it’s composed and used:
-
Dataset Composition and Sources:
The authors start with ~18K YouTube videos (30 sec–20 min), filtering them using visual and audio criteria. They retain only 9K videos after removing those with low scene change (inter-frame similarity >70%) or weak audio-visual alignment (via semantic gap analysis using UGCVideoCaptionier). Final dataset contains 919 high-quality videos and 1,034 QA pairs. -
Key Subset Details:
- Size: 919 videos, 1,034 QA pairs.
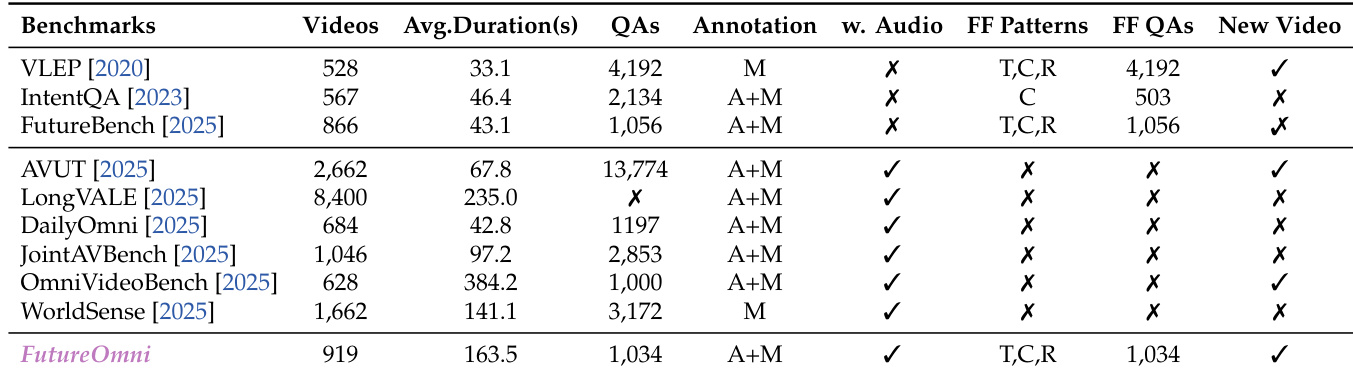
- Duration: Avg. 163.5 sec — longer than VLEP (33.1s) or FutureBench (43.1s).
- Annotation: 100% focused on future forecasting (vs. retrospective tasks in WorldSense/DailyOmni).
- Reasoning Types: Covers Thematic Montage (T), Causal (C), Routine Sequences (R) — unlike benchmarks limited to single logic types.
- Categories: 8 major groups (e.g., Cartoon, Education, Emergency, Surveillance, Daily Life, Movie) with 21 fine-grained subcategories for domain diversity.
-
How the Data Is Used:
- Training/evaluation uses the full 919-video set with 1,034 QA pairs.
- QA pairs target cross-modal causal reasoning — premise and conclusion events must integrate audio and video, require high-level reasoning, and avoid commonsense or descriptive associations.
- Each QA includes precise timestamps, modality labels, and a rationale to ensure challenging, non-obvious relationships.
-
Processing and Metadata:
- Videos are filtered for scene dynamics and audio dependency using frame similarity and captioning gap metrics.
- Annotations follow strict output format:
has_causal: [modality] to [modality], with start/end times and event descriptions. - Metadata includes key modality (Visual/Audio/Both) per question and detailed rationales for correct answers.
- Evaluation prompts present video frames + audio, asking models to select the correct future event from multiple choices — response is a single letter (A–E).
Method
The authors present a comprehensive framework for audio-visual temporal localization and causal reasoning, structured into distinct stages that integrate multimodal inputs to construct a rich, event-based timeline. The overall process begins with audio-coordinated video selection, where videos are filtered based on domain relevance and dynamic scene coordination, ensuring that the input data is both semantically and temporally coherent. This initial filtering step leverages a curated list of video domains, including surveillance, daily life, education, and emergency scenarios, to ensure diversity and applicability across real-world contexts. The filtered videos are then processed through an audio-visual temporal localization and calibration module, which employs a grounding prompt to identify plot-relevant events and generate precise timestamps in MM:SS format. This step is critical for isolating meaningful events from static or trivial background occurrences, thereby establishing a dense temporal timeline.
As shown in the figure below, the localization process involves a time boundary checking mechanism to validate the precision of the identified event durations. This is achieved by computing Mel-frequency cepstral coefficients (MFCCs) at the start and end points of each event, with transitions validated if the MFCC difference exceeds a pre-defined threshold of 2.0, indicating acoustic discontinuities that align with meaningful event boundaries. Following boundary validation, the system enriches the temporal segments through an audio fulfillment step, where Gemini 2.5 Flash is prompted to identify and annotate specific acoustic cues—such as dialogue, sound effects, or background music—that occur synchronously with the visual content. This ensures that significant audio events are captured alongside the visual action, enhancing the multimodal richness of the timeline.
The next phase, audio-visual QA construction, involves extracting logical cause-and-effect pairs from sequential events. This process, illustrated in the framework diagram, consists of two key components: causal pair discovery and dual-stage verification. In causal pair discovery, DeepSeek-V3.2 is employed to analyze adjacent event segments, with a strict temporal constraint limiting the gap between the premise and target event to a maximum of 30 seconds. The model is instructed to determine if the subsequent event is a direct logical consequence of the former, outputting three components: the premise event, the target event, and a rationale that bridges the causal gap. To explicitly mine pairs driven by acoustic cues, the model assigns a contribution score on a scale of 0 to 2, where 0 indicates no influence, 1 denotes decoration, and 2 signifies causality, while classifying the audio factor into speech, sound, or music categories.
The QA construction phase introduces four novel distractor types to rigorously evaluate multimodal reasoning: visual-only perception, audio-only perception, delayed, and reverse-causal. These distractors are designed to challenge models that fail to integrate auditory cues, over-rely on audio transcripts, lack temporal precision, or misunderstand the directional arrow of time. The framework ensures that candidate QAs are submitted to GPT-4o for automated logical validation, followed by human verification to mitigate ambiguity and ensure data quality.
Finally, the authors curate a high-quality instruction tuning dataset, FutureOmni-7K, and propose an Omni-Modal Future Forecasting method. This method integrates rationales derived from the data construction pipeline into each training instance, explicitly exposing the reasoning chain that elucidates why a specific future event follows from the audio-visual premise. By teaching the model not just to predict the outcome but to internalize the reasoning logic of future prediction, the framework aims to bridge the gap in current MLLMs' omni-modal future forecasting capabilities. The entire process is designed to enhance the model's ability to reason across modalities and time, ensuring robust and generalizable performance in complex, real-world scenarios.
Experiment
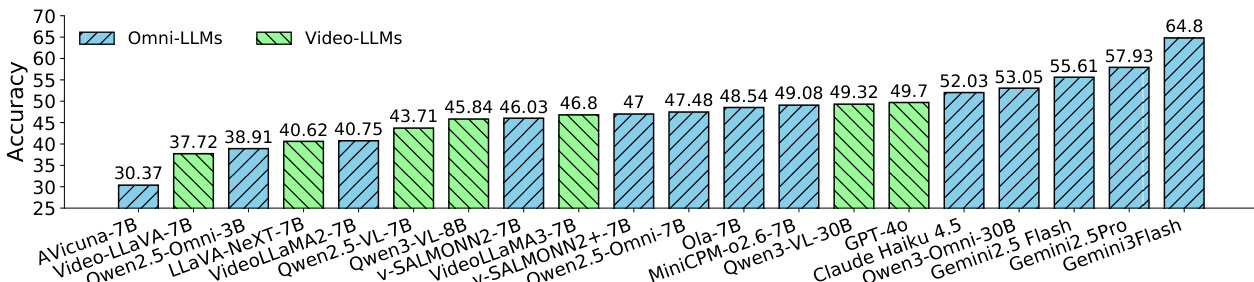
- Evaluated 20 MLLMs on FutureOmni, including open-source video-audio, video-only, and proprietary models; proprietary models (Gemini 2.5 Pro, Gemini 3 Flash) led with ~61% avg accuracy vs. 53% for top open-source Omni-LLM (Qwen3-Omni).
- Video-only models underperformed Omni-LLMs (e.g., GPT-4o at 49.70%), confirming audio-visual integration is critical for future event prediction.
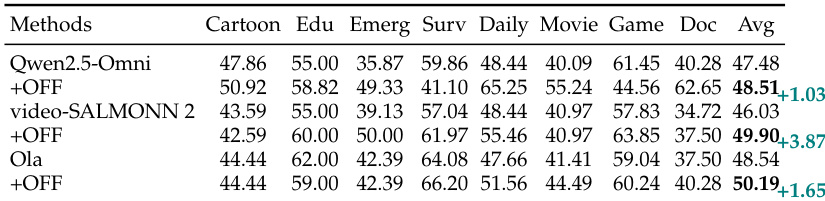
- Domain performance varied: Game/Dailylife (e.g., Qwen3-Omni 62.65% on Game) outperformed Documentary/Emergency (avg 20–40%), due to complex narration or chaotic cues.
- Contextual Cold Start observed: all models performed worst on shortest videos (e.g., Qwen3-Omni 34.90% at <1 min), peaking at 2–4 min duration.
- Speech was hardest modality (Qwen3-Omni: 47.99% vs. 57.54% on Music), highlighting need for linguistic-audiovisual alignment.
- Modality ablation confirmed A+V synergy is essential: Qwen2.5-Omni dropped ~5% when deprived of either modality; subtitles/captions underperformed raw audio.
- Error analysis (Gemini 3 Flash) showed 51.6% errors from video perception, 30.8% from audio-video reasoning failure, and only 2.5% from knowledge gaps.
- Fine-tuning on FutureOmni-7K boosted performance: video-SALMONN 2 gained +3.87% overall; Qwen2.5-Omni improved ~10% on speech tasks.
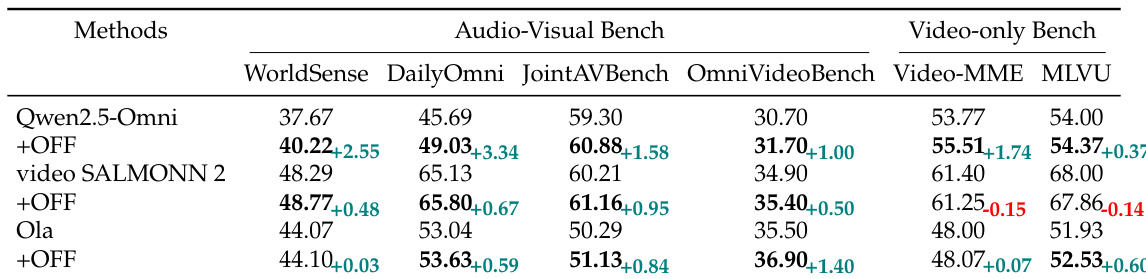
- Fine-tuned models generalized to out-of-domain benchmarks (WorldSense, DailyOmni, Video-MME, MLVU), e.g., Qwen2.5-Omni up +2.55% on WorldSense and +1.74% on Video-MME.
- Attention visualization revealed trained models increased focus on both video and audio keyframes across transformer layers, supporting cross-modal reasoning.
The authors evaluate the impact of instruction tuning on open-source omni-modal models using the FutureOmni-7K dataset, showing that fine-tuning leads to consistent performance improvements across multiple benchmarks. Results indicate that the tuned models achieve significant gains, particularly in the challenging Speech category, and demonstrate enhanced generalization to both audio-visual and video-only tasks, suggesting that future prediction training improves cross-modal reasoning and visual understanding.
The authors use FutureOmni to evaluate multimodal models across various benchmarks, highlighting its unique characteristics such as longer average video duration and inclusion of audio-visual annotations. Results show that FutureOmni stands out with a higher number of questions and a focus on future prediction, distinguishing it from other benchmarks that emphasize different tasks like action recognition or general QA.
The authors evaluate the performance of open-source and proprietary multimodal models on the FutureOmni benchmark, with results showing that proprietary models like Gemini 3 Flash achieve higher average accuracy (61%) compared to the best open-source model, Qwen2.5-Omni, which scores 47.48%. Fine-tuning the models on FutureOmni-7K leads to significant improvements, particularly in the Speech category, and enhances generalization across various audio-visual and video-only benchmarks.
The authors evaluate a range of open-source and proprietary multimodal models on the FutureOmni benchmark, with results showing that proprietary models like Gemini 3 Flash achieve the highest average accuracy of 64.80%, outperforming open-source models such as Qwen3-Omni at 53.05%. The table highlights that video-only models generally underperform compared to audio-visual models, with the strongest video-only model, GPT-4o, scoring 49.70%, while the best audio-visual model, Gemini 3 Flash, reaches 64.80%.

The authors use a benchmark to evaluate the performance of various multimodal large language models on future event prediction, comparing open-source and proprietary models across audio-visual and video-only settings. Results show that proprietary Omni-LLMs achieve higher accuracy than open-source models, and that models with both audio and video inputs outperform those using only one modality, highlighting the importance of multimodal integration.