Command Palette
Search for a command to run...
MemoryRewardBench : Évaluation des modèles de récompense pour la gestion de la mémoire à long terme dans les grands modèles linguistiques
MemoryRewardBench : Évaluation des modèles de récompense pour la gestion de la mémoire à long terme dans les grands modèles linguistiques
Zecheng Tang Baibei Ji Ruoxi Sun Haitian Wang WangJie You Zhang Yijun Wenpeng Zhu Ji Qi Juntao Li Min Zhang
Résumé
Les travaux existants adoptent de plus en plus des mécanismes centrés sur la mémoire pour traiter les contextes longs de manière segmentée, et une gestion efficace de la mémoire constitue l'une des capacités clés qui permet aux grands modèles linguistiques de propager de manière efficace l'information sur l'ensemble de la séquence. Il est donc crucial d'utiliser des modèles de récompense (RMs) pour évaluer automatiquement et de façon fiable la qualité de la mémoire. Dans ce travail, nous introduisons MemoryRewardBench, le premier benchmark conçu pour étudier de manière systématique la capacité des RMs à évaluer les processus de gestion de la mémoire à long terme. MemoryRewardBench couvre à la fois des tâches de compréhension de contexte long et des tâches de génération de texte long, comprenant 10 configurations distinctes présentant différentes stratégies de gestion de la mémoire, avec une longueur de contexte variant de 8K à 128K jetons. Les évaluations menées sur 13 RMs de pointe révèlent une réduction progressive de l'écart de performance entre les modèles open-source et les modèles propriétaires, les modèles de nouvelle génération surpassant de manière constante leurs prédécesseurs, indépendamment de leur nombre de paramètres. Nous mettons également en lumière les capacités ainsi que les limites fondamentales des RMs actuels dans l'évaluation de la gestion de la mémoire des grands modèles linguistiques dans diverses configurations.
One-sentence Summary
Researchers from Soochow University, LCM Laboratory, and China Mobile introduce MemRewardBench, the first benchmark evaluating reward models’ ability to assess long-context memory management in LLMs across 10 diverse settings up to 128K tokens, revealing performance trends and limitations in current models.
Key Contributions
- MemRewardBench is the first benchmark designed to evaluate how well reward models (RMs) can assess long-term memory management in LLMs, covering 10 diverse settings across comprehension and generation tasks with context lengths from 8K to 128K tokens.
- The benchmark introduces two evaluation criteria — outcome-based and process-based — to isolate memory management quality from final output correctness, enabling a more nuanced assessment of RM capabilities in judging memory trajectories.
- Evaluations on 13 state-of-the-art RMs reveal that newer-generation models outperform older ones regardless of size, and that the performance gap between open-source and proprietary models is narrowing, while also exposing key limitations in current RM behavior across memory patterns.
Introduction
The authors leverage reward models (RMs) to evaluate how well large language models manage long-term memory during segmented processing of extended contexts — a critical capability for applications like multi-turn dialogue and long-form reasoning. Prior benchmarks either assess memory via manual annotation or outcome-based metrics, lacking automated, process-oriented evaluation of memory updates themselves. MemRewardBench fills this gap by introducing the first systematic benchmark that tests 13 RMs across 10 memory management scenarios, spanning 8K to 128K tokens, with both outcome-based and process-based evaluation criteria. Their key findings reveal that newer-generation RMs outperform older ones regardless of size, and that open-source models now rival proprietary ones on reasoning tasks — though they still lag on memory-intensive generation and dialogue tasks.
Dataset

The authors use MemRewardBench to evaluate reward models (RMs) on their ability to judge long-term memory management in LLMs across three core tasks: Long-context Reasoning, Multi-turn Dialogue Understanding, and Long-form Generation. Each task is designed to assess distinct memory capabilities—MR (Multi-hop Reasoning), TR (Temporal Reasoning), KU (Knowledge Update), DU (Dialogue Understanding), and GEN (Generation)—with both outcome-based and process-based evaluation criteria.
Key dataset subsets and construction:
-
Long-context Reasoning (based on BABILong and LongMIT):
- Size: Not explicitly stated, but built from existing long-context datasets.
- Construction: Uses MemAgent to generate memory trajectories. Chosen samples are correct final outcomes; rejected samples are created via two perturbations:
- NOISE: Injecting redundant or incorrect memory updates (using weaker LLMs + LLM-as-judge correction loop).
- DROP: Removing key context chunks to induce missing evidence.
- Mixed pattern: Combines parallel processing (p=2 or 3 chunks) with sequential aggregation.
- Filtering: Discards trajectories where chosen samples fail to answer correctly; ensures key info is fully contained in one chunk.
-
Multi-turn Dialogue Understanding (based on LoCoMo and MemoryAgentBench):
- Size: Not specified, but includes two memory systems: A-Mem (semantic tagging) and Mem0 (global summary).
- Construction: Chosen samples = full-turn memory updates leading to correct answers. Rejected samples = skipped updates, categorized as:
- MEM: Correct final answer but flawed memory management.
- OUT: Incorrect answer due to missing key info.
- Filtering: Only retains samples where chosen trajectories yield correct answers.
-
Long-form Generation (based on LongProc, LongGenBench, LongEval):
- Size: Not specified, but uses path-traversal (LongProc) and constraint-driven generation (LongGenBench/LongEval).
- Construction:
- Sequential: Decompose instruction into step-wise constraints; generate incrementally.
- Parallel: Decompose instruction into sub-tasks; generate independently then aggregate.
- Chosen samples: Gold-standard outputs satisfying all constraints (block-wise verified by strong LLM).
- Rejected samples: Generated via constraint perturbation (LongEval) or omission (LongGenBench), preserving output length.
- Filtering: Rejects samples with hallucinated or missing intermediate memory states.
How the data is used in training:
- The authors construct preference pairs (chosen vs. rejected) for each task and memory pattern (Sequential, Mixed, MEM, OUT).
- Training splits are not explicitly defined, but the benchmark is designed for RM evaluation, not training.
- No cropping is mentioned; instead, context is chunked (Long-context Reasoning) or decomposed (Long-form Generation) to simulate memory management.
- Metadata includes memory trajectory type (Sequential/Mixed), perturbation type (NOISE/DROP), and outcome/memory quality labels (MEM/OUT).
- Processing includes LLM-as-judge validation, constraint decomposition, and trajectory caching for reproducibility.
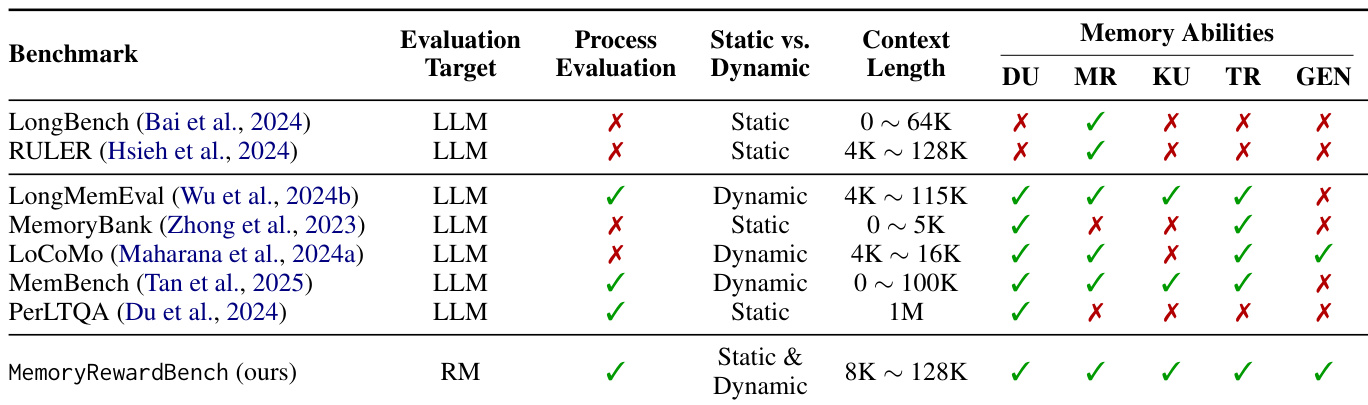
MemRewardBench uniquely emphasizes process-level evaluation of intermediate memory states, supporting both static (Long-context, Long-form) and dynamic (Dialogue) settings, and covers a broader context length range than prior benchmarks.
Method
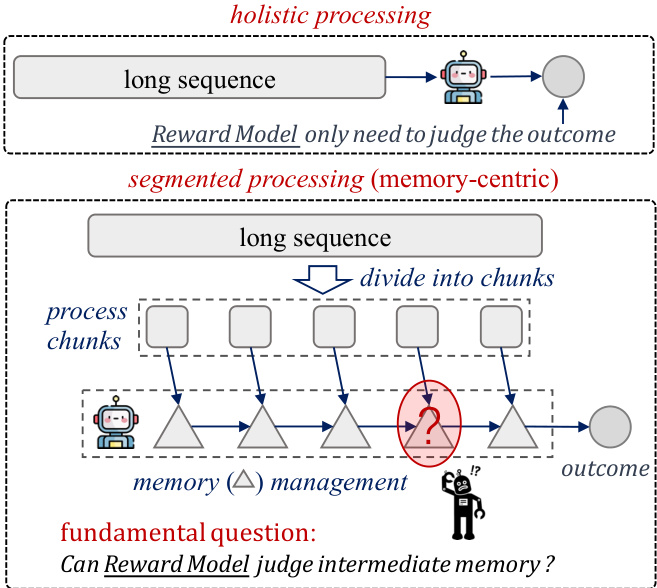
The authors leverage a memory management framework designed to process long sequences by decomposing them into manageable chunks, with the core mechanism governed by two fundamental patterns: sequential and parallel processing. As shown in the figure below, the overall approach begins with a long sequence that is segmented into smaller chunks, which are then processed through a memory-centric mechanism to produce a final outcome. The framework distinguishes between holistic processing, where the entire sequence is treated as a single unit, and segmented processing, where the sequence is divided and processed in parts, raising the central question of whether the reward model can effectively judge intermediate memory states.
The sequential pattern processes chunks one after another, maintaining a single evolving memory state. Given a model Φ and a sequence of chunks C={c1,c2,⋯,cn}, the intermediate memory M={m1,m2,⋯,mn} is updated step-by-step: m1=Φ(c1), and for t=2,⋯,n, mt=Φ(mt−1,ct). The final outcome is derived from the last memory state mn. In contrast, the parallelism pattern partitions the input context into k independent groups C={G1,⋯,Gk}, where each group Gj={cj,1,⋯,cj,nj} is processed in parallel. Within each group, the sequential pattern is applied to update memory states, resulting in a final memory state m(j) for each group. The final outcome is obtained by aggregating all m(j) through a fusion operation g: o=q(m(1),⋯,m(k)).
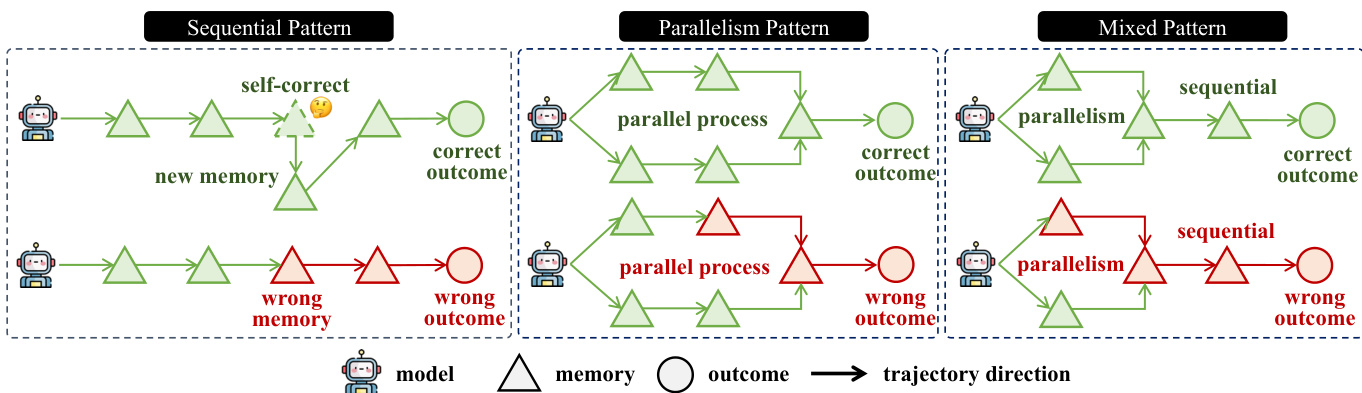
Any memory management strategy can be classified as an instance of either the sequential or parallelism pattern, or a composition of both, referred to as the mixed pattern. The mixed pattern combines both sequential and parallel processing steps, allowing for more complex and flexible memory management. The framework is designed to handle various processing scenarios, including self-correction and error propagation, as illustrated by the different trajectories in the diagram. The model's ability to manage memory effectively across these patterns is crucial for accurate outcome prediction.
Experiment
- Evaluated 13 LLMs (3 proprietary, 10 open-source) as reward models (RMs) for memory management; proprietary models lead overall, with Claude-Opus-4.5 achieving 74.75 average accuracy, followed by Gemini-3.0-Pro at 71.63; GLM4.5-106A12B (68.21) outperforms proprietary Qwen3-Max (67.79) and leads open-source models.
- Sequential memory management patterns yield significantly higher RM accuracy than parallel patterns across long-context reasoning and long-form generation tasks, indicating RMs favor step-by-step reasoning.
- RMs exhibit strong consistency under outcome-based criteria but show positional bias and inconsistency under process-based criteria, where both outcomes are correct but trajectories differ.
- RM performance peaks at ~25% constraint density in long-form generation; beyond that, gains plateau or decline, revealing limited capacity to handle dense, multifaceted constraints.
- Most RMs maintain >50% accuracy up to 64K tokens, but performance degrades sharply beyond 32K for many models; Llama-3.3-70B-Instruct collapses at 64K/128K despite large scale, while GLM-4.5-Air and Qwen2.5-72B-Instruct remain stable.
- Adding semantic tags to memory updates in multi-turn dialogue boosts RM accuracy by providing concise context, reducing reliance on parsing verbose trajectories.
- Qwen3-14B outperforms larger models like Qwen2.5-72B and Llama-3.3-70B due to post-training enhancements, excelling in constraint adherence and reasoning fidelity despite smaller size.
The authors use MemoryRewardBench to evaluate reward models across multiple memory-related tasks, comparing their performance against existing benchmarks. Results show that MemoryRewardBench supports both static and dynamic memory evaluation, covers a wide context length range, and assesses diverse memory abilities, making it a comprehensive framework for evaluating LLM memory management.
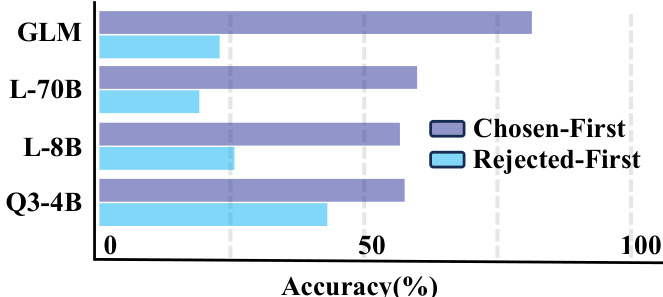
Results show that RMs achieve significantly higher accuracy under the Sequential pattern compared to the Parallel pattern across all models and tasks. The average accuracy for Sequential processing is consistently higher than for Parallel processing, indicating a strong preference for step-by-step reasoning in current reward models.
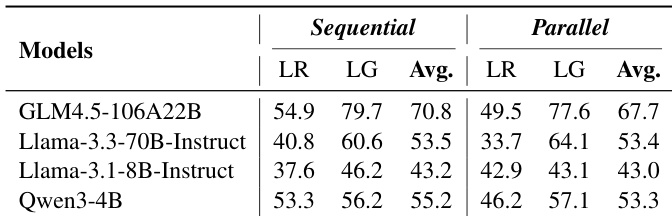
Results show that RMs achieve significantly higher accuracy under the Sequential memory management pattern compared to the Parallel pattern, with the Sequential pattern yielding average scores of 68.3 and 58.6 for Chosen-First and Rejected-First respectively, while the Parallel pattern scores 49.4 and 55.0. This indicates a strong preference for step-by-step reasoning processes in current reward models.
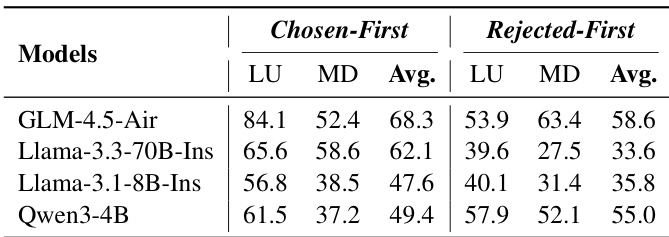
Results show that the Sequential memory management pattern consistently outperforms the Parallel pattern across all tasks, with the Sequential pattern achieving higher accuracy in Long-context Understanding, Multi-turn Dialogue, and Long-form Generation. The average performance across all models is significantly better under the Sequential pattern, indicating a strong preference for step-by-step reasoning processes in current reward models.
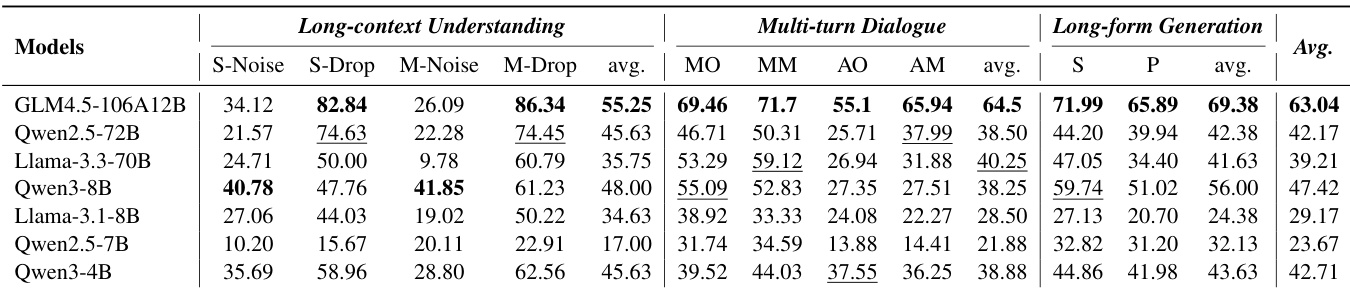
Results show that RMs achieve significantly higher accuracy under the Sequential pattern compared to the Parallel pattern, with the Sequential pattern consistently outperforming the Parallel pattern across all models. The authors use this comparison to conclude that current RMs exhibit a stronger preference for progressive, step-by-step reasoning processes, which aligns more closely with the causal structures commonly present in models' training data.