Command Palette
Search for a command to run...
A^3-Bench : Évaluation du raisonnement scientifique piloté par la mémoire à l’aide de l’activation d’ancrage et d’attracteur
A^3-Bench : Évaluation du raisonnement scientifique piloté par la mémoire à l’aide de l’activation d’ancrage et d’attracteur
Jian Zhang Yu He Zhiyuan Wang Zhangqi Wang Kai He Fangzhi Xu Qika Lin Jun Liu
Résumé
La raison scientifique repose non seulement sur l'inférence logique, mais également sur l'activation des connaissances antérieures et des structures expérientielles. La mémoire permet une réutilisation efficace des connaissances et renforce la cohérence et la stabilité du raisonnement. Toutefois, les benchmarks existants évaluent principalement les réponses finales ou la cohérence étape par étape, en ignorant les mécanismes fondés sur la mémoire qui sous-tendent le raisonnement humain — mécanismes qui impliquent l'activation d'ancres et d'attracteurs, puis leur intégration dans un raisonnement à plusieurs étapes. Pour combler cette lacune, nous proposons A^3-Bench~ https://a3-bench.github.io, un benchmark conçu pour évaluer le raisonnement scientifique à travers une activation à double échelle fondée sur la mémoire, ancrée dans les concepts d’activation d’ancres et d’attracteurs. Premièrement, nous annotons 2 198 problèmes de raisonnement scientifique couvrant divers domaines à l’aide du processus SAPM (subject, anchor & attractor, problem, memory developing). Deuxièmement, nous introduisons un cadre d’évaluation à double échelle basé sur les ancres et les attracteurs, ainsi qu’un indicateur AAUI (Anchor--Attractor Utilization Index) pour mesurer les taux d’activation de la mémoire. Enfin, à travers des expérimentations menées avec divers modèles de base et paradigmes, nous validons A^3-Bench et analysons l’impact de l’activation de la mémoire sur les performances de raisonnement, offrant ainsi des perspectives précieuses sur le raisonnement scientifique piloté par la mémoire.
One-sentence Summary
The authors from Xi'an Jiaotong University and the National University of Singapore propose A³-Bench, a dual-scale memory-driven benchmark for scientific reasoning that evaluates anchor and attractor activation via the SAPM annotation framework and AAUI metric, revealing how memory utilization enhances reasoning consistency beyond standard coherence or answer accuracy.
Key Contributions
-
We introduce A3-Bench, a novel benchmark for scientific reasoning that explicitly models human-like memory mechanisms through dual-scale annotations of anchors (foundational knowledge) and attractors (experience-based templates), derived via the SAPM process across 2,198 problems in math, physics, and chemistry.
-
The benchmark features a dual-scale evaluation framework and the AAUI (Anchor-Attractor Utilization Index) metric, which quantifies memory activation rates by measuring how effectively models retrieve and apply relevant knowledge in context-dependent, multi-step reasoning.
-
Experiments across ten LLMs and three memory paradigms demonstrate that enhanced memory activation significantly improves reasoning accuracy while maintaining efficient token usage, validating A3-Bench as a cognitively aligned tool for fine-grained evaluation and development of memory-driven models.
Introduction
Scientific reasoning in large language models (LLMs) requires more than logical inference—it demands the dynamic activation of prior knowledge structured like human memory. Current benchmarks focus on final answer accuracy or step-by-step coherence, failing to assess whether models effectively retrieve and activate relevant knowledge during reasoning. This gap limits the ability to diagnose failures due to flawed logic versus poor memory utilization. The authors introduce A3-Bench, the first benchmark designed to evaluate memory-driven scientific reasoning through the lens of Anchor and Attractor Activation. They annotate 2,198 problems across math, physics, and chemistry using the SAPM framework, mapping each to foundational knowledge units (anchors) and experience-based reasoning templates (attractors). To measure memory activation, they propose the AAUI metric within a dual-scale evaluation framework, enabling fine-grained analysis of when and how models engage memory. Experiments show that models leveraging anchor-attractor activation achieve higher accuracy with controlled token costs, revealing critical insights into memory utilization and guiding the development of more cognitively aligned LLMs.
Dataset

- The A3-Bench dataset is constructed from four existing benchmark datasets: MathVista, OlympiadBench, EMMA, and Humanity's Last Exam, covering math, physics, and chemistry domains.
- The dataset is organized into a hierarchical taxonomy: Math (8 subdomains), Physics (5 subdomains), and Chemistry (5 subdomains), based on established classification systems like MSC, higher-education curricula, and IUPAC standards.
- Each question undergoes a four-stage refinement process: (1) initial screening using three LLMs (GPT-5, Deepseek-V3.2, Qwen-30B), with only questions answered incorrectly by at least one model retained; (2) cross-analysis by the same LLMs, where two evaluate the reasoning of the third, followed by human expert revision to enhance multi-step reasoning; (3) assessment via 10 repeated answers per question from each of the three models, with difficulty classified as Easy (15–30 correct), Medium (5–14), or Difficult (0–4) based on majority correctness.
- Questions are assigned to subdomains via a voting mechanism among three LLMs, with human experts verifying and finalizing the classification and secondary discipline.
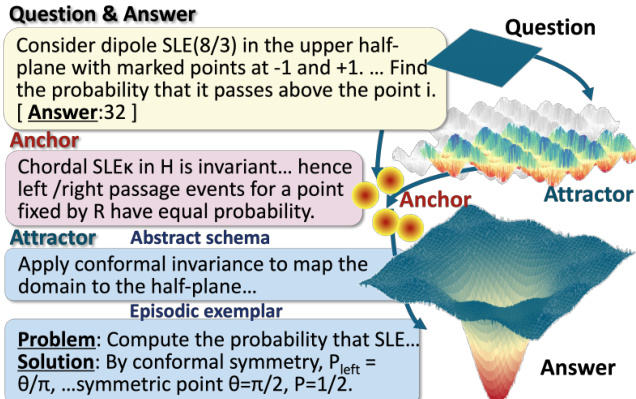
- For each question, human experts manually annotate up to 6 total anchor-attractor units: anchors (core concepts, principles, formulas) and attractors (abstract schemas, exemplars), ensuring relevance, non-redundancy, and alignment with the reasoning path.
- Each annotated data point includes the revised question, standard answer, subdomain label, and a set of anchors and attractors, forming a richly structured dataset for memory-augmented reasoning.
- The dataset is used in the paper to train and evaluate a HybridRAG framework, where the model leverages anchor-attractor pairs as memory cues during inference.
- During training, the authors use a mixture of difficulty levels and subdomains, with balanced sampling across domains and difficulty tiers to ensure comprehensive evaluation.
- No explicit cropping is applied; instead, the dataset is processed through iterative refinement and expert validation to ensure high-quality, semantically grounded reasoning traces.
- Metadata includes subdomain, difficulty level, anchor-attractor sets, and rationale logs for each annotation, enabling traceability and future model debugging.
Method
The authors leverage a memory-driven reasoning framework grounded in the theoretical concepts of anchors and attractors, memory activation, and memory-augmented reasoning. The overall architecture is structured around a four-step annotation process, which is illustrated in the framework diagram. This process begins with subject benchmarking, where subdomains within disciplines such as mathematics, physics, and chemistry are defined and categorized. Experts then develop anchors and attractors for each subdomain, establishing a structured knowledge base. Anchors are identified as foundational reasoning primitives, such as core concepts, principles, and formulas, while attractors are defined as solution pathways that connect these anchors to actionable problem-solving templates. Each attractor comprises an abstract schema and episodic exemplars, ensuring that reasoning can be guided by both general principles and concrete examples. The relationships between anchors and attractors are explicitly specified to maintain coherence and avoid redundancy.
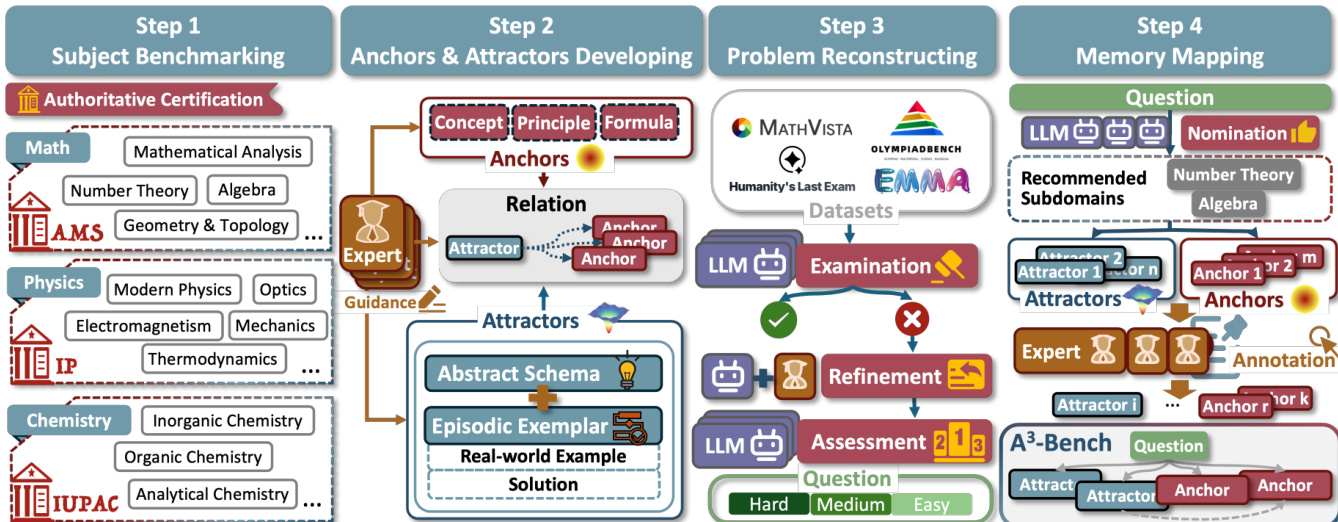
Following the development of the knowledge base, the framework proceeds to problem reconstructing, where existing questions are refined to ensure they require multi-step reasoning and are free from common failure modes. This step involves error diagnosis and cross-model refinement to identify and correct issues such as missing steps or incorrect assumptions. The reconstructed questions are then mapped to relevant anchors and attractors, forming the basis for memory-augmented reasoning. The final step, memory mapping, involves associating questions with the appropriate knowledge structures to guide the reasoning process.
The core of the method is implemented through a hybrid retrieval mechanism known as the Memory Twin-Needle Activator, which operates within the HybridRAG framework. This activator consists of two components: a vector-based retrieval system and a graph-based retrieval system. The vector needle retrieves top-k nodes from a dense store based on semantic similarity, while the graph needle traverses the knowledge graph to recover logical links between nodes. The hybrid retrieval process is formalized as z∗≈Φhybrid(x)≜V(x)⊕G(V(x)), where V(x) represents the vector-based retrieval and G(V(x)) represents the graph-based retrieval. This hybrid approach ensures that both semantic and structural information are leveraged to activate the most relevant memory states.
The activated memory state z∗ is then used by the Context Fabric Composer to construct the final context for the language model. The context is composed by weaving the original query x with the activated state z∗, resulting in Cfinal=W(x,z∗)≜I⊕[x⋈S(z∗)], where I is a fixed instruction prefix and S(⋅) serializes the memory state into a form readable by the language model. This composed context is then fed into the language model to generate the final answer, ensuring that the reasoning process is guided by the activated memory structures.
The authors further formalize the memory activation process as "Anchor-Induced Attractor Dynamics," characterizing cognitive evolution as a trajectory within a potential energy landscape. The memory state m∗ is defined as the minimizer of the variational free energy F(m,A,q)=DKL(q∥p(m∣A))+H(m), where DKL measures the prediction error and H(m) represents the system entropy. The reasoning process follows a gradient flow m˙=−η∇mF(m,A,q), where the anchors act as attractors, creating basins of attraction that pull the trajectory toward stable fixed points. This ensures that the system converges to a stable equilibrium, formalizing memory activation as an emergent property of attractor dynamics and free energy minimization.
Experiment
- Evaluated memory-driven scientific reasoning across three paradigms: No memory (Vanilla), Full memory, and Gold memory (human-labeled activation) using 10 LLMs on OlympiadBench and TheoremQA.
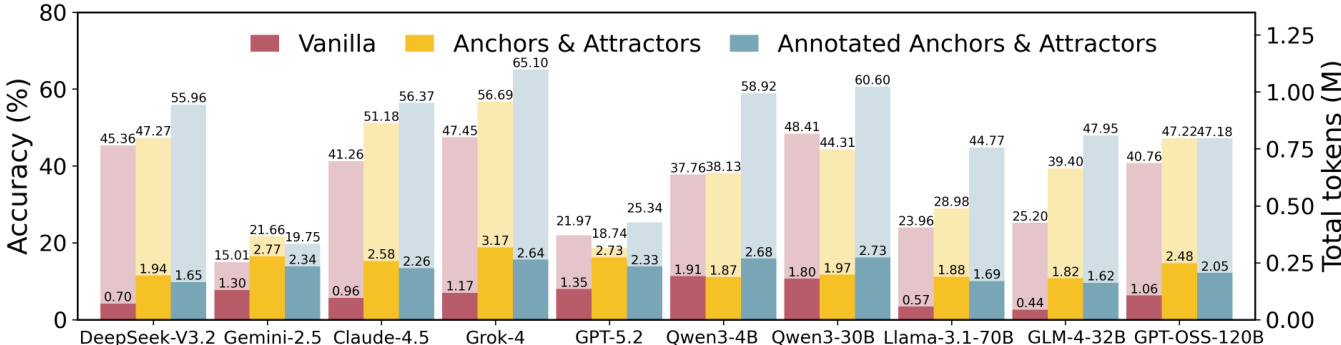
- Memory augmentation consistently improves accuracy: average increase from 34.71% (Vanilla) to 48.19% (Annotated Activation), with gains ranging from +3.37 (GPT-5-Mini) to +22.75 (GLM-4-32B).
- Significant performance gains on hard problems, especially in Physics (e.g., Grok-4-Fast +25.00, GLM-4-32B +15.56), indicating that activated Attractors help recover viable solution paths.
- AAUI (Anchor-Attractor Utilization Index) correlates strongly with accuracy, validating its role in measuring reasoning fidelity; higher AAUI corresponds to better performance (e.g., Grok-4-Fast: AAUI=0.66, Acc=56.69%; GPT-5-Mini: AAUI=0.09, Acc=18.74%).
- Anchor-Attractor activation generalizes to competition-level problems (P.C.), improving average score by 11.12 points over Vanilla and 6.35 over CoT; gains are most pronounced on hardest subsets (e.g., Qwen3-4B: 1.69% → 7.63% on P.C.).
- Attractor-only activation outperforms Anchor-only in most models, but dual activation achieves the highest performance, confirming complementary roles: Anchors provide conceptual grounding, Attractors offer procedural guidance.
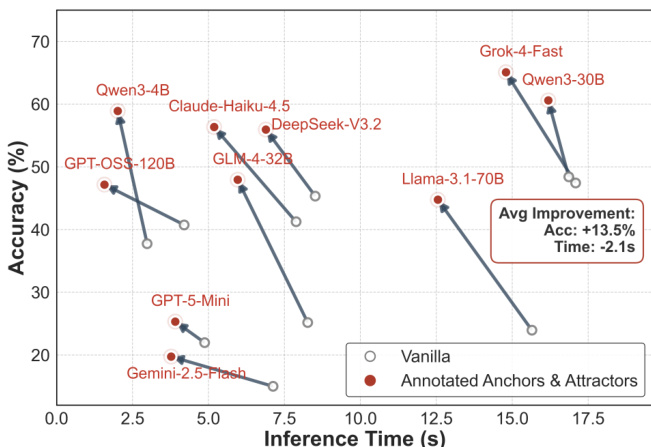
- Inference time decreases by 2.1 seconds on average under annotated activation, with concurrent accuracy gains (up to +13.5%), indicating efficiency improvements.
- Error analysis shows significant reductions in Reasoning and Knowledge errors under annotated activation, while Calculation and Comprehension errors remain stable.
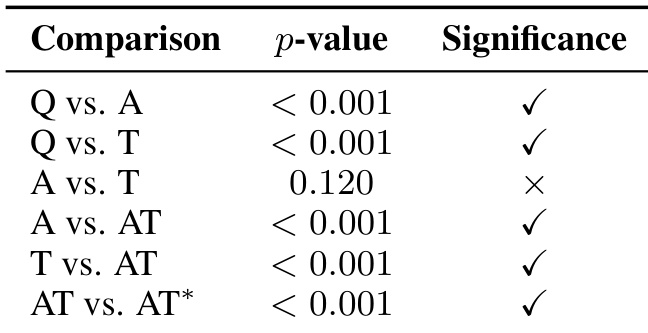
- Statistical significance tests (McNemar’s) confirm that memory augmentation is essential (p < 0.001), and joint activation of Anchors and Attractors is superior to isolated use.
- Performance degrades monotonically with increasing noise in memory (e.g., Grok-4-Fast: 65.1% → 32.5% with 100% noise), demonstrating that memory relevance is critical for reliable reasoning.
The authors use a heatmap to analyze the relationship between memory activation and performance gains across different subjects and difficulty levels. Results show that memory augmentation leads to the largest accuracy improvements on hard problems, with Math and Chemistry exhibiting the most significant gains in both accuracy and AAUI under hard difficulty, while Physics shows more modest improvements. The data indicates that memory activation is most effective in challenging scenarios, where it substantially boosts performance and aligns with higher AAUI values.

The authors use a scatter plot to compare the accuracy and inference time of ten LLMs under two paradigms: Vanilla and Annotated Anchors & Attractors. Results show that activating annotated memory improves accuracy for all models while reducing inference time, with an average improvement of 13.5% in accuracy and a 2.1-second reduction in inference time.
Results show that memory augmentation significantly improves scientific reasoning performance compared to relying solely on parametric knowledge, as indicated by the statistically significant differences between the question-only baseline and both anchor-only and attractor-only activation. The combined activation of anchors and attractors yields a further significant improvement over either component alone, demonstrating that both memory types are necessary for optimal reasoning. However, there is no significant difference between anchor-only and attractor-only activation, suggesting they play complementary roles in supporting scientific problem-solving.
The authors use a memory-driven framework to evaluate scientific reasoning in large language models across three paradigms: vanilla, chain of thought, and anchor & attractor activation. Results show that anchor & attractor activation significantly improves accuracy over both vanilla and chain of thought baselines, with average gains of 11.12% over vanilla and 6.35% over chain of thought, particularly on competition-level problems.
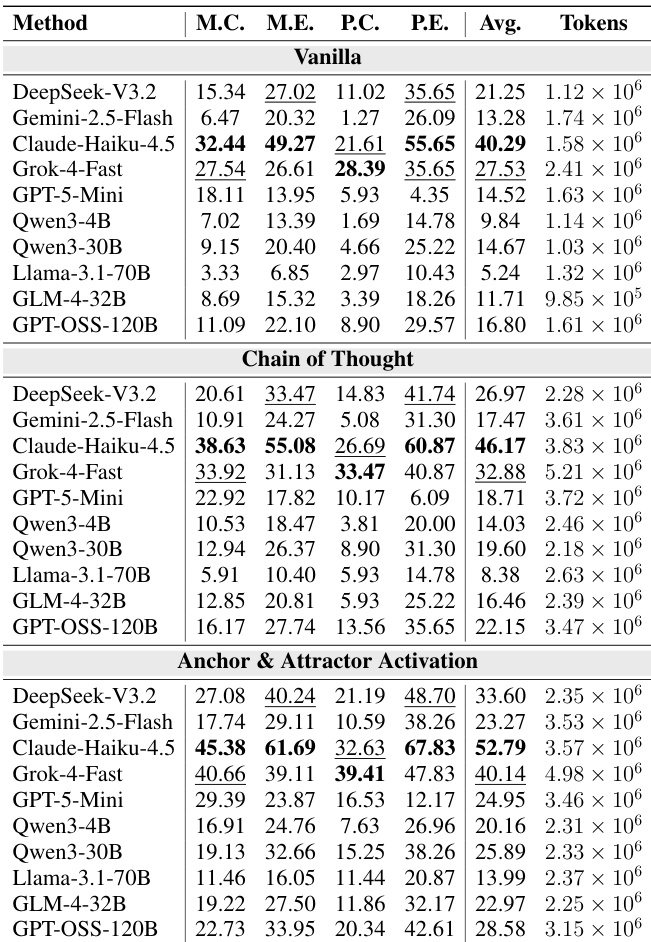
The authors use a comparison of three memory paradigms—Vanilla, Anchors & Attractors, and Annotated Anchors & Attractors—to evaluate the impact of memory activation on scientific reasoning accuracy across ten large language models. Results show that activating annotated Anchors and Attractors consistently improves accuracy over the Vanilla baseline, with the largest gains observed in harder problems and competition-level tasks, while also reducing inference time for most models.