Command Palette
Search for a command to run...
MAXS : Exploration Méta-Adaptative avec des Agents LLM
MAXS : Exploration Méta-Adaptative avec des Agents LLM
Jian Zhang Zhiyuan Wang Zhangqi Wang Yu He Haoran Luo li yuan Lingling Zhang Rui Mao Qika Lin Jun Liu
Résumé
Les agents basés sur les grands modèles linguistiques (LLM) possèdent des capacités intrinsèques de raisonnement grâce à la collaboration de plusieurs outils. Toutefois, lors de l’inférence par les agents, les méthodes existantes souffrent fréquemment de deux limites majeures : (i) une génération localement myope, due à l’absence de prévision (lookahead), et (ii) une instabilité des trajectoires, où de petites erreurs initiales peuvent s’aggraver en chemins de raisonnement divergents. Ces problèmes rendent difficile l’équilibre entre efficacité globale et efficacité computationnelle. Pour résoudre ces deux défis, nous proposons MAXS (Meta-Adaptive eXploration with LLM Agents), un cadre de raisonnement adaptatif méta, basé sur les agents LLM, qui intègre de manière flexible l’exécution d’outils et la planification de raisonnement. MAXS utilise une stratégie de lookahead pour étendre les chemins de raisonnement de quelques étapes à l’avance, en estimant la valeur d’avantage associée à l’utilisation d’un outil. Il combine ensuite la variance de cohérence par étape et les pentes de tendance entre étapes pour sélectionner de manière conjointe des étapes de raisonnement stables, cohérentes et à haute valeur. Par ailleurs, nous introduisons un mécanisme de convergence de trajectoire, qui limite le coût computationnel en interrompant les simulations supplémentaires dès qu’une cohérence de chemin est atteinte, permettant ainsi un équilibre entre efficacité des ressources et efficacité globale dans le raisonnement multi-outils. Nous menons des études empiriques approfondies sur trois modèles de base (MiMo-VL-7B, Qwen2.5-VL-7B, Qwen2.5-VL-32B) et cinq jeux de données, démontrant que MAXS surpasse de manière cohérente les méthodes existantes en termes de performance et d’efficacité d’inférence. Une analyse complémentaire confirme l’efficacité de notre stratégie de lookahead et de l’utilisation d’outils.
One-sentence Summary
The authors from Xi'an Jiaotong University and Nanyang Technological University propose MAXS, a meta-adaptive reasoning framework for LLM agents that integrates lookahead planning and trajectory convergence to mitigate local myopia and reasoning instability, enabling efficient, stable, and high-performance multi-tool reasoning through advantage estimation and consistency-driven step selection.
Key Contributions
- Existing LLM Agent methods suffer from locally myopic generation and trajectory instability due to the lack of lookahead and sensitivity to early errors, hindering the balance between global reasoning effectiveness and computational efficiency in multi-tool tasks.
- MAXS introduces a meta-adaptive reasoning framework that uses a lightweight lookahead strategy to estimate tool usage value and combines step consistency variance with inter-step trend slopes for stable, high-value step selection, mitigating both myopia and instability.
- Empirical evaluations across three LLM backbones and five datasets show MAXS consistently outperforms baselines in both task accuracy and inference efficiency, with ablation studies confirming the critical role of its lookahead and convergence mechanisms.
Introduction
LLM agents have become central to complex problem-solving tasks by dynamically integrating tools like search and code execution into reasoning workflows. However, existing methods face two key challenges: locally myopic decision-making, where tool use is determined without foresight, and trajectory instability, where early errors propagate due to rigid, incremental reasoning paths. While approaches like Tree of Thought and Monte Carlo Tree Search improve global planning, they incur high computational costs due to exhaustive path exploration. The authors introduce MAXS, a meta-adaptive exploration framework that enables LLM agents to perform lightweight, lookahead-based reasoning by estimating the value of future tool use. By combining step consistency variance and inter-step trend analysis, MAXS selects stable, high-value reasoning steps and employs a trajectory convergence mechanism to halt rollouts early when consistency is achieved. This balances global effectiveness with computational efficiency, outperforming prior methods across multiple benchmarks while reducing token consumption.
Dataset

-
The dataset comprises five publicly available benchmarks: MathVista, Olympiad-Bench, EMMA, TheoremQA, and MATH, each selected to evaluate diverse scientific reasoning capabilities of large language models across multiple disciplines and difficulty levels.
-
MathVista (testmini subset) includes 1,000 data points spanning algebraic, geometric, statistical, scientific, numeric commonsense, and logical reasoning tasks, designed with varying difficulty to assess comprehensive scientific problem-solving.
-
Olympiad-Bench contributes 6,728 open-ended questions from math and physics Olympiads, covering competition and college-level challenges; the authors selected only open-ended questions to focus on generative reasoning, excluding theorem-proof types.
-
EMMA provides 100 data points per subdomain—Math, Physics, and Chemistry—integrating mathematical expressions, physical formulas, and chemical symbols with natural language to test interdisciplinary reasoning.
-
TheoremQA contains 800 high-quality question-answer pairs grounded in over 350 unique theorems across mathematics, physics, engineering, computer science, and finance, emphasizing formal theorem application in problem solving.
-
MATH includes 12,500 high school competition-level problems from AMC, AIME, and similar exams, covering seven domains: Prealgebra, Algebra, Number Theory, Counting & Probability, Geometry, Intermediate Algebra, and Precalculus. The authors sampled 300 problems—60 from each of five difficulty levels—to ensure balanced representation across difficulty tiers.
-
The data is used in a training mixture with dynamically adjusted ratios based on model performance, enabling effective learning across diverse reasoning types and difficulty levels.
-
All datasets undergo minimal preprocessing: raw text is cleaned, and answers are extracted from step-by-step solutions where available. No cropping is applied to the original data, but the MATH subset is uniformly sampled by difficulty level to ensure balanced training.
-
Metadata such as subject labels, difficulty ratings, and problem domains are preserved and used to guide training and evaluation, supporting fine-grained performance analysis.
Method
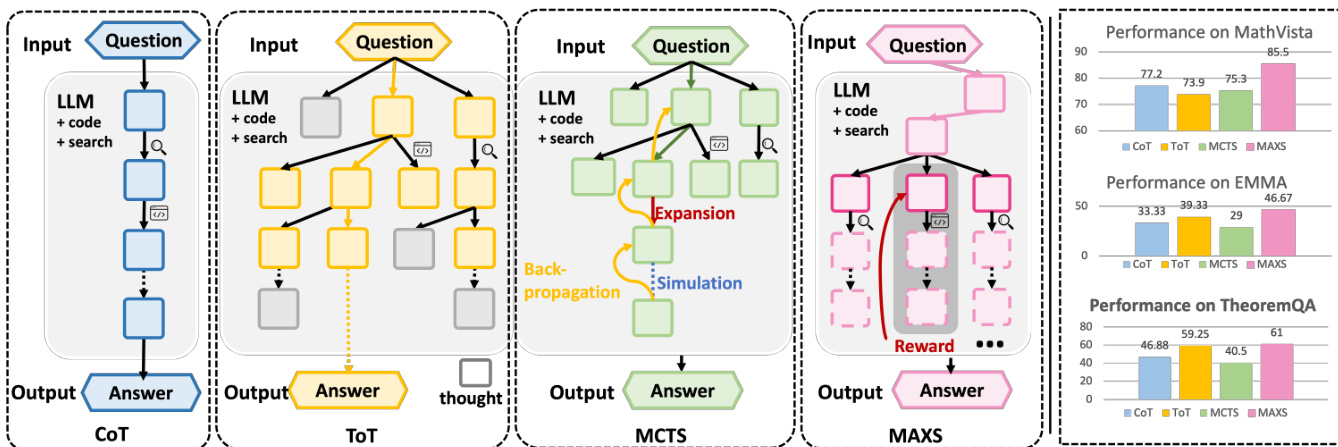
The authors leverage a meta-adaptive reasoning framework, MAXS, designed to enhance the decision-making process of Large Language Model (LLM) agents in multi-tool reasoning tasks. The overall architecture, illustrated in the framework diagram, operates as an iterative process where the agent generates reasoning steps based on the input question and its history. At each step, MAXS performs a three-stage procedure to select the optimal next action: a lookahead rollout, a value estimation, and an integration step. The framework begins with an input question, which is processed by the LLM Agent. The agent can choose to invoke external tools, such as a code interpreter or a search engine, at specific steps to augment its reasoning. The process continues until a final answer is generated.
The first key component is the lookahead strategy, which addresses the issue of locally myopic generation. This strategy simulates future reasoning paths a few steps ahead to estimate the long-term value of the current step. As shown in the figure below, the agent generates a set of candidate future trajectories from the current state si, and the expected return R(s>i) is recursively estimated using a discounted sum of future rewards, consistent with the Bellman Optimality Principle. This foresight allows the agent to make decisions that are not solely based on immediate gains but also on their potential to lead to a more effective global solution. The current step is then selected based on the estimated future values, incorporating this lookahead information into the policy.
The second component is a composite value estimation mechanism designed to mitigate trajectory instability. This mechanism evaluates candidate reasoning trajectories by combining three distinct scores. The first is an advantage score, which measures the relative improvement in foresight probability compared to the previous step. The second is a step-level variance score, which quantifies the fluctuation in the log-probability of future steps. A lower variance indicates a more stable and consistent trajectory, analogous to Lyapunov stability in dynamical systems. The third is a slope-level variance score, which measures the smoothness of the trajectory's directional progression by analyzing the variance of first-order differences in log-probabilities. A lower slope variance implies a more Lipschitz-continuous path, avoiding abrupt changes. These three scores are combined into a unified reward function, which is used to guide the selection of the next reasoning step.
The final component is a trajectory convergence mechanism that controls computational cost. This mechanism monitors the consistency of the generated trajectories. If the variance of the composite rewards across the candidate paths falls below a predefined threshold, the rollout process is terminated early. This allows the framework to achieve a balance between global effectiveness and computational efficiency, as it avoids unnecessary rollouts once a stable and high-value path is identified. The complete decoding process, as detailed in the algorithm, iterates this three-stage procedure until an end-of-sequence token is generated.
Experiment
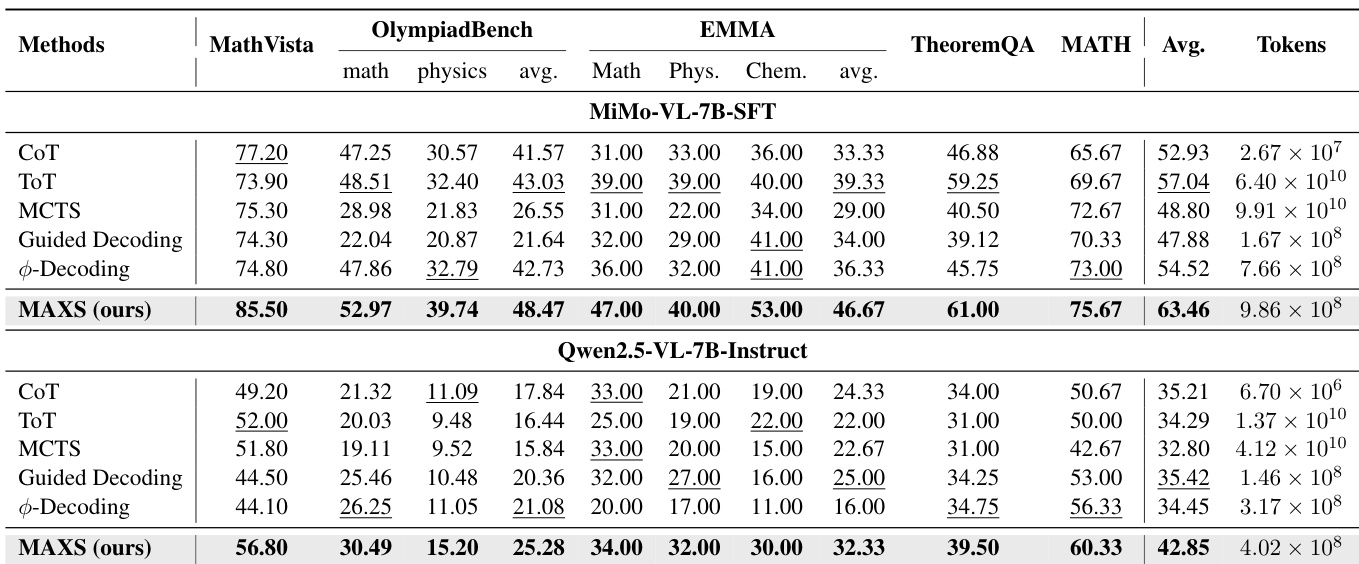
- MAXS achieves state-of-the-art performance across five reasoning benchmarks (MathVista, OlympiadBench, TheoremQA, MATH, EMMA) using three multimodal LLM backbones (MiMo-VL-7B, Qwen2.5-VL-7B, Qwen2.5-VL-32B), with 63.46% accuracy on MiMo-VL-7B—6.42% higher than ToT and 7.43% higher than Guided Decoding.
- MAXS demonstrates superior accuracy–cost trade-off: on MiMo-VL-7B, it achieves 49% accuracy with 1,000× fewer tokens than MCTS and outperforms φ-Decoding by nearly 8% at similar computational cost.
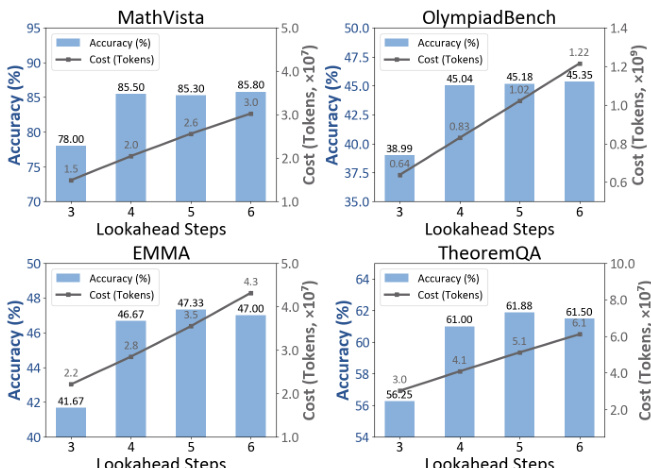
- The 4-step lookahead provides optimal balance—accuracy plateaus beyond 4 steps while token usage increases sharply, confirming it as the efficiency frontier.
- Trajectory convergence via variance-based early stopping (δ = 0.002) reduces inference cost without sacrificing accuracy, enabling efficient rollouts.
- Ablation studies show lookahead is critical for global reasoning (−9.44% drop on Qwen2.5-VL-7B), and the advantage score is the dominant reward component.
- Code and search tools are complementary: removing either harms performance, with code being especially vital for symbolic reasoning (e.g., −14.7% drop on MathVista).
- Value estimation with α = 0.3 and β = 0.2 yields peak accuracy (63.5%), outperforming advantage-only baselines by +8.3% and log-prob-based methods by 5.0–10.3%.
- Most problems are solved within 4–8 steps, validating the 13-step cap, with OlympiadBench requiring deeper reasoning.
- 1-beam decoding offers the best efficiency–accuracy trade-off, with larger beams yielding diminishing returns.
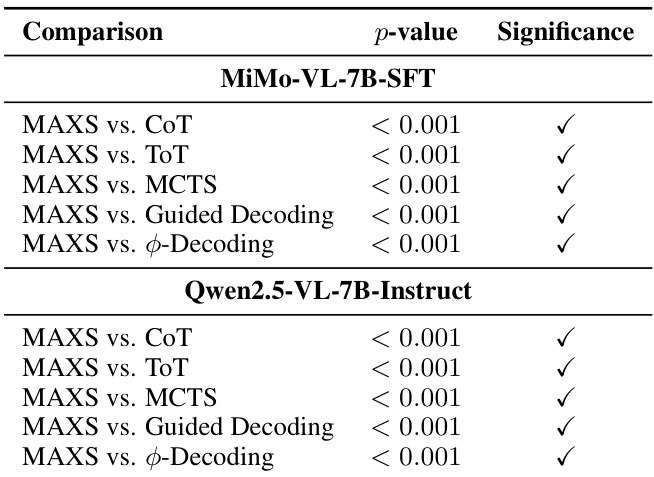
- McNemar’s test confirms MAXS’s improvements are statistically significant (p < 0.001) across all baselines and model architectures.
- A failure case reveals vulnerability to early misidentification when tool-based retrieval is uncertain, leading to error propagation despite correct downstream calculations.
The authors use a trajectory convergence mechanism to terminate rollouts when the variance of candidate rewards falls below a threshold, improving inference efficiency without sacrificing stability. Results show that MAXS achieves higher accuracy than baselines like ToT and MCTS while using significantly fewer tokens, demonstrating a superior trade-off between performance and computational cost.
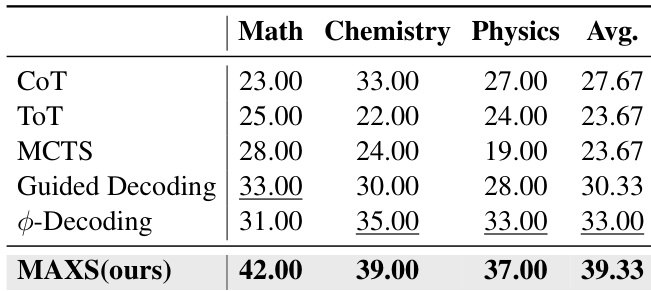
The authors use MAXS to achieve the highest average accuracy across all benchmarks, outperforming baselines such as CoT, ToT, MCTS, and Guided Decoding by significant margins. Results show MAXS reaches 39.33% average accuracy, surpassing the next best method, Guided Decoding, by 6.00 percentage points.
The authors use McNemar's test to evaluate the statistical significance of MAXS against five baselines across two models, MiMo-VL-7B-SFT and Qwen2.5-VL-7B-Instruct. Results show that MAXS achieves statistically significant improvements over all baselines, with p-values less than 0.001 in every comparison.
Results show that a 4-step lookahead achieves the best balance between accuracy and efficiency across all datasets. Accuracy improves from 3 to 4 steps and then plateaus, while token usage increases sharply beyond 4 steps, confirming that further lookahead provides diminishing returns.
The authors use MAXS to achieve state-of-the-art performance across multiple reasoning benchmarks, outperforming baselines such as ToT and Guided Decoding on both MiMo-VL-7B and Qwen2.5-VL-7B models. Results show that MAXS achieves higher accuracy with significantly lower computational cost, using up to 100 times fewer tokens than tree-based methods like MCTS while maintaining strong efficiency.