Command Palette
Search for a command to run...
Le dilemme de la confiance : analyse et atténuation de la mauvaise calibration chez les agents utilisant des outils
Le dilemme de la confiance : analyse et atténuation de la mauvaise calibration chez les agents utilisant des outils
Weihao Xuan Qingcheng Zeng Heli Qi Yunze Xiao Junjue Wang Naoto Yokoya
Résumé
Les agents autonomes fondés sur des modèles de langage à grande échelle (LLM) évoluent rapidement pour gérer des tâches à plusieurs tours, mais garantir leur fiabilité demeure un défi majeur. Un pilier fondamental de cette fiabilité est la calibration, qui désigne la capacité d’un agent à exprimer une confiance qui reflète fidèlement ses performances réelles. Bien que la calibration soit bien établie pour les modèles statiques, ses dynamiques dans les flux de travail agencés intégrant des outils restent largement sous-explorées. Dans ce travail, nous étudions de manière systématique la calibration verbalisée dans les agents utilisant des outils, révélant une dichotomie fondamentale de la confiance liée au type d’outil. Plus précisément, notre étude pilote identifie que les outils d’acquisition de preuves (par exemple, la recherche sur le web) induisent systématiquement une surconfiance sévère en raison du bruit inhérent aux informations récupérées, tandis que les outils de vérification (par exemple, les interprètes de code) permettent de fondre le raisonnement sur un retour déterministe et de réduire la miscalibration. Pour améliorer de manière robuste la calibration à travers les différents types d’outils, nous proposons un cadre de fine-tuning par apprentissage par renforcement (RL) qui optimise conjointement la précision de la tâche et la calibration, appuyé par une évaluation holistique des conceptions de récompenses. Nous démontrons que les agents entraînés atteignent non seulement une meilleure calibration, mais aussi une généralisation robuste depuis des environnements d’entraînement locaux vers des environnements bruyants comme le web, ainsi que vers des domaines distincts tels que le raisonnement mathématique. Nos résultats mettent en évidence la nécessité de stratégies de calibration spécifiques au domaine pour les agents utilisant des outils. Plus largement, ce travail établit une base pour concevoir des agents auto-conscients capables de communiquer de manière fiable l’incertitude dans des déploiements réels à enjeux élevés.
One-sentence Summary
The authors from the University of Tokyo, RIKEN AIP, Northwestern University, Waseda University, and Carnegie Mellon University propose a reinforcement learning framework to improve verbalized calibration in tool-integrated LLM agents, addressing a confidence dichotomy between noisy evidence tools and deterministic verification tools, enabling self-aware, trustworthy performance across diverse real-world scenarios.
Key Contributions
-
We identify a fundamental confidence dichotomy in tool-use agents: evidence tools like web search induce severe overconfidence due to noisy, uncertain information, while verification tools like code interpreters provide deterministic feedback that grounds reasoning and reduces miscalibration.
-
We propose Calibration Agentic RL (CAR), a reinforcement learning framework that jointly optimizes task accuracy and verbalized calibration through a holistic benchmark of reward designs, including a novel Margin-Separated Calibration Reward (MSCR) that enhances confidence reliability.
-
Our method demonstrates robust generalization across environments and domains, achieving superior calibration in both local training settings and noisy web-based scenarios, as well as in mathematical reasoning tasks, validating the effectiveness of domain-aware calibration strategies.
Introduction
Autonomous agents powered by large language models (LLMs) are advancing rapidly in handling complex, multi-turn tasks by integrating external tools such as web search or code interpreters. However, their trustworthiness hinges on proper calibration—accurately reflecting confidence in their own performance—which remains poorly understood in tool-augmented workflows. Prior work has shown that tool use often exacerbates overconfidence, but this effect has been studied primarily in narrow contexts like web search, leaving open whether the issue is universal or tool-dependent. The authors reveal a critical confidence dichotomy: evidence tools (e.g., web search) introduce noise and lack clear correctness feedback, leading to severe overconfidence, while verification tools (e.g., code interpreters) provide deterministic feedback that grounds reasoning and improves calibration. To address this, the authors propose Calibration Agentic RL (CAR), a reinforcement learning framework that jointly optimizes task accuracy and calibration through a novel Margin-Separated Calibration Reward (MSCR). This approach enables agents to maintain high accuracy while significantly improving confidence reliability, generalizing robustly from controlled environments to noisy real-world settings and across domains like mathematical reasoning. The work establishes that calibration strategies must be tailored to tool type and lays the groundwork for self-aware agents capable of trustworthy uncertainty communication in high-stakes applications.
Dataset

- The dataset is composed of two primary sources: NQ (Natural Questions) and HotpotQA, used as training data for tool-use agent policy optimization.
- NQ and HotpotQA are combined in a mixture ratio to train the model, with the specific proportions not detailed but designed to support robust reasoning and tool-use behavior.
- The retrieval component relies on a local search engine built using the 2018 Wikipedia dump as the knowledge base and E5 as the dense retriever, ensuring consistent and reproducible evidence retrieval.
- The policy networks are implemented using instruction-tuned LLMs: Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct, and Qwen3-4B-Instruct-2507, selected for their strong instruction-following capabilities and reliable confidence reporting.
- Training is conducted using Group Relative Policy Optimization (GRPO), a reinforcement learning algorithm that enables effective policy learning in multi-step tool-use scenarios.
- The model is evaluated within the Search-R1 framework, which serves as the primary testbed for studying miscalibration in evidence-based tool use.
- No explicit cropping or metadata construction is described; the data is used in its original form for training, with processing limited to standard tokenization and formatting for instruction-tuning and RL training.
Method
The authors leverage a reinforcement learning (RL) framework to train an agent model that achieves robust and calibrated performance in task execution. The overall architecture, as illustrated in the framework diagram, consists of an agent model that interacts with external tools—such as evidence tools (e.g., web search) and verification tools (e.g., code interpreter)—to solve tasks. The agent generates reasoning, actions, and observations, and is trained to produce outputs that are both accurate and well-calibrated in terms of confidence. The training process is guided by a joint reward function that combines structural integrity with calibration-aware scoring.
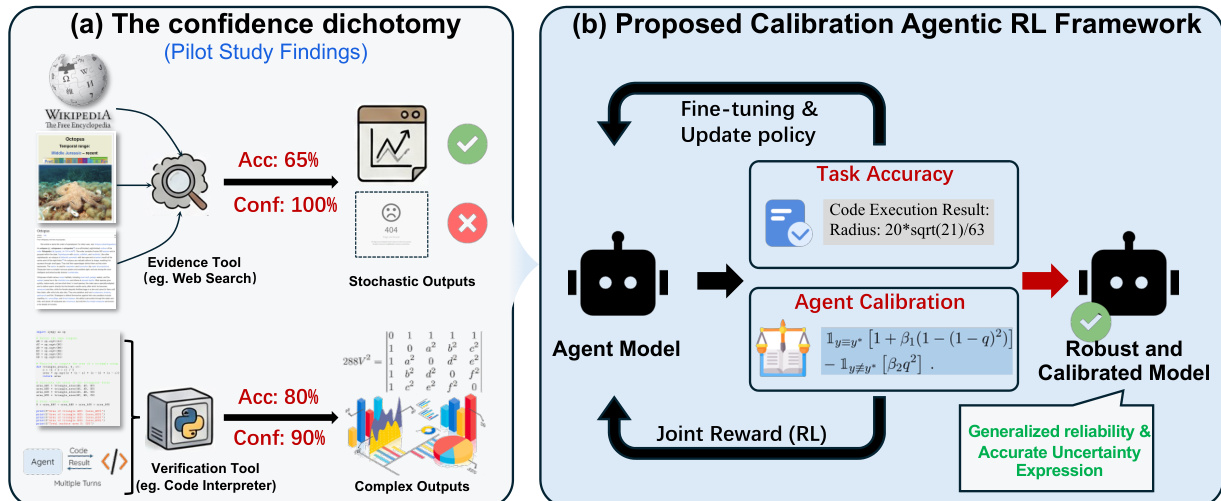
As shown in the figure below, the framework begins with the agent model generating a sequence of reasoning, actions, and observations. The outputs are evaluated for task accuracy and agent calibration. Task accuracy is determined by the correctness of the final answer, while agent calibration assesses the alignment between the model’s confidence and its actual performance. The agent is trained using a joint reward signal derived from both components, which is then used to fine-tune and update the policy. This iterative process results in a robust and calibrated model capable of generalized reliability and accurate uncertainty expression.
The proposed reward architecture extends the standard Search-R1 format by requiring the agent to output a numerical confidence score within <confidence> XML tags. This structural requirement is enforced through a boolean format reward function fformat(y), which returns True only when all structural constraints, including the presence of the confidence tag, are satisfied. This ensures that the agent adheres to the required output format.
The calibration-motivated outcome reward is designed to encourage both accurate predictions and well-calibrated confidence estimates. The authors experiment with two formulations. The first is a Weighted Brier Score Reward, which combines accuracy and confidence into a single scalar reward:
R(y,q,y∗)=1y≡y∗−λ(q−1y≡y∗)2.This formulation penalizes overconfidence in incorrect answers and underconfidence in correct ones. To mitigate optimization instability caused by incentive overlap, the authors propose the Margin-Separated Calibration Reward (MSCR), which decouples the calibration terms for correct and incorrect predictions:
RMSCR(y,q,y∗)=1y≡y∗[1+β1(1−(1−q)2)]−1y≡y∗⌈β2q2⌉,where β1,β2>0 control the magnitude of calibration. This formulation ensures a strict reward margin: correct answers receive a base reward of at least 1, while incorrect answers receive at most 0 and are penalized for false confidence.
The unified reward function combines the format constraint with the calibration-aware scoring. Given a model output τ, the total reward rϕ(x,τ) is defined as:
rϕ(x,τ)={Rcal(y,q,y∗)Rcal(y,q,y∗)−λfif fformat(τ)=True,otherwise.In the case where the format is violated, a penalty λf is applied. If the confidence q cannot be extracted, a minimal calibration reward is used as a fallback to preserve the correctness gradient while still penalizing format errors.
Experiment
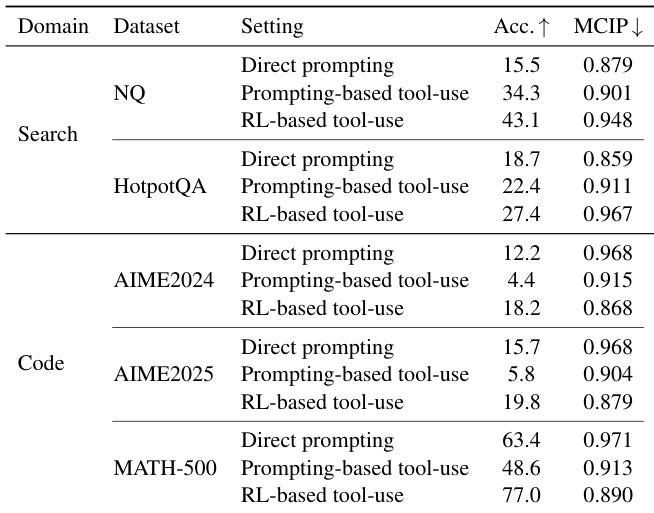
- Direct Prompting, Prompting-based Tool-Use, and RL-based Tool-Use were evaluated on Web Search (evidence tools) and Code Interpreter (verification tools) using Qwen2.5-3B-Instruct.
- On NQ and HotpotQA, RL-based tool use with Web Search significantly increased overconfidence (higher MCIP), with statistically significant differences from direct prompting, indicating calibration degradation due to noisy retrieval.
- On AIME2024/2025 and MATH-500, tool use with Code Interpreter reduced overconfidence, with RL-based agents achieving the lowest MCIP, showing that deterministic feedback improves calibration.
- CAR (Calibration-Aware Reward) training reduced ECE by up to 68% across all backbone models on both ID and OOD settings, while maintaining accuracy competitive with correctness-only reward baselines.
- CAR achieved up to 17% AUROC improvement, demonstrating enhanced ability to distinguish correct from incorrect predictions, not just confidence rescaling.
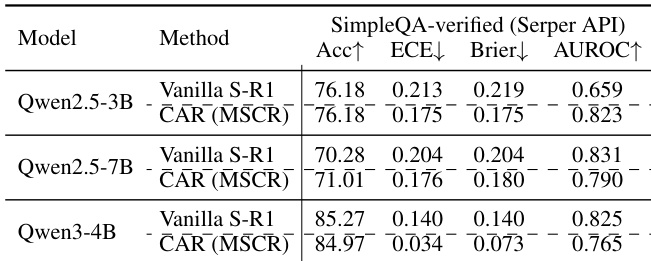
- Calibration gains from CAR transferred robustly to real-world API environments (Serper API), with CAR (MSCR) outperforming vanilla Search-R1 in calibration and accuracy.
- In Tool-integrated Reasoning (TIR), CAR reduced ECE and Brier scores and improved AUROC on both AIME2024/2025 and MATH-500, but calibration remained worse than pure reasoning models, with higher ECE on more complex AIME tasks.
The authors use Qwen2.5-3B-Instruct to evaluate three tool-use configurations—direct prompting, prompting-based tool-use, and RL-based tool-use—across evidence (Web Search) and verification (Code Interpreter) domains. Results show that in the search domain, tool use increases overconfidence, with RL-based tool-use achieving the highest accuracy but also the highest MCIP, while in the code domain, tool use reduces overconfidence, with RL-based tool-use achieving the lowest MCIP and highest accuracy.
The authors use Qwen2.5-3B-Instruct to evaluate tool-integrated reasoning with a Code Interpreter, comparing Vanilla SimpleTIR against their CAR (MSCR) method across AIME2024/2025 and MATH-500 benchmarks. Results show that CAR significantly improves calibration, reducing ECE and Brier scores while increasing AUROC, though absolute calibration remains lower than in pure reasoning models and is more challenging on complex problems.

The authors use Qwen2.5-3B-Instruct and Qwen2.5-7B to evaluate different calibration strategies across evidence and verification tool domains, with results showing that CAR (MSCR) consistently reduces Expected Calibration Error (ECE) and improves AUROC while maintaining competitive accuracy. Results indicate that calibration improvements are robust across model sizes and generalize to out-of-distribution settings and noisy API environments, though calibration performance in tool-integrated reasoning remains constrained by task complexity.
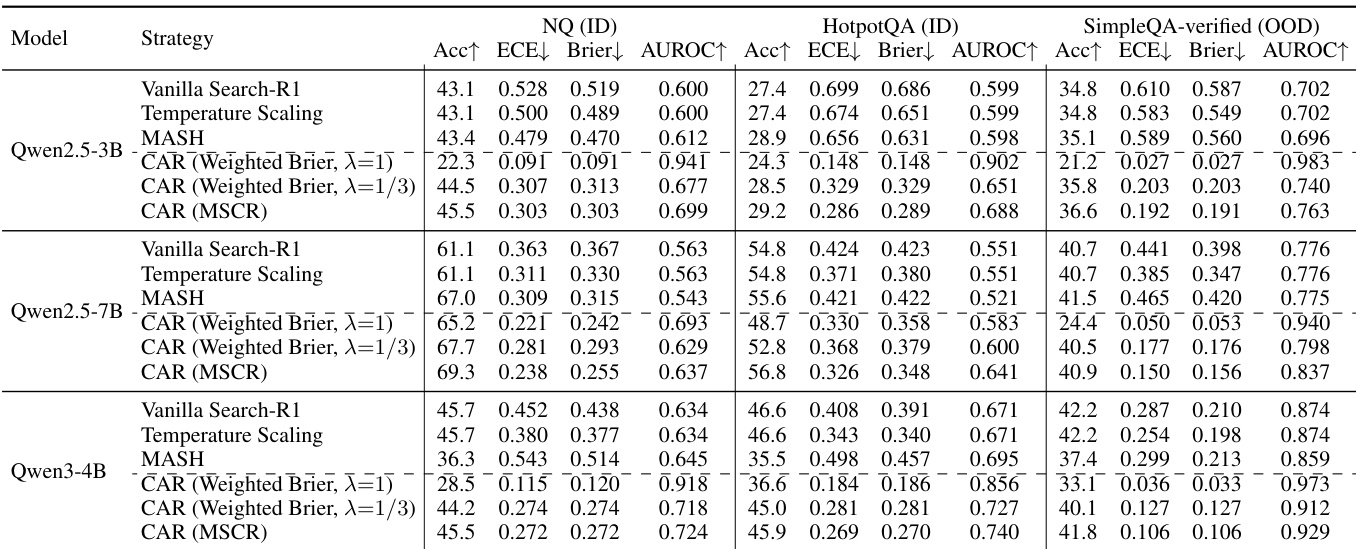
The authors use a simulated retrieval environment and a real-world API-driven retriever to evaluate calibration performance in search agents. Results show that CAR (MSCR) achieves significant improvements in calibration metrics such as ECE and Brier score while maintaining competitive accuracy compared to the vanilla baseline, demonstrating robust generalization to noisy, real-world retrieval conditions.