Command Palette
Search for a command to run...
CHAOS stochastique : Pourquoi l'inférence déterministe tue, et la variabilité distributionnelle est le battement cardiaque de la cognition artificielle
CHAOS stochastique : Pourquoi l'inférence déterministe tue, et la variabilité distributionnelle est le battement cardiaque de la cognition artificielle
Tanmay Joshi Shourya Aggarwal Anusa Saha Aadi Pandey Shreyash Dhoot Vighnesh Rai Raxit Goswami Aman Chadha Vinija Jain Amitava Das
Résumé
L’inférence déterministe constitue un idéal rassurant dans les logiciels classiques : un même programme, sur une même entrée, doit toujours produire la même sortie. À mesure que les grands modèles linguistiques (LLM) s’insèrent dans des déploiements du monde réel, cet idéal a été adopté de façon intégrale dans les piles d’inférence. Des travaux récents du Thinking Machines Lab ont fourni une analyse détaillée de la non-déterminisme dans l’inférence des LLM, montrant comment des noyaux invariants par lot et une attention déterministe permettent d’assurer des sorties identiques au bit près, positionnant ainsi l’inférence déterministe comme une condition préalable à la reproductibilité et à la fiabilité en environnement d’entreprise.Dans cet article, nous adoptons une position opposée. Nous affirmons que, pour les LLM, l’inférence déterministe est mortelle. Elle tue la capacité à modéliser l’incertitude, éteint les capacités émergentes, réduit le raisonnement à un unique chemin fragile, et affaiblit l’alignement en matière de sécurité en masquant les risques de queue. Les LLM implémentent des distributions conditionnelles sur les sorties, et non des fonctions fixes. Réduire ces distributions à une seule complétion canonique peut sembler rassurant, mais elle cache systématiquement des propriétés centrales de la cognition artificielle. Nous proposons plutôt d’adopter le CHAOS stochastique, en traitant la variabilité distributionnelle comme un signal à mesurer et à contrôler.Expérimentalement, nous montrons que l’inférence déterministe est systématiquement trompeuse. L’évaluation à un seul échantillon, déterministe, sous-estime à la fois les capacités et la fragilité, en masquant la probabilité d’échec face à des reformulations ou à des perturbations. Les transitions de phase associées aux capacités émergentes disparaissent sous le décodage glouton. Le raisonnement multi-chemins se dégrade lorsqu’il est contraint par des architectures déterministes, entraînant une baisse de précision et une perte d’insight diagnostique. Enfin, l’évaluation déterministe sous-estime le risque de sécurité en cachant des comportements rares mais dangereux, qui ne se manifestent que dans des évaluations à plusieurs échantillons.
One-sentence Summary
The authors from Pragya Lab, BITS Pilani Goa, Raapid Lab, Apple, and Google argue that deterministic inference in LLMs undermines artificial cognition by suppressing uncertainty, emergent abilities, multi-path reasoning, and safety robustness; they advocate for Stochastic CHAOS, emphasizing distributional reproducibility and semantic stability over bitwise determinism to enable faithful modeling of conditional distributions and reliable evaluation under variability.
Key Contributions
- The paper challenges the prevailing assumption that deterministic inference is essential for LLM reliability, arguing instead that forcing bitwise-identical outputs collapses the model’s inherent conditional distribution pθ(y∣x), thereby suppressing uncertainty modeling, emergent abilities, multi-path reasoning, and robust safety alignment.
- It introduces a three-tiered framework for inference stability—bitwise determinism, distributional reproducibility, and semantic stability—and demonstrates that deterministic evaluation systematically underestimates model fragility, obscures phase-like emergent behaviors, and fails to detect rare but dangerous safety failures under perturbations.
- Empirical results show that multi-sample, stochastic evaluation reveals critical vulnerabilities and capabilities absent in single-sample deterministic runs, including higher failure rates under prompt variations, vanishing emergence signals, degraded performance in self-consistency and tree-of-thought reasoning, and hidden tail risks in alignment.
Introduction
Large language models (LLMs) are inherently probabilistic, representing knowledge as conditional distributions pθ(y∣x), yet current inference practices often enforce deterministic outputs—typically via greedy decoding at temperature T=0—to achieve bitwise reproducibility. This approach, driven by demands for debuggability, auditability, and consistency in enterprise systems, overlooks the fact that real-world deployment involves stochasticity from both algorithmic sampling and system-level numerical nondeterminism (e.g., floating-point non-associativity, dynamic batching). Prior work has attempted to eliminate this variability through batch-invariant kernels and deterministic attention, but such efforts treat nondeterminism as a bug rather than a signal of model uncertainty.
The authors argue that enforcing deterministic inference fundamentally misrepresents LLM capabilities. By collapsing the rich trajectory space into a single greedy path, it suppresses emergent abilities that only appear under multi-sample evaluation, collapses multiple valid reasoning paths into a brittle script, and masks rare but dangerous safety failures that only surface under stochastic exploration. Empirical results show that deterministic evaluation systematically underestimates both model fragility and competence—especially under paraphrases, adversarial prompts, and complex reasoning tasks—while creating an illusion of robustness.
The authors’ main contribution is a framework for rethinking LLM inference around three stability goals: bitwise determinism (for debugging), distributional reproducibility (for reliable metric estimation), and semantic stability (for user-facing consistency). They advocate for "Stochastic CHAOS"—a paradigm where controlled randomness is not eliminated but measured and leveraged as a core component of evaluation, safety, and reasoning. This shift enables honest generalization, exposes latent model capabilities, and provides a more faithful characterization of LLM behavior than any single deterministic output can.
Dataset

-
The dataset comprises three distinct benchmarks, each selected to minimize training-data contamination by virtue of being released after mid-2024: BESSTIE for sentiment and sarcasm classification, InstruSum for instruction-controllable summarization, and a trio of reasoning benchmarks (GSM8K, SVAMP, StrategyQA) for chain-of-thought reasoning.
-
BESSTIE includes manually annotated Google Place reviews and Reddit comments in three English varieties (en-AU, en-IN, en-UK), with labels for sentiment (positive, negative, neutral) and sarcasm (sarcastic, non-sarcastic). The dataset is used in few-shot in-context learning with 4 or 8 in-context demonstrations drawn only from the training split, evaluated on a held-out development/test set. The authors use this setup to study decoding policy effects without confounding by model memorization, given that all open models analyzed predate the benchmark’s release.
-
InstruSum consists of news articles paired with natural-language instructions specifying length, content focus, and style/format constraints, along with human reference summaries. The authors filter the official test split to include only instances with well-defined constraints (length, content focus, and optionally style), discarding underspecified or purely topical prompts. From each instruction, they automatically derive a compact constraint bundle: length band, required entities, avoid-words, and style/format indicators. These are used to score generated summaries via automated checkers.
-
For reasoning tasks, the authors use GSM8K, SVAMP, and StrategyQA—benchmarks requiring multi-step arithmetic and commonsense reasoning. Each instance is prompted with "Let's reason this out step by step," and models generate chains of thought under two decoding regimes: greedy (T=0) and multi-sample (T=0.7, top-p=0.9, k=8, 16, or 32). The resulting rationales are analyzed for correctness, diversity, and intermediate-step validity.
-
In safety evaluation, the authors use a threat model where harmful completions (e.g., self-harm, weapon instructions, hate speech) constitute failure. The attack distribution includes direct harm prompts, indirect/roleplay prompts, and oversight vs. hidden framing variants. Prompts are standardized into chat format and evaluated under four decoding policies: greedy, temperature sampling (T=0.7 or 1.0), multi-sample best-of-k (k=8,16,32), and adversarial search (in select cases).
-
All models are used in their instruction-tuned variants where available, and all open models have pretraining cutoffs before mid-2024, ensuring that the benchmarks are treated as fresh, post-training evaluation resources rather than memorized data.
-
Processing includes automatic constraint extraction from instructions in InstruSum, truncation of generated outputs to match requested length bands, and consistent prompt formatting across all tasks. For multi-sample decoding, the lexicographic selection rule is applied to the multi-objective score vector (semantic adequacy, length, inclusion, avoidance, style) to select the final output.
-
The datasets are used in a unified experimental protocol: models are evaluated in pure few-shot or zero-shot mode with no task-specific fine-tuning, and decoding policies are systematically varied to expose differences in behavior across greedy, stochastic, and multi-sample regimes.
Method
The authors leverage a multi-step reasoning framework to analyze how deterministic inference collapses diverse reasoning paths into a single, brittle trace. This approach constructs a reasoning graph for each problem instance by aggregating multiple sampled chains of thought into a directed acyclic graph (DAG). Each node in the graph represents a reasoning prefix, defined as a sequence of steps from the initial problem statement to a partial solution. Prefixes are considered equivalent if their step embeddings, derived from a sentence encoder, exhibit high cosine similarity, allowing the model to merge semantically similar partial paths. The graph is built by processing each sampled chain sequentially, creating new nodes for unique prefixes and connecting them via directed edges to form paths from the root (empty prefix) to leaves (complete chains of thought). Leaves are labeled as correct, near-miss, or failure based on the final answer and logical consistency of intermediate steps. The greedy decoding path is identified as a specific root-to-leaf trajectory within this graph, representing the single path selected by the deterministic policy. This framework enables the quantification of reasoning diversity and the identification of "collapsed failures," where correct strategies exist in the sampled graph but are systematically pruned by greedy inference. 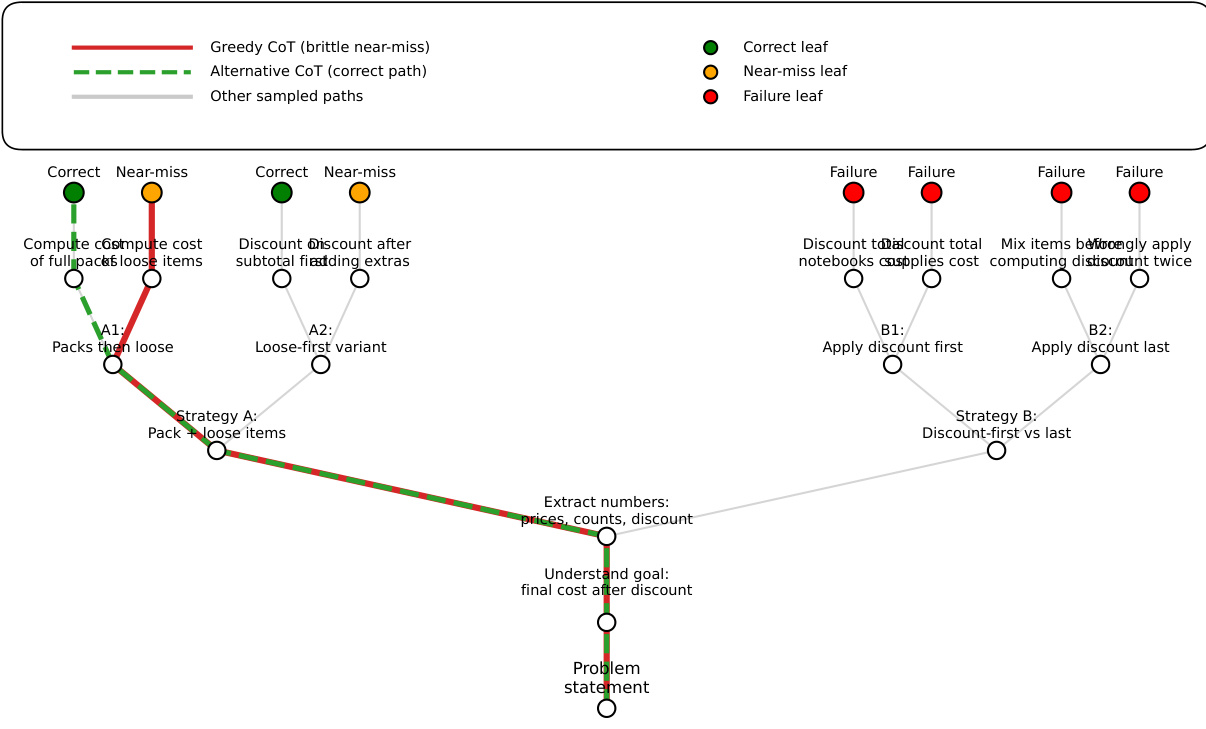
Experiment
- Main experiments validate that deterministic decoding underestimates model robustness, instruction-following ability, reasoning diversity, and safety, while stochastic decoding reveals latent capabilities across multiple tasks.
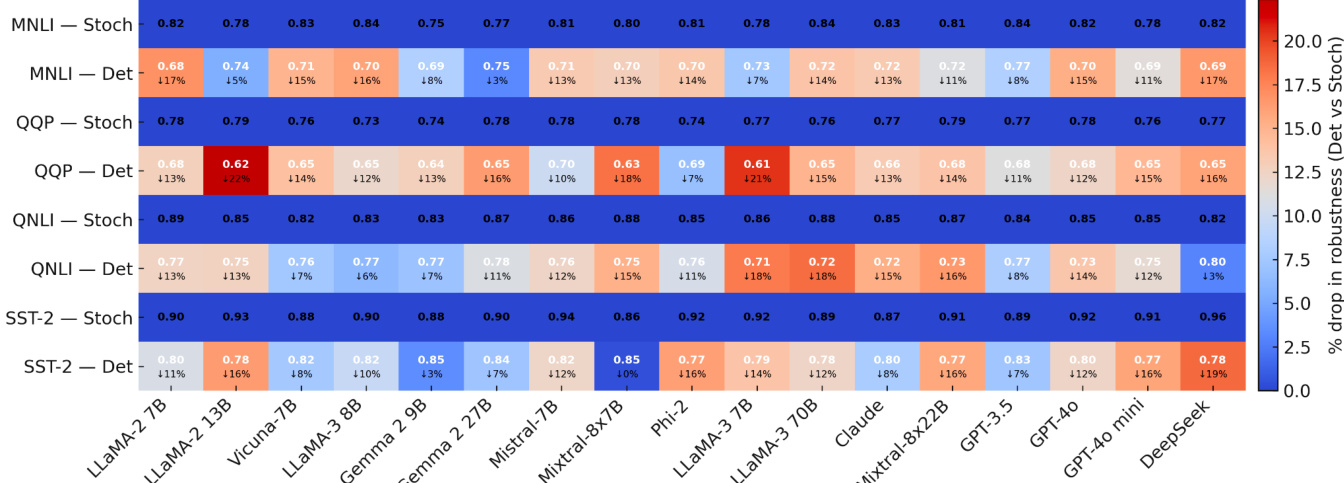
- On GLUE-style tasks (MNLI, QQP, QNLI, SST-2), stochastic decoding achieves robustness ratios up to 0.96, significantly surpassing deterministic decoding (e.g., GPT-4o: 0.87–0.93 vs. 0.75–0.84), with gains of 0.04–0.16 absolute points.
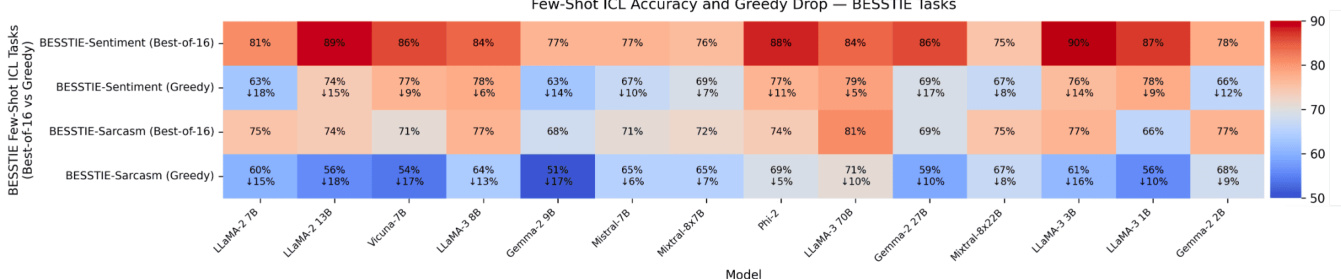
- In few-shot ICL (BESSTIE), best-of-16 decoding increases accuracy by 8–22 points over greedy decoding, with models like Phi-2 and LLaMA-2 13B showing gains >15 points, revealing hidden reasoning ability.
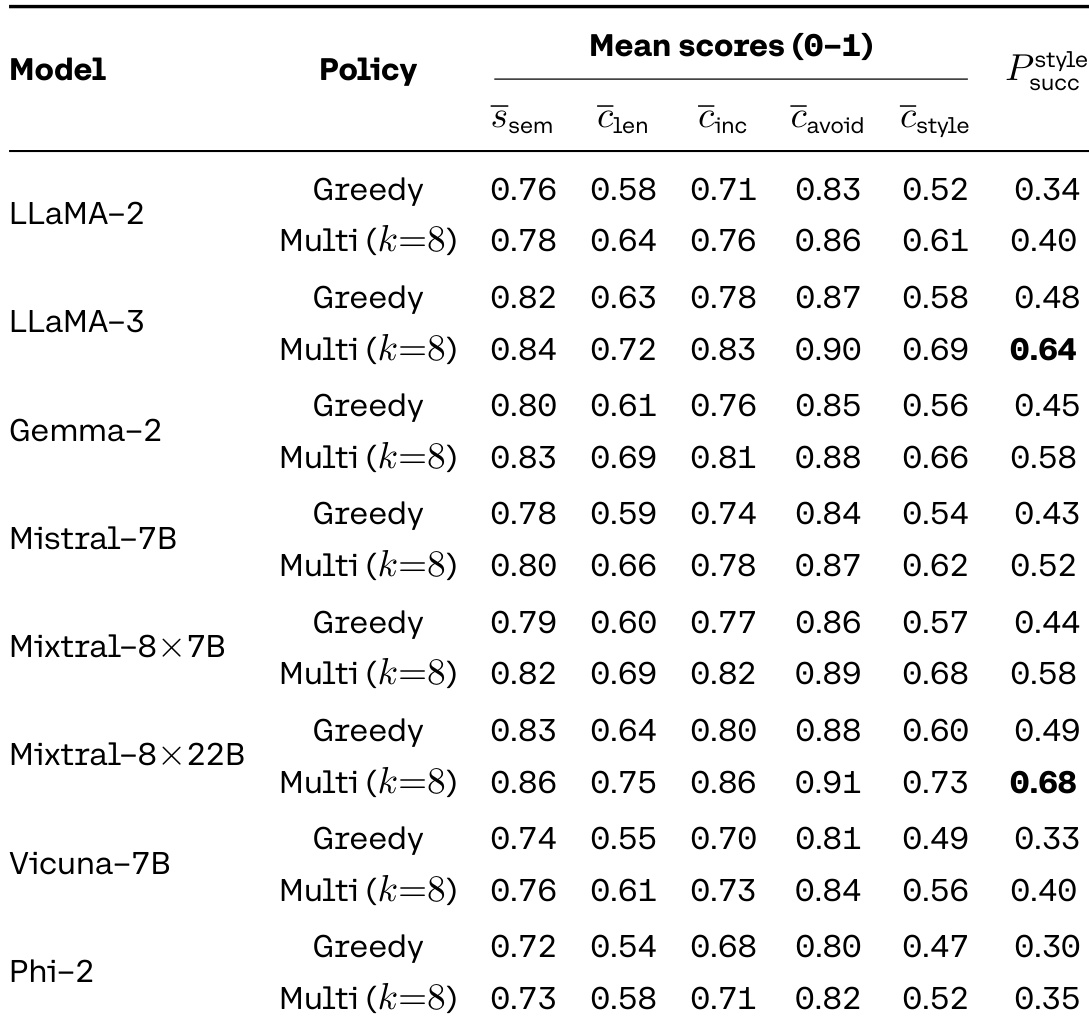
- On InstruSum, multi-sample search (k=8) improves instruction-following success by 10–13 points for large models (e.g., LLaMA-3, Mixtral-8×22B), with gains driven by improved length and style compliance.
- In reasoning tasks (GSM8K, SVAMP, StrategyQA), stochastic decoding recovers 5–15 points in accuracy, with collapsed failures accounting for up to 30% of errors in strong models, indicating that correct paths are pruned by greedy decoding.
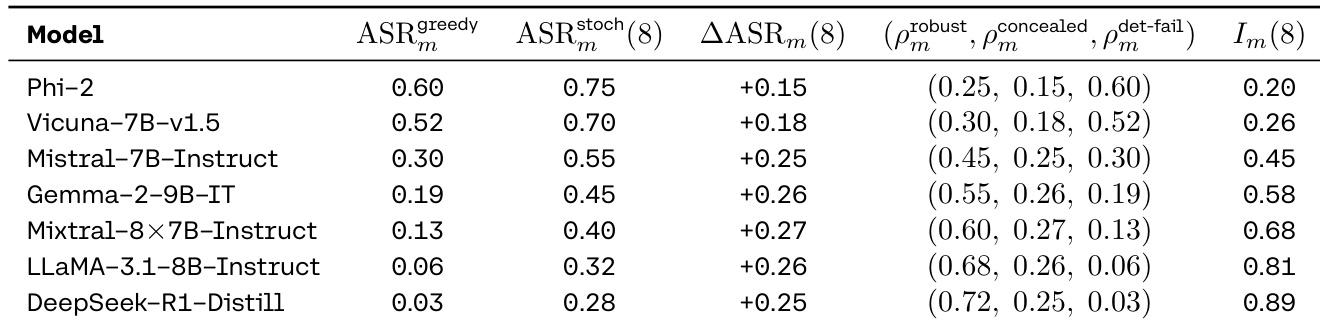
- Safety evaluations show deterministic assessment creates an illusion of robustness: models with low greedy ASR (e.g., LLaMA-3 70B) exhibit high stochastic ASR (up to 30%) and concealed risk, with illusion indices >0.8, revealing that harmful tails are invisible under greedy evaluation.
The authors use a GLUE robustness heatmap to compare deterministic and stochastic decoding across multiple models and tasks, finding that stochastic decoding consistently reveals higher robustness ratios than deterministic decoding. This indicates that deterministic inference systematically underestimates a model's generalization capacity by collapsing its distributional behavior into a single, often brittle, trace.

The authors use a best-of-k sampling strategy to evaluate few-shot in-context learning (ICL) on BESSTIE tasks, comparing it to greedy decoding. Results show that for most models, best-of-16 decoding significantly increases accuracy compared to greedy decoding, with gains often exceeding 10 percentage points. This indicates that a substantial portion of the model's in-context learning capability is hidden under deterministic inference and only becomes visible when the model is probed with a richer, multi-sample decoding policy.
The authors use the table to compare the performance of different models under greedy and multi-sample decoding policies on an instruction-following task. Results show that multi-sample decoding consistently improves performance across all models, with the largest gains observed in the style success rate, which increases from 0.34 to 0.64 for LLaMA-3 and from 0.30 to 0.68 for Mixtral-8×22B. This indicates that the models' ability to follow instructions is significantly underrepresented by greedy decoding, and that a substantial fraction of instruction-compliant trajectories is only revealed through distributional exploration.
The authors use a GLUE robustness heatmap to compare deterministic and stochastic decoding across multiple models and tasks, finding that stochastic decoding consistently yields higher robustness ratios than deterministic decoding. This indicates that deterministic inference systematically underestimates the model's generalization capacity, as it collapses the distribution of possible outputs into a single, often brittle, path, while stochastic evaluation reveals a broader and more stable set of correct behaviors.
The authors use a GLUE robustness heatmap to compare deterministic and stochastic decoding across multiple models and tasks, showing that stochastic decoding consistently yields higher robustness ratios than deterministic decoding. This indicates that deterministic inference systematically underestimates the model's generalization capacity, as it collapses the distribution of possible outputs into a single, often brittle, trace, while stochastic evaluation reveals a broader and more stable set of correct behaviors.