Command Palette
Search for a command to run...
Apprentissage de modèles mondiaux d’actions latentes dans le monde réel
Apprentissage de modèles mondiaux d’actions latentes dans le monde réel
Quentin Garrido Tushar Nagarajan Basile Terver Nicolas Ballas Yann LeCun Michael Rabbat
Résumé
Les agents capables de raisonner et de planifier dans le monde réel doivent être en mesure de prédire les conséquences de leurs actions. Bien que les modèles mondiaux possèdent cette capacité, ils nécessitent généralement des étiquettes d’actions, qui sont souvent difficiles à obtenir à grande échelle. Cela motive l’apprentissage de modèles d’actions latentes, capables d’apprendre un espace d’actions à partir de vidéos seules. Ce travail aborde le problème de l’apprentissage de modèles mondiaux à actions latentes à partir de vidéos prises dans le monde réel (in-the-wild), élargissant ainsi le cadre des travaux existants qui se concentrent principalement sur des simulations robotiques simples, des jeux vidéo ou des données de manipulation. Bien que cette approche permette de capturer des actions plus riches, elle soulève également des défis liés à la diversité des vidéos, tels que le bruit environnemental ou l’absence d’une embodiment commune entre les vidéos. Pour relever certains de ces défis, nous discutons des propriétés que les actions devraient satisfaire, ainsi que des choix architecturaux pertinents et des méthodes d’évaluation. Nous constatons que des actions latentes continues, mais contraintes, sont capables de représenter la complexité des actions présentes dans les vidéos du monde réel — une capacité que les méthodes classiques de quantification vectorielle ne parviennent pas à atteindre. Par exemple, nous observons que des changements dans l’environnement dus à des agents, tels que l’entrée d’une personne dans une pièce, peuvent être transférés d’une vidéo à une autre. Cela met en évidence la capacité à apprendre des actions spécifiques aux vidéos du monde réel. En l’absence d’une embodiment commune entre les vidéos, nous sommes principalement en mesure d’apprendre des actions latentes localisées dans l’espace, par rapport à la caméra. Toutefois, nous parvenons à entraîner un contrôleur qui associe des actions connues à leurs représentations latentes, permettant ainsi d’utiliser les actions latentes comme une interface universelle et de résoudre des tâches de planification avec notre modèle mondial, avec des performances comparables à celles des modèles conditionnés par les actions. Nos analyses et expériences constituent une étape importante vers le déploiement à grande échelle des modèles d’actions latentes dans le monde réel.
One-sentence Summary
The authors from FAIR at Meta, Inria, and NYU propose a latent action world model trained solely on in-the-wild videos, demonstrating that continuous, constrained latent actions—unlike discrete vector quantization—effectively capture complex, transferable actions across diverse real-world scenes. By learning camera-relative, spatially localized actions without a common embodiment, their model enables a universal action interface, allowing planning performance comparable to action-labeled baselines despite training on unlabeled data.
Key Contributions
- This work addresses the challenge of learning latent action world models from in-the-wild videos, where action labels are absent and video content exhibits high diversity in embodiment, environment, and agent behavior, extending beyond controlled settings like robotics simulations or video games.
- The authors demonstrate that continuous, constrained latent actions—rather than discrete representations via vector quantization—better capture the rich, diverse, and transferable actions present in real-world videos, including changes caused by external agents like humans entering a scene.
- Experiments on large-scale in-the-wild datasets show that learned latent actions can be localized relative to the camera and used to train a controller that maps known actions to latent ones, enabling planning tasks with performance comparable to action-conditioned baselines.
Introduction
The authors address the challenge of enabling agents to reason and plan in real-world environments by learning world models that predict the consequences of actions. While traditional world models rely on labeled action data—often unavailable at scale—latent action models (LAMs) aim to infer action representations directly from unlabeled videos. Prior work has largely focused on controlled settings like video games or robotic manipulation, where actions are well-defined and embodiments are consistent, limiting generalization. In contrast, this work tackles the more complex and diverse domain of in-the-wild videos, which include varied agents, unpredictable events, and no shared embodiment. The key contribution is demonstrating that continuous, constrained latent actions—rather than discrete, quantized ones—can effectively capture rich, transferable action semantics from such videos, including changes caused by external agents like people entering a scene. Despite the lack of a common embodiment, the learned latent actions become spatially localized relative to the camera, and the authors show they can serve as a universal interface for planning by training a controller to map known actions to latent ones, achieving performance comparable to action-conditioned baselines. This advances the feasibility of scaling world models to real-world, unstructured video data.
Method
The authors leverage a latent action world model framework to predict future video frames by modeling the evolution of the world state conditioned on both past observations and a latent action variable. The core architecture, illustrated in the framework diagram, consists of a frame causal encoder fθ that processes video frames into representations st, a world model pψ that predicts the next frame st+1 given the past sequence s0:t and a latent action zt, and an inverse dynamics model gϕ that infers the latent action zt from a pair of consecutive frames st and st+1. The world model pψ is trained to minimize the prediction error L=∥st+1−pψ(s0:t,zt)∥1, where zt is obtained from the inverse dynamics model. This joint training process enables the model to learn a latent action space that captures the essential information for future prediction.
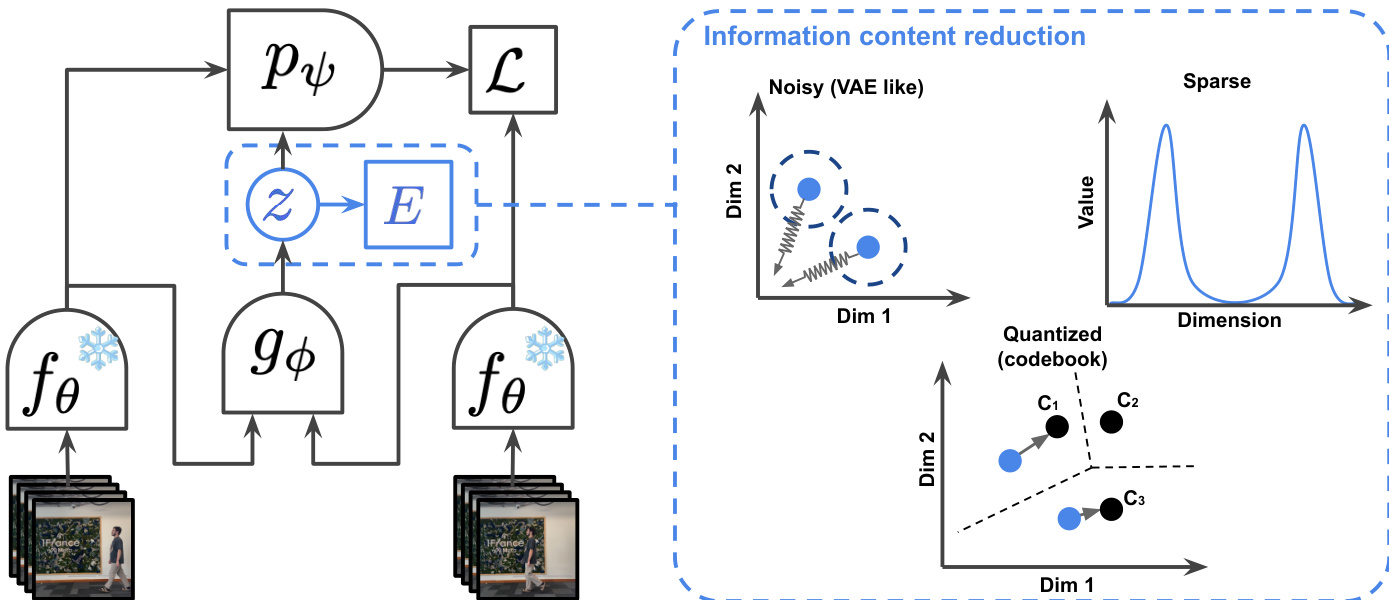
To ensure the latent action zt contains only the necessary information for prediction and avoids encoding extraneous noise or the entire future state, the authors employ three distinct information content reduction mechanisms. The first is sparsity, which constrains the latent actions to have a low L1 norm. This is achieved through a regularization term L(Z) that combines a Variance-Covariance-Mean (VCM) regularization with an energy function E(z) to promote sparsity while preventing trivial solutions. The second mechanism is noise addition, where the latent actions are regularized to follow a prior distribution, such as N(0,1), similar to a Variational Autoencoder (VAE). This is implemented via a KL divergence term that encourages the latent action distribution to match the prior. The third approach is discretization, which uses vector quantization to map continuous latent actions to a finite set of discrete codebook entries, effectively limiting the information capacity of the latent space. The framework diagram illustrates these three regularization strategies within the "Information content reduction" block.
The world model pψ is implemented as a Vision Transformer (ViT-L) with RoPE positional embeddings, and it is conditioned on the latent action zt using AdaLN-zero, which adapts the conditioning to be applied frame-wise. The latent actions zt are 128-dimensional continuous vectors by default. The model is trained using teacher forcing, where the ground truth next frame is used as input for the next prediction step during training. The training process involves optimizing the prediction loss L and the chosen latent action regularization simultaneously. The authors also train a frame causal video decoder to generate visualizations of the model's predictions, which is used for qualitative evaluation and perceptual metric computation.
The learned latent action space can be used as an interpretable interface for planning. The authors train a lightweight controller module, which can be an MLP or a cross-attention based adapter, to map real-world actions (and optionally past representations) to the learned latent actions. This controller is trained with an L2 loss to predict the latent action produced by the inverse dynamics model. Once trained, the controller can be used to generate action sequences for planning tasks. The process involves inferring the latent action from the current state and goal, and then using the world model to predict the resulting future states. The controller training process is illustrated in the diagram, showing how the controller learns to map known actions to the latent action space, with past representations helping to disambiguate the action's effect based on the current camera perspective.
Experiment
- Conducted experiments on regulating latent action information content in in-the-wild videos, showing that sparse and noisy continuous latent actions adapt better to complex, diverse actions than discrete or quantized ones.
- Demonstrated that latent actions encode spatially-localized, camera-relative transformations without requiring a common embodiment, enabling effective transfer of motion between objects (e.g., human to ball) and across videos.
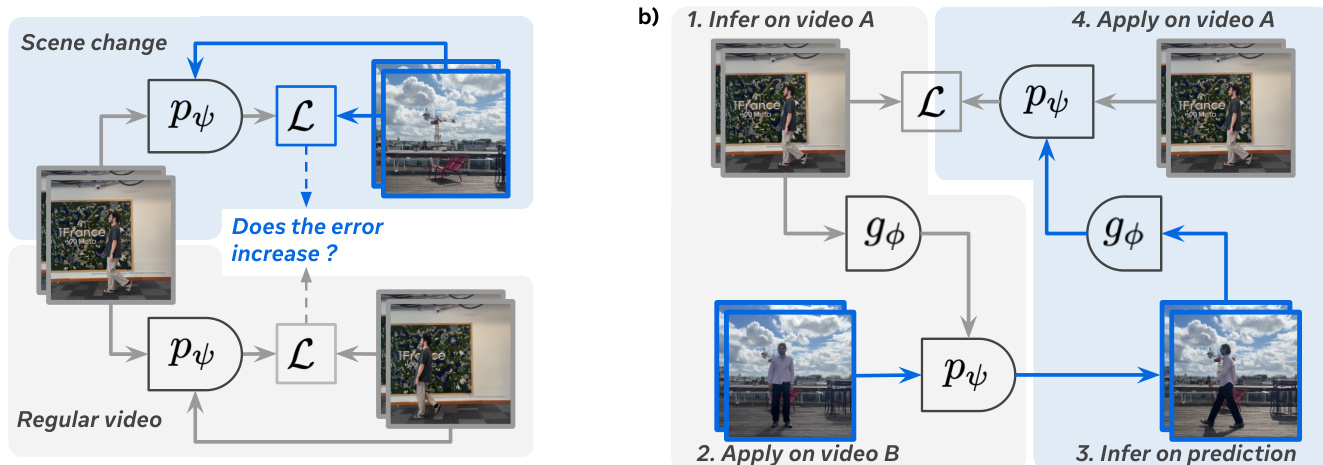
- Validated that latent actions do not leak future frame information, as prediction error more than doubles under artificial scene cuts, confirming they capture meaningful, non-cheating representations.
- Showed high cycle consistency in latent action transfer across videos (Kinetics and RECON), with minimal increase in prediction error, indicating robust and reusable action representations.
- Achieved planning performance on robotic manipulation (DROID) and navigation (RECON) tasks comparable to models trained on domain-specific, action-labeled data, using only a small controller trained on natural videos.
- On DROID and RECON datasets, the latent action world model achieved planning performance within 0.06–0.05 L1 error, matching or approaching baselines trained with explicit action labels.
- Found that optimal performance arises from a balanced latent action capacity—too high capacity reduces transferability and generality, while too low limits expressiveness.
- Scaling experiments showed improved inverse dynamics model performance with larger models, longer training, and more data, with training time yielding the clearest gains in downstream planning.
The authors evaluate the planning performance of latent action models with varying capacities on robotic manipulation tasks, measuring the error in cumulative displacement. Results show that models with high capacity latent actions achieve lower error, with the V-JEPA 2 + WM model achieving the best performance at 0.05 meters.
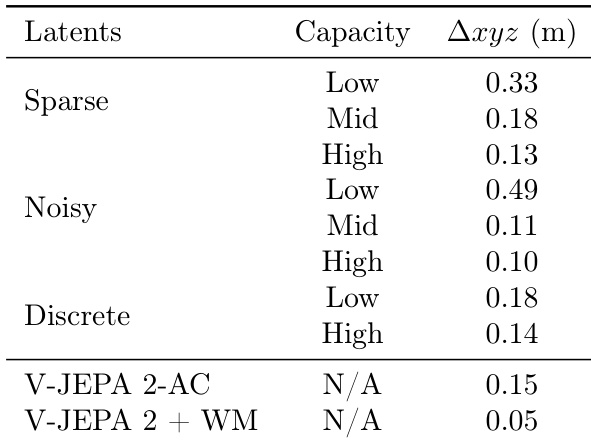
The authors evaluate the transferability of latent actions across different regularization methods and capacities, measuring prediction error increases when actions inferred on one video are applied to another. Results show that sparse and noisy latent actions achieve lower prediction errors with higher capacity, while discrete latent actions perform worse, particularly at high capacity, indicating that continuous latent actions are more effective for transfer.
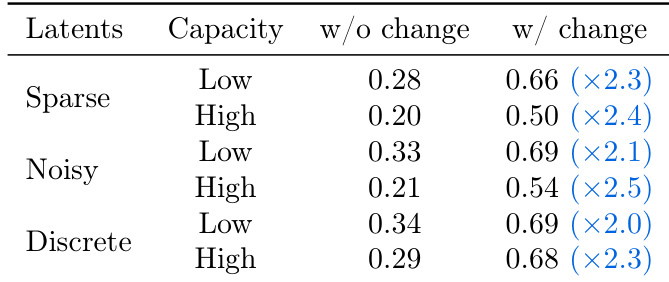
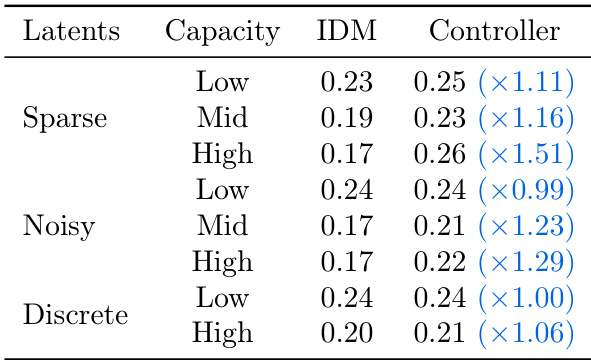
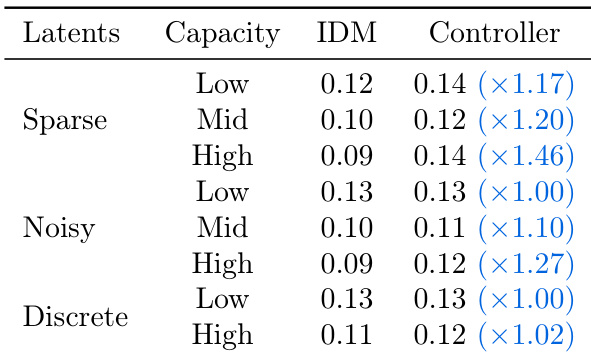
The authors compare different latent action regularization methods and their impact on prediction and control performance. Results show that sparse and noisy latent actions achieve lower prediction errors in the inverse dynamics model (IDM) and maintain consistent performance when used for control, while discrete latent actions perform worse in both settings. The best control performance is achieved with mid-capacity sparse and noisy latents, indicating a balance between action complexity and identifiability.
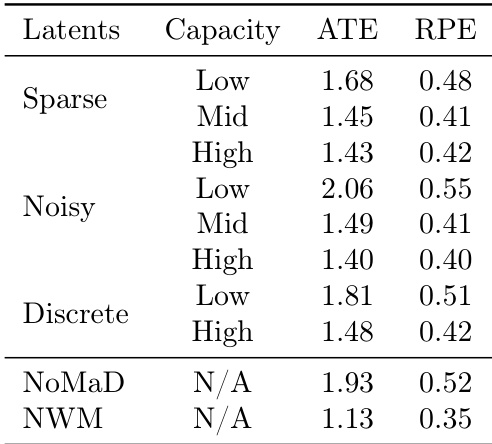
The authors evaluate the performance of different latent action regularizations on planning tasks using ATE and RPE metrics. Results show that noisy latent actions with high capacity achieve the lowest ATE and RPE values, outperforming sparse and discrete actions, while the NoMaD and NWM baselines perform worse or are not applicable.
The authors compare different latent action regularization methods, finding that sparse and noisy latent actions achieve lower prediction errors in both inverse dynamics model (IDM) and controller tasks compared to discrete ones. While higher capacity generally improves performance, the best results are achieved with moderate capacity, indicating a trade-off between action complexity and transferability.