Command Palette
Search for a command to run...
Collaboration de LLM au niveau des tokens par FusionRoute
Collaboration de LLM au niveau des tokens par FusionRoute
Nuoya Xiong Yuhang Zhou Hanqing Zeng Zhaorun Chen Furong Huang Shuchao Bi Lizhu Zhang Zhuokai Zhao
Résumé
Les grands modèles linguistiques (LLM) présentent des forces dans divers domaines. Toutefois, atteindre une performance élevée dans ces différents domaines à l’aide d’un seul modèle généraliste exige généralement une augmentation de taille qui rend son entraînement et son déploiement prohibitivement coûteux. À l’inverse, bien que les modèles plus petits spécialisés dans un domaine particulier soient bien plus efficaces, ils peinent à généraliser au-delà de leurs distributions d’apprentissage. Pour résoudre ce dilemme, nous proposons FusionRoute, un cadre robuste et efficace de collaboration multi-LLM au niveau des tokens, dans lequel un routeur léger sélectionne simultanément, à chaque étape de décodage : (i) l’expert le plus adapté, et (ii) apporte une logit complémentaire qui affine ou corrige la distribution du prochain token de l’expert sélectionné par addition de logit. Contrairement aux méthodes existantes de collaboration au niveau des tokens, qui s’appuient exclusivement sur les sorties fixes des experts, nous fournissons une analyse théorique montrant que la stratégie de routage basée uniquement sur les experts est fondamentalement limitée : à moins que des hypothèses globales de couverture fortes ne soient satisfaites, elle ne peut en général réaliser la politique de décodage optimale. En enrichissant la sélection d’experts par un générateur complémentaire entraînable, FusionRoute élargit la classe de politiques effectives et permet la récupération des fonctions de valeur optimales sous des conditions modérées. Expérimentalement, sur les familles Llama-3 et Gemma-2, ainsi que sur divers benchmarks couvrant le raisonnement mathématique, la génération de code et le respect des instructions, FusionRoute surpasser à la fois les approches de collaboration au niveau de la séquence et au niveau du token, ainsi que les méthodes de fusion de modèles et le fine-tuning direct, tout en restant compétitive avec les experts spécialisés sur leurs tâches respectives.
One-sentence Summary
The authors from Meta AI, Carnegie Mellon University, University of Chicago, and University of Maryland propose FusionRoute, a token-level multi-LLM collaboration framework that dynamically selects domain-specific experts while training a lightweight router to provide complementary logits for refinement. Unlike prior methods relying solely on expert outputs, FusionRoute theoretically overcomes fundamental limitations of pure expert routing by expanding the policy class through trainable correction, enabling robust, efficient, and general-purpose performance across math, coding, and instruction-following tasks without requiring joint training or architectural compatibility.
Key Contributions
- Existing token-level multi-LLM collaboration methods are limited by their reliance on fixed expert outputs, which cannot in general realize optimal decoding policies without strong global coverage assumptions, leading to suboptimal performance on diverse tasks.
- FusionRoute introduces a novel token-level collaboration framework where a lightweight router not only selects the most suitable expert at each step but also generates a trainable complementary logit to refine the expert's output via logit addition, expanding the effective policy class and enabling recovery of optimal value functions under mild conditions.
- Empirically, FusionRoute outperforms sequence-level and token-level collaboration methods, model merging, and direct fine-tuning across Llama-3 and Gemma-2 families on benchmarks for mathematical reasoning, code generation, and instruction following, while matching the performance of domain-specialized experts on their respective tasks.
Introduction
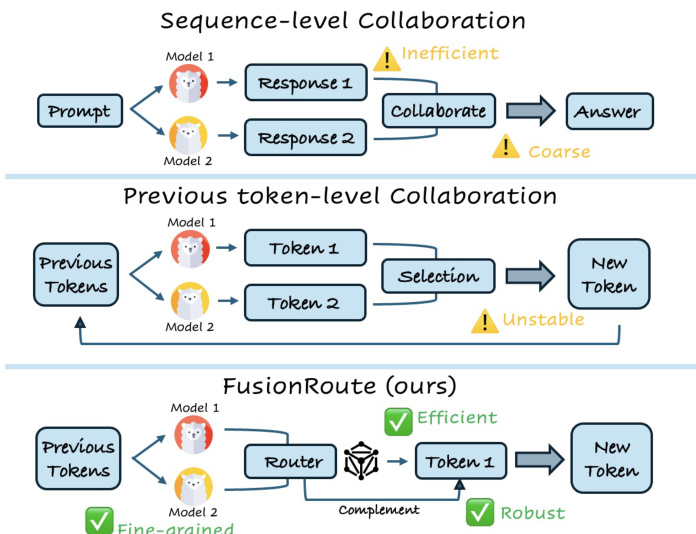
Large language models (LLMs) excel in specific domains but face a trade-off between generalization and efficiency—large general-purpose models are costly to train and deploy, while smaller specialized models lack robustness outside their training distributions. Prior approaches like mixture-of-experts (MoE) and model merging require joint training, architectural compatibility, or gradient access, limiting flexibility, while multi-agent systems often operate at the coarse sequence level, leading to inefficiency and performance degradation. Token-level collaboration methods offer finer control but are fragile, relying solely on expert outputs without mechanisms to correct or refine decisions. The authors introduce FUSIONROUTE, a lightweight, token-level multi-LLM collaboration framework that uses a trainable router to both select the most suitable expert at each step and generate complementary logits to refine the next-token distribution. This dual mechanism expands the policy space beyond fixed expert outputs, enabling recovery of optimal behavior under mild conditions. Empirically, FUSIONROUTE outperforms existing sequence- and token-level methods, model merging, and fine-tuning across diverse benchmarks, while matching domain experts on their respective tasks—achieving high performance without training or architectural constraints.
Method
The authors propose FusionRoute, a token-level collaboration framework designed to enable robust and efficient coordination among multiple specialized language models. The core architecture centers on a lightweight router model, which is post-trained from a base language model and operates at the token level to select the most suitable expert for each generation step while simultaneously providing a complementary logit signal. This dual functionality allows FusionRoute to both leverage the domain-specific strengths of expert models and correct or refine their outputs when they are uncertain or unreliable.
Refer to the framework diagram. The overall process begins with a prompt and a sequence of previously generated tokens. The router model processes this context and produces two outputs: a vector of routing weights that determines the preferred expert from a set of specialized models, and a set of logits that serve as a complementary correction signal. The routing weights are generated via a lightweight linear projection applied to the final hidden state of the base model. During inference, the router selects the expert with the highest routing weight and combines its logits with the router's complementary logits through logit addition to form the final next-token distribution. This combined distribution is then used to generate the next token greedily, ensuring that the final output benefits from both the expert's specialized knowledge and the router's adaptive refinement.
The training of the FusionRoute router is a staged and decoupled process, consisting of a Supervised Fine-Tuning (SFT) phase followed by a preference optimization phase. The SFT phase is designed to establish two foundational properties: accurate next-token prediction and reliable token-level expert selection. This phase jointly optimizes the base model parameters and the routing projection using a combination of a standard language modeling loss and a routing loss. The routing loss is specifically designed to focus on informative token positions where experts disagree, thereby preventing the router from being dominated by trivial agreement patterns. The final SFT objective is a weighted sum of the language modeling loss and the routing loss.
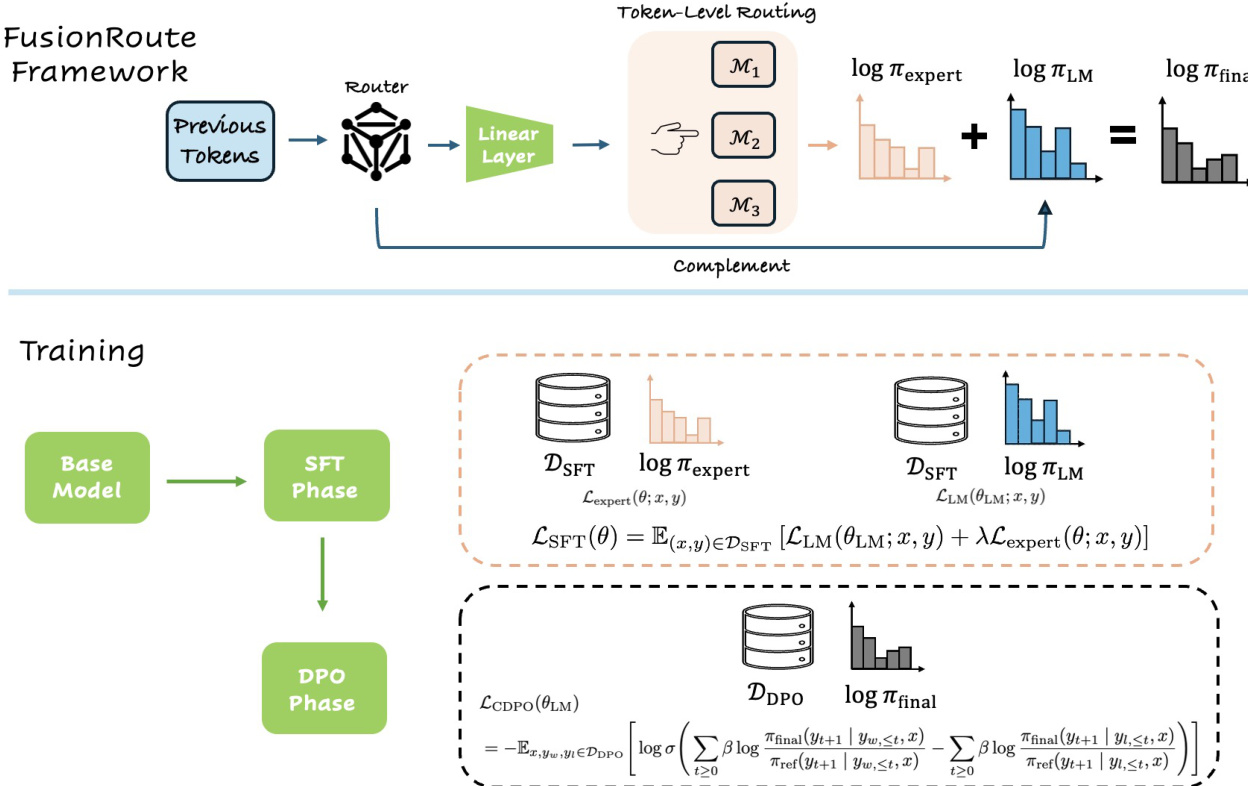
The preference optimization phase, which uses a modified DPO objective, is applied only to the base model parameters to refine the final policy. To preserve the expert-selection capability learned during SFT, the routing projection is excluded from this optimization. This decoupled strategy prevents the routing layer from overfitting to preference-alignment signals and losing its ability to correctly select among experts. The training process is further enhanced by a mixed training scheme, where preference-optimization data is jointly mixed with supervised SFT data, ensuring consistency between the base model and the routing layer. This two-phase training strategy enables the router to acquire an effective complementary logit contribution while maintaining reliable expert selection.
Experiment
- Evaluated FUSIONROUTE against sequence-level collaboration, token-level collaboration, model merging, and fine-tuned single models on Llama-3 and Gemma-2 families.
- On cross-domain benchmarks (GSM8K, MATH500, MBPP, HumanEval, IfEval), FUSIONROUTE achieved the highest average performance across both model families, outperforming all baselines and matching or exceeding domain-specific experts on individual tasks.
- On a held-out general dataset, FUSIONROUTE achieved a significantly higher GPT-4o win rate compared to the fine-tuned baseline, demonstrating superior overall response quality in fluency, alignment, and formatting.
- The performance gap between FUSIONROUTE and baselines widened on larger 8B models, indicating that complementary routing becomes increasingly beneficial with model scale, while expert-only collaboration degrades.
- Ablation studies confirmed that the router’s complementary logit contribution is essential: removing it led to significant performance drops, especially in coding and instruction-following tasks.
- CDPO training stage was critical—FUSIONROUTE with CDPO substantially outperformed the SFT-only variant, showing that preference optimization enhances correction of expert failures and improves general response quality.
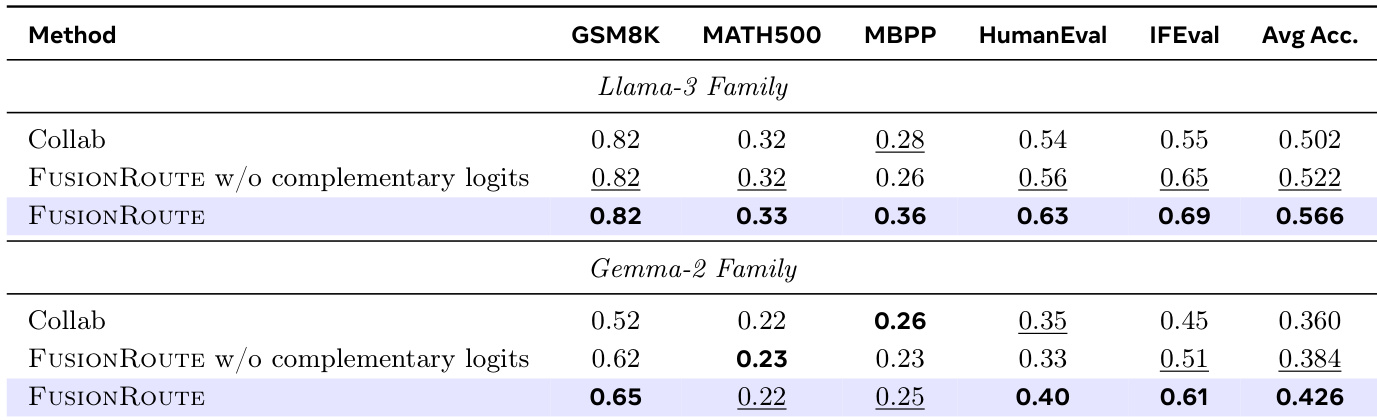
The authors evaluate FUSIONROUTE on five cross-domain benchmarks, including GSM8K, MATH500, MBPP, HumanEval, and IfEval, using a subset of samples from each dataset with a maximum of 400 new tokens per generation. The results show that FUSIONROUTE achieves the highest average performance across all domains on both the Llama-3 and Gemma-2 families, consistently outperforming baselines that rely on sequence-level collaboration, token-level collaboration, model merging, and fine-tuned models.
The authors use FUSIONROUTE to evaluate cross-domain performance across multiple models and collaboration methods, showing that it consistently achieves the highest average accuracy on both the Llama-3 and Gemma-2 families. Results show that FUSIONROUTE outperforms sequence-level collaboration, token-level collaboration, model merging, and fine-tuned baselines, demonstrating its effectiveness in selecting domain-appropriate experts while maintaining strong performance on general tasks.
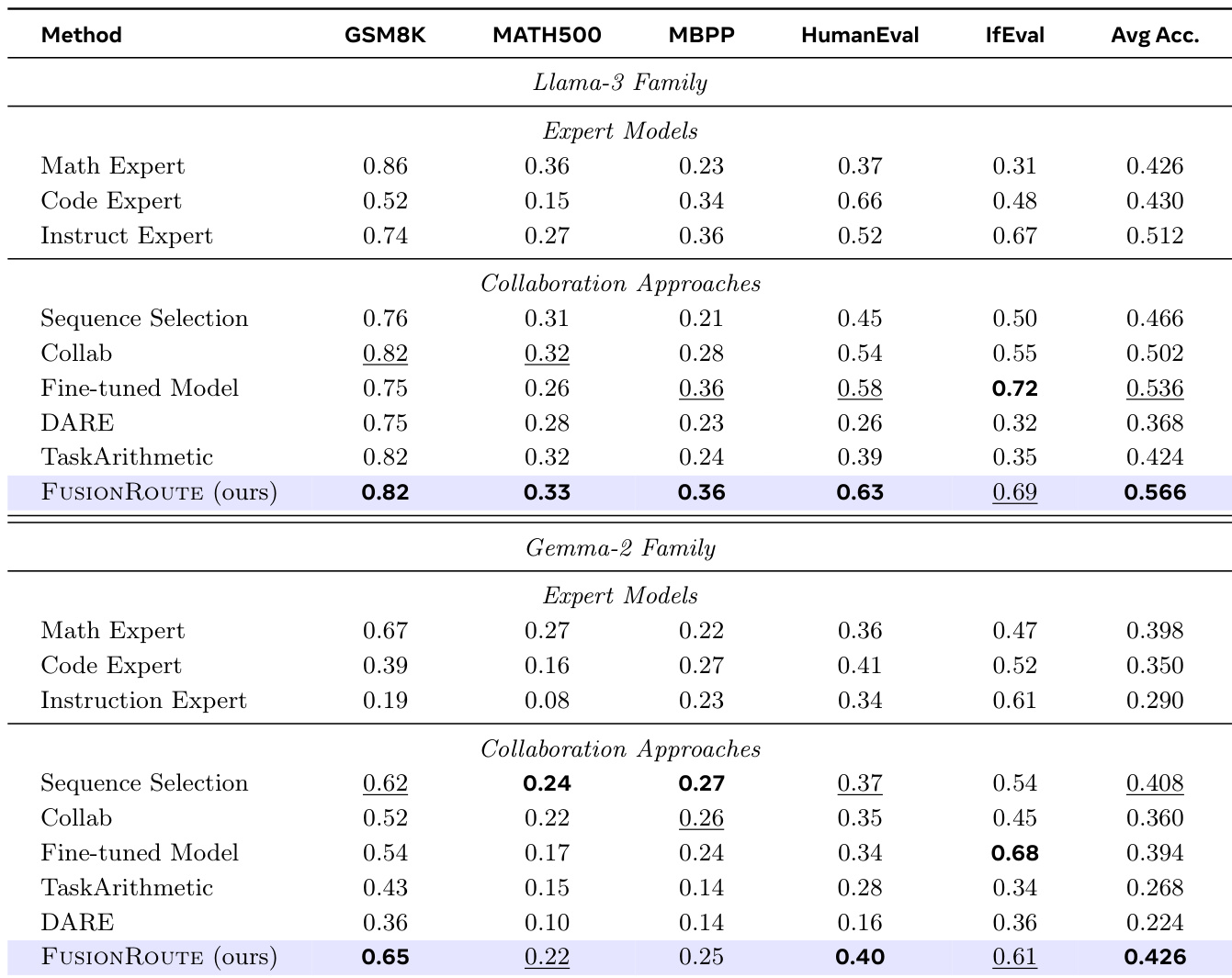
The authors use a cross-domain evaluation to compare FUSIONROUTE against baselines on both the Llama-3 and Gemma-2 families, showing that FUSIONROUTE achieves the highest average accuracy across all tasks. Results show that FUSIONROUTE consistently outperforms other methods, including token-level collaboration and model merging, and matches or exceeds expert models on individual benchmarks.