Command Palette
Search for a command to run...
Chorégraphier un monde d'objets dynamiques
Chorégraphier un monde d'objets dynamiques
Yanzhe Lyu Chen Geng Karthik Dharmarajan Yunzhi Zhang Hadi Alzayer Shangzhe Wu Jiajun Wu
Résumé
Les objets dynamiques dans notre monde physique à 4 dimensions (3D + temps) évoluent constamment, se déforment et interagissent avec d'autres objets, donnant lieu à une grande diversité de dynamiques scéniques en 4D. Dans cet article, nous présentons une pipeline générative universelle, CHORD, pour la chorégraphie des objets dynamiques et des scènes ainsi que la synthèse de ces phénomènes. Les pipelines traditionnelles basées sur des règles pour générer ces dynamiques reposent sur des heuristiques spécifiques aux catégories d’objets, mais sont coûteuses en main-d’œuvre et peu évolutives. Les méthodes récentes basées sur l’apprentissage nécessitent généralement de grandes quantités de données, qui peuvent ne pas couvrir toutes les catégories d’objets d’intérêt. Notre approche, en revanche, tire parti de l’universalité des modèles génératifs vidéo en proposant une pipeline fondée sur la distillation pour extraire les informations riches sur le mouvement lagrangien cachées dans les représentations eulériennes des vidéos 2D. Notre méthode est universelle, polyvalente et indépendante des catégories. Nous démontrons son efficacité à travers des expériences visant à générer une large variété de dynamiques 4D multi-corps, mettons en évidence ses avantages par rapport aux méthodes existantes, et illustrons son application dans la génération de politiques de manipulation robotique. Page du projet : https://yanzhelyu.github.io/chord
One-sentence Summary
Stanford University, University of Cambridge, and University of Maryland present CHORD, a universal, category-agnostic generative pipeline that distills Lagrangian motion from Eulerian video representations to synthesize complex multi-body 4D dynamics, enabling scalable, data-efficient animation and robotics manipulation policy generation without relying on category-specific rules or large-scale datasets.
Key Contributions
- Existing methods for generating 4D scene dynamics are limited by reliance on category-specific rules or scarce, narrow-scope datasets, making them non-scalable and unable to model diverse object interactions and deformations across categories.
- CHORD introduces a novel 4D motion representation with a hierarchical spatial structure and a Fenwick tree-inspired cumulative temporal design, enabling stable, coherent, and diverse motion generation through distillation from video models.
- The framework enables zero-shot robotic manipulation by generating physically grounded Lagrangian trajectories, and demonstrates superior performance over prior methods on diverse dynamic scenes, including multi-body interactions and deformable objects.
Introduction
The authors tackle the challenge of generating realistic, scene-level 4D dynamics—3D object motions over time—where multiple objects deform and interact, a key need for embodied AI and robotics. Prior methods are limited by reliance on category-specific rules, scarce 4D interaction data, or inability to scale across diverse object types. Existing learning-based approaches struggle with high-dimensional, temporally irregular deformations and are hindered by incompatibility with modern video generative models. The authors introduce CHORD, a universal generative pipeline that distills 4D motion from 2D video models by treating them as a high-level choreographer. Their key innovations are a novel 4D motion representation combining a hierarchical, bi-level spatial control and a Fenwick tree-inspired cumulative temporal structure, which enforces smoothness and coherence, and a new distillation strategy for flow-based video models that enables effective guidance via Score Distillation Sampling. This framework generates physically plausible, multi-object interactions without category-specific priors and enables zero-shot robotic manipulation by producing Lagrangian deformation trajectories.
Dataset

- The dataset comprises 3D assets sourced from Sketchfab and BlenderKit, with static scene snapshots generated in Blender.
- 3D-GS rendering for mesh initialization and 4D optimization is performed using gsplat, and video generation is driven by the Wan 2.2 (14B) image-to-video model.
- All training is conducted at a resolution of 832 × 464, with deformation sequences optimized over 41 frames.
- Control points are initialized using signed distance fields (SDFs) from object meshes, with voxel centers inside the object extracted via a grid-based occupancy check.
- Farthest point sampling followed by K-means clustering determines control point positions, while initial scale is set as the average distance to the three nearest neighbors; rotations are initialized as identity.
- During training, control point positions are fixed, and only covariance matrices (scales and rotations) are optimized.
- A split training schedule is applied: at iteration 100, deformations after frame 30 are reinitialized to their state at frame 30 to improve stability.
- Learning rates follow a log-linear decay: deformation and scale parameters decay from 0.006 to 0.00006, rotations from 0.003 to 0.00003, CFG scale from 25 to 12, temporal regularization weight from 9.6 to 1.6, and spatial regularization weight from 3000 to 300.
- Voxel size is automatically determined via binary search to ensure approximately 7,500 voxel centers near each object’s surface.
- Each asset is trained for 2,000 iterations with a batch size of 4, taking about 20 hours on an NVIDIA H200 GPU.
- For robot manipulation tasks, real-world objects from "pick banana" and "lower lamp" scenarios are scanned directly and used in the pipeline.
- For other cases, where accurate scanning is difficult, digital replicas are created in Blender with dimensions matching real object measurements.
Method
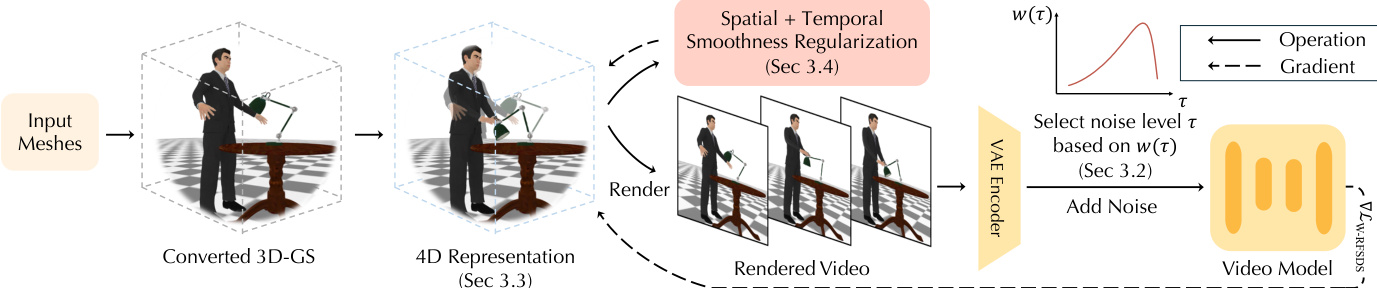
The authors leverage a hierarchical 4D representation to enable the distillation of dynamic 4D scenes from static 3D meshes, using a modified Score Distillation Sampling (SDS) framework tailored for Rectified Flow (RF) video generative models. The overall framework begins with input meshes, which are first converted into 3D Gaussian Splatting (3D-GS) representations to facilitate smooth gradient computation. This 3D-GS model serves as the canonical shape, which is then used to initialize a 4D representation that captures temporal motion. The 4D representation is refined iteratively by sampling camera poses, rendering corresponding videos, and passing them through a video generation model to obtain optimization gradients. The process is guided by a novel SDS target derived for RF models, which aligns the optimization objective with the model's training loss. As shown in the figure below, the framework integrates spatial and temporal regularization to stabilize the optimization process and ensure coherent motion.
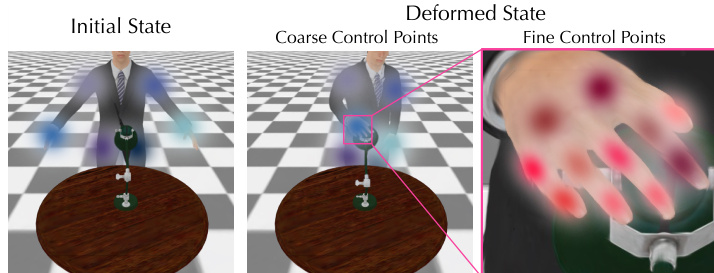
The core of the method lies in the hierarchical 4D representation, which is designed to stabilize the optimization of complex deformations. This representation consists of a canonical 3D-GS geometry and a 4D motion component that deforms the canonical shape over time. The deformation fields are represented using a novel hierarchical control point structure, which reduces the dimensionality of the high-dimensional spatial deformation fields. As illustrated in the figure below, this structure employs a coarse level of control points to capture large-scale deformations and a fine level to refine local details. Each control point is defined by a mean position and a covariance matrix, which determine its radius of influence. The deformation of a Gaussian is computed by blending transformations from neighboring control points using linear blend skinning. The blending weights are determined by a Gaussian kernel based on the distance from the Gaussian to the control point.
The optimization of the control points is performed in a coarse-to-fine manner, synchronized with the noise schedule. At the beginning of the optimization, when the noise level is high, only the coarse control points are optimized to generate substantial motion. As the noise level anneals to a lower value, the fine control points are introduced to add residual deformations, allowing for the refinement of local details. This two-stage optimization strategy aligns with the inherent nature of the SDS gradient, which is noisy at high noise levels but more stable at low noise levels.
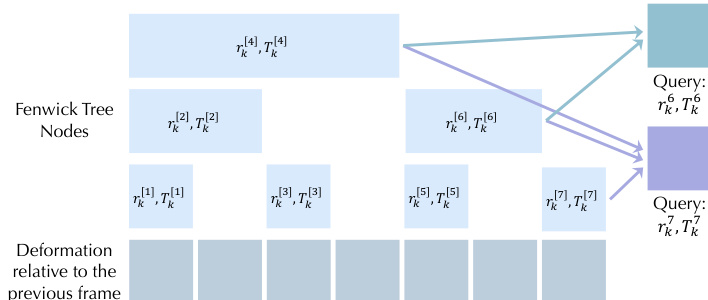
To further improve temporal coherence, the authors introduce a temporal hierarchy using a Fenwick tree data structure. As shown in the figure below, the sequence of deformations for each control point is represented as a set of nodes in the Fenwick tree, where each node encodes the accumulated deformation over a specific range of frames. This range-based decomposition allows deformations at different frames to share parameters through overlapping intervals, which greatly improves temporal coherence and enables the learning of long-horizon motion. The final deformation at a given frame is obtained by composing all relevant nodes from the Fenwick tree.
The optimization process is further stabilized by two regularization terms. A temporal regularization loss is defined by rendering a 3D flow map video from the same viewpoint, which measures the smoothness of motion over time. A spatial regularization loss is computed using an As-Rigid-As-Possible (ARAP) formulation over a uniformly distributed point cloud near the surface of each object, which encourages local spatial consistency in the deformations. These regularization terms are integrated into the overall optimization framework to ensure that the generated motion is both temporally coherent and spatially plausible.
Experiment
- Evaluated on diverse dynamic scenes with multiple interacting objects, comparing against state-of-the-art baselines: Animate3D, AnimateAnyMesh, MotionDreamer, and TrajectoryCrafter-based 4D reconstruction.
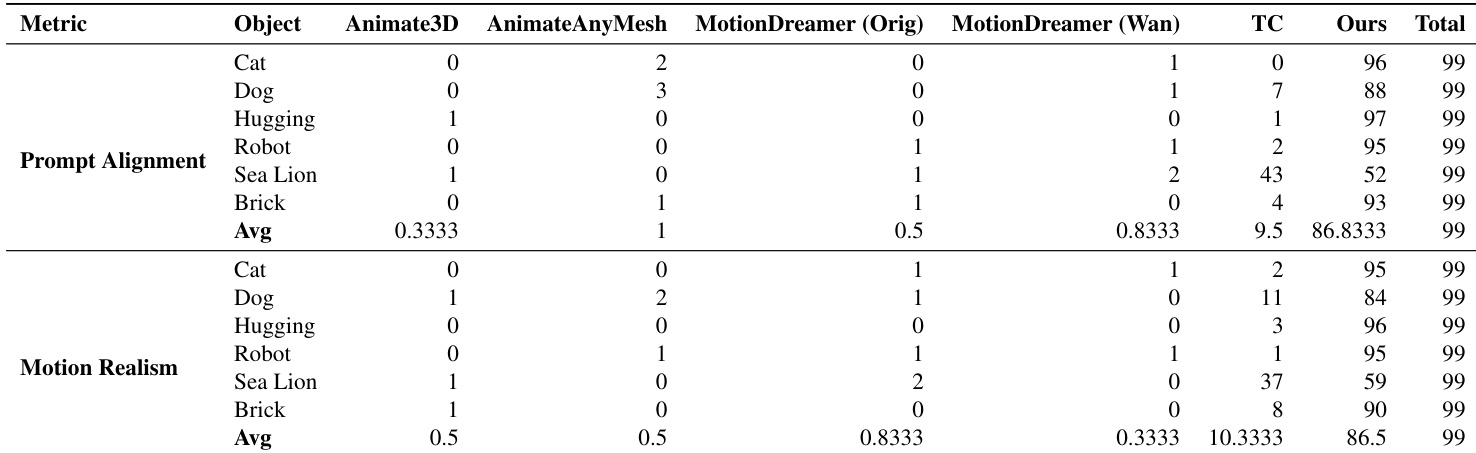
- On six scene animations, achieved the highest Semantic Adherence (SA) and second-highest Physical Commonsense (PC) scores in quantitative evaluation using VideoPhy-2, with 99 participants in a user study favoring our method for prompt alignment and motion realism.
- Demonstrated strong prompt alignment and natural motion in qualitative results, outperforming baselines that suffer from misalignment, artifacts, or temporal inconsistencies.
- Extended to long-horizon motion generation by iterative frame propagation, real-world object animation using real video-trained models, and robot manipulation guided by dense object flow for rigid, articulated, and deformable objects.
- Ablation studies confirmed the necessity of noise-level sampling, Fenwick tree for deformation modeling, hierarchical control points, and regularization losses to prevent artifacts, flickering, and distortions.
- On single-object animation tasks, achieved 89.6% preference for prompt alignment and 84% for motion realism in a 50-participant user study, with full results in supplementary tables.
- Failure cases primarily stem from limitations of the underlying video generator and inability to generate objects not present in the initial static scene, leading to missing or incomplete motion.
Results show that the proposed method, CHORD, achieves the highest scores in both user study metrics—Alignment and Realism—outperforming all baselines. In the VideoPhy-2 evaluation, CHORD attains the second-highest score in Physical Commonsense and the highest in Semantic Adherence, demonstrating superior prompt alignment and natural motion generation compared to existing approaches.
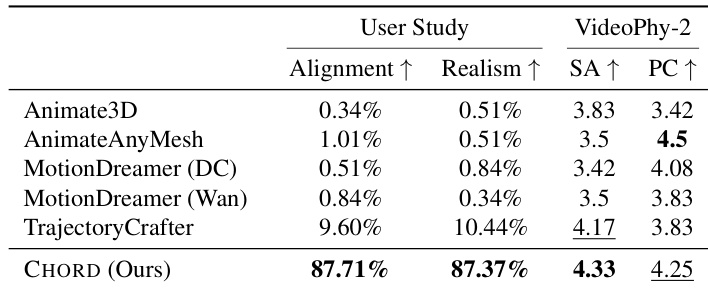
The authors conduct a user study to evaluate prompt alignment and motion realism, comparing their method against several baselines including Animate3D, AnimateAnyMesh, MotionDreamer, and TrajectoryCrafter. Results show that their method achieves the highest average score for prompt alignment and the second-highest for motion realism, outperforming most baselines in both metrics.
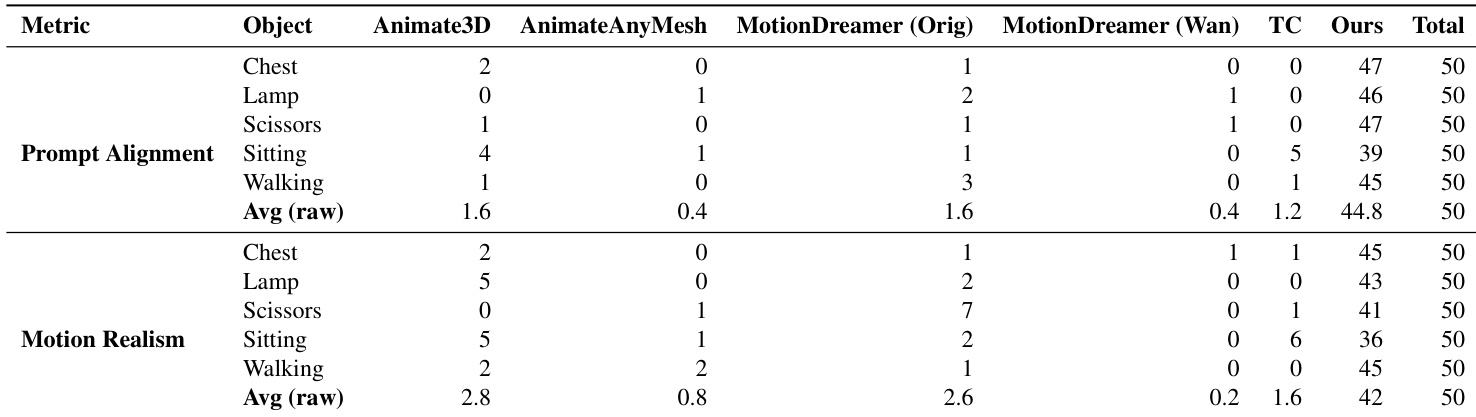
Results show that the proposed method achieves the highest average score in prompt alignment and motion realism across all evaluated scenes, outperforming all baselines. The authors use a user study with 99 participants to evaluate the methods, and the data indicates that their approach consistently receives the most votes for both metrics, with the highest average scores in both categories.