Command Palette
Search for a command to run...
Comment les grands modèles linguistiques apprennent-ils des concepts pendant un pré-entraînement continu ?
Comment les grands modèles linguistiques apprennent-ils des concepts pendant un pré-entraînement continu ?
Barry Menglong Yao Sha Li Yunzhi Yao Minqian Liu Zaishuo Xia Qifan Wang Lifu Huang
Résumé
Les êtres humains comprennent principalement le monde à travers des concepts (par exemple, « chien »), des représentations mentales abstraites qui structurent la perception, le raisonnement et l'apprentissage. Toutefois, la manière dont les grands modèles linguistiques (LLM) acquièrent, conservent et oublient de tels concepts au cours d'un pré-entraînement continu reste mal comprise. Dans ce travail, nous étudions comment les concepts individuels sont acquis et oubliés, ainsi que la manière dont plusieurs concepts interagissent par interférence ou synergie. Nous associons ces dynamiques comportementales aux « circuits conceptuels » internes des LLM, c'est-à-dire des sous-graphes computationnels liés à des concepts spécifiques, et intégrons des métriques de graphes pour caractériser la structure de ces circuits. Notre analyse révèle : (1) les circuits conceptuels des LLM fournissent un signal non trivial et statistiquement significatif de l'acquisition et de l'oubli des concepts ; (2) les circuits conceptuels présentent un motif temporel en stades durant le pré-entraînement continu, marqué par une augmentation initiale, suivie d'une diminution progressive et d'une stabilisation ; (3) les concepts qui connaissent de plus fortes gains d'apprentissage montrent généralement un oubli plus important lors des étapes ultérieures d'entraînement ; (4) les concepts sémantiquement proches induisent une interférence plus forte que ceux faiblement liés ; (5) les connaissances conceptuelles diffèrent quant à leur transférabilité, certaines facilitant significativement l'apprentissage d'autres. Ensemble, ces résultats offrent une perspective au niveau du circuit pour comprendre les dynamiques d'apprentissage des concepts et orientent la conception de stratégies d'entraînement plus interprétables et robustes, prenant en compte les concepts, pour les LLM.
One-sentence Summary
The authors from UC Davis, Virginia Tech, UCLA, and Meta AI propose a circuit-level analysis of concept learning and forgetting in LLMs, revealing that Concept Circuits—computational subgraphs linked to specific concepts—exhibit stage-wise dynamics, semantic interference, and transferability, enabling interpretable, robust training strategies through graph-based characterization of concept interactions.
Key Contributions
-
This work presents the first systematic study of concept acquisition and forgetting in large language models during continual pretraining, linking behavioral dynamics to internal Concept Circuits—computational subgraphs associated with specific concepts—and demonstrating that graph metrics on these circuits provide a statistically significant signal of learning and forgetting.
-
The study reveals a stage-wise temporal pattern in concept circuits, with an initial increase followed by gradual decrease and stabilization during continued training, indicating distinct phases of concept consolidation, while also showing that concepts with larger learning gains tend to experience greater subsequent forgetting.
-
It identifies interference and synergy across concepts, finding that semantically similar concepts induce stronger interference, and that certain types of conceptual knowledge—such as hyponym/hypernym relations—significantly transfer to and improve learning of other types like synonym/antonym knowledge, suggesting opportunities for interference-aware training scheduling.
Introduction
Large language models (LLMs) are increasingly trained continuously on evolving data, yet how they learn, retain, and forget abstract concepts—such as "dog" or "justice"—remains poorly understood. This is critical because concept-level knowledge underpins reasoning, generalization, and robustness in downstream tasks. Prior work has focused on static probing of isolated facts or localized interpretability of individual components, but lacks a dynamic, system-level view of how concepts evolve and interact during continual training. The authors address this gap by introducing the FICO dataset—synthetic, ConceptNet-derived concepts with realistic relational structure—to enable controlled experiments. They leverage mechanistic interpretability to extract Concept Circuits, computational subgraphs tied to specific concepts, and use graph metrics to track their structural evolution. Their key findings reveal that concept circuits exhibit stage-wise temporal dynamics during training, with early growth followed by stabilization; stronger initial learning correlates with greater subsequent forgetting, indicating a trade-off between acquisition strength and retention; semantically similar concepts interfere more strongly, while certain knowledge types transfer efficiently to others. These insights provide a circuit-level framework for understanding concept learning dynamics and suggest actionable strategies for designing more stable, efficient, and interpretable continual pre-training pipelines.
Dataset

- The dataset, named FICO (Fictional COnccept), is built around 1,000 concepts—500 concrete ones from the THINGS dataset and 500 abstract ones from the Concreteness Ratings dataset—each linked to factual knowledge from ConceptNet, a large-scale knowledge graph with millions of concept relations.
- The original fine-grained relations in ConceptNet are grouped into five high-level knowledge types: Hyponym and Hypernym (taxonomic/definitional), Synonym and Antonym (similarity/contrast), Meronym and Holonym (part-whole), Property and Affordance (attributes and functions), and Spatial Relation (location-based). Relations in Causality & Event, Lexical/Etymological, and Other categories are filtered out to focus on stable, concept-centric knowledge.
- To reduce reliance on pre-existing knowledge in LLMs, each real concept name is replaced with a fictional name generated by GPT-5, while preserving the underlying conceptual knowledge. This ensures models learn semantic relations rather than memorizing real-world terms.
- For training, each knowledge triple is converted into multiple prefix-target examples using natural language templates generated by GPT-5 (e.g., “{concept} has the ability to” for CapableOf), resulting in 92,250 training samples from 3,075 triples—totaling 1.04M tokens. The model is trained for 10 epochs, amounting to 10.4M total training tokens.
- For evaluation, a disjoint set of 500 concepts and a separate pool of templates are used to generate 13,530 test tokens from 1,586 knowledge triples, enabling assessment of generalization to novel surface forms and underlying relational understanding.
Method
The authors leverage a framework that models a pretrained large language model (LLM) as a directed acyclic graph (DAG), where nodes represent computational components such as neurons, attention heads, and embeddings, and edges denote their interactions through operations like residual connections and linear projections. Within this framework, a concept circuit is defined as the minimal computational subgraph capable of faithfully predicting the target object of a knowledge triple conditioned on a textual prefix derived from the subject–relation pair. For concept-level analysis, the authors define a concept circuit as the subgraph responsible for predicting all knowledge triples associated with a given concept, thereby serving as an internal representation of that concept within the model’s parametric memory.
To identify these concept circuits at various checkpoints during continual training, the authors employ EAP-IG, a method that assigns importance scores to edges while balancing computational efficiency with attribution faithfulness. The circuit is constructed by selecting the top-scoring edges such that the resulting subgraph retains at least 70% of the full model’s performance on the associated concept. 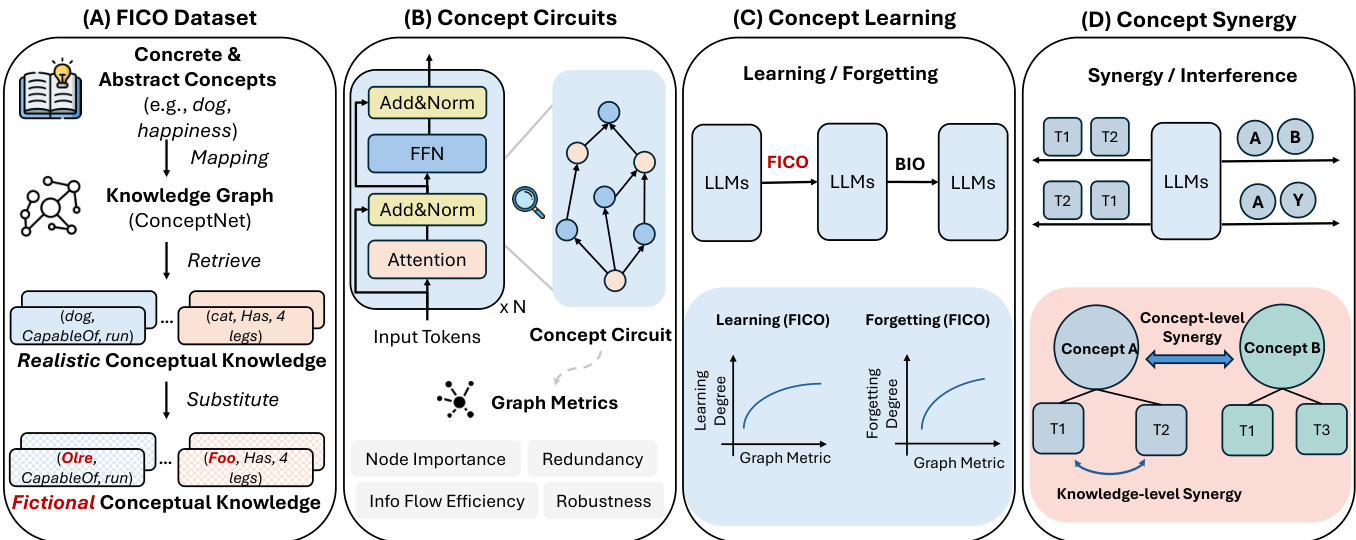
The structural properties of these concept circuits are quantified using four families of graph-theoretic metrics. Node importance is measured by the standard deviation of eigenvector centrality, reflecting the uneven distribution of structural influence across nodes; higher variance suggests a more hub-concentrated structure. Redundancy is assessed via graph density, the ratio of existing edges to the maximum possible, with higher values indicating more redundant connections. Information flow efficiency is captured by global efficiency, defined as the average inverse shortest-path distance between node pairs, where higher values imply more efficient signal propagation. Robustness is proxied by the average k-core number, which measures the depth of the densely connected core and indicates resilience to disruption.
The experimental design involves a two-stage continual pre-training process. In Stage 1 (Concept Acquisition), a pre-trained LLM π0 is trained on the FICO dataset to acquire novel concepts, resulting in model π1. In Stage 2 (Forgetting Induction), π1 is further trained on the BIO dataset to induce forgetting, producing model π2. The authors analyze concept learning and forgetting dynamics by comparing π0 and π1 for learning, and π1 and π2 for forgetting. Knowledge learning and forgetting degrees are defined at the knowledge-triple level as the change in logit assigned to the target object after training, and concept-level degrees are computed as the average across all associated triples. The analysis is conducted on two open-source LLMs: GPT-2 Large and LLaMA-3.2-1B-Instruct. For evaluation, only the textual prefix is provided, and the model is tasked with generating the target phrase on the FICO test set. Spearman’s correlation coefficient is used to assess the relationship between concept learning/forgetting dynamics and the topology of concept circuits.
Experiment
- Concept learning and forgetting degrees vary significantly across 500 concepts on the FICO dataset, with unimodal but widely spread distributions, indicating differing acquisition and retention strengths under the same training regime.
- Strong Spearman correlations (p < 0.001) link concept learning/forgetting degrees to circuit graph metrics: higher eigenvector centrality, k-core, density, and global efficiency enhance learning but also increase forgetting, revealing a structural trade-off between learning strength and stability.
- During continual training, concept circuits exhibit a stage-wise temporal pattern—initial increase in graph metrics followed by gradual decrease and stabilization—indicating systematic reorganization rather than simple decay.
- Concepts with higher learning degrees show correspondingly higher forgetting degrees, suggesting that aggressively acquired knowledge is more vulnerable to interference, particularly in highly integrated circuits with hub-dominated structures.
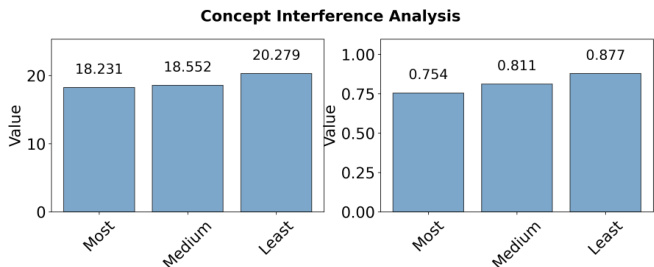
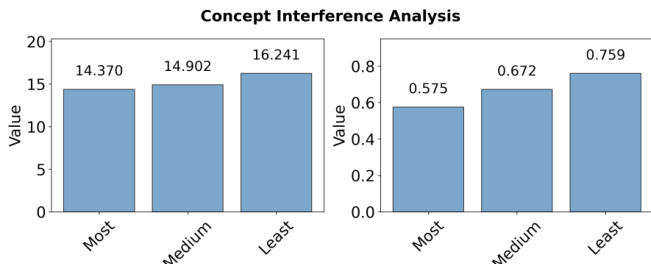
- Joint training with highly related concepts leads to significantly lower performance (57.5% average logit) compared to weakly related (75.9%) or moderately related (67.2%) concepts, due to increased circuit overlap and representational competition, as shown by higher Jaccard similarity in edge sets.
- Cross-knowledge-type training reveals asymmetric and substantial transfer effects: pretraining on Property & Affordance (PAA) boosts learning of Hyponym & Hypernym (HAH) and Synonym & Antonym (SAA), while reverse directions show weak transfer, indicating that knowledge type ordering can be leveraged to induce synergy and improve learning efficiency.
The authors use a concept interference analysis to examine how semantic relatedness affects concept learning during joint training. Results show that training with highly related concepts leads to lower performance (average logit: 14.370, average probability: 0.575) compared to training with weakly related concepts (average logit: 16.241, average probability: 0.759), indicating stronger interference among semantically similar concepts.
The authors use a pairwise continual-training setup to examine transfer effects between five high-level knowledge categories, measuring paired transferability as the performance gain or loss when transitioning from a source to a target knowledge type. Results show substantial and asymmetric transfer effects, with pretraining on Property & Affordance (PAA) yielding strong gains for Hyponym & Hypernym (HAH) and Synonym & Antonym (SAA), while reverse directions show weaker transfer, indicating directional and uneven benefits across knowledge types.
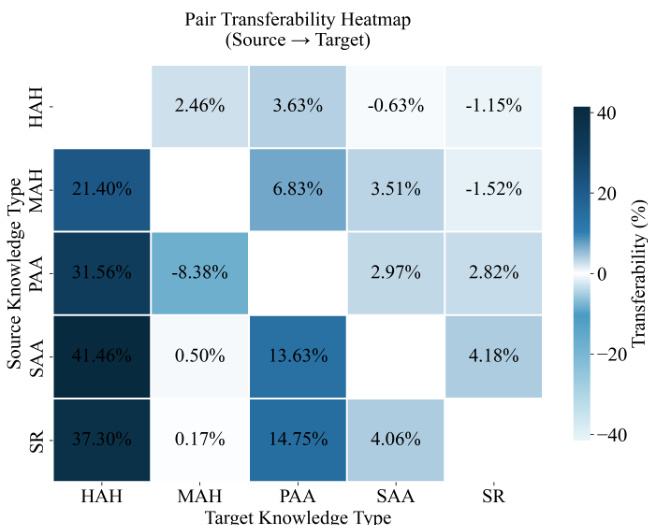
The authors use a heatmap to visualize paired transferability between five high-level knowledge types during continual training, showing that pretraining on one type can facilitate or hinder learning of another. Results indicate substantial and asymmetric transfer effects, with certain source-target pairs exhibiting strong positive transferability, such as from Property & Affordance to Hyponym & Hypernym, while others show minimal or negative effects, highlighting directional dependencies in knowledge acquisition.
The authors use scatter plots to examine the correlation between concept learning degree and forgetting degree across multiple circuit graph metrics. Results show a consistent positive correlation between learning and forgetting degrees, with statistically significant Spearman correlations observed for metrics such as density, k-core mean, eigenvector centrality standard deviation, and global efficiency, indicating that concepts learned more strongly tend to be more vulnerable to forgetting.
The authors use the provided bar charts to analyze concept interference during joint training, showing that training with highly related concepts results in lower performance compared to weakly related concepts. The left chart indicates that average logit values are highest when training with least related concepts, while the right chart shows that average probability is also highest in the least related condition, confirming that semantic relatedness negatively impacts concept acquisition.