Command Palette
Search for a command to run...
MMFormalizer : Autoformalisation multimodale dans le wild
MMFormalizer : Autoformalisation multimodale dans le wild
Résumé
L’autoformalisation, qui consiste à traduire les énoncés mathématiques en langage naturel en énoncés formels afin de permettre le raisonnement automatique, fait face à des défis fondamentaux dans des environnements réels en raison de la nature multimodale du monde physique, où la physique exige d’inférer des contraintes cachées (par exemple, la masse ou l’énergie) à partir d’éléments visuels. Pour relever ce défi, nous proposons MMFormalizer, une méthode qui étend l’autoformalisation au-delà du texte en intégrant un ancrage adaptatif avec des entités provenant de domaines mathématiques et physiques du monde réel. MMFormalizer construit de manière récursive des propositions formelles à partir de primitives ancrées perceptuellement, via un processus d’ancrage récursif et de composition d’axiomes, avec une terminaison récursive adaptative garantissant que chaque abstraction est soutenue par des preuves visuelles et ancrée dans un cadre dimensionnel ou axiomatique. Nous évaluons MMFormalizer sur une nouvelle base d’évaluation, PhyX-AF, composée de 115 échantillons soigneusement sélectionnés provenant de MathVerse, PhyX, Geometry Synthétique et Géométrie Analytique, couvrant une large variété de tâches d’autoformalisation multimodale. Les résultats montrent que des modèles de pointe tels que GPT-5 et Gemini-3-Pro atteignent les meilleures performances en termes de précision de compilation et de précision sémantique, avec GPT-5 se distinguant particulièrement dans le raisonnement physique, tandis que la géométrie reste le domaine le plus difficile. Globalement, MMFormalizer offre un cadre évolutif pour une autoformalisation multimodale unifiée, reliant perception et raisonnement formel. À notre connaissance, il s’agit de la première méthode d’autoformalisation multimodale capable de traiter la mécanique classique (dérivée du formalisme hamiltonien), ainsi que la relativité, la mécanique quantique et la thermodynamique. Pour plus de détails, rendez-vous sur notre page de projet : MMFormalizer.github.io
One-sentence Summary
The authors, from The University of Hong Kong, University of Michigan, University of Edinburgh, University of California, Santa Barbara, Ohio State University, and University of California, Los Angeles, propose MMFORMALIZER—a novel multimodal autoformalization framework that integrates adaptive grounding with perceptual primitives to recursively construct formally grounded mathematical and physical propositions, enabling machine reasoning across domains including classical mechanics, relativity, quantum mechanics, and thermodynamics, with demonstrated scalability on the PHYX-AF benchmark.
Key Contributions
-
We introduce MMFORMALIZER, a multimodal autoformalization framework that recursively grounds visual and textual inputs in physical and mathematical axioms, using dimensional analysis and adaptive termination to ensure every formal proposition is anchored in measurable reality and supported by perceptual evidence.
-
The framework enables the formalization of complex physical theories—including classical mechanics (via Hamiltonian derivation), relativity, quantum mechanics, and thermodynamics—making it the first method capable of unified multimodal reasoning across these domains.
-
We present PHYX-AF, a new benchmark with 115 diverse samples from MathVerse, PhyX, Synthetic Geometry, and Analytic Geometry, designed to enforce genuine multimodal reasoning by minimizing redundancy between modalities, and demonstrate that frontier models like GPT-5 and Gemini-3-Pro achieve state-of-the-art compile and semantic accuracy.
Introduction
The authors address the challenge of translating real-world, multimodal inputs—such as diagrams, text, and physical scenes—into formally verifiable mathematical and physical statements, a critical step for enabling machine reasoning in complex domains. Prior work in autoformalization has largely focused on symbolic or textual inputs within geometry, relying on fixed formal languages that struggle to capture dimensional and physical constraints inherent in real-world phenomena. These systems often fail to ground abstract reasoning in measurable reality, especially when dealing with physics where quantities like mass, energy, and time require empirical and dimensional consistency. To overcome this, the authors introduce MMFORMALIZER, a recursive framework that integrates perceptual grounding with dimensional and axiomatic reasoning within the Lean theorem prover. It uses adaptive recursive termination to ensure each formal step is anchored in visual evidence and dimensionally consistent, enabling formalization of classical mechanics, relativity, quantum mechanics, and thermodynamics—domains previously inaccessible to multimodal autoformalization. The method is evaluated on PHYX-AF, a new benchmark designed to enforce genuine multimodal reasoning by minimizing redundancy between modalities, demonstrating that while large models like GPT-5 show strong performance, geometry and physical reasoning remain challenging.
Dataset

-
The PHYX-AF benchmark consists of 115 curated samples drawn from multiple sources: MATHVERSE (Zhang et al., 2024a), PHYX (Shen et al., 2025), SYNTHETIC GEOMETRY (Trinh et al., 2024), and an extended ANALYTIC GEOMETRY dataset. Additional synthetic data is generated using a rule-based computation engine (Hubert et al., 2025) and a symbolic deduction framework inspired by AlphaGeometry and GenesisGeo (Zhu et al., 2025).
-
The dataset is divided into distinct subsets:
- Multimodal Mathematical Setup: Primarily sourced from MATHVERSE, covering Plane Geometry, Solid Geometry, and Function categories. These problems are drawn from real-exam contexts and emphasize proof-based reasoning and solving multivariate/higher-order equations from function graphs.
- Analytic Geometry: Includes problems from GEOMETRY3K (Lu et al., 2021) and GEOINT (Wei et al., 2025), augmented with procedurally generated 2D and 3D figures composed of points, lines, planes, and polyhedra. This subset tests understanding of coordinate-based geometric and numerical relationships.
- Multimodal Physical Setup: Derived from the PHYX subset (21.7% of the dataset), featuring visual scenes from mechanics, electromagnetism, thermodynamics, and relativity. Each problem pairs an image with a textual constraint, assessing visual-physical grounding under perceptual noise.
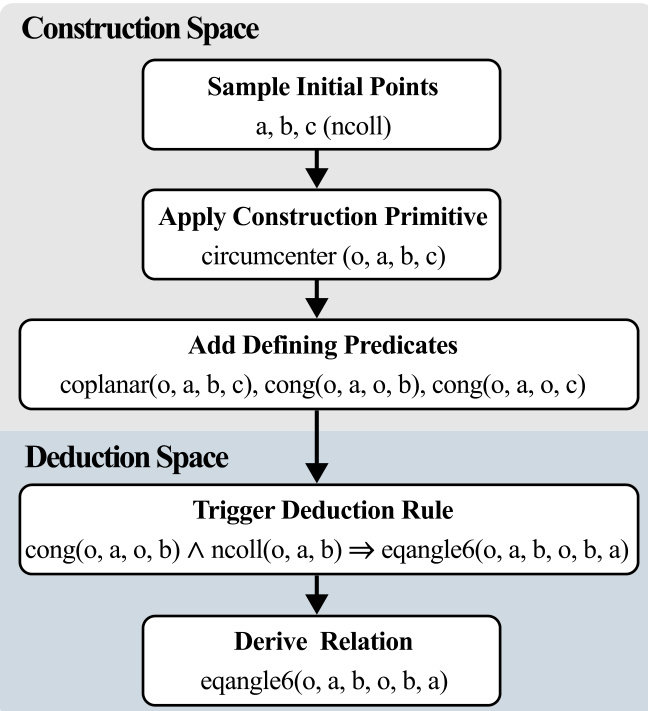
- Synthetic Geometry Setup: Entirely generated via a symbolic pipeline that constructs geometric configurations using a bounded sequence of declarative operators (e.g., point, line, circle, incidence, perpendicularity). These configurations are validated through symbolic deduction closure and numerical verification.
-
Data filtering ensures only problems where diagrams are essential for solution are retained—text-only solvable problems are excluded to enforce genuine multimodal reasoning.
-
The synthetic geometry pipeline follows a four-stage process:
- Synthetic Construction: Geometric configurations are built using a finite sequence of construction operators, bounded in length and object count to ensure well-defined, non-degenerate setups. Invalid constructions (e.g., intersecting parallel lines) are discarded.
- Symbolic Deduction Closure: Forward chaining deduces all derivable geometric statements from the construction, producing a full derivation graph that records dependency relations.
- Minimal Dependency Extraction: A derived statement is selected as the goal, and a minimal premise set is extracted by traversing the derivation graph backward. This ensures only necessary facts are included, preserving derivational sufficiency.
- Numerical Verification: Each instance is instantiated with concrete real-number coordinates. Geometric predicates (equality, incidence, perpendicularity, etc.) are checked under a fixed numerical tolerance. Failed or unstable instances are discarded.
-
The final dataset is used for training and evaluation with a mixture of in-distribution (MATHVERSE, PHYX) and out-of-distribution (synthetic, analytic geometry) samples. The model is trained to perform autoformalization across these domains, with synthetic data specifically designed to test the model’s ability to synthesize new dependent types and constructors at test time.
-
Metadata is constructed through structured symbolic representations, including derivation graphs and premise-goal dependencies, enabling precise evaluation of logical correctness and semantic fidelity. All synthetic instances are reproducible given a fixed random seed.
Method
The authors leverage a multimodal autoformalization framework, implemented through the MMFORMALIZER model, to synthesize formal, type-theoretic representations from perceptual inputs such as images and text. The overall architecture operates in three primary inductive stages: recursive grounding, recursive termination, and axiom composition, forming a hierarchical pipeline that maps visual and textual data into a formally consistent propositional chain. The process begins with the decomposition of an input image into a scene graph, which encodes primitive visual entities and their spatial relations. This scene graph serves as the foundation for recursively constructing a dependent hierarchy of formal propositions, referred to as a PropChain, where each proposition is grounded in perceptual data.
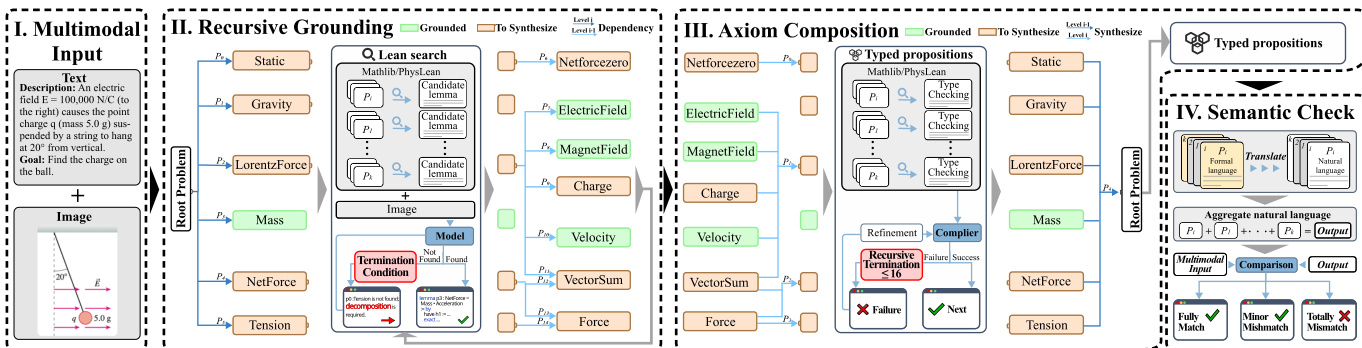
As shown in the figure below, the pipeline overview consists of three stages: Recursive Grounding, identifying physical primitives (the red parts in the figure, e.g., the Hamiltonian or dimensional quantities) for Termination, and Axiom Composition. The blue parts in the figure indicate the compiler checking process. The green part indicates the formal statements we retrieved from the dependency library.
The recursive grounding process, denoted as RG, incrementally constructs a PropChain by mapping perceptual scene structures to formal propositions. This is achieved through a recursive decomposition of the scene graph into a hierarchy of lemmas, where each lemma is a dependent pair of a formal proposition and its proof term. The grounding process is initiated by parsing the input image into a base-level scene graph, G0, which consists of a list of visual primitives—such as points, lines, or regions—and their spatial relations. Each primitive is assigned an initial semantic hypothesis, forming the base layer of the propositional structure. The grounding is inductively extended by mapping each visual element to a formal statement, using a combination of semantic search and large language model (LLM) prompting to retrieve and select the most relevant theorems from a formal library.

The recursive termination phase ensures that the formal abstraction is both supported by perceptual grounding and capable of constraining subsequent parsing. The recursion terminates when a proposition is grounded either in a primitive dimensional quantity or a fundamental axiom. This termination condition is determined by a mapping function that evaluates whether the current proposition corresponds to a physical dimension or an axiom within the formal system. The process is implemented through two major phases: grounding, where intermediate lemma statements are used to search for relevant theorems in a formal library, and termination, where the recursion stops upon reaching a primitive or axiom.
The final stage, axiom composition, constructs the AxiomChain, which represents the formal closure of the propositional hierarchy. This is achieved by recursively combining child nodes into non-leaf nodes using a composition operator, which captures the transition from perceptual substructures to hierarchically dependent propositions. The resulting formal statements are passed through a syntax checker for compilation verification, ensuring their structural and logical validity within the LEAN system. This process enables the construction of formal models that faithfully reflect the generative structure of physical and conceptual reality, where primitives combine to form law-constrained, formal systems.
Experiment
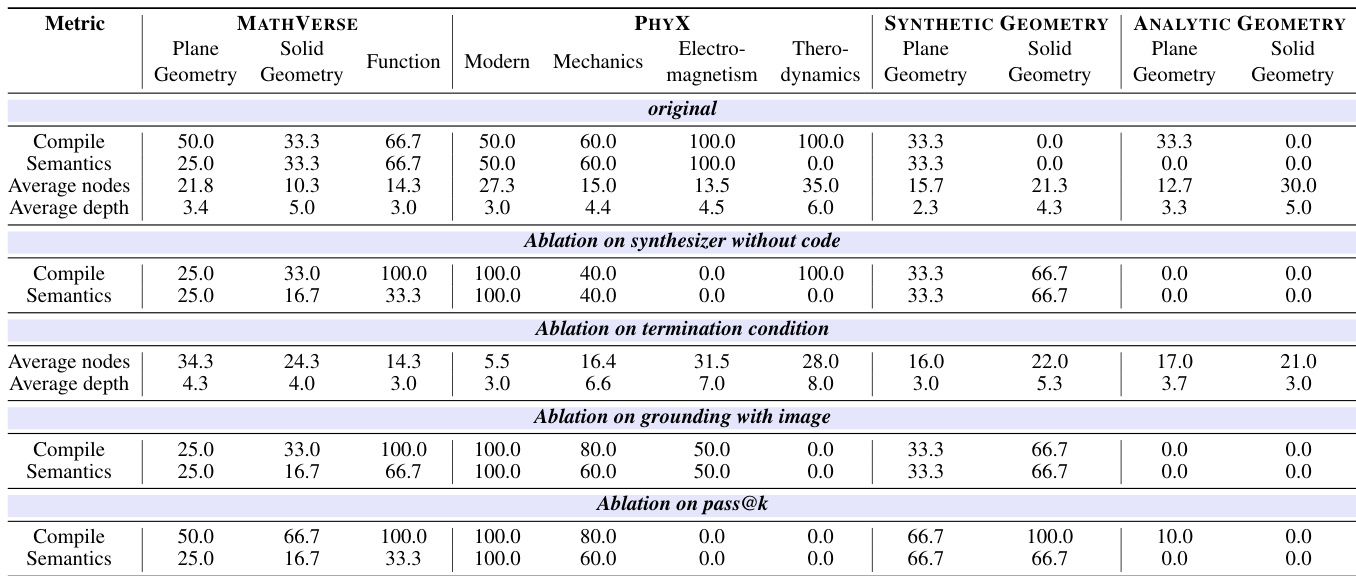
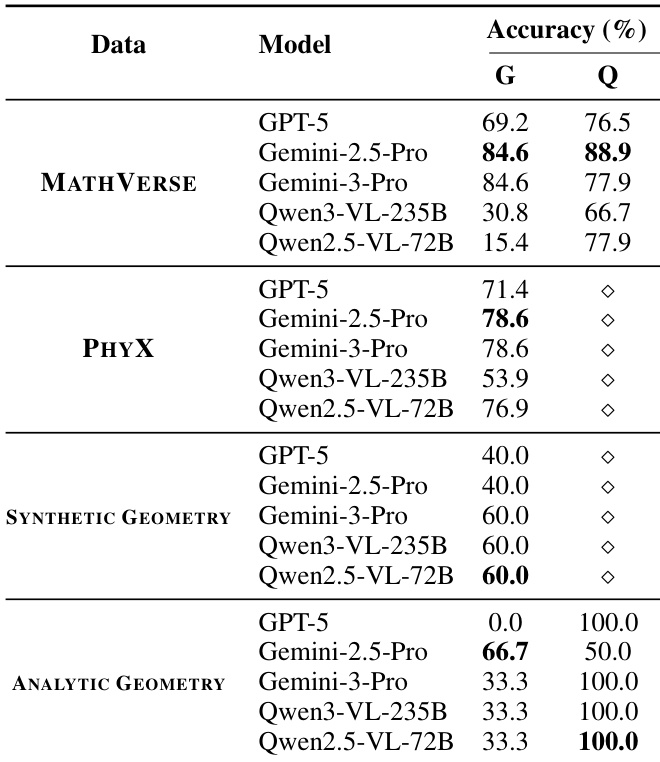
- Gemini-3-Pro achieves the highest compile and semantic accuracy on MATHVERSE and ANALYTIC GEOMETRY, while GPT-5 excels on PHYX, particularly in the MODERN category (quantum mechanics and relativity), demonstrating superior physical reasoning and grounding.
- All models show significantly lower accuracy on SYNTHETIC GEOMETRY and ANALYTIC GEOMETRY, indicating persistent challenges in visual-to-formal reasoning and generalization beyond training distributions.
- Qwen3-VL-235B, the strongest open-source model, performs poorly on physical domain problems and out-of-distribution synthetic geometry tasks, highlighting a performance gap compared to frontier models.
- Ablation studies show that removing retrieved reference code improves out-of-distribution generalization in synthetic geometry, explicit recursion termination prevents infinite decomposition, grounding with images boosts performance in modern physics and synthetic geometry, and increasing pass@k enhances results on difficult problems.
- In semantic checking, Gemini-2.5-Pro achieves the highest accuracy across MATHVERSE, PHYX, and ANALYTIC GEOMETRY; Qwen2.5-VL-72B performs on par with Gemini-3-Pro when verifying code from Qwen3-VL-235B, revealing the potential of weak models supervising strong ones.
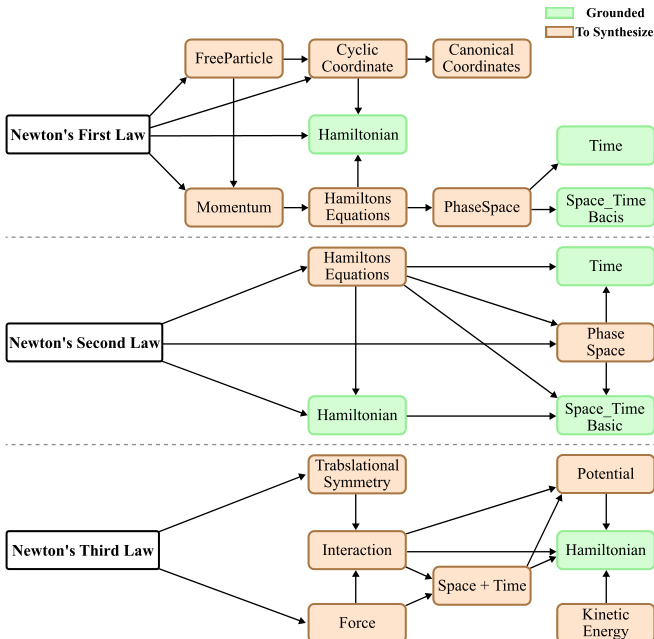
- Case studies validate the framework’s ability to construct verifiable dependency graphs and perform logical grounding in Lean for complex problems, including geometric solids, Newton’s laws, quantum tunneling, and relativistic velocity addition, with failure cases underscoring the necessity of termination conditions.
Results show that GPT-5 achieves the highest compile and semantic accuracy across most benchmarks, particularly excelling in the PHYX dataset, while Gemini-3-Pro performs best on MATHVERSE and ANALYTIC GEOMETRY. All models struggle with synthetic and analytic geometry tasks, indicating persistent challenges in visual and formal reasoning, and open-source models like Qwen3-VL-235B show significant performance gaps compared to frontier models.
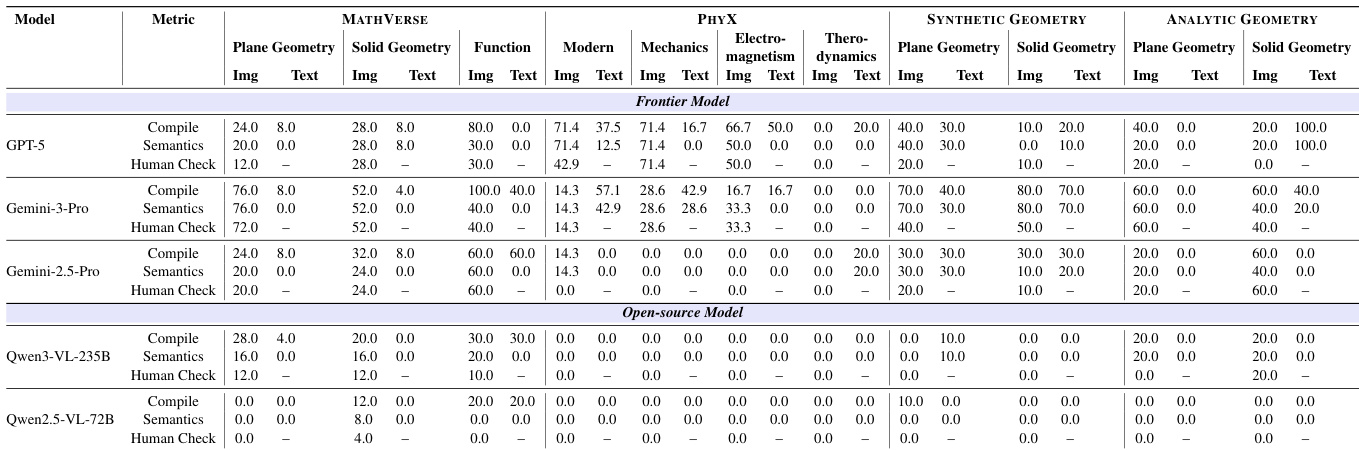
The authors use the provided bar chart to illustrate the distribution of problems across different domains and subdomains within the evaluation benchmarks. Results show that MATHVERSE accounts for the majority of the dataset at 52.2%, with the largest portion being Plan Geometry. PHYX contributes 21.7% of the total, primarily composed of Mechanics and Solid Geometry. Synthetic Geometry and Analytic Geometry make up the remaining 17.4% and 8.7% respectively, with the former dominated by Plane Geometry and the latter by Plan Geometry as well.
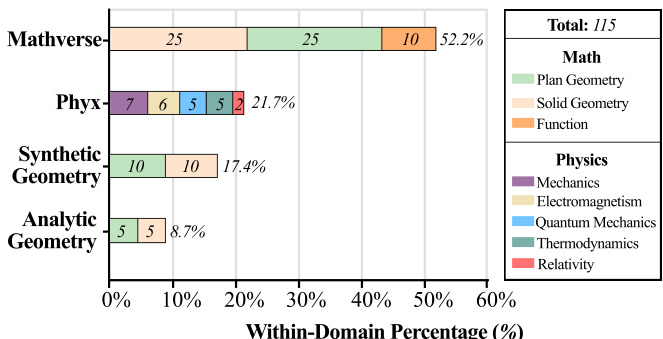
Results show that Gemini-3-Pro achieves the highest accuracy on MATHVERSE and ANALYTIC GEOMETRY, while GPT-5 performs best on PHYX and SYNTHETIC GEOMETRY. All models exhibit significantly lower performance on synthetic geometry tasks, indicating persistent challenges in visual and formal reasoning.
Results show that the original model configuration achieves the highest compile and semantic accuracy across most benchmarks, particularly excelling in the PHYX and MATHVERSE datasets. Ablation studies reveal that removing retrieved code improves out-of-distribution generalization, while enforcing a termination condition prevents recursive over-decomposition, and grounding with images enhances performance in challenging physics and geometry tasks. Increasing pass@k improves semantic accuracy on difficult problems, indicating the effectiveness of test-time scaling.