Command Palette
Search for a command to run...
DreamStyle : Un cadre unifié pour la stylisation vidéo
DreamStyle : Un cadre unifié pour la stylisation vidéo
Mengtian Li Jinshu Chen Songtao Zhao Wanquan Feng Pengqi Tu Qian He
Résumé
La stylisation vidéo, une tâche importante en aval des modèles de génération vidéo, n’a pas encore été pleinement explorée. Les conditions de style d’entrée courantes incluent le texte, l’image de style et la première image stylisée. Chaque condition présente un avantage spécifique : le texte offre une plus grande flexibilité, l’image de style fournit un ancrage visuel plus précis, tandis que la première image stylisée permet la stylisation de vidéos longues. Toutefois, les méthodes existantes sont principalement limitées à un seul type de condition de style, ce qui restreint leur champ d’application. Par ailleurs, leur manque de jeux de données de haute qualité entraîne une incohérence stylistique et un clignotement temporel. Pour surmonter ces limitations, nous introduisons DreamStyle, un cadre unifié pour la stylisation vidéo, prenant en charge (1) la stylisation guidée par le texte, (2) la stylisation guidée par l’image de style, et (3) la stylisation guidée par la première image, accompagnée d’un pipeline soigneusement conçu pour la curatation de données vidéo appariées de haute qualité. DreamStyle est basé sur un modèle Image-to-Video (I2V) de base et entraîné à l’aide d’une adaptation par rang faible (LoRA) munie de matrices d’augmentation spécifiques aux jetons, réduisant ainsi la confusion entre les différents jetons de condition. Des évaluations qualitatives et quantitatives démontrent que DreamStyle est performant dans les trois tâches de stylisation vidéo et surpasser les méthodes concurrentes en termes de cohérence stylistique et de qualité vidéo.
One-sentence Summary
The authors from ByteDance's Intelligent Creation Lab propose DreamStyle, a unified video stylization framework supporting text-, style-image-, and first-frame-guided generation via a LoRA-enhanced I2V model with token-specific up matrices, enabling consistent, high-quality stylization across diverse conditions and overcoming prior limitations in flexibility and temporal coherence.
Key Contributions
- Video stylization has been limited by reliance on single-style conditions (text, style image, or first frame), restricting flexibility and generalization; DreamStyle introduces a unified framework that seamlessly supports all three modalities within a single model, enabling versatile and controllable stylization.
- To overcome the lack of high-quality training data, DreamStyle employs a systematic data curation pipeline that generates paired stylized videos by first stylizing the initial frame and then propagating the style through an I2V model with ControlNets, combined with hybrid automatic and manual filtering for high fidelity.
- The framework leverages a modified LoRA with token-specific up matrices to reduce interference between different condition tokens, achieving superior style consistency and video quality compared to specialized baselines, while enabling advanced applications like multi-style fusion and long-video stylization.
Introduction
Video stylization is a key task in visual content generation, enabling the transformation of real-world videos into artistic or stylistic outputs while preserving motion and structure. Prior methods are largely limited to single-style conditions—either text prompts or style images—each with trade-offs in flexibility, accuracy, and usability. Moreover, the absence of high-quality, modality-aligned training data leads to poor style consistency and temporal flickering. Existing approaches also struggle with extended applications like multi-style fusion and long-video stylization due to rigid architectures and lack of unified frameworks.
The authors introduce DreamStyle, a unified video stylization framework built on a vanilla Image-to-Video (I2V) model that supports three style conditions—text, style image, and stylized first frame—within a single architecture. To enable effective multi-condition handling, they design a token-specific LoRA module with shared down and condition-specific up matrices, reducing interference between different style tokens. A key innovation is a scalable data curation pipeline that generates high-quality paired video data by first stylizing the initial frame using image stylization models and then propagating the style through an I2V model with ControlNets, followed by hybrid (automatic and manual) filtering. This pipeline addresses the scarcity of training data and improves both style fidelity and temporal coherence.
DreamStyle achieves state-of-the-art performance across all three stylization tasks, outperforming specialized models in style consistency and video quality, while enabling new capabilities such as multi-style fusion and long-video stylization through unified condition injection.
Dataset

- The dataset consists of 40K stylized-raw video pairs for Continual Training (CT) and 5K pairs for Supervised Fine-Tuning (SFT), each with a resolution of 480P and up to 81 frames.
- The raw videos are sourced from existing video collections, and stylized videos are generated in two stages: first, the initial frame is stylized using either InstantStyle (style-image-guided) or Seedream 4.0 (text-guided); second, an in-house I2V model generates the full video from the stylized first frame.
- For CT, the dataset uses InstantStyle to produce a large-scale, diverse set focused on general video stylization capability, with one style reference image per sample. For SFT, Seedream 4.0 generates a smaller, higher-quality set with 1 to 16 style reference images per sample, where only one is used during training.
- To ensure motion consistency between raw and stylized videos, the same control conditions—depth and human pose—are applied to drive both video generations, avoiding motion mismatches caused by imperfect control signal extraction.
- Metadata is constructed using a Visual-Language Model (VLM) to generate two text prompts per video: one excluding style attributes (t_ns) and one including them (t_sty), enabling style-irrelevant and style-aware conditioning.
- Style reference images (s_i^1..K) are generated using the same guidance as the stylized video, with the CT dataset filtered for style consistency using VLM and CSD scores, while the SFT dataset undergoes manual filtering and content consistency verification.
- During training, the three style conditions—text-guided, style-image-guided, and first-frame-guided—are sampled in a 1:2:1 ratio, and the model is trained with LoRA (rank 64) using AdamW optimizer, a learning rate of 4×10⁻⁵, and a total of 6,000 (CT) and 3,000 (SFT) iterations.
- A 2-step gradient accumulation strategy is used to achieve an effective batch size of 16, with training conducted on NVIDIA GPUs and a per-GPU batch size of 1.
Method
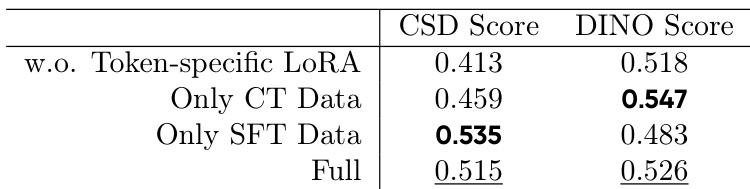
The authors leverage the Wan14B-I2V [48] base model as the foundation for the DreamStyle framework, which is designed to support three distinct style conditions: text, style image, and first frame. The framework's architecture is built upon the base model's structure, with modifications to the input conditioning mechanism to enable the injection of raw video and additional style guidance. As shown in the figure below, the model processes multiple input modalities, including the raw video, a stylized first frame, a style reference image, and a text prompt. These inputs are encoded into latent representations using a VAE encoder, with the raw video and stylized first frame being processed into video latents, and the style image being encoded into a style latent. The text prompt is processed by a text encoder, and the style image's high-level semantics are further enhanced by a CLIP image feature branch. 
The input latents are then prepared for the model by incorporating noise and mask tensors. For the raw video condition, the encoded raw video latent zraw and the stylized video latent zsty are concatenated with a mask tensor 04×F×H×W, where the mask value of 0.0 is used to indicate the absence of a condition. For the style-image condition, the VAE-encoded style reference image latent zs is combined with a noise-injected version of itself and a mask tensor 14×1×H×W, which is filled with 1.0 to signify the presence of the style condition. The first-frame condition is similarly handled by feeding the stylized first frame into the image condition channels with a mask of 1.0. These conditioned latents are then transformed into token sequences after patchification, which are fed into the core model.
To address the challenge of inter-token confusion arising from the distinct semantic roles of the different condition tokens, the authors introduce a token-specific LoRA module. This modification is applied to the full attention and feedforward (FFN) layers of the model. As illustrated in the figure below, for an input token xin, a shared down matrix Wdowni projects the token, and the output residual token xout is computed using a specific up matrix Wupi that is selected based on the token type i. This design allows the model to learn adaptive features for each condition type while maintaining training stability through the large proportion of shared parameters. 
Experiment
- Text-guided video stylization: DreamStyle outperforms commercial models (Luma, Pixverse, Runway) and open-source baseline StyleMaster, achieving the highest CLIP-T and DINO scores, indicating superior style prompt following and structure preservation. On the test set, it surpasses competitors in style consistency (CSD) and dynamic degree, with overall quality scores of approximately 4 or higher in user study.
- Style-image-guided stylization: DreamStyle achieves the best CSD score and excels in handling complex styles involving geometric shapes, outperforming StyleMaster in both quantitative metrics and visual quality.
- First-frame-guided stylization: DreamStyle achieves optimal style consistency (CSD) and strong video quality, though slightly lower DINO scores due to occasional structural conflicts from stylized first frames; visual results confirm preservation of primary structural elements.
- Multi-style fusion: DreamStyle successfully integrates text prompts and style images during inference, enabling creative style fusion beyond single guidance.
- Long-video stylization: By chaining short video segments using the last frame as the next segment’s first frame, DreamStyle extends beyond the 5-second limit, enabling stylization of longer sequences with consistent style.
- Ablation studies: Token-specific LoRA significantly improves style consistency and reduces style degradation and confusion; training on both CT and SFT datasets in two stages achieves the best balance between style consistency and structure preservation.
Results show that DreamStyle outperforms all compared methods in text-guided video stylization, achieving the highest CLIP-T and DINO scores, indicating superior style prompt following and structure preservation. In style-image-guided and first-frame-guided tasks, DreamStyle achieves the best or second-best performance across most metrics, particularly excelling in style consistency while maintaining strong overall quality.
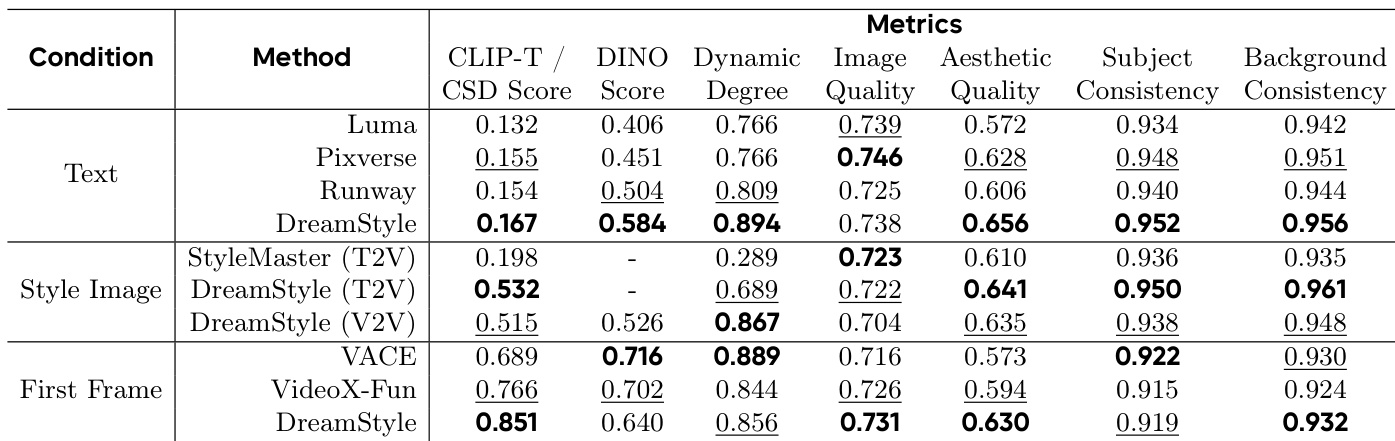
Results show that DreamStyle achieves the highest scores in style consistency, content consistency, and overall quality across all three video stylization tasks. In text-guided stylization, it outperforms Luma, Pixverse, and Runway, particularly in style consistency and content preservation. For style-image-guided and first-frame-guided tasks, DreamStyle also leads in style consistency and overall quality, demonstrating superior performance compared to StyleMaster, VACE, and VideoX-Fun.
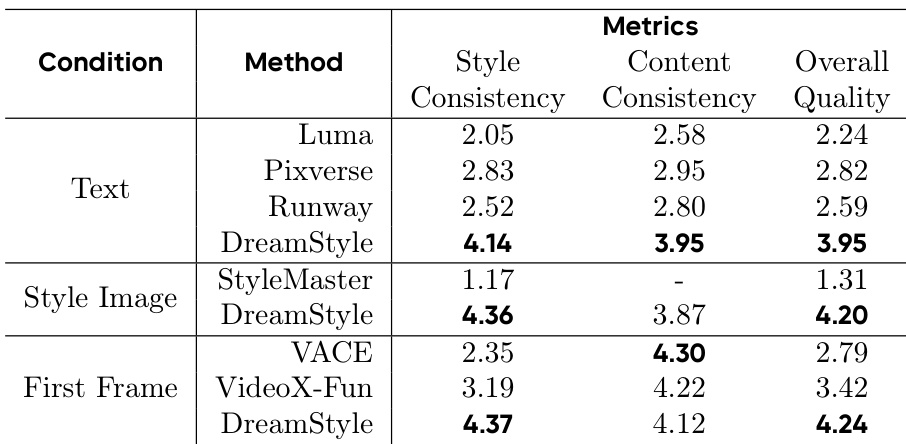
Results show that the token-specific LoRA significantly improves style consistency, with the full model achieving a CSD score of 0.515, outperforming the version without it (0.413). The full model also maintains strong structure preservation, scoring 0.526 on the DINO metric, while the ablation with only CT data achieves the highest CSD score but at the cost of structure preservation.