Command Palette
Search for a command to run...
ShowUI-π : Modèles génératifs basés sur les flux comme mains habiles GUI
ShowUI-π : Modèles génératifs basés sur les flux comme mains habiles GUI
Siyuan Hu Kevin Qinghong Lin Mike Zheng Shou
Résumé
La conception d’agents intelligents capables d’une manipulation habile est essentielle pour atteindre une automatisation similaire à celle de l’humain, tant en robotique qu’en environnements numériques. Toutefois, les agents existants basés sur une interface graphique utilisateur (GUI) s’appuient sur des prédictions discrètes de clics (x,y), ce qui empêche l’exécution de trajectoires continues et en boucle fermée (par exemple, le glissement d’une barre de progression), nécessitant une perception et une adaptation en temps réel. Dans ce travail, nous proposons ShowUI-π, le premier modèle génératif basé sur un flux (flow-based) conçu comme une main habile pour les GUI, intégrant les améliorations suivantes : (i) Actions discrètes-continues unifiées, qui intègrent les clics discrets et les glissements continus dans un même modèle, permettant une adaptation flexible à divers modes d’interaction ; (ii) Génération d’actions basée sur un flux pour le modèle de glissement, qui prédit des ajustements incrémentaux du curseur à partir d’observations visuelles continues via un expert d’action léger, assurant des trajectoires fluides et stables ; (iii) Données d’entraînement et benchmark pour le glissement, où nous avons collecté manuellement et synthétisé 20 000 trajectoires de glissement sur cinq domaines (ex. : PowerPoint, Adobe Premiere Pro), et introduisons ScreenDrag, un benchmark doté de protocoles d’évaluation complets (en ligne et hors ligne) pour évaluer les capacités de glissement des agents GUI. Nos expériences montrent que les agents GUI propriétaires peinent encore sur ScreenDrag (par exemple, Operator obtient 13,27, et le meilleur modèle Gemini-2.5-CUA atteint 22,18). En revanche, ShowUI-π atteint 26,98 avec seulement 450 millions de paramètres, soulignant à la fois la difficulté de la tâche et l’efficacité de notre approche. Nous espérons que ce travail contribuera à faire évoluer les agents GUI vers un contrôle habile, similaire à celui de l’humain, dans le monde numérique. Le code source est disponible à l’adresse suivante : https://github.com/showlab/showui-pi.
One-sentence Summary
The authors, affiliated with the National University of Singapore's Show Lab, propose ShowUI-π, a lightweight flow-based generative model that enables human-like dexterous GUI automation by jointly modeling discrete clicks and continuous dragging actions through incremental visual observation, outperforming prior agents on the new ScreenDrag benchmark with 26.98 score using only 450M parameters.
Key Contributions
- Existing GUI agents rely on discrete click predictions, which limits their ability to perform continuous, closed-loop interactions like dragging; ShowUI-π addresses this by introducing a unified framework that models both discrete clicks and continuous drags as sequences of (x, y, m) triplets within a single flow-based generative model.
- The model employs a lightweight action expert trained with flow matching to generate incremental cursor adjustments from streaming visual observations, enabling smooth and stable trajectory generation for complex tasks such as rotating captchas and precise resizing in professional software.
- To evaluate continuous GUI manipulation, the authors introduce ScreenDrag, a benchmark with 505 real-world drag tasks across five domains and 20K synthesized trajectories, demonstrating that ShowUI-π achieves 26.98 on the benchmark—outperforming proprietary agents like Gemini-2.5-CUA (22.18) despite its small 450M parameter size.
Introduction
The authors address the challenge of enabling GUI automation agents to perform continuous, dexterous interactions such as dragging, drawing, and rotating captchas—tasks requiring real-time visual feedback and fine-grained trajectory control. Prior work relies on discrete, tokenized action representations from vision-language models, which fail to capture the continuous nature of dragging and limit agents to coarse, stepwise actions. To overcome this, the authors propose ShowUI-π, the first flow-based generative model for GUI automation that treats both clicks and drags as continuous trajectories through a unified (x,y,m) action space. By leveraging flow matching on a lightweight transformer backbone, ShowUI-π generates smooth, on-the-fly cursor movements from streaming visual observations. The authors introduce ScreenDrag, a new benchmark with 505 real-world drag tasks across five domains and 20K dense trajectory annotations, supporting both offline error metrics and online success evaluation. Experiments show that ShowUI-π achieves state-of-the-art performance with only 450M parameters, significantly outperforming existing proprietary agents, demonstrating the effectiveness of continuous trajectory modeling for human-like GUI dexterity.
Dataset

- The dataset, ScreenDrag, consists of 20,000 drag trajectories across five domains: PowerPoint, OS Desktop and File Manager, Handwriting, Adobe Premiere Pro, and Captcha-solving, covering both everyday and professional-level tasks requiring precise spatial control.
- Data is collected using a scalable pipeline combining automated execution and human demonstrations. Automated data is generated via three stages: (i) element parsing using Windows UI Automation (UIA) or DOM for web-based tasks, (ii) instruction generation via Qwen-2.5-72B LLM, and (iii) trajectory synthesis using PyAutoGUI code executed on real systems.
- Human demonstrations are recorded at 60 FPS with high-resolution screen captures, dense cursor trajectories, and corresponding task instructions, ensuring rich temporal and spatial fidelity.
- For PowerPoint, templates are sourced from Microsoft’s official gallery, parsed via UIA, and used to generate tasks like rotation and resizing; rotation handle positions are estimated via heuristics.
- Handwriting data is synthesized using an open-source library, with text generated by Qwen-2.5-72B and strokes rendered via Win32 mouse interface for fine-grained control.
- Captcha tasks are collected using a modified Go-Captcha library that exposes real-time metadata (e.g., puzzle piece positions, success status), enabling filtering of only successfully solved trajectories.
- Adobe Premiere Pro data is collected via human expert demonstrations, as UI metadata is not fully accessible; two experienced annotators perform real-world editing tasks like trimming, layer adjustment, and effect application.
- OS Desktop and File Manager tasks are automated with files and folders created via modified Windows registry settings to disable auto-arrangement, increasing task complexity; UIA is used to extract bounding boxes for icons and controls.
- All data is recorded using OBS for low-latency screen capture, synchronized with high-frequency mouse event logging.
- The dataset includes a 20K-trajectory training set and a 505-trajectory benchmark (101 per domain) for evaluation, with average recording duration of 9.62 seconds and 577 frames per clip.
- For model training, ShowUI-π uses ScreenDrag’s training data alongside the desktop Click subset from GUIAct, WaveUI, UGround, and ShowUI-Desktop, excluding all non-Click and mobile data.
- No cropping is applied to screen recordings; instead, full-screen video and metadata are preserved. Metadata includes UI element locations, attributes, and real-time task status, enabling precise alignment with trajectories.
- The full data generation codebase and raw collected data (including PowerPoint templates) will be open-sourced to support reproducibility and community use.
Method
The authors leverage a unified flow-based generative model, ShowUI-π, to enable dexterous GUI manipulation by directly modeling continuous spatial trajectories. The framework is built upon the SmolVLA-450M architecture, integrating a pretrained vision-language model (VLM) with a lightweight action expert. The VLM processes multimodal inputs, encoding visual observations into a unified embedding space alongside projected action states and task instructions. This enables the model to maintain a coherent understanding of the environment and task context. The action expert, a transformer with the same number of layers as the VLM backbone, is responsible for generating action sequences. During inference, the VLM and action expert perform interleaved self-attention and cross-attention, allowing the action expert to condition its predictions on the current visual state and the history of actions. The action state from the previous step is projected back into the VLM backbone to inform subsequent predictions, enabling fine-grained, closed-loop control.
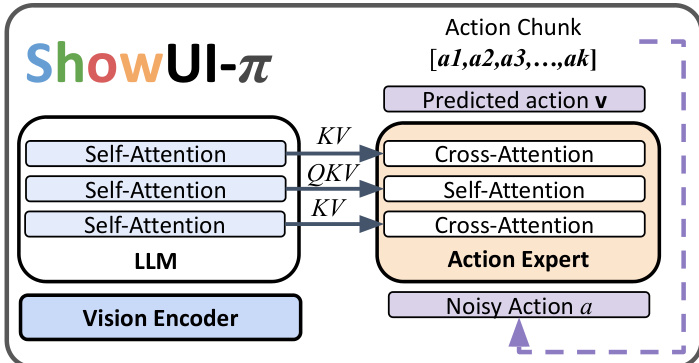
The model employs a unified action representation to seamlessly integrate discrete clicks and continuous drags. This is achieved by modeling all interactions as sequences of (x,y,m) triplets, where (x,y) are cursor coordinates and m is the mouse button state (down or up). A click is represented as a minimal two-step trajectory: [(x1,y1,down),(x1,y1,up)], while a drag is represented as an extended incremental press-hold trajectory: [(x1,y1,down),(x2,y2,down),…,(xT,yT,up)]. This unified representation simplifies the action space and allows the policy to naturally support flexible multi-dataset co-training.

For continuous trajectory generation, ShowUI-π adopts a flow-based incremental generation framework. The action expert predicts a time-conditioned velocity field vθ, which governs the smooth evolution of the predicted action trajectory a^(s) over a continuous parameter s∈[0,1]. This is formalized by the differential equation dsda^(s)=vθ(a^(s),s∣ot,Q), where ot is the current observation and Q is the task instruction. To ensure high-quality trajectories, the model uses a reweighted flow-matching loss that emphasizes the initial and terminal segments of the trajectory, assigning a weight of 10 to these critical steps compared to 1 for intermediate steps. This reweighting scheme ensures that the model accurately conditions on the start point and lands precisely on the intended endpoint.
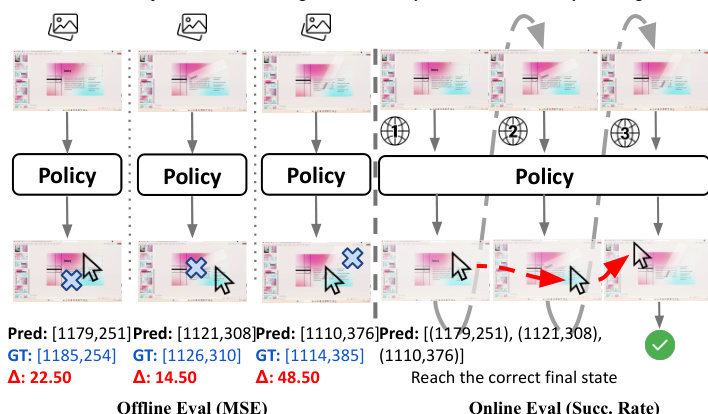
To further enhance trajectory quality, the model incorporates directional regularization. Standard flow-based methods optimize trajectory magnitude but do not explicitly enforce directional consistency, which can lead to jitter or incorrect cursor orientation. To address this, a directional regularization loss is introduced, defined as Lreg=T1∑t=1T(1−cos(a^t,ut)), where a^t and ut are the predicted and ground-truth action points, respectively. This loss term penalizes deviations in the direction of movement, promoting smooth and coherent trajectories. The final training objective combines the reweighted flow-matching loss and the directional regularization loss, with a balance parameter λ set to 0.1 to ensure comparable magnitudes of the loss terms.
Experiment
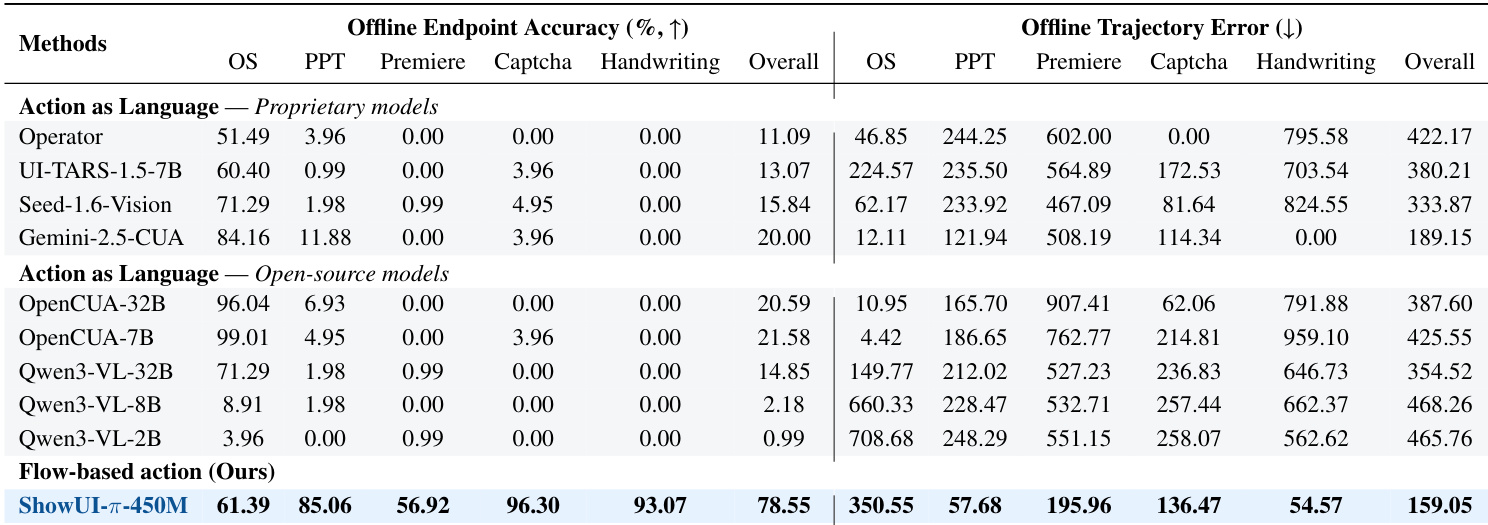
- Offline evaluation validates the model's stepwise trajectory accuracy using Average Trajectory Error (ATE) and Trajectory Endpoint Accuracy (TEA), with ShowUI-π achieving the lowest ATE of 159.05 px and highest TEA of 78.55%, outperforming diffusion policy and language modeling.
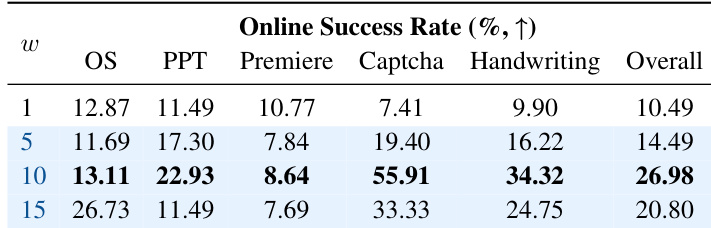
- Online evaluation validates real-world closed-loop performance via Task Success Rate, where ShowUI-π achieves 26.98% success, surpassing SOTA proprietary model Gemini-2.5-CUA by 4.8% and open-source model OpenCUA-7B by 6.19%.
- Ablation studies show that flow matching outperforms language modeling and diffusion policy in both offline and online settings, with directional regularization and reweighting significantly improving success, especially on Captcha and free-form drag tasks.
- Unified action head design matches separate heads in accuracy while reducing model size by 100M parameters and improving online drag success by 3.7%.
- Qualitative results demonstrate ShowUI-π generates smooth, human-like trajectories that precisely follow complex paths in PowerPoint rotation, handwriting, and Captcha-solving tasks.
- Evaluation on public benchmarks (VideoGUI-Action) shows ShowUI-π achieves competitive drag performance despite training on continuous observations, indicating strong generalization despite domain shift.
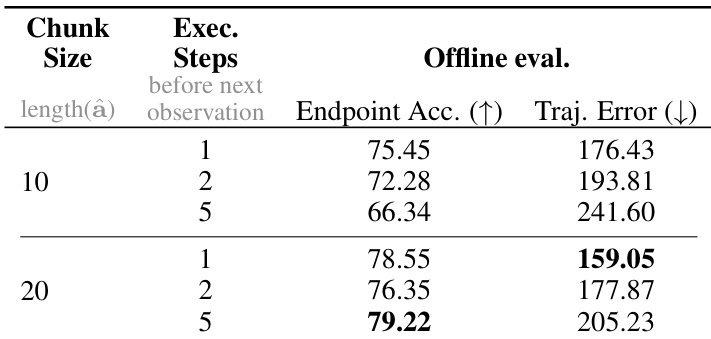
Results show that increasing the chunk size from 10 to 20 improves endpoint accuracy and reduces trajectory error, with the best performance achieved at a chunk size of 20 and one execution step, indicating that longer action predictions and frequent re-observations enhance precision.
Results show that the online success rate varies significantly with the temporal weighting scale w, where a scale of 10 achieves the highest overall success rate of 26.98%, outperforming other scales across multiple domains, particularly in Captcha tasks. The performance peaks at w=10, indicating that moderate reweighting optimally balances accuracy at critical steps, while higher scales like 15 degrade overall performance due to overemphasis on specific steps.
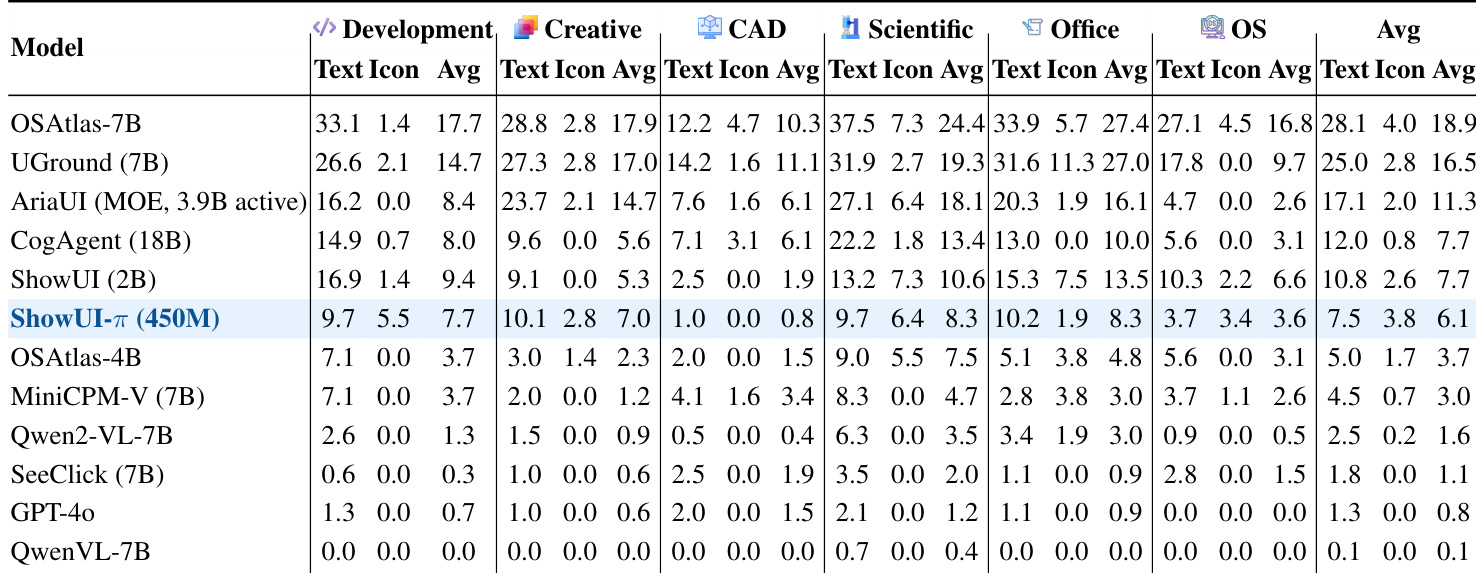
The authors use a data-driven approach to evaluate ShowUI-π on the ScreenSpot-Pro benchmark, comparing performance across different training data recipes. Results show that co-training with both drag and grounding data significantly improves performance, achieving the highest scores in all categories, particularly in Creative and Office domains, where the model benefits from the abundance of relevant data in the ScreenDrag dataset.

The authors use a data-driven approach to enable closed-loop rollouts in online evaluation, where the model's predicted actions are matched to recorded states within a tolerance to retrieve the next observation, allowing continuous interaction without requiring full OS setup. Results show that ShowUI-π achieves the highest average task success rate of 6.1% across all domains, outperforming all baseline models, with particularly strong performance in Creative and Office tasks, while also demonstrating robustness in handling diverse drag actions such as free-form rotations and handwriting.
Results show that ShowUI-π-450M achieves the highest offline endpoint accuracy across all domains, particularly excelling in Captcha and Handwriting tasks, while also demonstrating the lowest offline trajectory error compared to all baseline models. The authors use this table to highlight that their flow-based action modeling approach outperforms language-based and diffusion-based methods in both endpoint precision and trajectory smoothness.