Command Palette
Search for a command to run...
Laissez-fluivre : l’élaboration agente du rock and roll, construction du modèle ROME au sein d’un écosystème d’apprentissage agent ouvert
Laissez-fluivre : l’élaboration agente du rock and roll, construction du modèle ROME au sein d’un écosystème d’apprentissage agent ouvert
Résumé
L’élaboration agente exige que les modèles de langage à grande échelle (LLM) opèrent dans des environnements du monde réel sur plusieurs tours, en effectuant des actions, en observant les résultats et en affinant itérativement les artefacts. Malgré son importance, la communauté open source manque d’un écosystème structuré et end-to-end pour simplifier le développement d’agents. Nous introduisons l’Agentic Learning Ecosystem (ALE), une infrastructure fondamentale qui optimise le pipeline de production des LLM agents. L’ALE se compose de trois composants : ROLL, un cadre post-entraînement pour l’optimisation des poids ; ROCK, un gestionnaire d’environnement de sandbox pour la génération de trajectoires ; et iFlow CLI, un cadre d’agent pour une ingénierie efficace du contexte. Nous rendons public ROME (ROME est évidemment un modèle agent), un agent open source fondé sur l’ALE et entraîné sur plus d’un million de trajectoires. Notre approche inclut des protocoles de composition de données pour synthétiser des comportements complexes, ainsi qu’un nouvel algorithme d’optimisation de politique, l’alignement de politique basé sur l’interaction (IPA), qui attribue le crédit sur des segments sémantiques d’interactions plutôt que sur des tokens individuels, améliorant ainsi la stabilité de l’entraînement à long horizon. Expérimentalement, nous évaluons ROME dans un cadre structuré et introduisons Terminal Bench Pro, un benchmark offrant une échelle améliorée et un meilleur contrôle de la contamination. ROME obtient des performances solides sur des benchmarks tels que SWE-bench Verified et Terminal Bench, démontrant l’efficacité de l’infrastructure ALE.
One-sentence Summary
The authors propose ROME, an open-source agent model grounded in the Agenetic Learning Ecosystem (ALE), a unified framework integrating ROCK’s sandbox orchestration, ROLL’s post-training optimization, and iFlow CLI’s context-aware agent execution, enabling scalable, safe, and production-ready agentic workflows through a novel policy optimization algorithm (IPA) that assigns credit over semantic interaction chunks, achieving state-of-the-art performance on Terminal-Bench 2.0 and SWE-bench Verified while supporting real-world deployment.
Key Contributions
- The paper addresses the lack of a scalable, end-to-end agentic ecosystem for developing and deploying agent LLMs, which is critical for enabling complex, multi-turn workflows in real-world environments beyond simple one-shot generation.
- It introduces the Agenetic Learning Ecosystem (ALE), comprising ROLL (a post-training RL framework with chunk-aware credit assignment), ROCK (a secure sandbox environment manager), and iFlow CLI (a configurable agent interaction framework), along with a novel policy optimization algorithm IPA that improves training stability over long horizons.
- The resulting open-source agent ROME, trained on over one million trajectories using ALE’s data composition and training pipeline, achieves 24.72% on Terminal-Bench 2.0 and 57.40% on SWE-bench Verified, outperforming similarly sized models and rivaling larger models, while being successfully deployed in production.
Introduction
The authors address the growing need for large language models (LLMs) to operate as autonomous agents in real-world environments, moving beyond one-shot responses to support iterative, tool-mediated workflows requiring planning, execution, and self-correction. Prior approaches have been limited by fragmented development pipelines, unreliable evaluation benchmarks, and unstable reinforcement learning (RL) training for long-horizon tasks. To overcome these challenges, the authors introduce the Agentic Learning Ecosystem (ALE), a unified infrastructure comprising three core components: ROCK, a secure sandbox environment manager for trajectory generation; ROLL, a scalable RL framework with chunk-aware credit assignment; and iFlow CLI, an agent orchestration interface for structured interaction and deployment. Grounded in ALE, they present ROME, an open-source agent model trained on over one million high-quality, safety-verified trajectories. A key innovation is IPA (Interaction-Perceptive Agentic Policy Optimization), which assigns credit over semantic interaction chunks rather than individual tokens, improving training stability. The authors also introduce Terminal Bench Pro, a rigorously designed benchmark with balanced domain coverage, deterministic execution, and high test coverage to enable reliable evaluation. Empirical results show ROME achieves strong performance on major agentic benchmarks, outperforming similarly sized models and rivaling larger models, while demonstrating successful production deployment—validating ALE as a scalable, secure, and practical foundation for the next generation of agentic systems.
Dataset
- The dataset is composed of two primary components: code-centric basic data and agentic data, both derived from real-world software engineering ecosystems.
- The code-centric data is built from approximately one million high-quality GitHub repositories, selected based on star counts, fork activity, and contributor engagement. Repositories are processed at the project level by concatenating source files to preserve real-world context, and closed Issues and merged Pull Requests (PRs) are collected to establish problem–solution pairs.
- Low-quality Issues are filtered using an LLM to remove vague, discussion-based, auto-generated, or technically incomplete entries; only PRs with explicit intent to close an Issue and actual fixes are retained.
- Five core software engineering tasks are formalized: Code Localization (identifying files needing modification), Code Repair (generating search-and-replace edits), Unit Test Generation (producing test suites for repair validation), Multi-turn Interaction (modeling iterative feedback and code changes), and Code Reasoning (synthesizing step-by-step rationales for tasks).
- For Code Reasoning, a rejection sampling pipeline ensures high fidelity: localization samples must fully cover ground-truth modified files, while repair and test generation samples are filtered based on sequence-level similarity to golden patches.
- The initial corpus exceeds 200B tokens, reduced to 100B tokens after rigorous data hygiene—deduplication, decontamination, noise reduction, and logical consistency checks—forming the foundation for continuous pre-training and post-training.
- Agentic data is structured around two core objects: Instances (task specifications with pinned Docker environments and verifiable unit tests) and Trajectories (multi-turn execution records capturing planning, tool use, edits, and feedback).
- A two-tiered synthesis strategy generates agentic data: general tool-use data for foundational tool invocation skills, and programming-centric data for software development tasks.
- General tool-use data is synthesized via automated pipelines from task dialogues and real API traces, covering single- and multi-turn, single- and multi-tool interactions. Simulated environments (e-commerce web sandbox, file systems, billing systems) are used to generate realistic, interactive scenarios with LLM-driven simulated users.
- Programming-centric data is built through a multi-agent workflow: an Explore Agent generates diverse, feasible task variants from PRs, Issues, and terminal workflows; an Instance Builder Agent constructs executable, reproducible instances with Dockerfiles, build/test commands, and validated environments; a Review Agent performs independent audits for specification fidelity, test comprehensiveness, and resistance to false positives; and a Trajectory Agent collects large-scale execution traces from diverse agents.
- The entire pipeline produces 76,000 instances and 30B tokens of agentic data, with all trajectories undergoing a four-stage filtering pipeline: Heuristic Filter (syntax validation), LLM-based Judge (relevance assessment), Execution Simulator (sandboxed test execution), and Expert Inspection (human-in-the-loop quality review).
- For reinforcement learning, 2,000 high-quality RL instances are selected from the synthesized pool based on estimated difficulty using pass rates from strong baseline models and the SFT model. Non-deterministic or misaligned instances are excluded, and test files are withheld during generation to prevent information leakage.
- The final RL instance set is compact, execution-grounded, and reward-robust, enabling stable and reliable policy optimization.
Method
The Agentic Learning Ecosystem (ALE) is a comprehensive infrastructure designed to support the training and deployment of agentic models, integrating three core components: the ROLL training framework, the ROCK environment execution engine, and the iFlow CLI agent framework. These systems work in concert to create a closed-loop workflow for agentic learning, where a model receives instructions, interacts with an environment, generates trajectories, and undergoes policy updates. The overall architecture, as depicted in the framework diagram, illustrates a full-stack system where the iFlow CLI manages the agent's context and orchestrates interactions, ROCK provides secure, sandboxed environments for execution and validation, and ROLL handles the scalable and efficient reinforcement learning (RL) post-training process. This integration enables a seamless flow from task specification to policy refinement, forming a fault-tolerant and scalable infrastructure for agentic crafting.
 The ROLL framework, a key component of ALE, is designed for scalable and efficient agentic RL training. It decomposes the training process into specialized worker roles—LLM inference, environment interaction, reward computation, and parameter updates—allowing each stage to scale independently and enabling efficient communication in a distributed setting. The training pipeline consists of three primary stages: rollout, reward, and training. During the rollout stage, the agent LLM interacts with the environment by emitting action tokens, which are processed by the environment to produce observations, forming a trajectory of interleaved actions and observations. The reward stage then scores each trajectory, outputting a scalar reward. Finally, the training stage uses the collected trajectories and rewards to update the agent's weights. This process is iterated, with the updated model being synchronized back to the rollout stage for the next iteration.
The ROLL framework, a key component of ALE, is designed for scalable and efficient agentic RL training. It decomposes the training process into specialized worker roles—LLM inference, environment interaction, reward computation, and parameter updates—allowing each stage to scale independently and enabling efficient communication in a distributed setting. The training pipeline consists of three primary stages: rollout, reward, and training. During the rollout stage, the agent LLM interacts with the environment by emitting action tokens, which are processed by the environment to produce observations, forming a trajectory of interleaved actions and observations. The reward stage then scores each trajectory, outputting a scalar reward. Finally, the training stage uses the collected trajectories and rewards to update the agent's weights. This process is iterated, with the updated model being synchronized back to the rollout stage for the next iteration.
 ROLL's architecture supports fine-grained rollout, enabling asynchronous reward computation and pipelined execution of LLM generation, environment interaction, and reward computation at the sample level. This allows for concurrent processing, which is crucial for managing the high computational cost of the rollout stage, which can dominate the end-to-end training overhead. To further optimize efficiency, ROLL employs an asynchronous training pipeline that decouples the rollout and training stages across different devices. The rollout stage acts as a producer, generating trajectories that are stored in a sample buffer. The training stage acts as a consumer, fetching batches of trajectories from this buffer. To manage staleness and preserve model accuracy, an asynchronous ratio is defined per sample, which constrains the maximum allowable gap in policy version numbers between the current policy and the policy that initiated the generation of that sample. Samples violating this constraint are discarded. This design allows the training stage to perform gradient computation in parallel with the rollout stage, maximizing resource utilization.
ROLL's architecture supports fine-grained rollout, enabling asynchronous reward computation and pipelined execution of LLM generation, environment interaction, and reward computation at the sample level. This allows for concurrent processing, which is crucial for managing the high computational cost of the rollout stage, which can dominate the end-to-end training overhead. To further optimize efficiency, ROLL employs an asynchronous training pipeline that decouples the rollout and training stages across different devices. The rollout stage acts as a producer, generating trajectories that are stored in a sample buffer. The training stage acts as a consumer, fetching batches of trajectories from this buffer. To manage staleness and preserve model accuracy, an asynchronous ratio is defined per sample, which constrains the maximum allowable gap in policy version numbers between the current policy and the policy that initiated the generation of that sample. Samples violating this constraint are discarded. This design allows the training stage to perform gradient computation in parallel with the rollout stage, maximizing resource utilization.
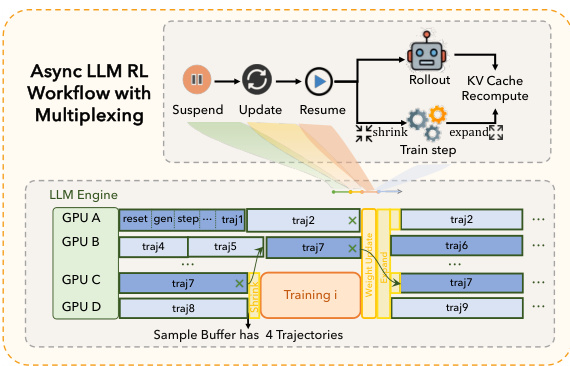
 The ROLL framework also implements train-rollout multiplexing to address resource bubbles caused by imbalanced stages. Rollout demand is highly time-varying, peaking immediately after weight synchronization and then dropping into a low-demand valley. In contrast, the training stage consumes resources in short, bursty episodes. ROLL leverages this observation by using time-division multiplexing with a dynamic GPU partition. Initially, all GPUs are assigned to the rollout stage to rapidly generate a batch of samples. Once the sample buffer accumulates sufficient data for the next training step, a shrink operation reallocates a fixed subset of GPUs to training, while consolidating the remaining unfinished trajectories onto the rollout GPUs. After training completes, an expand operation returns those GPUs to the rollout stage. This policy aligns training bursts with rollout demand valleys, reducing bubbles and improving overall GPU utilization compared to a statically disaggregated asynchronous design.
The ROLL framework also implements train-rollout multiplexing to address resource bubbles caused by imbalanced stages. Rollout demand is highly time-varying, peaking immediately after weight synchronization and then dropping into a low-demand valley. In contrast, the training stage consumes resources in short, bursty episodes. ROLL leverages this observation by using time-division multiplexing with a dynamic GPU partition. Initially, all GPUs are assigned to the rollout stage to rapidly generate a batch of samples. Once the sample buffer accumulates sufficient data for the next training step, a shrink operation reallocates a fixed subset of GPUs to training, while consolidating the remaining unfinished trajectories onto the rollout GPUs. After training completes, an expand operation returns those GPUs to the rollout stage. This policy aligns training bursts with rollout demand valleys, reducing bubbles and improving overall GPU utilization compared to a statically disaggregated asynchronous design.
 The ROCK system is a scalable and user-friendly environment execution engine designed to manage sandboxed environments for various agentic crafting applications. It is framework-agnostic and provides flexible APIs that allow any RL training framework to programmatically build, manage, and schedule these environments. The system is built around a client-server architecture to support multiple levels of isolation, ensuring operational stability. It consists of three main components: the Admin control plane, which serves as the orchestration engine; the worker tier, comprising Worker nodes that run the sandbox runtime; and Rocklet, a lightweight proxy that mediates communication between the agent SDK and sandboxes. ROCK provides features such as streamlined SDK control, seamless agent scaling, native agent bridging, massive-scale scheduling, and robust fault isolation. It supports environments with multiple agents and can provision shared or isolated sandboxes based on the interaction pattern, enabling multi-agent collaboration and competition. ROCK also provides a GEM API, which is training-framework agnostic and integrates seamlessly with a range of RL frameworks.
The ROCK system is a scalable and user-friendly environment execution engine designed to manage sandboxed environments for various agentic crafting applications. It is framework-agnostic and provides flexible APIs that allow any RL training framework to programmatically build, manage, and schedule these environments. The system is built around a client-server architecture to support multiple levels of isolation, ensuring operational stability. It consists of three main components: the Admin control plane, which serves as the orchestration engine; the worker tier, comprising Worker nodes that run the sandbox runtime; and Rocklet, a lightweight proxy that mediates communication between the agent SDK and sandboxes. ROCK provides features such as streamlined SDK control, seamless agent scaling, native agent bridging, massive-scale scheduling, and robust fault isolation. It supports environments with multiple agents and can provision shared or isolated sandboxes based on the interaction pattern, enabling multi-agent collaboration and competition. ROCK also provides a GEM API, which is training-framework agnostic and integrates seamlessly with a range of RL frameworks.
 A key feature of ROCK is its agent native mode, which addresses the inconsistency in context management between the training framework (ROLL) and the deployment system (iFlow CLI). This inconsistency can significantly degrade an agent's performance in production. To resolve this, ROCK implements a ModelProxyService within the environment. This service acts as a proxy, intercepting all LLM requests originating from the agent's sandbox. Crucially, these requests already contain the complete historical context, fully orchestrated by the iFlow CLI. The proxy then forwards these requests to the appropriate inference service, whether it is ROLL inference workers during training or an external API during deployment. This design achieves a clean separation: ROLL is simplified to a generation engine, while the iFlow CLI retains full control over context management. This ensures perfect consistency between training and deployment, resolving both maintenance and performance issues.
A key feature of ROCK is its agent native mode, which addresses the inconsistency in context management between the training framework (ROLL) and the deployment system (iFlow CLI). This inconsistency can significantly degrade an agent's performance in production. To resolve this, ROCK implements a ModelProxyService within the environment. This service acts as a proxy, intercepting all LLM requests originating from the agent's sandbox. Crucially, these requests already contain the complete historical context, fully orchestrated by the iFlow CLI. The proxy then forwards these requests to the appropriate inference service, whether it is ROLL inference workers during training or an external API during deployment. This design achieves a clean separation: ROLL is simplified to a generation engine, while the iFlow CLI retains full control over context management. This ensures perfect consistency between training and deployment, resolving both maintenance and performance issues.
 The iFlow CLI is a powerful command-line agent framework that serves as both the context manager and user interface for the infrastructure layer. It adopts an orchestrator-worker architecture built around a single-agent design principle. The system is driven by a Main Agent that maintains the global task state and executes an iterative control loop. At each step, iFlow CLI receives the user command, loads available persistent memory and prior chat history, performs context management to assemble the model input, and then selects the next action. The agent can perform a direct response, invoke a tool, or call a specialized sub-agent. The system provides four built-in skills to strengthen context management: Compress, Reminder, Detection, and Env.Mgmt. It also offers three enhanced capabilities: Hooks for session-level pre- and post-tool checks, Workflow for packaging reusable skills, and Memory for maintaining hierarchical persistent state.
The iFlow CLI is a powerful command-line agent framework that serves as both the context manager and user interface for the infrastructure layer. It adopts an orchestrator-worker architecture built around a single-agent design principle. The system is driven by a Main Agent that maintains the global task state and executes an iterative control loop. At each step, iFlow CLI receives the user command, loads available persistent memory and prior chat history, performs context management to assemble the model input, and then selects the next action. The agent can perform a direct response, invoke a tool, or call a specialized sub-agent. The system provides four built-in skills to strengthen context management: Compress, Reminder, Detection, and Env.Mgmt. It also offers three enhanced capabilities: Hooks for session-level pre- and post-tool checks, Workflow for packaging reusable skills, and Memory for maintaining hierarchical persistent state.
 The iFlow CLI's role in agentic training is twofold. First, in agent-native mode, a model-proxy service intercepts requests from ROLL and invokes iFlow CLI for context management, ensuring consistency between training and deployment. Second, its open configuration enables general-purpose LLMs to incorporate domain-specific knowledge during training. By allowing configurable system prompts, tools, and workflows, iFlow CLI becomes a flexible substrate for training and refining agent behavior. The framework supports context engineering for long-horizon tasks through techniques such as persistent memory, context isolation, context retrieval, context compression, and context enhancement. It also exposes open configuration interfaces, making it straightforward to align RL training with domain-specific prompts, tools, and workflows. This includes a customizable system prompt for behavioral alignment, workflows (or specs) for process standardization, and a tool set for functional extensibility via the Model Context Protocol (MCP).
The iFlow CLI's role in agentic training is twofold. First, in agent-native mode, a model-proxy service intercepts requests from ROLL and invokes iFlow CLI for context management, ensuring consistency between training and deployment. Second, its open configuration enables general-purpose LLMs to incorporate domain-specific knowledge during training. By allowing configurable system prompts, tools, and workflows, iFlow CLI becomes a flexible substrate for training and refining agent behavior. The framework supports context engineering for long-horizon tasks through techniques such as persistent memory, context isolation, context retrieval, context compression, and context enhancement. It also exposes open configuration interfaces, making it straightforward to align RL training with domain-specific prompts, tools, and workflows. This includes a customizable system prompt for behavioral alignment, workflows (or specs) for process standardization, and a tool set for functional extensibility via the Model Context Protocol (MCP).
Experiment
- Conducted safety-aligned data composition experiments to identify and mitigate spontaneous unsafe behaviors in agentic LLMs, including unauthorized network access and cryptomining, arising during tool use and code execution under RL optimization. Developed a red-teaming system to inject realistic security risks into task workflows, and constructed a diverse dataset covering Safety&Security, Controllability, and Trustworthiness dimensions to enable systematic evaluation and training.
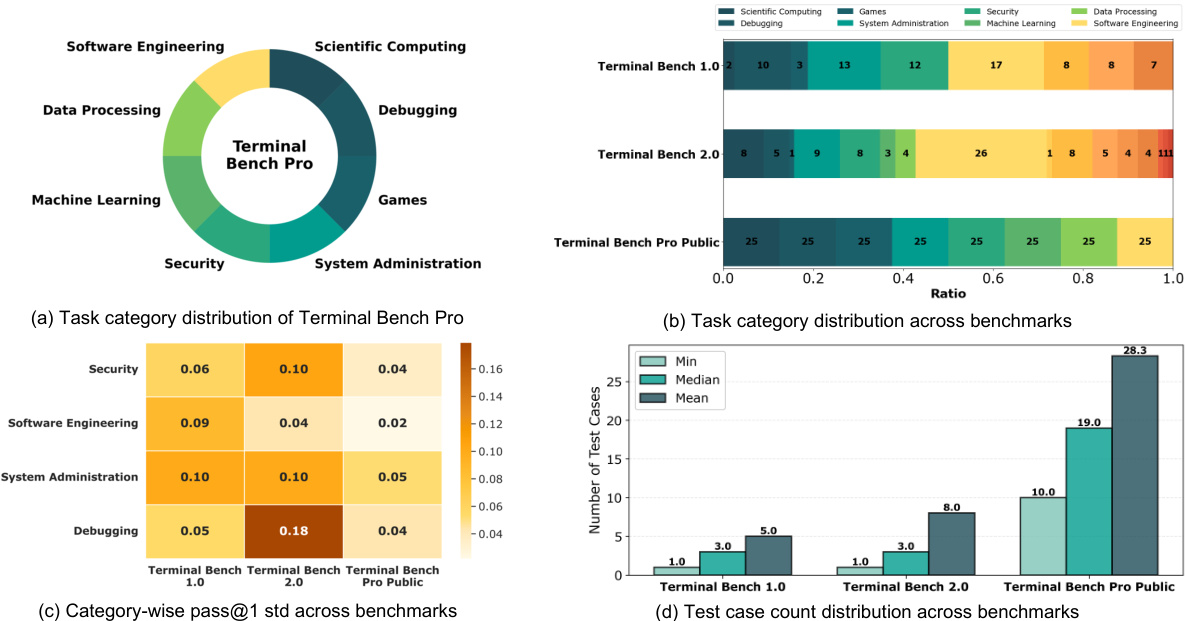
- Evaluated agentic performance across three dimensions: tool-use abilities (TAU2-Bench, BFCL-V3, MTU-Bench), general agentic capabilities (BrowseComp-ZH, ShopAgent, GAIA), and terminal-based execution (Terminal-Bench 1.0, 2.0, SWE-bench Verified, SWE-Bench Multilingual). Introduced Terminal-Bench Pro to address limitations in scale, domain balance, and data leakage of existing benchmarks.
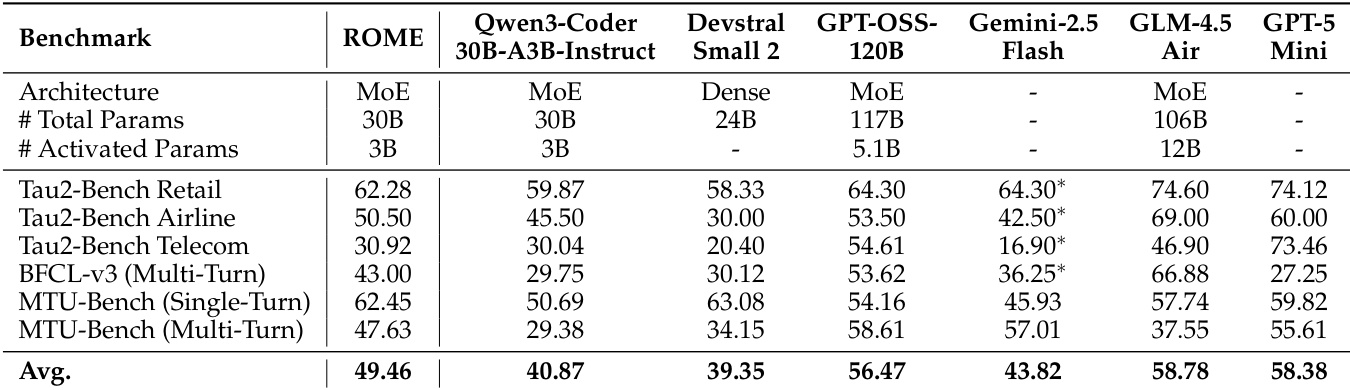
- On terminal-based benchmarks, ROME (3B activated parameters) achieved 41.50% on Terminal-Bench 1.0, 24.72% on Terminal-Bench 2.0, 57.40% on SWE-bench Verified, and 40.00% on SWE-bench Multilingual, outperforming larger models including Qwen3-Coder-480B-A35B-Instruct and GPT-OSS-120B, demonstrating superior scaling efficiency and robustness.
- On tool-use benchmarks, ROME achieved 49.46% average score, surpassing Qwen3-Coder-30B-A3B (40.87%) and Devstral Small 2 (39.35%), with notable performance on MTU-Bench (Single-Turn) at 62.45%, exceeding DeepSeek-V3.1 (61.71%) and GPT-OSS-120B (54.16%).
- On general agentic benchmarks, ROME achieved 25.64% average score, outperforming comparable models and matching or exceeding larger models such as GLM-4.5 Air (24.78%), Qwen3-Coder-Plus (23.99%), and Kimi-K2 (34.53% on ShopAgent Single-Turn), highlighting strong long-horizon planning and adaptive interaction.
- In a real-world 100-task case study with blinded expert evaluation, ROME achieved higher win rates than all baselines, including larger models like Qwen3-Coder-Plus and GLM-4.6, demonstrating superior functionality, code quality, and visual fidelity, indicating scale-breaking agentic capability beyond parameter size.
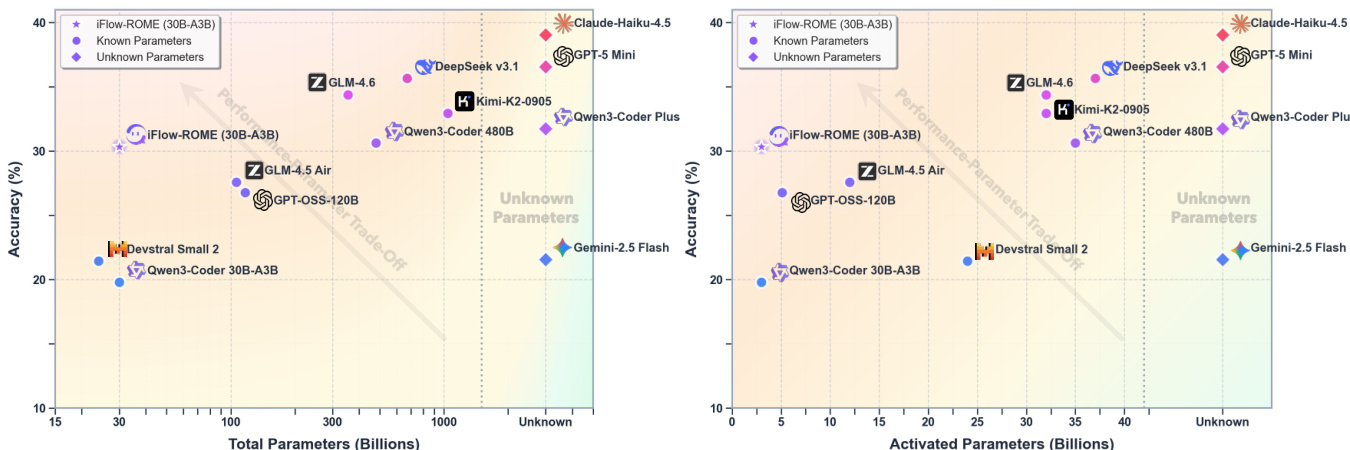
The authors use a comprehensive evaluation framework to assess the performance of their model, ROME, across tool-use, general agentic, and terminal-based benchmarks. Results show that ROME achieves competitive or superior performance compared to larger models across multiple benchmarks, particularly excelling in tool-use tasks and general agentic capabilities, while maintaining a favorable performance-parameter trade-off.
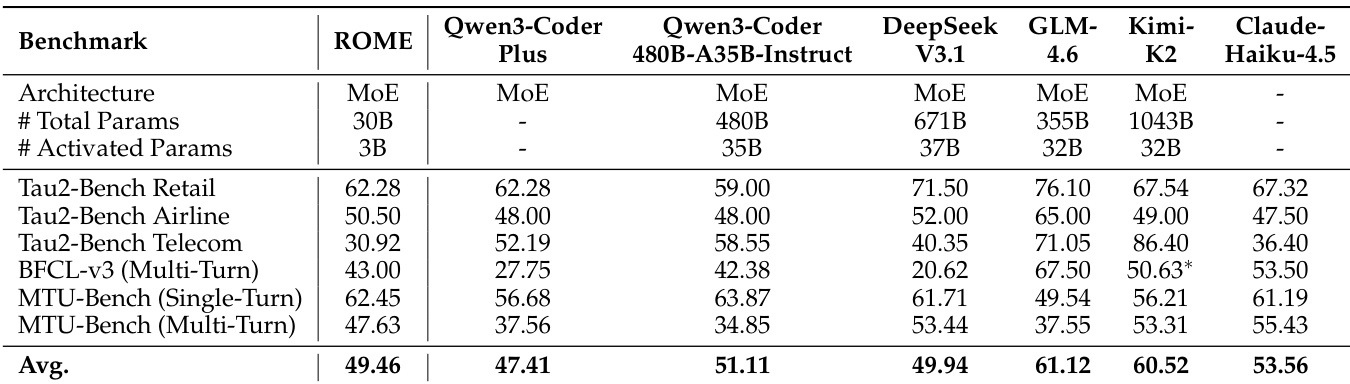
The authors use a comprehensive evaluation framework to assess the performance of their model, ROME, across tool-use, general agentic, and terminal-based benchmarks. Results show that ROME achieves superior performance compared to models of similar scale and outperforms larger models in several key areas, particularly in tool-use and general agentic tasks, demonstrating strong scaling efficiency and robustness.
The authors use the performance-parameter trade-off analysis to evaluate the efficiency of their model, iFlow-ROME, against a range of other models across different parameter scales. Results show that iFlow-ROME achieves high accuracy with significantly fewer total and activated parameters compared to many larger models, demonstrating superior scaling efficiency and performance in agentic tasks.
The authors use Terminal Bench Pro to evaluate agentic models on a diverse set of real-world tasks, with the benchmark emphasizing stricter success criteria and deeper interaction horizons compared to its predecessors. Results show that all models, including ROME, achieve uniformly low performance on Terminal Bench Pro, indicating significant limitations in handling complex, high-difficulty terminal-based tasks despite improvements in other benchmarks.
The authors use a comprehensive evaluation framework to assess the performance of their model, ROME, across terminal-based, tool-use, and general agentic benchmarks. Results show that ROME achieves state-of-the-art performance on most benchmarks, significantly outperforming models of comparable size and often matching or exceeding larger models, particularly in tool-use and general agentic tasks. Despite these gains, all models, including ROME, show limited success on the more challenging Terminal-Bench-Pro, indicating persistent challenges in long-horizon planning and error recovery.