Command Palette
Search for a command to run...
Entraînement en temps réel du bout en bout pour un contexte long
Entraînement en temps réel du bout en bout pour un contexte long
Résumé
Nous formulons le modèle linguistique à longue portée comme un problème d’apprentissage continu, plutôt que comme un problème de conception d’architecture. Dans cette formulation, nous utilisons uniquement une architecture standard — un Transformer doté d’une attention à fenêtre glissante. Toutefois, notre modèle apprend continuellement au moment du test grâce à la prédiction du token suivant sur le contexte fourni, en compressant le contexte lu dans ses poids. En outre, nous améliorons l’initialisation du modèle pour faciliter l’apprentissage au moment du test grâce à une méta-apprentissage effectué pendant l’entraînement. Globalement, notre méthode, qui relève d’une forme d’entraînement au moment du test (Test-Time Training, TTT), est end-to-end tant au moment du test (via la prédiction du token suivant) que pendant l’entraînement (via la méta-apprentissage), contrairement aux approches antérieures. Nous menons des expériences étendues axées sur les propriétés d’échelle. En particulier, pour des modèles de 3 milliards de paramètres entraînés sur 164 milliards de tokens, notre méthode (TTT-E2E) évolue avec la longueur du contexte de manière identique à celle du Transformer à attention complète, tandis que d’autres approches, comme Mamba 2 ou Gated DeltaNet, ne le font pas. Toutefois, tout comme les réseaux de neurones récurrents (RNN), TTT-E2E présente une latence d’inférence constante indépendamment de la longueur du contexte, ce qui la rend 2,7 fois plus rapide que l’attention complète pour un contexte de 128K tokens. Notre code est disponible publiquement.
One-sentence Summary
The authors from Astera Institute, NVIDIA, Stanford University, UC Berkeley, and UC San Diego propose TTT-E2E, a test-time training method that enables standard Transformers with sliding-window attention to scale effectively with long contexts by continuously learning via next-token prediction and meta-learning initialization, achieving full-attention performance with constant latency—2.7× faster than full attention at 128K context—while maintaining end-to-end training and inference.
Key Contributions
- The paper reframes long-context language modeling as a continual learning problem, using a standard Transformer with sliding-window attention and enabling the model to continuously learn at test time via next-token prediction, thereby compressing context into its weights without requiring architectural changes.
- It introduces a novel end-to-end Test-Time Training (TTT) method that uses meta-learning during training to optimize the model's initialization for effective test-time adaptation, ensuring the model is primed to improve on new context through dynamic updates.
- Experiments show that TTT-E2E matches the performance scaling of full-attention Transformers with increasing context length while maintaining constant inference latency—achieving 2.7× faster inference than full attention at 128K context—outperforming alternatives like Mamba 2 and Gated DeltaNet.
Introduction
The authors address the challenge of efficient long-context language modeling, where traditional Transformers suffer from quadratic computational cost due to full self-attention, while RNN-based alternatives like Mamba degrade in performance over long sequences. Prior approaches such as sliding windows or hybrid architectures offer limited gains and fail to match full attention’s effectiveness. The key insight is that humans compress vast experience into usable intuition—inspiring a method where models continuously adapt at test time via next-token prediction, effectively compressing context into learned weights. The authors introduce end-to-end Test-Time Training (TTT) with meta-learning: the model is initialized to be optimized for performance after a short period of test-time adaptation, using a bi-level optimization framework where the outer loop trains the initialization to minimize the loss after inner-loop TTT. This approach achieves strong long-context performance with constant per-token cost, without relying on memorization or architectural changes, and demonstrates that TTT can be a general-purpose mechanism for continual learning in language models.
Method
The authors leverage a Transformer architecture with sliding-window attention as the baseline for their method, which they frame as a form of Test-Time Training (TTT) that is end-to-end (E2E) at both training and test time. The core idea is to enable the model to continue learning at test time by performing next-token prediction on the given context, thereby compressing the context into its weights. This process is achieved through a two-stage optimization: an outer loop that trains the initial model weights to be suitable for test-time adaptation, and an inner loop that performs gradient updates on the model's parameters during inference.
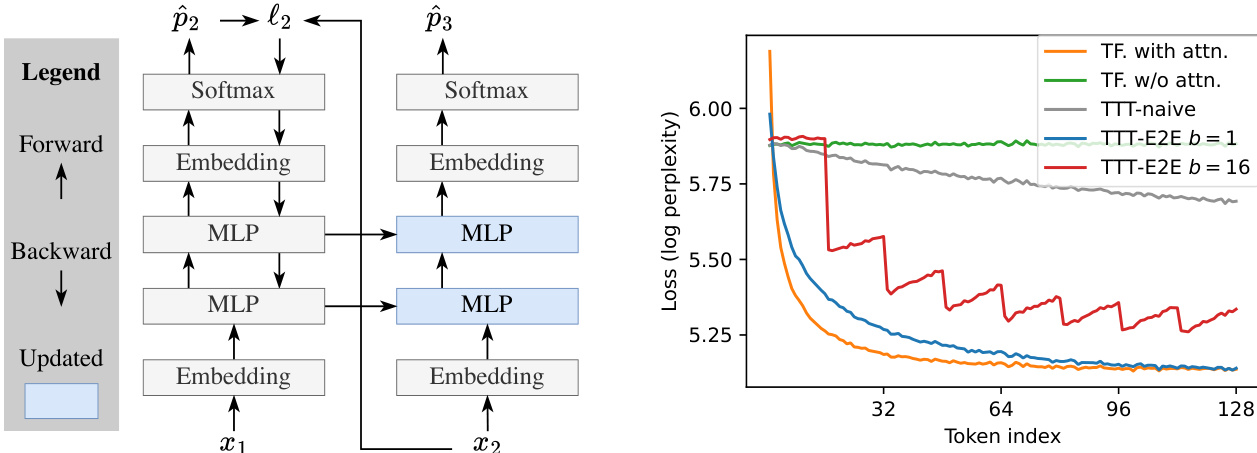
The framework diagram illustrates the overall process. The model processes input tokens sequentially, with each token passing through the network's layers. The key innovation lies in the backward pass, where gradients from the loss at each token are used to update the model's weights. This update is performed in a mini-batch fashion, where the model processes a block of tokens and then performs a single gradient step to update its weights. The updated weights are then used for the next block of tokens, allowing the model to gradually incorporate the context it has seen so far. The model's architecture includes a sliding window attention mechanism, which restricts the attention to a fixed window size, enabling the model to maintain a local context while still allowing for long-range dependencies to be learned through the test-time training process.
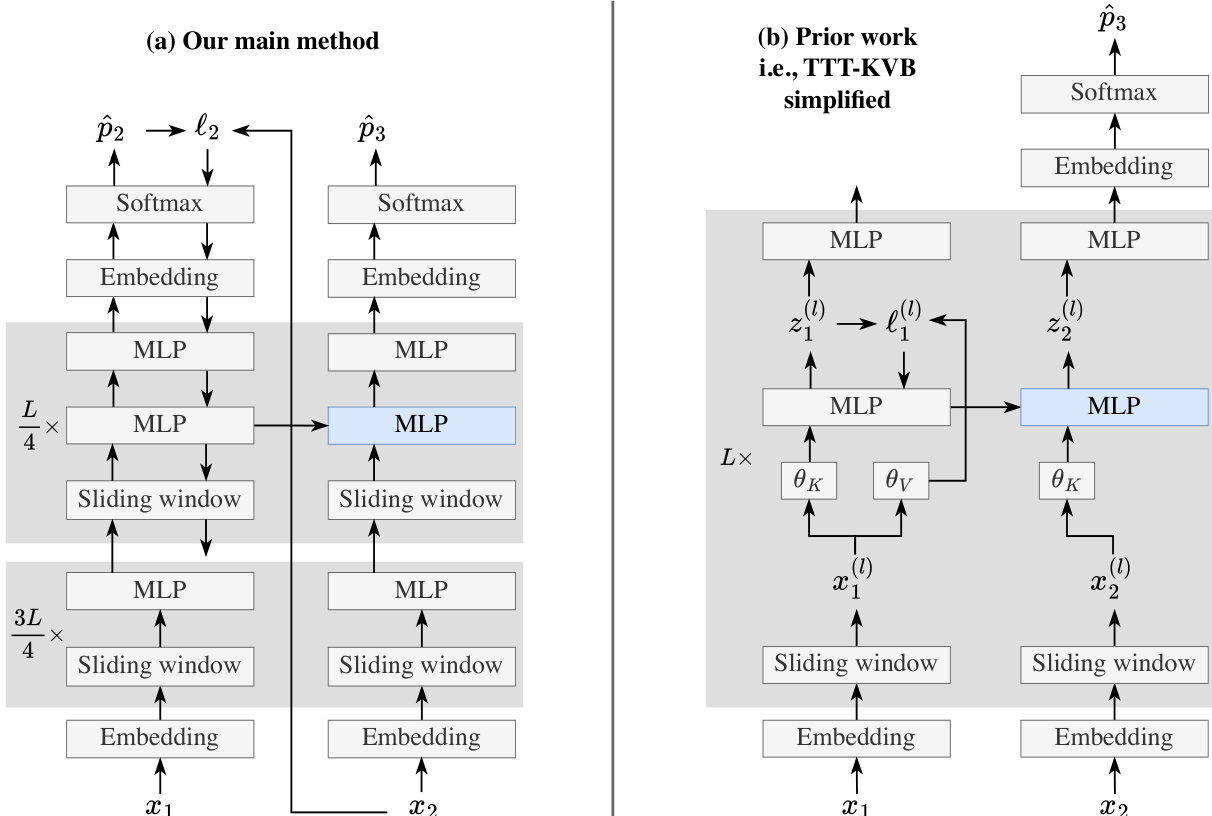
The comparison diagram highlights the differences between the authors' main method and prior work, specifically TTT-KVB. The main method, shown in (a), uses a standard Transformer architecture with sliding-window attention and updates only a subset of the model's layers (specifically, the last quarter) during test-time training. In contrast, prior work, shown in (b), uses a more complex architecture with multiple TTT layers, each with its own set of parameters and reconstruction loss. The main method simplifies this by using a single next-token prediction loss at the end of the network, making it E2E at test time. This simplification allows for a more efficient and stable training process, as the gradients are only backpropagated through the updated layers, reducing the computational cost and the risk of gradient explosion. The authors also note that their method can be viewed as an RNN with a single layer, where the model's weights act as long-term memory and the sliding window acts as short-term memory.
Experiment
- Main experiment: Evaluation of TTT-E2E on next-token prediction with test-time training, comparing prefill and decode efficiency against baselines.
- Validates: TTT-E2E achieves lower test loss than full attention across context lengths, especially in early tokens, despite using only 1/4 of the layers and sliding-window attention.
- Core results: On Books dataset at 128K context length, TTT-E2E achieves a loss of 2.67, surpassing full attention (2.70) and other baselines; on 3B model, TTT-E2E maintains consistent advantage over full attention across context lengths up to 128K.
- Ablations confirm optimal hyperparameters: sliding window size k=8K, mini-batch size b=1K, and updating 1/4 of the layers.
- TTT-E2E scales similarly to full attention under large training budgets, with performance matching full attention at 48B training tokens and beyond.
- Decoding evaluation shows TTT-E2E maintains lower loss than full attention during long sequence generation, with reasonable text output.
- Computational efficiency: TTT-E2E has O(T) prefill and O(1) decode latency, outperforming prior RNN methods in hardware utilization, though training latency remains a bottleneck due to gradient-of-gradients computation.
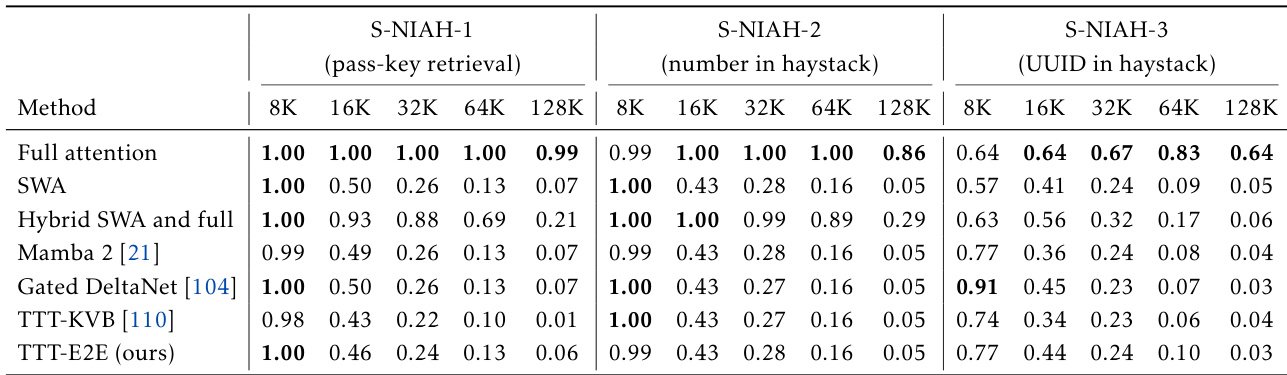
The authors use a Needle in a Haystack (NIAH) evaluation to assess the ability of models to retrieve specific information from long contexts. Results show that full attention dramatically outperforms all other methods, including the proposed TTT-E2E, especially in long contexts, indicating that full attention's strength lies in its nearly lossless recall.
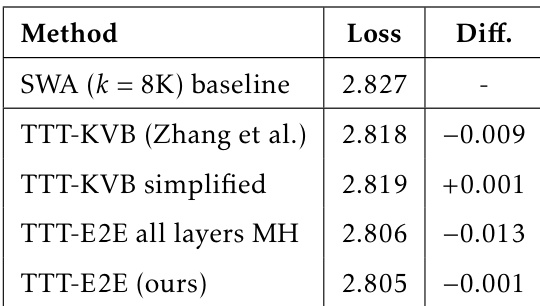
The authors use a table to compare the performance of various methods on a language modeling task, with loss values indicating model accuracy. Results show that TTT-E2E (ours) achieves the lowest loss among the methods listed, outperforming the SWA baseline and other TTT variants, with a loss of 2.805 and a difference of -0.001 compared to the baseline.
The authors use a consistent basic recipe across five model sizes, ranging from 125M to 2.7B parameters, with model configurations and pre-training hyperparameters derived from GPT-3 and Mamba 2. The pre-training recipe uses a fixed batch size of 0.5M tokens and a learning rate that varies with model size, while the fine-tuning recipe employs a larger batch size and a fixed learning rate of 4e-4 across all models and context lengths.
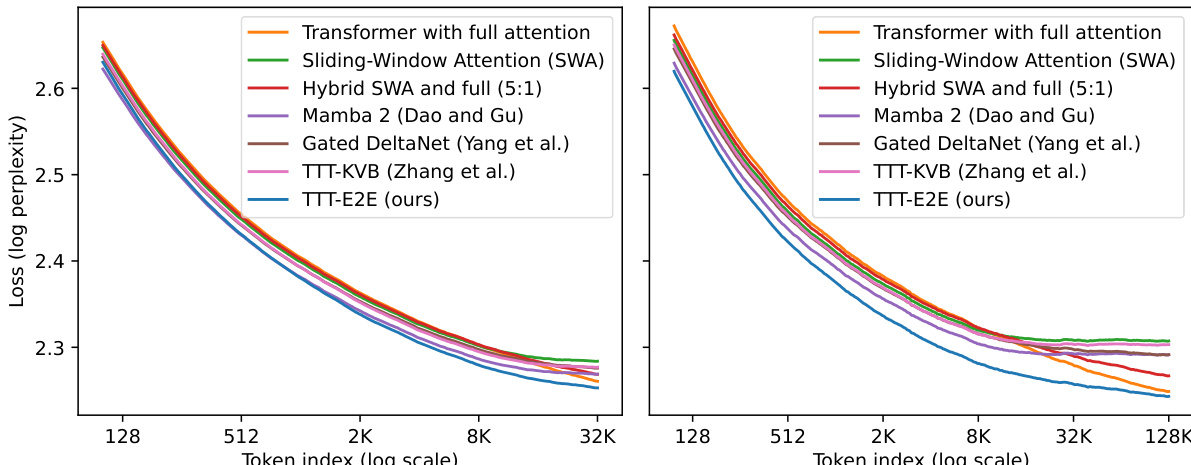
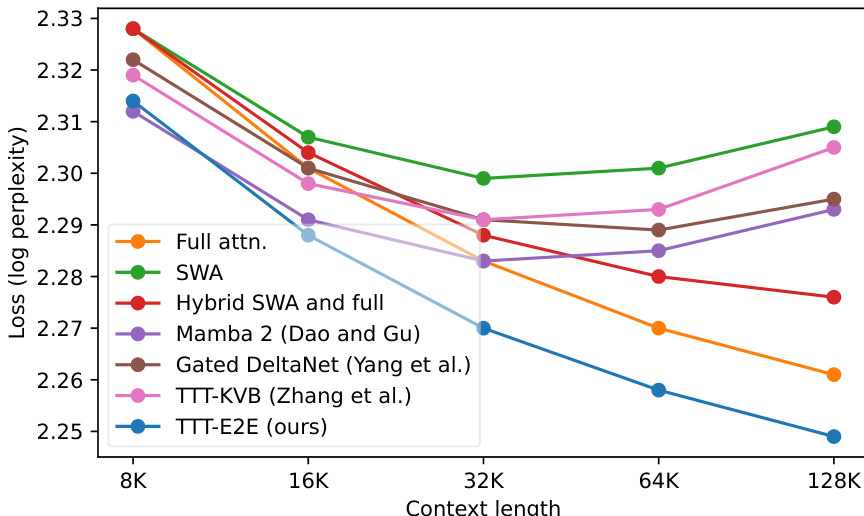
Results show that TTT-E2E achieves lower loss than full attention across all context lengths, with the largest advantage observed at shorter contexts. While full attention maintains a slight edge at the longest context length, TTT-E2E consistently outperforms all other baselines, including Mamba 2 and Gated DeltaNet, especially in the 8K to 32K range.
The authors use a loss breakdown by token index to analyze model performance across different context lengths. Results show that TTT-E2E consistently achieves lower losses than full attention across all token positions, with the advantage primarily coming from earlier tokens in the context. This indicates that TTT-E2E maintains a performance edge even in long-context scenarios where full attention typically excels.