Command Palette
Search for a command to run...
MindWatcher : Vers un raisonnement multimodal intégrant des outils plus intelligent
MindWatcher : Vers un raisonnement multimodal intégrant des outils plus intelligent
Résumé
Les agents basés sur des workflows traditionnels présentent une intelligence limitée lorsqu'ils sont confrontés à des problèmes du monde réel nécessitant l'invocation d'outils. Les agents de raisonnement intégrant des outils (Tool-integrated Reasoning, TIR), capables de raisonnement autonome et d'invocation d'outils, émergent rapidement comme une approche puissante pour des tâches décisionnelles complexes impliquant des interactions multi-étapes avec des environnements externes. Dans ce travail, nous introduisons MindWatcher, un agent TIR qui intègre un raisonnement en chaîne de pensée (chain-of-thought, CoT) multimodal et une pensée entrelacée. MindWatcher peut décider de manière autonome, et de façon adaptative, si, quand et comment invoquer divers outils, ainsi que coordonner leur utilisation, sans dépendre de prompts humains ni de workflows prédéfinis. Le paradigme de pensée entrelacée permet au modèle de basculer à tout stade intermédiaire entre la réflexion et l'appel d'outils, tandis que sa capacité en CoT multimodal lui permet de manipuler des images au cours du raisonnement, aboutissant à des résultats de recherche plus précis. Nous avons mis en œuvre des pipelines automatisés d'audit et d'évaluation des données, complétés par des jeux de données de haute qualité soigneusement curatifs pour l'entraînement, et nous avons conçu un benchmark, nommé MindWatcher-Evaluate Bench (MWE-Bench), pour évaluer sa performance. Doté d'une suite complète d'outils auxiliaires de raisonnement, MindWatcher est en mesure de traiter des problèmes multimodaux couvrant un large spectre de domaines. Une base de données locale de récupération d'images de grande qualité, à grande échelle et couvrant huit catégories — y compris voitures, animaux et plantes — confère au modèle une robuste capacité de reconnaissance d'objets, malgré sa taille réduite. Enfin, nous avons conçu une infrastructure d'entraînement plus efficace pour MindWatcher, améliorant significativement la vitesse d'entraînement et l'utilisation des ressources matérielles. Les expériences démontrent non seulement que MindWatcher atteint ou dépasse les performances de modèles plus grands ou plus récents grâce à une meilleure gestion des outils, mais révèlent également des insights critiques pour l'entraînement des agents, tels que le phénomène d'héritage génétique dans le cadre de l'apprentissage par renforcement agencé (agentic RL).
One-sentence Summary
The authors from Li Auto Inc. introduce MindWatcher, a multimodal Tool-Integrated Reasoning agent that leverages interleaved thinking and multimodal chain-of-thought reasoning to autonomously coordinate diverse tools—including image region manipulation, local visual search, and code execution—without relying on human workflows. By adopting continuous reinforcement learning with a novel step-wise normalization strategy and a large-scale, expert-curated local image retrieval database, MindWatcher achieves state-of-the-art performance on MWE-Bench, outperforming larger models in complex, real-world tasks while enabling efficient distillation into smaller variants.
Key Contributions
- MindWatcher introduces an interleaved thinking and multimodal chain-of-thought framework that enables autonomous, dynamic decision-making between reasoning and tool invocation, supporting fine-grained visual manipulation and cross-modal reasoning for real-world multimodal tasks beyond text-only capabilities.
- The agent is trained via continuous reinforcement learning with automated data pipelines for image-text pair generation, avoiding the pitfalls of supervised fine-tuning such as rigid imitation and excessive tool calls, while achieving superior performance on complex, multi-step tasks.
- MindWatcher is evaluated on MWE-Bench, a newly constructed benchmark, and demonstrates state-of-the-art results on 2B, 3B, and 4B distilled models, outperforming larger or more recent models through efficient tool coordination and a local image retrieval database covering eight domains.
Introduction
The authors address the growing need for intelligent agents capable of autonomous, multi-step reasoning in real-world environments, where traditional workflow-based systems and even modern multi-agent architectures struggle with adaptability, latency, and cross-modal integration. Prior TIR agents are largely limited to text-based tasks, with minimal support for fine-grained visual reasoning, and suffer from training instability, redundant tool use, and reliance on expensive external APIs. To overcome these challenges, the authors introduce MindWatcher, a multimodal TIR agent that combines interleaved thinking with multimodal chain-of-thought reasoning, enabling dynamic, context-aware tool invocation and direct image manipulation. The system leverages continuous reinforcement learning instead of supervised fine-tuning to avoid rigid imitation, employs a novel RL algorithm with step-wise normalization for stable training, and integrates a cost-effective local visual corpus and automated data pipelines. MindWatcher achieves state-of-the-art performance on a new multimodal benchmark, MWE-Bench, outperforming larger models while demonstrating that foundation model limitations impose a fundamental "genetic constraint" on agentic reasoning, even after extensive RL optimization.
Dataset

-
The dataset is composed of multiple sources, including a private, high-quality multimodal database, authoritative sports portals, and curated open-source benchmarks. The core of the dataset is the MindWatcher Multi-modal Retrieval Database (MWRD), which spans eight categories: Person, Car, Plant, Animal, Logo, Landmark, Fruit & Vegetable, and Dish. It contains 50,000 retrieval entities, with 3–10 high-quality images per entity, totaling over 300,000 images. The images are sourced from the internet and professional museum databases, and undergo expert-level filtering and curation to ensure over 99% precision.
-
The MWRD is used to support multimodal reasoning and tool use in training. For the training data, the authors construct a cross-modal QA dataset through a three-stage pipeline: source knowledge anchoring and generation, QA quality validation, and difficulty grading. This includes fine-grained visual-knowledge mapping via object localization and retrieval labeling, followed by knowledge graph augmentation using web search to enrich factual context. Initial QA pairs are generated based on both visual and external knowledge.
-
A dedicated pipeline is used for domain-specific ingestion, particularly for sports data. A focused crawler collects articles from authoritative sports portals, retaining only those with non-empty text and at least one relevant image. This creates a repository of event-centric multimedia documents, which are later used to generate QA pairs.
-
The MWE-Bench benchmark is constructed with strict separation from training data to prevent data leakage. It includes 373 car, 351 animal, 397 plant, 63 person, 90 landmark, and 142 sports-related instances. For non-sports categories, knowledge entries from the internal database are excluded from training. The construction process involves expanding the knowledge base with web data, applying category-specific constraints, and using closed-source models for "uniqueness deconstruction" to extract core identifying facts. These facts form the basis of single-turn QA pairs, which are then synthesized into multi-step reasoning tasks. All samples undergo automated and manual verification for quality and temporal accuracy.
-
For sports data, text and image corpora from non-overlapping time points are merged, and atomic facts are extracted using a powerful LLM. Complex queries are built from these facts, followed by data cleaning and filtering similar to the non-sports pipeline.
-
The training data is split across online and offline environments. Online training includes 1,639 VQA samples from private images and 2,949 from public news sources. Open-source data, drawn from WebSailor, ToolStar, and SimpleDeepSearcher, totals 5,000 samples after rigorous filtering to remove outdated or leaked content. Offline RL training uses approximately 20,000 samples. A curriculum learning strategy guides training on the Qwen2.5-VL-32B model for one epoch, with asynchronous tool invocation and reward computation.
-
The fully trained MindWatcher-32B model is used to distill multimodal reasoning and tool-use capabilities into smaller models. This involves generating 1–3 TIR trajectories per sample from a base dataset of 181K samples (VLAA SFT, WebWalker silver, and a self-built RAG QA dataset). After filtering, the final distillation dataset contains 124K samples—100K multimodal and 24K text-only—used to train the MindWatcher-2B, -3B, and -4B models.
-
The MWE-Bench and filtered open-source benchmarks (MMSearch subset: 221 samples; SimpleVQA subset: 823 samples) are used for evaluation under the ReAct/Agent paradigm. All tests use a temperature of 0.7 and top-p of 0.95, with correctness assessed via LLM-as-Judges and the primary metric being pass@1.
Method
The authors leverage a reinforcement learning framework to train MindWatcher, an agent designed for multimodal reasoning and autonomous tool use. The core of the system is an autoregressive generation loop that models the task as a Markov Decision Process (MDP), where the agent iteratively generates actions and processes environment observations. At each step, the policy model, parameterized by a large language model (LLM), conditions on the full history of interactions to produce a unified action, which can be either a reasoning step (thought) or a tool call. These actions are serialized using dedicated tags, enabling interleaved thinking and action generation within a single decoding sequence. This approach supports a multimodal chain-of-thought mechanism, allowing the agent to reason with images by embedding image-dependent operations into its reasoning process.

As shown in the figure below, the agent begins with an initial user prompt and an image, then enters an iterative planning and tool-call process. After each tool call, the resulting observation is appended to the context, informing the next action. The agent continues this cycle until it generates a final action containing the concluding response. The framework integrates a large-scale local retrieval corpus and a comprehensive multimodal toolkit, including tools for region cropping, visual search, external text retrieval, webpage content extraction, and local code execution. This enables the agent to perform complex multimodal question answering by dynamically interacting with the environment and leveraging external knowledge sources.

The training process employs an enhanced version of Group Relative Policy Optimization (GRPO) as the core learning algorithm. To address the challenges of interleaved thinking, where trajectories consist of multiple "Think and Tool-call" cycles with varying lengths, the authors propose a step-wise normalization mechanism. This approach optimizes the objective function on individual action segments rather than the global token stream, ensuring balanced supervision across every reasoning step. The optimization objective incorporates two normalization factors: action-step normalization, which weights each trajectory equally regardless of the number of cycles, and token-length normalization, which averages the loss within each episode. This dual-normalization mechanism prevents longer episodes from dominating the optimization process.
The reward function is designed to guide the model toward both syntactic correctness and factual accuracy through a hybrid reward system. It consists of three components: Outcome Accuracy Reward, Format Reward, and Hallucination Tool-call Penalty. The Outcome Accuracy Reward is a sparse reward computed at termination, evaluated by a model-based judge to assess factual consistency. The Format Reward enforces strict schema adherence using a regex-based parser, penalizing format errors and non-whitespace residues outside valid tags. The Hallucination Tool-call Penalty discourages the model from generating consecutive tool calls without waiting for environmental feedback, penalizing discrepancies between the number of model calls and actual responses. The final reward is a weighted sum of these components, with specific coefficients set to balance their influence.
Experiment
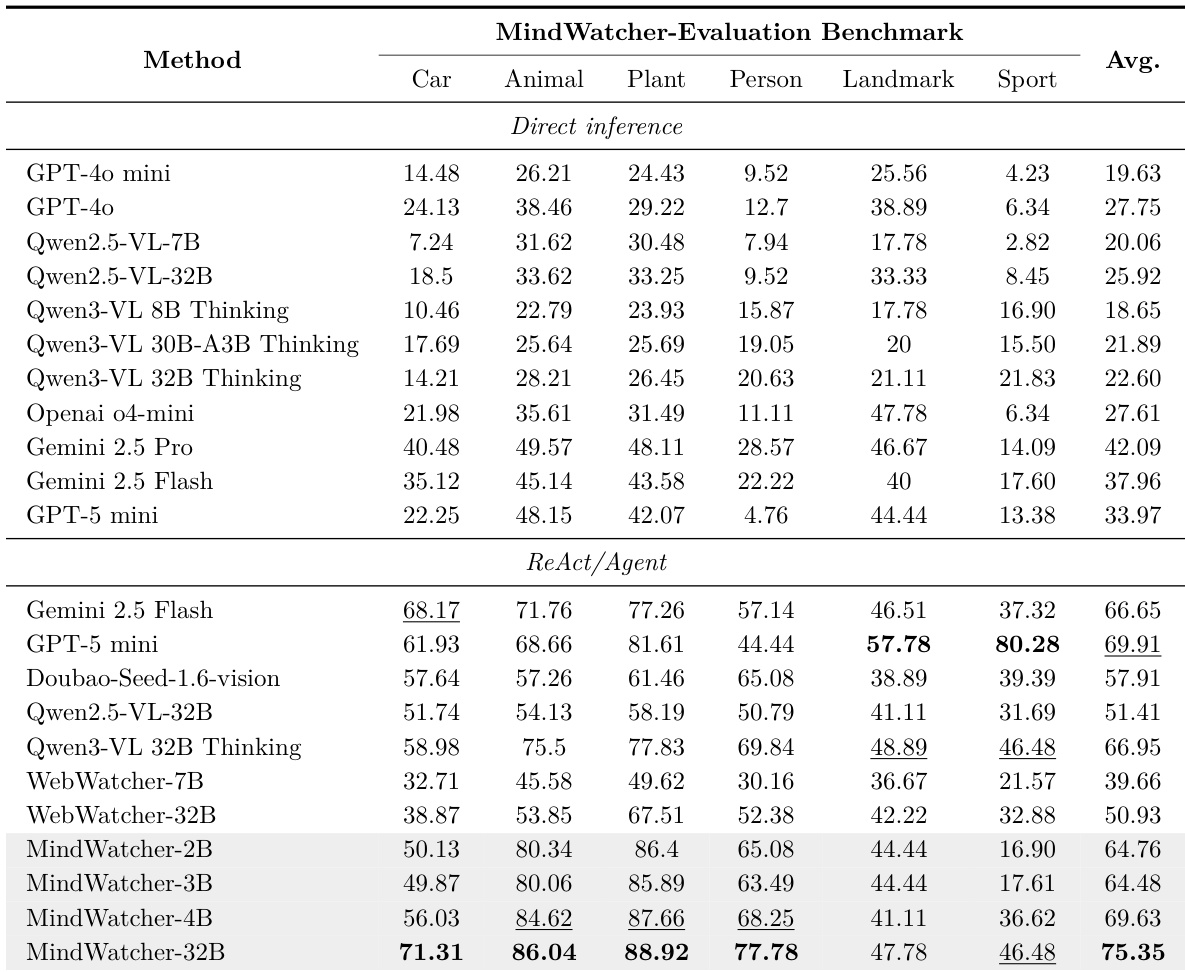
- Main experiments validate the effectiveness of tool-augmented reasoning in multimodal agents, particularly through the MindWatcher series, which achieves SOTA performance on MWE-Bench with a global score of 75.35, outperforming models like Gemini 2.5 Flash and GPT-5 mini.
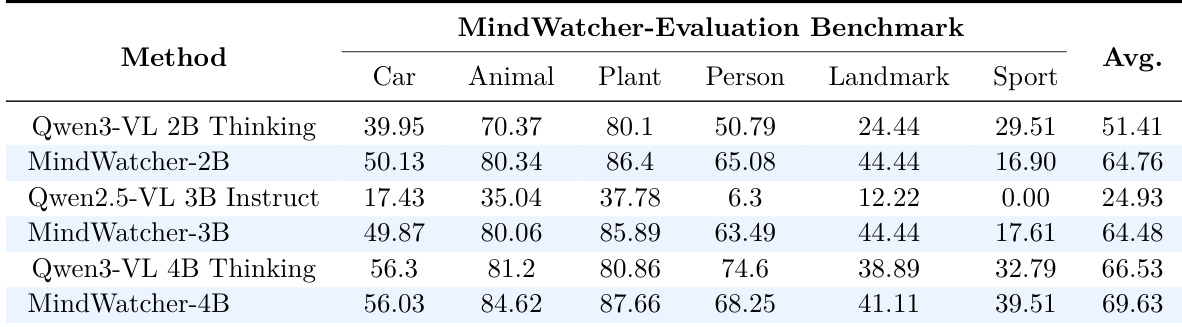
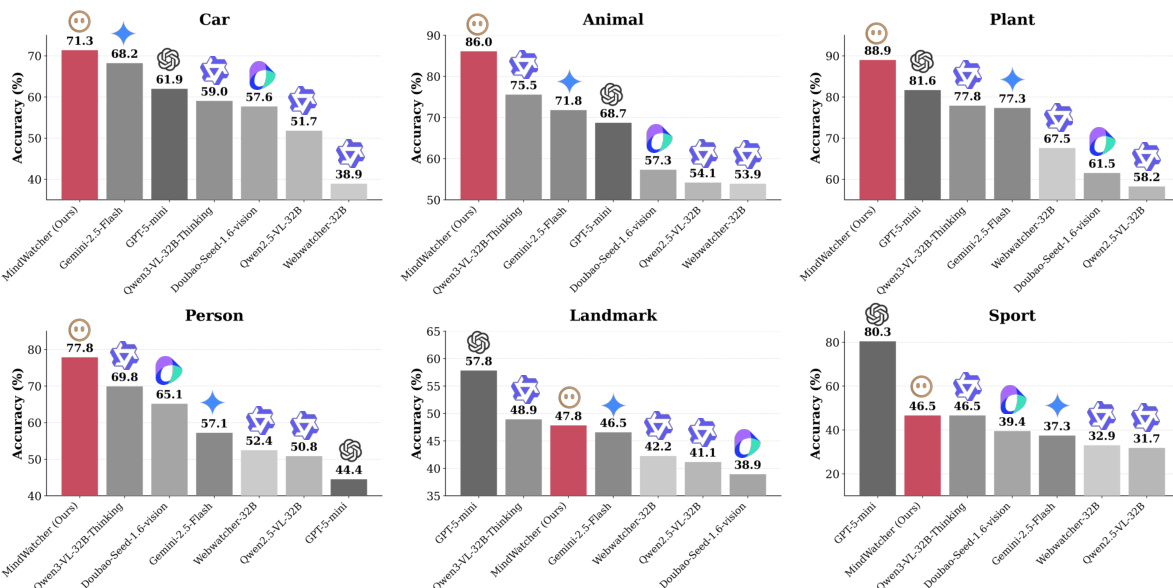
- On MWE-Bench, MindWatcher-32B surpasses Qwen3-VL 32B and demonstrates strong performance across four domains (Vehicle, Animal, Plant, Person), while distilled variants (MindWatcher-2B, 3B, 4B) match or exceed the base model performance, proving that agentic capabilities can compensate for limited parameter size.
- Tool integration dramatically boosts performance: Qwen3-VL 32B’s score nearly triples with tool access, and GPT-5 mini’s score in Sports jumps from 13.38 to 80.28, highlighting the critical role of external tools in overcoming internal knowledge limitations.
- On filtered benchmarks (MMSearch, SimpleVQA, WebWalkerQA), MindWatcher-32B achieves SOTA results across all, including outperforming Qwen3-VL 32B on SimpleVQA and remaining competitive on the pure-text WebWalkerQA, indicating successful enhancement of multimodal agentic reasoning without sacrificing text-based capabilities.
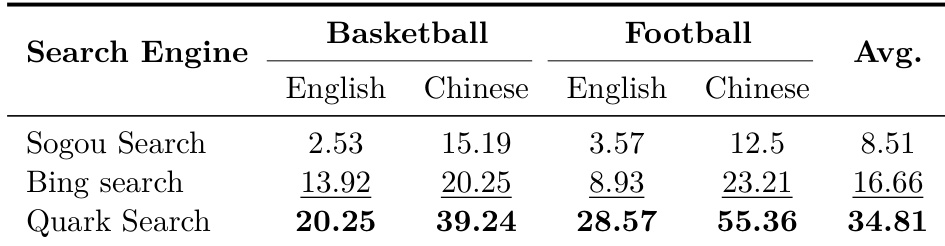
- The choice of search engine significantly impacts performance, with Quark outperforming Sogou by 42.86% on Chinese football queries, demonstrating that agent performance is highly sensitive to tool environment and not solely dependent on model architecture.
- Case studies reveal that internal world knowledge critically influences tool-use success: Qwen3-VL 32B leverages prior knowledge to formulate effective queries, while MindWatcher (based on Qwen2.5-VL) fails without such knowledge, showing that benchmark results can be confounded by long-tail knowledge disparities.
- Genetic inheritance analysis shows that both agentic RL and SFT preserve the base model’s cognitive ceiling: while RL enables stable, structured tool-use behavior with synchronized performance decay, SFT leads to volatile tool-call patterns and less consistent optimization, indicating RL’s superior alignment for complex reasoning.
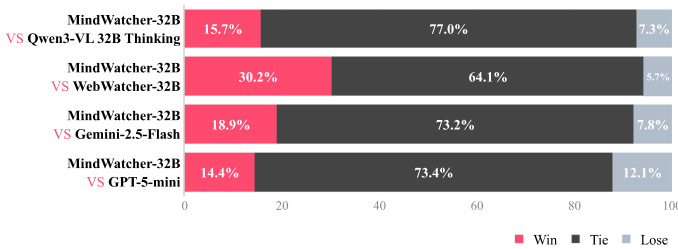
The authors use a win-tie-loss analysis to compare MindWatcher-32B against four models across public benchmarks and the MWE-Bench, showing that MindWatcher-32B consistently outperforms its 32B counterparts and achieves superior results compared to SOTA closed-source models like Gemini 2.5 Flash and GPT-5 mini. The results indicate that MindWatcher-32B wins in 15.7% of comparisons against Qwen3-VL 32B Thinking, 30.2% against WebWatcher-32B, 18.9% against Gemini 2.5-Flash, and 14.4% against GPT-5 mini, with the majority of outcomes being ties.
The authors use the MWE-Bench to evaluate the performance of MindWatcher distilled models against their foundation models across multiple domains. Results show that MindWatcher-2B, -3B, and -4B achieve significantly higher average scores than their respective base models, with MindWatcher-4B attaining the highest overall score of 69.63, demonstrating that the distilled models outperform their larger counterparts in most categories.
The authors use the provided bar charts to compare the performance of various models across six domains on the MWE-Bench, with MindWatcher-32B achieving the highest accuracy in four of them: Car, Animal, Plant, and Person. Results show that MindWatcher-32B outperforms prominent closed-source models such as Gemini 2.5 Flash and GPT-5 mini across all domains, demonstrating its superior agentic capabilities.
The authors use the MWE-Bench to evaluate model performance under direct inference and ReAct/Agent modes, showing that internal knowledge cutoffs do not consistently predict performance, as models like Gemini 2.5 Pro outperform more recent models in direct inference. Results show that tool-augmented inference significantly boosts performance, with MindWatcher-32B achieving the highest overall score of 75.35, outperforming both open-source and closed-source models across multiple domains.
Results show that the choice of search engine significantly impacts agent performance on sports-related queries, with Quark Search achieving the highest average score of 34.81 across all domains and languages. The performance varies substantially depending on the query domain and language, indicating that tool capacity is highly dependent on the specific context rather than being universally superior.