Command Palette
Search for a command to run...
L'hypothèse Prism : Harmonisation des représentations sémantiques et pixeliques par auto-encodage unifié
L'hypothèse Prism : Harmonisation des représentations sémantiques et pixeliques par auto-encodage unifié
Weichen Fan Haiwen Diao Quan Wang Dahua Lin Ziwei Liu
Résumé
Les représentations profondes à travers les modalités sont intrinsèquement imbriquées. Dans cet article, nous analysons de manière systématique les caractéristiques spectrales de divers encodeurs sémantiques et de pixels. De façon intéressante, notre étude met en évidence une correspondance particulièrement inspirante et peu explorée entre le spectre des caractéristiques d’un encodeur et son rôle fonctionnel : les encodeurs sémantiques captent principalement les composantes à basse fréquence, qui codent le sens abstrait, tandis que les encodeurs de pixels conservent en outre des informations à haute fréquence, qui véhiculent des détails fins. Ce constat heuristique offre une perspective unificatrice reliant le comportement des encodeurs à leur structure spectrale sous-jacente. Nous le formulons comme l’Hypothèse du Prisme, selon laquelle chaque modalité de données peut être vue comme une projection du monde naturel sur un spectre commun de caractéristiques, tout comme un prisme. À partir de cette insight, nous proposons Unified Autoencoding (UAE), un modèle qui harmonise la structure sémantique et les détails au niveau des pixels grâce à un modulateur innovant par bandes de fréquence, permettant ainsi leur coexistence fluide. Des expériences étendues sur les benchmarks ImageNet et MS-COCO confirment que notre UAE unifie efficacement l’abstraction sémantique et la fidélité au niveau des pixels dans un espace latent unique, atteignant des performances de pointe.
One-sentence Summary
Researchers from Nanyang Technological University and SenseTime Research propose Unified Autoencoding (UAE), introducing the Prism Hypothesis that semantic encoders capture low-frequency global meaning while pixel encoders retain high-frequency details. UAE innovates with a frequency-band modulator harmonizing these representations within one latent space, effectively unifying semantic abstraction and pixel fidelity for state-of-the-art performance on ImageNet and MSCOCO benchmarks.
Key Contributions
- The paper identifies a critical fragmentation in foundation models where semantic encoders (focused on high-level meaning) and pixel encoders (preserving fine details) operate separately, causing representational conflicts and reduced training efficiency due to heterogeneous feature spaces.
- It introduces the Prism Hypothesis, revealing that semantic encoders predominantly capture low-frequency spectral components for abstract meaning while pixel encoders retain high-frequency details, and proposes Unified Autoencoding (UAE) with a frequency-band modulator to harmonize these into a single latent space.
- Extensive validation on ImageNet and MSCOCO shows UAE achieves state-of-the-art performance across reconstruction (rFID, PSNR, gFID) and perception (Accuracy) tasks, outperforming contemporaries like RAE and SVG by effectively unifying semantic abstraction and pixel fidelity.
Introduction
The authors address a critical fragmentation in vision foundation models where semantic encoders (capturing high-level meaning) and pixel encoders (preserving visual detail) operate in separate, incompatible latent spaces. This separation forces downstream systems to reconcile heterogeneous representations, reducing training efficiency and causing representational conflicts that degrade performance in joint perception-generation tasks. Prior approaches either transfer semantic knowledge into generation pipelines—sacrificing fine detail recovery—or inject pixel-level awareness into semantic models through distillation and hierarchical features, achieving only partial integration via compromises rather than true unification.
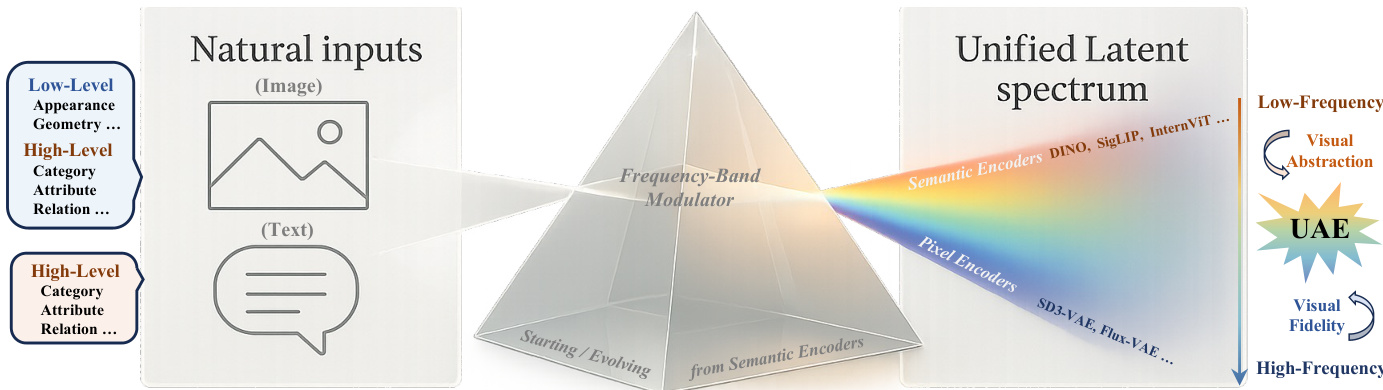
The authors introduce the Prism Hypothesis, which posits that natural inputs project onto a continuous frequency spectrum: low-frequency bands encode global semantics (e.g., categories and relations), while high-frequency bands capture local texture and geometry. Leveraging this insight, they propose Unified Autoencoding (UAE), a tokenizer that harmonizes semantic and pixel representations within a single latent space using a frequency-band modulator. This modulator explicitly factorizes content into a fundamental semantic band and residual pixel bands, enabling controllable detail reconstruction. UAE outperforms contemporary unified tokenizers like RAE, SVG, and UniFlow on ImageNet and MS-COCO across reconstruction (rFID, PSNR) and perception (gFID, accuracy) metrics, demonstrating that spectral factorization resolves the abstraction-fidelity tension without trade-offs.
Dataset
The authors use two primary datasets for training and evaluation:
- Training data: ImageNet-1K training set (standard 1.28M images), processed at 256x256 resolution. No additional filtering or cropping strategies are described beyond this resolution.
- Evaluation data:
- ImageNet-1K validation set (standard 50k images) for classification benchmarks.
- MS-COCO 2017 validation set for cross-dataset generalization tests.
Key implementation details:
- The model (UAE) trains exclusively on the ImageNet-1K training split, using DINOv2-B or DINOv2-L as semantic encoders.
- Training occurs in three stages:
- Decoder training with reconstruction loss (frozen encoder).
- Full-model fine-tuning with semantic-focused loss and reconstruction loss.
- End-to-end fine-tuning with noise injection and GAN loss (following RAE methodology).
- No dataset mixture ratios, metadata construction, or explicit preprocessing steps beyond resolution scaling are specified.
Method
The authors leverage the Prism Hypothesis to design Unified Autoencoding (UAE), a framework that unifies semantic abstraction and pixel-level fidelity within a single latent space by explicitly modeling the spectral decomposition of visual representations. The core insight is that natural inputs project onto a shared frequency spectrum, where low-frequency components encode semantic structure and high-frequency bands capture fine-grained visual detail. UAE operationalizes this by decomposing the latent representation into frequency bands and modulating them to preserve both global semantics and local fidelity.
Refer to the framework diagram, which illustrates how natural inputs—both image and text—are mapped through a frequency-band modulator into a unified latent spectrum. Semantic encoders such as DINOv2 or CLIP primarily occupy the low-frequency region, encoding visual abstraction, while pixel encoders like SD-VAE extend into higher frequencies to retain visual fidelity. UAE bridges these modalities by initializing its encoder from a pretrained semantic model and then expanding its spectral coverage through joint optimization.
The architecture begins with a unified encoder initialized from a pretrained semantic encoder (e.g., DINOv2), which processes the input image into a latent grid z∈RB×C×H×W. This latent is then decomposed into K frequency bands zf∈RB×K×C×H×W via an FFT Band Projector and an Iterative Split procedure. The projector applies a 2D discrete Fourier transform, partitions the spectrum using smooth radial masks Mk, and transforms each band back to the spatial domain. The iterative split ensures disentanglement: starting with r(0)=z, each band zf(k)=Pk(r(k)) is extracted, and the residual is updated as r(k+1)=r(k)−Pk(r(k)). This yields a multi-band latent representation where low bands encode global semantics and high bands capture edges and textures.
As shown in the figure below, the decomposed bands are processed by a frequency band modulator. During training, a noise injection module perturbs only the high-frequency bands using a binary mask m and Gaussian noise N(0,σ2I), enhancing decoder robustness. The processed bands are then concatenated along channels and passed through a spectral transform module—a two-layer convolutional block with SiLU activations—that predicts a residual Δ. The final fused latent q=Δ+∑k=0K−1b(k) maintains the original spatial dimensions and is fed into a ViT-based pixel decoder to reconstruct the RGB image.
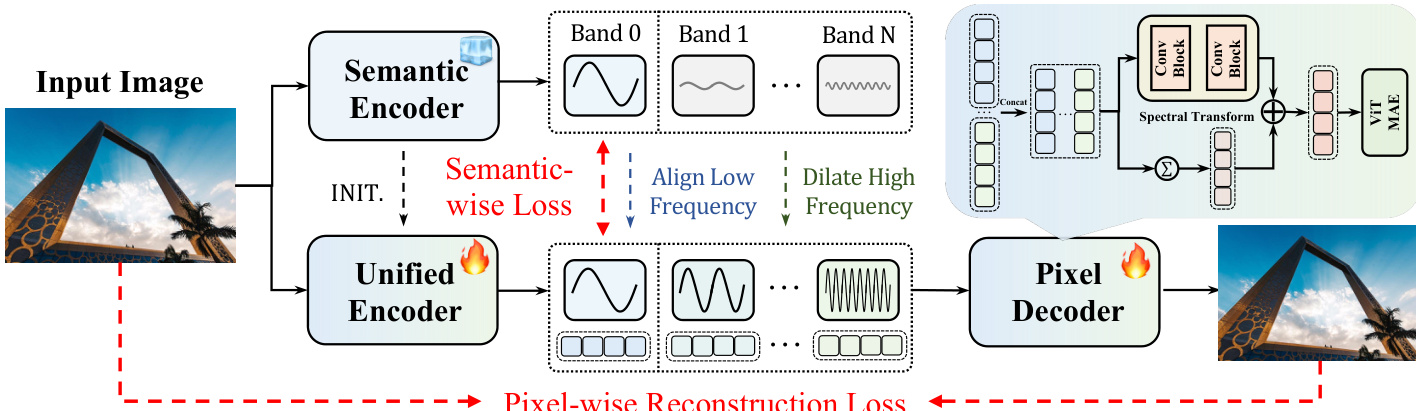
Training is guided by two complementary objectives. The semantic-wise loss enforces alignment between the unified encoder and the frozen semantic encoder only on the lowest Kbase bands (typically Kbase=1), computed as:
\mathcal{L}_{\mathrm{sem}} = \frac{\sum_{k=0}^{K_{\mathrm{base}} - 1} \| \mathbf{f}_{u}^{k} - \mathbf{f}_{s}^{k} \|_2^2}{K_{\mathrm{base}}} $$. This preserves the semantic layout inherited from the teacher while leaving higher bands free to learn pixel-level detail. Concurrently, a pixel-wise reconstruction loss—computed between the decoded output and the original image—ensures visual fidelity. The joint optimization harmonizes semantic structure and pixel detail within a single latent space, enabling UAE to unify modalities without sacrificing either abstraction or fidelity. # Experiment - Visual reconstruction: On ImageNet-1K with DINOv2-base, UAE achieved 29.65 PSNR and 0.19 rFID, surpassing RAE baseline (18.05 PSNR, 2.04 rFID) by over 90% in rFID reduction and matching Flux-VAE/SD3-VAE. On MS-COCO, it reached 29.23 PSNR and 0.18 rFID. Scaled to DINOv2-L, it attained 33.08 PSNR and 0.16 rFID, validating frequency-aware factorization for detail preservation. - Generative modeling: In class-conditional ImageNet generation, UAE achieved 1.68 gFID and 301.6 IS, matching state-of-the-art diffusion and autoregressive models by leveraging progressive low-to-high frequency generation. - Semantic understanding: Linear probing on ImageNet-1K yielded 83.0% top-1 accuracy with ViT-B, surpassing VFMTok (69.4%) and BEiT (73.5%), and matching larger models like UniFlow (82.6%), confirming strong semantic retention in the unified latent space. - Ablation studies: BandProjector, encoder tuning, and noise injection progressively improved PSNR from 15.27 to 29.65. Performance remained stable across 2-10 frequency bands (PSNR ~29, rFID 0.19, semantic accuracy 83.0%), demonstrating robustness to band granularity. The authors use UAE with DINOv2 encoders to achieve state-of-the-art reconstruction quality among unified tokenizers, significantly outperforming RAE in PSNR, SSIM, and rFID on both ImageNet-1K and MS-COCO 2017. When scaled to DINOv2-L, UAE attains the best overall fidelity and perceptual quality, demonstrating that frequency-aware factorization effectively preserves both semantic structure and fine visual detail. Results show UAE remains competitive with strong generative autoencoders like Flux-VAE and SD3-VAE while operating under the same encoder configurations. 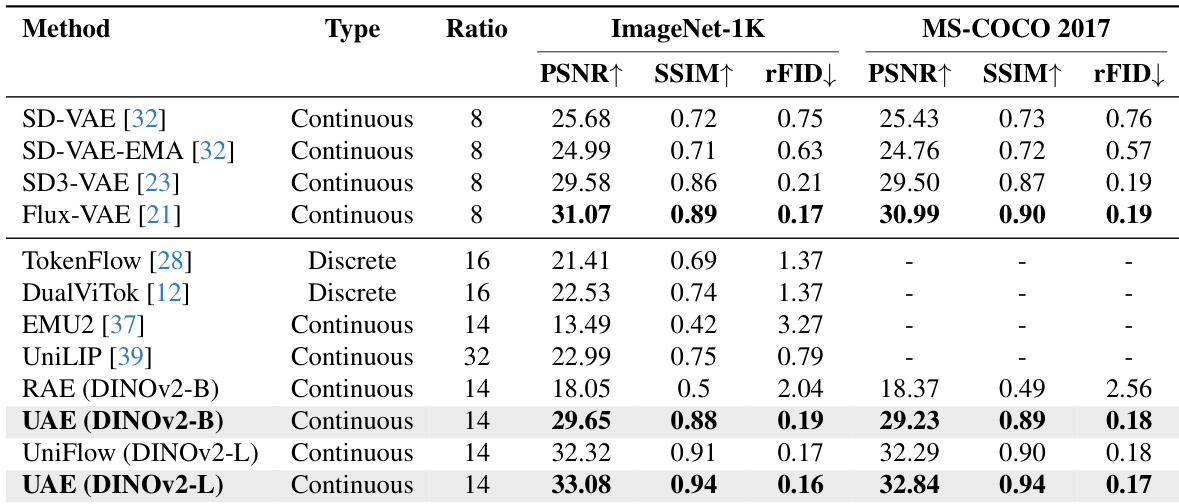 The authors progressively enhance reconstruction quality by adding components to a baseline model: BandProjector improves structure recovery, encoder tuning boosts fidelity and reduces rFID, and noise injection further refines perceptual quality, culminating in PSNR 29.65, SSIM 0.88, and rFID 0.19. Results show that frequency decomposition, semantic alignment, and noise regularization jointly enable high-fidelity reconstruction while preserving semantic structure. 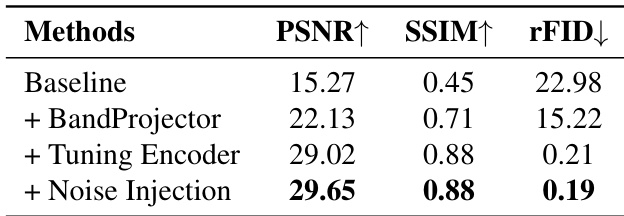 The authors evaluate UAE for class-conditional image generation on ImageNet at 256x256, comparing it against recent diffusion and autoregressive models. Results show UAE achieves a gFID of 1.68 and IS of 301.6, matching or exceeding baselines like UniFlow and RAE in generative quality while maintaining competitive precision and recall. This demonstrates that UAE’s frequency-based latent space supports effective generation without sacrificing semantic coherence. 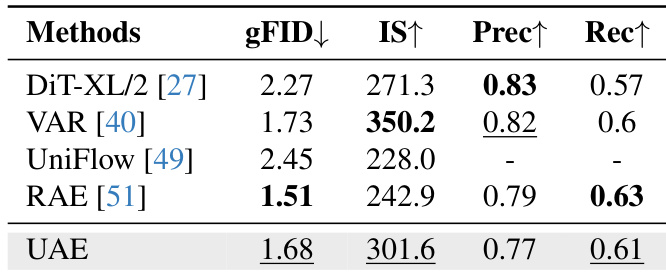 The authors evaluate semantic discriminability via linear probing on ImageNet-1K, showing that UAE achieves 83.0% top-1 accuracy with a ViT-B backbone. This matches RAE and surpasses larger ViT-L models like MAE, MAGE, and UniFlow, indicating UAE preserves strong semantic alignment despite its smaller size. 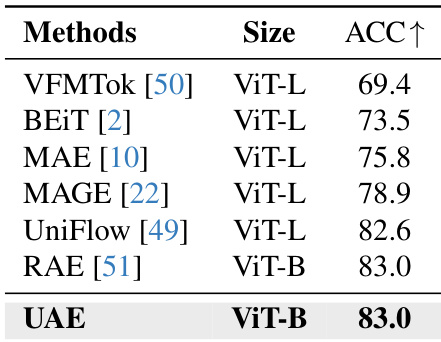 The authors evaluate semantic discriminability by linear probing on ImageNet-1K using different representations derived from DINOv2. Results show that using only the lowest-frequency band (Band₀) achieves slightly higher top-1 accuracy (83.3%) than the original DINOv2 features (83.0%) or the concatenated multi-band representation (83.0%), indicating that low-frequency components preserve dominant global semantic structure. 