Command Palette
Search for a command to run...
Peuvent les LLM prédire les difficultés des étudiants ? Alignement entre humains et IA sur la difficulté grâce à une simulation de compétence pour la prévision de la difficulté des items
Peuvent les LLM prédire les difficultés des étudiants ? Alignement entre humains et IA sur la difficulté grâce à une simulation de compétence pour la prévision de la difficulté des items
Ming Li Han Chen Yunze Xiao Jian Chen Hong Jiao Tianyi Zhou
Résumé
Une estimation précise de la difficulté des items (questions ou tâches) est essentielle pour l’évaluation éducative, mais elle souffre du problème du « démarrage froid ». Bien que les grands modèles linguistiques (Large Language Models) démontrent des capacités de résolution de problèmes supérieures à celles des humains, il reste une question ouverte quant à leur capacité à percevoir les difficultés cognitives auxquelles sont confrontés les apprenants humains. Dans ce travail, nous présentons une analyse empirique à grande échelle de l’alignement entre la difficulté perçue par les humains et celle perçue par les IA, portant sur plus de 20 modèles dans des domaines variés tels que les connaissances médicales et le raisonnement mathématique. Nos résultats révèlent une désalignement systématique : l’augmentation de la taille du modèle n’améliore pas de manière fiable cette correspondance. Au lieu de s’aligner sur les humains, les modèles convergent vers un consensus machine partagé. Nous observons que de hautes performances nuisent souvent à une estimation précise de la difficulté, car les modèles peinent à simuler les limites de compétence des élèves, même lorsqu’ils sont explicitement invités à adopter un niveau de maîtrise spécifique. En outre, nous identifions un manque critique d’autoréflexion : les modèles échouent à prédire leurs propres limites. Ces résultats suggèrent qu’une capacité générale de résolution de problèmes ne s’accompagne pas nécessairement d’une compréhension des difficultés cognitives humaines, mettant en évidence les défis liés à l’utilisation des modèles actuels pour la prédiction automatisée de la difficulté.
One-sentence Summary
Researchers from University of Maryland, Carnegie Mellon University, and University at Buffalo empirically analyze Human-AI Difficulty Alignment across 20+ large language models, revealing systematic misalignment where scaling model size fails to capture human cognitive struggles; instead, models converge toward machine consensus, and high performance impedes accurate difficulty estimation as they cannot simulate student limitations or self-assess, challenging their use in automated educational assessment despite problem-solving capabilities.
Key Contributions
- Accurate item difficulty estimation is critical for educational assessment but suffers from a cold start problem because new items lack historical response data, requiring expensive and time-consuming field testing with real students to calibrate difficulty parameters within frameworks like Item Response Theory.
- The authors introduce a large-scale empirical analysis of Human-AI Difficulty Alignment, evaluating over 20 LLMs across four educational domains by treating models as both external observers predicting student difficulty and internal actors experiencing difficulty themselves, while analyzing inter-model consensus, capability-perception gaps via Item Response Theory, and metacognitive alignment.
- Their findings reveal systematic misalignment where scaling model size does not improve human difficulty perception; instead, models converge toward a shared machine consensus and high-performing models fail to simulate student limitations or predict their own errors, with evidence from diverse domains including medical knowledge and mathematical reasoning.
Introduction
Accurate item difficulty estimation is essential for educational applications like adaptive testing and curriculum design but traditionally requires costly field testing with real students, creating a cold-start problem for new questions. Prior supervised learning approaches for item difficulty prediction depend on historical response data, making them ineffective for unseen items, while early LLM-based methods failed to address the fundamental misalignment between a model's problem-solving capability and its ability to perceive human-like cognitive struggles. The authors investigate Human-AI Difficulty Alignment by rigorously evaluating whether off-the-shelf LLMs can estimate difficulty through dual perspectives: as external observers predicting student struggles and as internal actors simulating lower-proficiency reasoning. Their contribution includes scaling this analysis across 20+ models and four educational domains while introducing metacognitive alignment and proficiency simulation to dissect the capability-perception gap beyond simple accuracy metrics.
Dataset
The authors address Human-AI Difficulty Alignment by curating four datasets with ground truth difficulty values from real student field testing, ensuring domain diversity and avoiding private/mixed-source discrepancies. Key details per subset:
- USMLE (Medical Knowledge): 667 high-stakes medical exam items sourced from NBME/FSMB. Difficulty uses continuous transformed p-values [0, 1.3], validated by field testing with 300+ medical students per item (Yaneva et al., 2024).
- Cambridge (Linguistic Proficiency): 793 English reading comprehension questions from Cambridge exams, requiring long-context inference. Difficulty uses rescaled IRT b-parameters [0, 100] as ground truth (Mullooly et al., 2023).
- SAT Reading & Writing (Verbal Reasoning): 1,338 standardized test questions after filtering out figure-dependent items. Difficulty uses discrete categories (Easy/Medium/Hard).
- SAT Math (Mathematical Logic): 1,385 algebra/geometry/data analysis questions, similarly filtered for text-only processing. Difficulty uses discrete categories (Easy/Medium/Hard).
The datasets serve exclusively as evaluation benchmarks—not training data—to test 20+ LLMs (including GPT-4o, Llama3.1, and reasoning-focused models) for alignment with real student performance. Processing involved:
- Removing visual/figure-dependent SAT questions to enforce text-only input.
- Direct use of provided difficulty metrics (continuous for USMLE/Cambridge; discrete for SAT subsets).
- No cropping beyond SAT filtering, with all subsets retaining original field-tested difficulty labels.
Method
The authors leverage a dual-modal evaluation framework to assess the alignment between human-assigned item difficulty and large language model (LLM) cognition. The framework operates across two distinct roles: as an observer estimating difficulty (Difficulty Perception) and as an actor solving problems (Problem-Solving Capability). Each role is conditioned on a proficiency prompt that simulates varying levels of student expertise, enabling a granular analysis of how model behavior shifts under different cognitive assumptions.
In the Observer View, the model is provided with the full item context xi, the ground truth answer ai∗, and an optional proficiency prompt p. The model generates a natural language response via Genm(xi,ai∗,p), which is then parsed into a normalized numerical difficulty score y^i,m using a function ϕ(⋅). This setup isolates the model’s explicit perception of difficulty from its actual problem-solving ability. The proficiency prompts are designed to simulate low, medium, or high student proficiency, as shown in the prompt templates for difficulty prediction across domains such as USMLE, Cambridge English, SAT Reading, and SAT Math.



In the Actor View, the model operates in a zero-shot setting without access to the correct answer. It generates a solution a^i,m=ψ(Genm(xi,p)), where ψ(⋅) extracts the final answer from the generated text. The binary correctness vi,m is then computed as I(a^i,m=ai∗). This mode evaluates the model’s intrinsic capability to solve items under the simulated proficiency condition.
To quantify alignment, the authors employ Spearman’s Rank Correlation (ρ) as a unified metric. For Perception Alignment (ρpred), they compute the correlation between the model’s predicted difficulty scores y^i,m and human ground truth yi. For Capability Alignment (ρirt), they treat the ensemble of models M as a synthetic examinee population and fit a Rasch Model to derive an empirical machine difficulty βi for each item. The probability of model m answering item i correctly is modeled as:
P(vi,m=1∣θm,βi)=1+exp(−(θm−βi))1where θm represents the model’s latent ability and βi the item’s intrinsic machine difficulty, estimated via Marginal Maximum Likelihood. The final Capability Alignment is then computed as the Spearman correlation between βi and yi.
The proficiency simulation is implemented through four distinct configurations: baseline (no proficiency), low, medium, and high. Each configuration is instantiated via system-level prompts that condition the model’s generation process. For example, in the low-proficiency setting, the model is instructed to simulate a “weak student” with limited subject mastery, while in the high-proficiency setting, it assumes the role of a “good student” with high proficiency. These prompts are tailored per domain and task, as illustrated in the templates for question answering.



This structured approach enables a systematic investigation into how LLMs perceive and perform on educational items under varying cognitive assumptions, providing a comprehensive view of Human-AI Difficulty Alignment.
Experiment
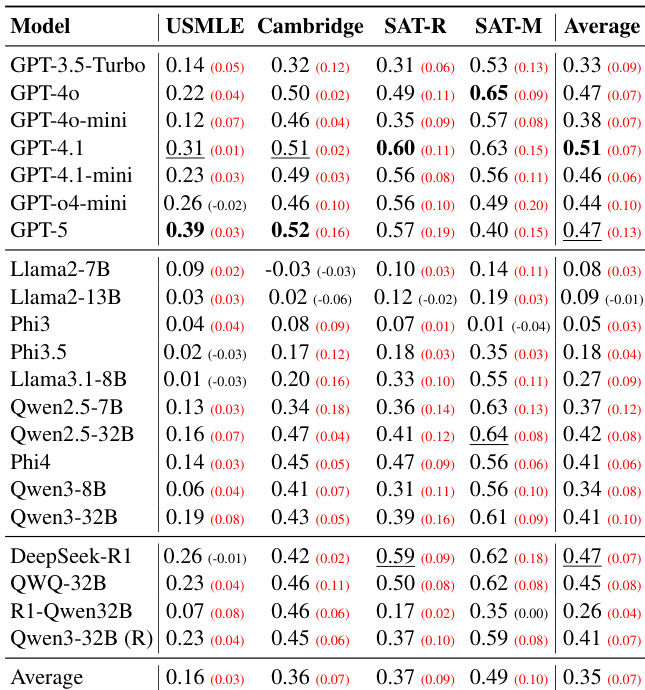
- Systematic misalignment validated across medical (USMLE) and reasoning (SAT Math) domains: scaling model size worsens human-AI difficulty alignment, with Spearman's ρ averaging below 0.50 (USMLE ρ≈0.13, SAT Math ρ≈0.41), as models converge toward machine consensus rather than human perception.
- Limits of simulation confirmed: ensemble methods show bounded gains (e.g., USMLE ensemble immediately degrades with weaker models), while proficiency prompting yields inconsistent results; GPT-5 improved alignment to ρ=0.47 from baseline 0.34 only via persona-averaging, not authentic student simulation.
- The curse of knowledge demonstrated via IRT analysis: model-derived difficulty correlates worse with humans than explicit estimates, with high Savant Rates (70.4% on USMLE) showing models solve most human-difficult items trivially, and proficiency prompts minimally altering accuracy (<1% change).
- Metacognitive blindness identified: AUROC scores near 0.55 (random) reveal models cannot predict their own errors, with even GPT-5 achieving only 0.73 on Cambridge dataset, indicating decoupled self-awareness.
The authors evaluate 21 large language models on their ability to estimate item difficulty across four educational domains, finding that model scale does not consistently improve alignment with human difficulty perception. Results show moderate to weak Spearman correlations, with the highest average score of 0.67 achieved by GPT-5, and notable domain sensitivity—SAT Math exhibits the strongest alignment while USMLE shows the weakest. Models exhibit a systematic misalignment, converging toward a shared machine consensus rather than reflecting human cognitive struggle.
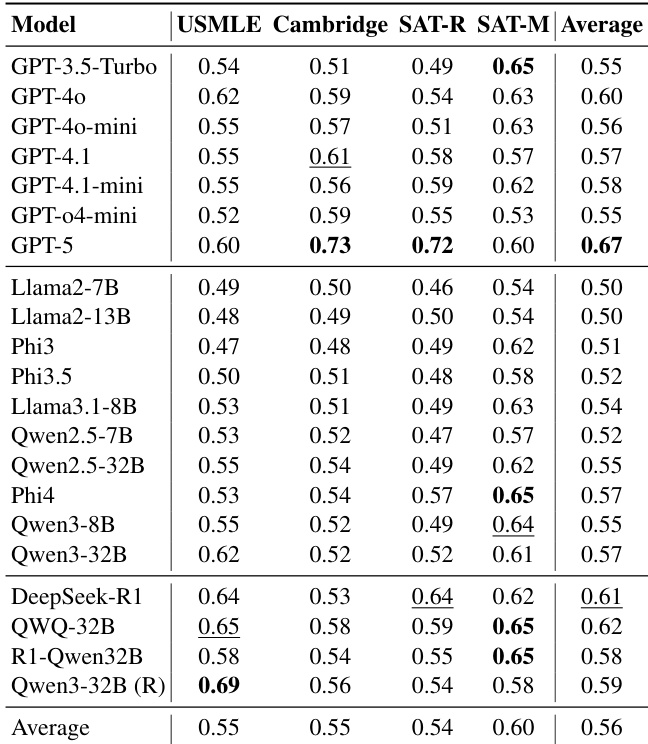
The authors evaluate 21 large language models on their ability to estimate item difficulty across four educational domains, finding that alignment with human difficulty rankings remains weak, with average Spearman correlations below 0.50. Scaling model size does not reliably improve alignment; instead, models exhibit stronger agreement with each other than with human reality, forming a machine consensus that systematically diverges from student experience. Even high-performing models like GPT-4.1 and DeepSeek-R1 show limited gains, and domain-specific performance varies widely, with particularly poor alignment in knowledge-intensive tasks like USMLE.
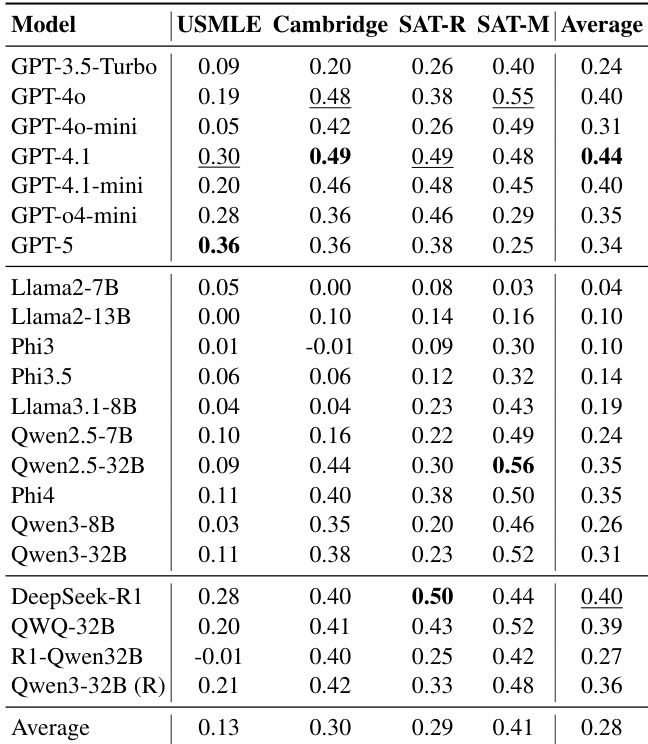
The authors evaluate 21 large language models across four domains using zero-shot item difficulty prediction, finding that model scale does not reliably improve alignment with human difficulty perceptions. Results show that even top-performing models like GPT-5 and DeepSeek-R1 exhibit only modest gains under persona prompting, with most models converging toward a machine consensus that diverges from human reality. Across domains, alignment remains weak—particularly in knowledge-intensive tasks like USMLE—while reasoning domains like SAT Math show slightly better but still limited correlation, underscoring a persistent gap between model capability and human cognitive modeling.
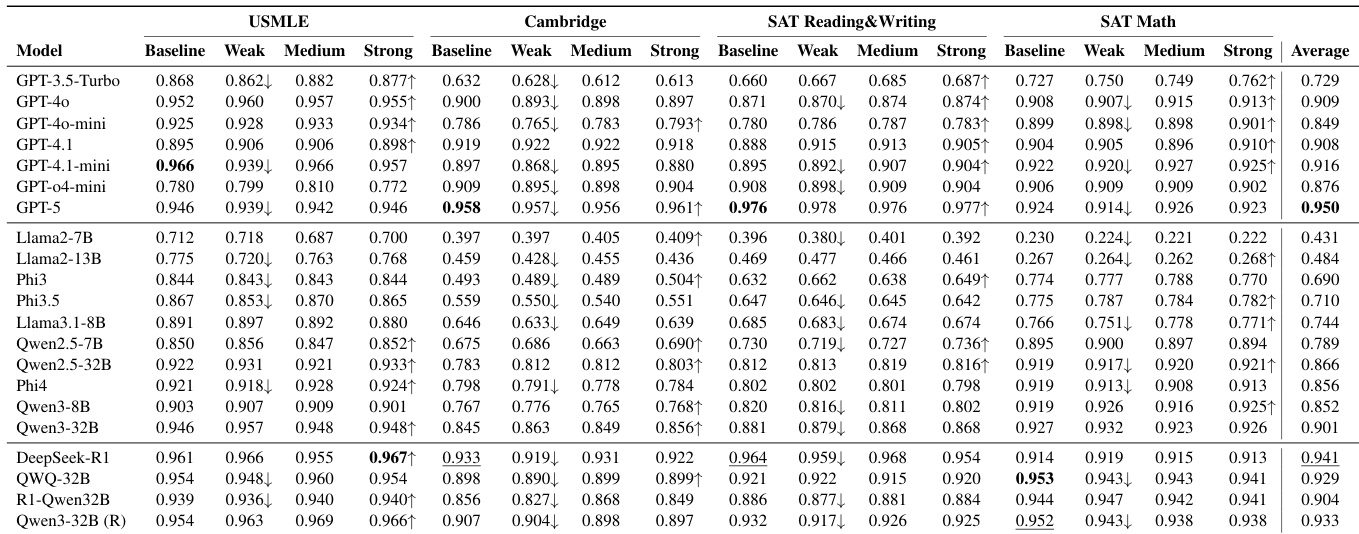
The authors evaluate 20+ LLMs on zero-shot item difficulty prediction across four domains, finding that larger or more capable models do not consistently align better with human difficulty perceptions. Results show systematic misalignment, with models forming a cohesive machine consensus that diverges from human reality, and performance varies significantly by domain—SAT Math shows the highest alignment while USMLE shows the lowest. Scaling model size or using proficiency prompts does not reliably improve alignment, and even top models like GPT-5 underperform relative to mid-tier baselines such as GPT-4.1.
The authors use Item Response Theory to quantify cognitive divergence between human and model difficulty perceptions, revealing that models frequently find human-difficult items trivial, especially in knowledge-intensive domains like USMLE where 70.4% of hard human items are easily solved by models. Results show high saturation rates across domains, indicating models overestimate student capability, and minimal brittleness, suggesting models rarely fail on items humans find easy. This systematic misalignment persists even when models are prompted to simulate lower proficiency, underscoring their inability to authentically replicate human cognitive limitations.