Command Palette
Search for a command to run...
InsertAnywhere : Connecter la géométrie 4D de la scène et les modèles de diffusion pour une insertion d’objet vidéo réaliste
InsertAnywhere : Connecter la géométrie 4D de la scène et les modèles de diffusion pour une insertion d’objet vidéo réaliste
Hoiyeong Jin Hyojin Jang Jeongho Kim Junha Hyung Kinam Kim Dongjin Kim Huijin Choi Hyeonji Kim Jaegul Choo
Résumé
Les avancées récentes dans la génération vidéo fondée sur les modèles de diffusion ont ouvert de nouvelles perspectives pour l’édition vidéo contrôlable, mais l’insertion d’objets vidéo réalistes (VOI) demeure un défi en raison d’une compréhension limitée des scènes 4D et d’un traitement insuffisant des effets d’occlusion et d’éclairage. Nous présentons InsertAnywhere, un nouveau cadre pour l’insertion d’objets vidéo qui permet un placement géométriquement cohérent et une synthèse d’apparence fidèle. Notre méthode commence par un module de génération de masques conscient du dimension 4, qui reconstruit la géométrie de la scène et propage la position de l’objet spécifiée par l’utilisateur à travers les trames tout en préservant la cohérence temporelle et la cohérence d’occlusion. À partir de cette base spatiale, nous étendons un modèle de génération vidéo basé sur la diffusion afin de synthétiser conjointement l’objet inséré et les variations locales environnantes, telles que l’éclairage et les ombres. Pour permettre un apprentissage supervisé, nous introduisons ROSE++, un jeu de données synthétique sensible à l’éclairage, construit en transformant le jeu de données ROSE pour la suppression d’objets en triplets composés d’une vidéo sans objet, d’une vidéo avec objet et d’une image de référence générée par un modèle de langage-visuel (VLM). À travers des expériences approfondies, nous démontrons que notre cadre produit des insertions d’objets géométriquement plausibles et visuellement cohérentes dans divers scénarios du monde réel, surpassant significativement les modèles existants, tant scientifiques que commerciaux.
One-sentence Summary
The authors from KAIST AI and SK Telecom propose InsertAnywhere, a diffusion-based video object insertion framework that integrates 4D scene understanding with illumination-aware synthesis, enabling geometrically consistent and appearance-faithful object placement across complex motions and viewpoints, outperforming prior methods in real-world production scenarios.
Key Contributions
-
We introduce a 4D-aware mask generation module that reconstructs scene geometry from input videos and propagates user-specified object placement across frames, ensuring geometric consistency, temporal coherence, and accurate handling of occlusions even under complex camera motions.
-
Our framework extends a diffusion-based video generation model to jointly synthesize the inserted object and its surrounding local variations—such as lighting, shading, and reflections—by leveraging a geometry-aware mask sequence and context-aware diffusion priors.
-
We construct ROSE++, a novel illumination-aware synthetic dataset by augmenting the ROSE object-removal dataset with VLM-generated reference images, enabling supervised training through an inverted object removal task and demonstrating superior performance over existing research and commercial models.
Introduction
The authors leverage 4D scene understanding and diffusion-based video generation to enable realistic video object insertion (VOI), a critical capability for applications in film post-production and commercial advertising where objects must be seamlessly integrated into dynamic scenes with geometric accuracy and visual fidelity. Prior work struggles with inconsistent object placement due to limited 4D scene modeling and fails to handle occlusions and lighting variations, especially when inserting objects into complex, moving scenes. The main contribution is InsertAnywhere, a framework that first uses a 4D-aware mask generation module to reconstruct scene geometry and propagate object masks across frames with temporal coherence, even under occlusions. It then extends a diffusion model to jointly synthesize the inserted object and its surrounding local variations—such as lighting and shading—by training on ROSE++, a novel synthetic dataset constructed by augmenting object removal videos with VLM-generated reference images to invert the removal task into insertion. This enables high-fidelity, appearance-consistent video generation suitable for production use.
Dataset
- The ROSE++ dataset is a synthetic, illumination-aware dataset created for training Video Object Insertion (VOI) models, comprising four key components: an object-removed video, an object-present video, a corresponding object mask video, and a reference object image.
- It is derived from the original ROSE dataset, which was designed for object removal and includes object-present videos, object masks, and object-removed videos where both the object and its side effects (shadows, reflections, illumination changes) are erased.
- To enable VOI training, the authors restructure the ROSE dataset by using the object-removed video as the source and the object-present video as the target, forming supervised training pairs.
- Since the original ROSE dataset lacks explicit reference object images, the authors introduce a VLM-based object retrieval pipeline: for each video, they sample n frames containing the target object, extract object regions, and feed these multi-view crops along with a text prompt to a Vision-Language Model (VLM) to generate m candidate object images on a white background.
- The candidate images are ranked using a DINO-based similarity metric that compares each generated image to the original object crops from the video frames; the image with the highest average similarity score is selected as the final reference object image.
- This approach ensures contextual alignment and avoids the copy-and-paste artifacts common in prior methods that directly crop objects from video frames, maintaining consistent input conditions between training and inference.
- The dataset is used in training with a mixture of different video types and object categories, with training splits carefully balanced to cover diverse scenes and object appearances.
- During training, the authors apply a cropping strategy that extracts object regions from multiple frames to provide multi-view context for the VLM, enhancing the quality and consistency of generated reference images.
- Metadata for each sample includes scene type, object category, and frame-level mask annotations, supporting fine-grained evaluation and analysis.
- For evaluation, the authors introduce VOIBench, a benchmark of 50 video clips spanning indoor, outdoor, and natural environments, each containing two objects. Contextually relevant objects are crawled for each scene, resulting in 100 total evaluation videos.
- Evaluation metrics include Subject Consistency (CLIP-I, DINO-I), Video Quality (VBench: Image Quality, Background/Subject Consistency, Motion Smoothness), and Multi-View Consistency under occlusion conditions.
Method
The authors present a two-stage framework for realistic video object insertion (VOI) that combines 4D scene understanding with diffusion-based video synthesis. The overall architecture, depicted in the framework diagram, consists of a 4D-aware mask generation stage followed by a video object insertion stage. The first stage generates a temporally consistent and geometrically accurate mask sequence that encodes the object's position, scale, and occlusion relationships within the scene. This mask sequence is then used to condition a diffusion-based video generator in the second stage, enabling the synthesis of photorealistic videos where the inserted object integrates naturally with the scene's lighting, shadows, and motion.
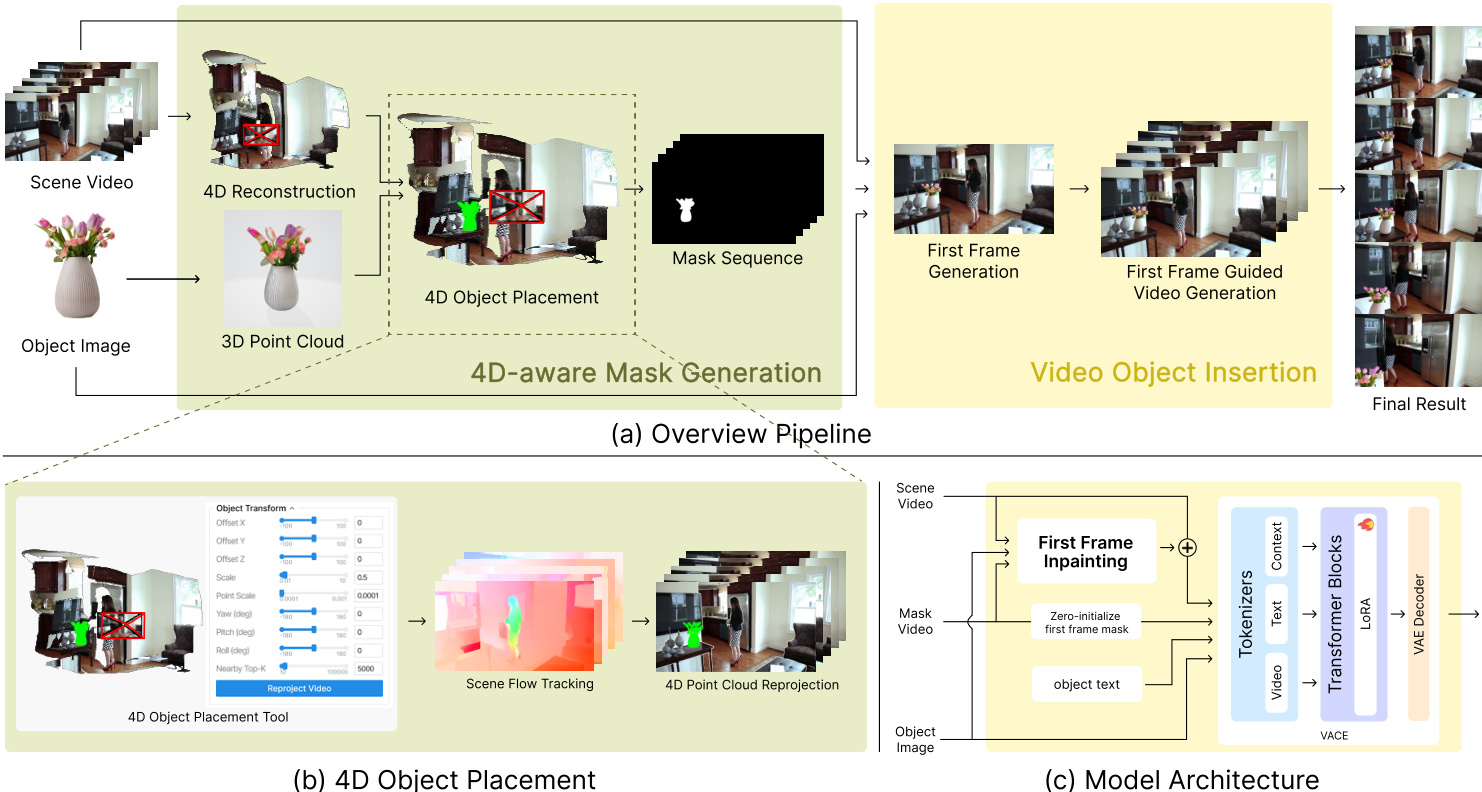
The 4D-aware mask generation stage begins with a 4D scene reconstruction of the input video. This reconstruction, which builds upon the Uni4D paradigm, jointly estimates per-frame geometry and camera motion by integrating predictions from multiple pretrained vision models, including depth estimation, optical flow, and segmentation networks. The reconstructed 4D scene provides a robust spatio-temporal representation of the environment. The user then interacts with a 3D-reconstructed scene, typically corresponding to the first frame, to place and scale the reference object. The object image is converted into a 3D point cloud using a pretrained single-view reconstruction network. This point cloud is aligned to the reconstructed scene through a rigid transformation, which is controlled via an interactive interface to precisely adjust the object's position, orientation, and size relative to the scene geometry.

To ensure temporal consistency, the object's motion is propagated across frames using the scene flow. The dense optical flow field of the scene is estimated using SEA-RAFT, and the motion of the object is refined by computing the average 3D motion vectors of the K nearest 3D points around the object in the first frame. This scene flow-based propagation updates the object's centroid and ensures that the inserted object moves in a physically plausible manner, synchronized with the surrounding scene dynamics. After propagation, each 3D point of the object is reprojected onto the image plane of each frame using the estimated camera intrinsics and extrinsics. This camera-aligned reprojection step accounts for camera motion, parallax, and occlusion, producing a geometrically consistent silhouette for each frame. The resulting synthetic video sequence is processed by a segmentation model to extract a temporally aligned binary mask sequence, which serves as a geometry-aware and temporally consistent spatial condition for the video generation stage.
The video object insertion stage leverages a pretrained image object insertion model as a strong prior to guide the synthesis of the final video. The authors fine-tune a video diffusion model using a LoRA module for efficient adaptation, preserving the model's pretrained video generation capabilities while improving its adaptability to object-insertion scenarios. The model architecture, shown in the diagram, first generates the initial frame with high fidelity to establish the object's appearance and lighting conditions. This visual reference is then propagated throughout the subsequent video generation process to maintain consistent color, texture, and lighting. The model is trained on the ROSE++ dataset, which enables it to learn illumination and shadow-aware behaviors by providing explicit supervision for geometric and illumination relationships, allowing for the synthesis of soft shadows and material-dependent shading.
Experiment
- Qualitative results show that InsertAnywhere outperforms Pika Pro and Kling in object fidelity and occlusion handling, with the 4D-aware mask enabling robust performance in complex scenarios like object movement behind hands.
- Quantitative results on Table 3 demonstrate that InsertAnywhere achieves the highest CLIP-I and DINO-I scores, indicating superior subject consistency, and excels in overall video quality and multi-view consistency, while baselines introduce background artifacts.
- Ablation study confirms that the 4D-aware mask is critical for occlusion handling, first-frame inpainting improves initial object identity, and LoRA fine-tuning on ROSE++ enhances photometric consistency, enabling realistic lighting and shadow generation.
- User study (Table 4) shows strong preference for InsertAnywhere across all criteria, including object realism, lighting consistency, occlusion integrity, and overall naturalness, with higher vote percentages than baselines.
- On the ROSE++ dataset, LoRA fine-tuning enables the model to dynamically adapt object illumination and shadow formation to scene lighting, significantly improving VBench scores and physical plausibility.
The authors use a quantitative evaluation to compare their method with baselines on subject and video quality metrics. Results show that their approach achieves the highest scores in subject consistency and multi-view consistency, while also outperforming others in background consistency and imaging quality, indicating superior overall video realism and object fidelity.

Results show that the proposed method achieves higher multi-view consistency compared to the baseline using random-frame references, with a score of 0.5857 versus 0.5295. This improvement demonstrates the effectiveness of the VLM-based object generation in capturing spatio-temporal structure and preventing occlusion-related inconsistencies.

The authors use an ablation study to evaluate the impact of different components in their framework, with the table showing quantitative results across subject consistency, video quality, and multi-view consistency metrics. Results show that their full method, labeled "Ours," achieves the highest scores in all evaluated metrics compared to configurations with fewer components, demonstrating the effectiveness of their 4D-aware mask, first-frame inpainting, and LoRA fine-tuning with the ROSE++ dataset.

The authors use a user study to evaluate the performance of their method against baselines, with results shown in the table. Results show that their method achieves significantly higher scores across all evaluation criteria, particularly in object realism, occlusion integrity, and overall naturalness, demonstrating superior realism and consistency in video object insertion.
