Command Palette
Search for a command to run...
DataFlow : un cadre piloté par LLM pour la préparation unifiée des données et l'automatisation des flux de travail à l'ère de l'intelligence artificielle centrée sur les données
DataFlow : un cadre piloté par LLM pour la préparation unifiée des données et l'automatisation des flux de travail à l'ère de l'intelligence artificielle centrée sur les données
Résumé
La demande croissante de données de haute qualité pour les grands modèles linguistiques (LLM) a renforcé l’urgence de mettre en place des pipelines de préparation de données évolutifs, fiables et riches sémantiquement. Toutefois, les pratiques actuelles restent largement dominées par des scripts ad hoc et des workflows mal spécifiés, manquant de notions abstraites rigoureuses, entravant la reproductibilité et offrant un soutien limité à la génération de données intégrant le modèle dans la boucle (model-in-the-loop). Pour relever ces défis, nous présentons DataFlow, un cadre unifié et extensible pour la préparation de données piloté par les LLM. Conçu autour d’abstractions au niveau du système, DataFlow permet des transformations de données modulaires, réutilisables et composites, et propose une API de construction de pipelines inspirée de PyTorch, permettant de concevoir des flux de données vérifiables et optimisables. Le cadre comprend près de 200 opérateurs réutilisables et six pipelines généraux applicables à divers domaines : texte, raisonnement mathématique, code, Text-to-SQL, RAG agencé, et extraction de connaissances à grande échelle. Pour améliorer encore l’accessibilité, nous introduisons DataFlow-Agent, qui traduit automatiquement des spécifications en langage naturel en pipelines exécutables grâce à une synthèse d’opérateurs, une planification de pipeline et une vérification itérative. Sur six cas d’usage représentatifs, DataFlow améliore de manière cohérente les performances des LLM en aval. Nos pipelines dédiés aux mathématiques, au code et au texte surpassent des jeux de données humains soigneusement curatés ainsi que des bases de données synthétiques spécialisées, atteignant une précision d’exécution maximale de +3 % en Text-to-SQL par rapport à SynSQL, +7 % d’amélioration moyenne sur les benchmarks de code, et des gains de 1 à 3 points sur MATH, GSM8K et AIME. En outre, un jeu de données unifié de 10 000 échantillons produit par DataFlow permet à des modèles de base de dépasser leurs homologues entraînés sur 1 million d’échantillons de données Infinity-Instruct. Ces résultats démontrent que DataFlow constitue une base pratique, performante et fiable pour la préparation de données des LLM, à la fois reproductible et évolutible, et établit une fondation au niveau du système pour le développement futur de l’IA centrée sur les données.
One-sentence Summary
Peking University, Shanghai Artificial Intelligence Laboratory, and LLaMA-Factory Team propose DataFlow, a unified LLM-driven framework for data preparation featuring system-level abstractions, a PyTorch-style API, and nearly 200 reusable operators across six domains. Its DataFlow-Agent translates natural language specifications into executable pipelines, consistently improving LLM performance while enabling small datasets to surpass models trained on 1M samples through semantic-rich synthesis and refinement.
Key Contributions
- Current LLM data preparation relies on ad-hoc scripts lacking reproducibility and model-in-the-loop support, while existing big-data frameworks like Apache Spark fail to handle semantic text operations efficiently for unstructured data. DataFlow addresses this with a unified framework featuring modular, reusable operators and a PyTorch-style API for debuggable pipelines, plus DataFlow-Agent for natural-language-to-pipeline translation via operator synthesis.
- The framework integrates nearly 200 operators and six domain-general pipelines for text, math, code, Text-to-SQL, agentic RAG, and knowledge extraction, enabling scalable and semantically rich data transformations. It supports model-in-the-loop processing and GPU-efficient batching, overcoming limitations of traditional ETL systems in handling token-level operations and semantic cleaning.
- Evaluated across six use cases, DataFlow pipelines outperformed human-curated datasets and specialized baselines, achieving up to +3% Text-to-SQL accuracy over SynSQL, +7% average gains on code benchmarks, and 1–3 point improvements on MATH, GSM8K, and AIME. A unified 10K-sample dataset generated by DataFlow enabled base models to surpass those trained on 1M Infinity-Instruct samples.
Introduction
The growing scale of large language models intensifies the need for high-quality, diverse training data, as poor data quality or limited diversity directly impairs model generalization and amplifies distributional biases. Existing data preparation relies on ad-hoc scripts or big-data frameworks like Spark, which lack native support for semantic operations, model-in-the-loop processing, and unstructured text transformations, forcing manual implementation of critical steps like deduplication or safety filtering and hindering reproducibility. The authors introduce DataFlow, a unified LLM-driven framework featuring system-level abstractions for modular data transformations, a PyTorch-style API, and nearly 200 reusable operators across six domain pipelines. They further develop DataFlow-Agent to auto-generate pipelines from natural language specifications. Evaluated on six tasks, DataFlow consistently boosts LLM performance—exceeding human-curated datasets with gains up to +7% on code benchmarks and enabling base models trained on its 10K-sample output to surpass those using 1M samples of prior art—establishing a reproducible foundation for scalable data-centric AI.
Dataset
The authors construct domain-specific synthetic datasets using the DATAFLOW framework across multiple reasoning tasks. Key details per subset:
-
Math Reasoning (DATAFLOW-REASONING-10K)
- Size/Source: 10K samples derived from NuminaMath seed dataset.
- Filtering: Candidate problems validated via MathQ-Verify to remove incorrect/ambiguous entries; CoT traces generated using DeepSeek-R1.
- Usage: Fine-tunes Qwen2.5-32B-Instruct (1–2 epochs) against Open-R1/Synthetic-1 baselines. Evaluated on 8 math benchmarks (e.g., GSM8K, MATH).
- Processing: Temperature=0.6/top-k=20 for AIME problems; temperature=0 otherwise. Omits seed pre-verification (NuminaMath pre-curated).
-
Code Generation (DATAFLOW-CODE-1K/5K/10K)
- Size/Source: 1K–10K samples from 20K Ling-Coder-SFT seeds.
- Filtering: Pipeline-refined for high-quality code instructions; compared against Code Alpaca/SC2-Exec-Filter baselines.
- Usage: Full-parameter SFT for Qwen2.5-7B/14B-Instruct. Evaluated on 4 code benchmarks (e.g., HumanEval, LiveCodeBench).
-
Text-to-SQL (DATAFLOW-TEXT2SQL-90K)
- Size/Source: 89.5K instances from Spider-train (37.5K), BIRD-train (37.5K), and EHRSQ-train (14.5K).
- Filtering: Ensures SQL syntactic/semantic diversity; includes natural language questions, SQL queries, and CoT traces.
- Usage: Fine-tunes models exclusively on synthesized data. Evaluated via greedy decoding or 8-sample majority voting across 6 benchmarks.
-
Agentic RAG (DATAFLOW-AGENTICRAG-10K)
- Size/Source: 10K multihop questions from Wikipedia (excluding test-benchmark documents).
- Filtering: Removes samples with logical errors, leakage, or inappropriate difficulty via verification module.
- Usage: Trains Qwen2.5-7B-Instruct with GRPO RL; E5-base-v2 retriever (top-k=5). Evaluated against 2WikiMultiHopQA/Musique.
-
Medical Knowledge (DATAFLOW-KNOWLEDGE)
- Size/Source: 140M tokens from medical textbooks (MedQA Books), StatPearls articles (9.3K), and clinical guidelines (45.7K).
- Filtering: Text normalization (MinerU), noise filtering, factuality-aware QA synthesis.
- Usage: Fine-tunes Qwen2.5-7B-Instruct (37.5K steps/5 epochs). Evaluated on PubMedQA/Covert/PubHealth.
-
Multimodal Instruction (DATAFLOW-INSTRUCT-10K)
- Composition: Combined 10K corpus (3K math, 2K code, 5K general instructions).
- Sources: Math (MATH seed), code (LingoCoder SFT), text (Condor Generator + Refiner).
- Usage: Full-parameter SFT for Qwen2-7B/2.5-7B; compared against Infinity-Instruct baselines. Evaluated on math, code, and knowledge benchmarks (MMLU/C-Eval).
Method
The authors leverage a unified, modular architecture to standardize LLM-driven data preparation, centering the framework around a core execution engine and an intelligent agentic layer for automated pipeline construction. The system’s design prioritizes programmability, extensibility, and backend-agnostic operation, enabling users to compose, debug, and optimize data workflows with minimal boilerplate.
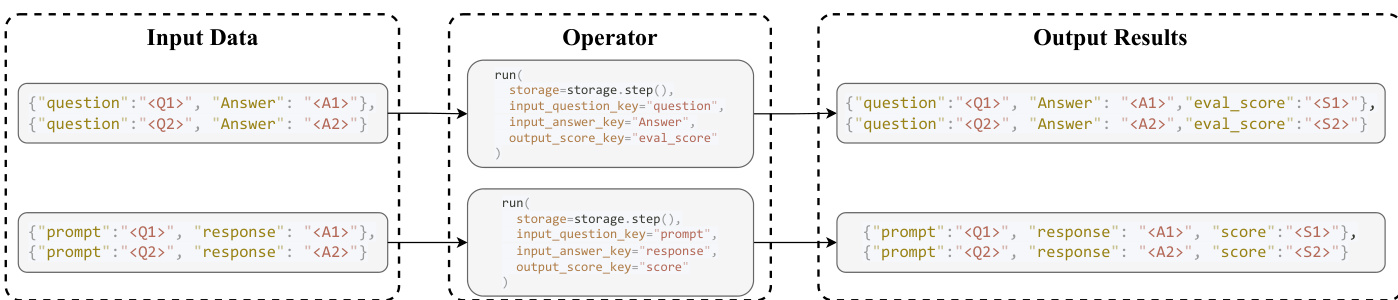
At the foundation lies the DataFlow-Core, which provides abstractions for storage, LLM serving, operators, and prompt templates. The storage layer maintains a canonical tabular representation of datasets, decoupling data management from transformation logic. Operators interact with this layer through a minimal, backend-agnostic API that exposes read() and write() operations, ensuring that intermediate artifacts are immediately available to subsequent stages. This read-transform-write paradigm, as illustrated in the operator interaction diagram, enables flexible composition and reordering without modifying operator internals. The default storage implementation uses Pandas, supporting common formats such as JSONL, Parquet, and CSV.
LLM-driven operators rely on a unified serving API that abstracts over heterogeneous backends, including local inference engines like vLLM and SGLang, as well as online APIs such as ChatGPT and Gemini. The serving interface exposes a single entry point, generate_from_input(), which accepts prompts and optional parameters like system_prompt or json_schema to enable structured prompting and decoding. This abstraction shields operators from backend-specific concerns such as batching, retry logic, and rate limiting, facilitating flexible substitution of LLM engines to evaluate their impact on data quality.
Operators themselves are the fundamental transformation units, following a two-phase interface: initialization (init()) configures static parameters and binds to serving or prompt template objects, while execution (run()) performs the transformation. The run() method accepts a DataFlowStorage object and key-based bindings (input_* and output_*), allowing operators to adapt to diverse upstream datasets. This design forms a directed dependency graph among operators, enabling topological scheduling and downstream optimization. The framework categorizes operators along three orthogonal dimensions: modality (text, visual, document), core vs. domain-specific, and function (generate, evaluate, filter, refine). This categorization balances conceptual compactness with domain extensibility, supporting over 180 operators organized into four functional categories that underpin the generate–evaluate–filter–refine paradigm.
Pipelines compose these operators into multi-stage workflows, represented as ordered sequences or lightweight DAGs. The pipeline API adopts a PyTorch-like design, with init() handling resource allocation and forward() encoding execution. A built-in compile() procedure performs static analysis prior to execution, extracting dependencies, validating key-level consistency, and constructing a deferred execution plan. This enables advanced runtime features such as checkpointing and stepwise resumption, improving iterative development and large-scale construction.
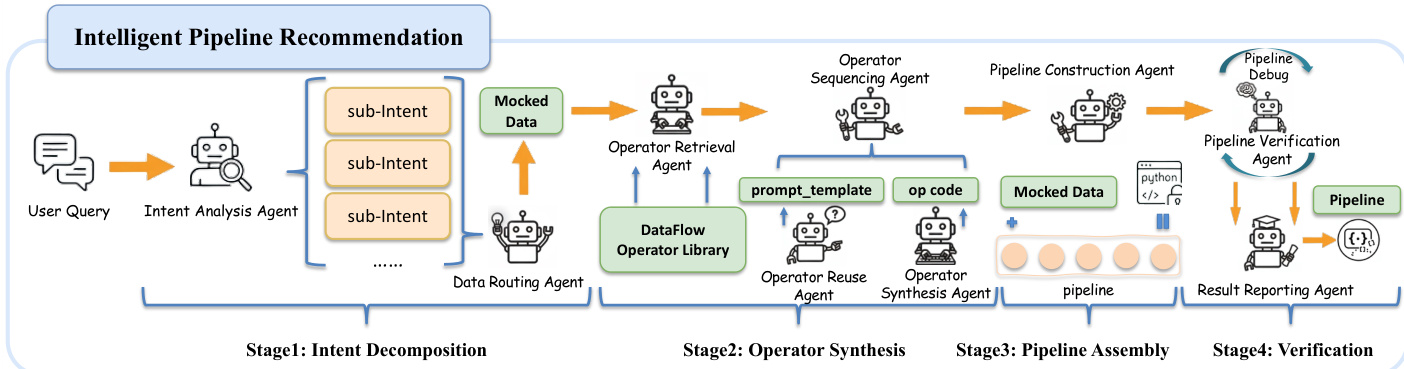
To automate pipeline construction, the DataFlow-Agent layer orchestrates a multi-agent workflow built on LangGraph. The agent decomposes user queries into sub-intents, retrieves or synthesizes operators, assembles them into a DAG, and verifies the pipeline in a sandboxed environment. The agent employs a “retrieve-reuse-synthesize” strategy: it first attempts to reuse existing operators via prompt templates, then synthesizes new code using RAG-based few-shot learning if functional gaps are detected, and finally debugs the code to ensure stable execution. This enables the system to construct adaptive pipelines that handle unforeseen requirements without manual intervention.
The framework’s extensibility is further supported by the DataFlow-Ecosystem, which allows users to package and distribute domain-specific operators, templates, and pipelines as Python modules. The DataFlow-CLI scaffolds new extensions, generating templates for operators and pipelines, while the agent can synthesize and debug new components on demand. This ecosystem fosters community-driven growth, enabling practitioners to share, reproduce, and improve data preparation recipes.
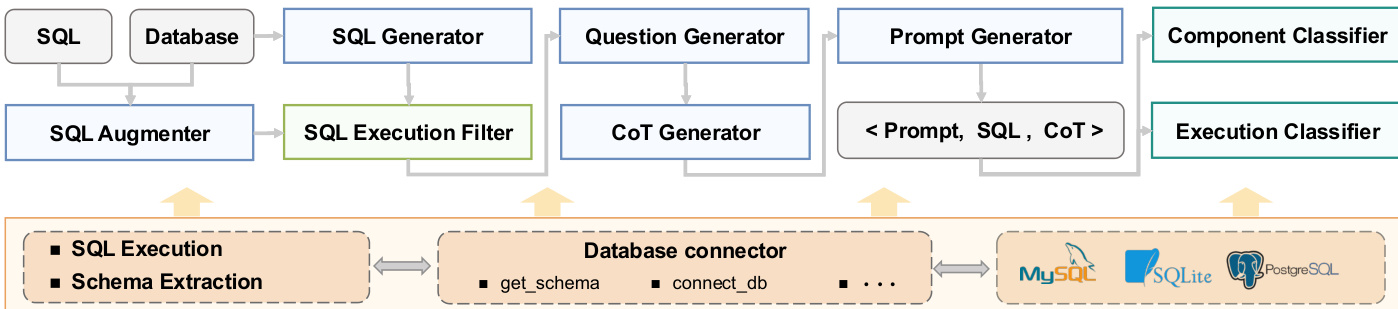
For domain-specific tasks, such as Text-to-SQL generation, the framework provides specialized operators and a database manager module that abstracts low-level database interactions. The Text-to-SQL pipeline, for instance, includes operators for SQL generation, augmentation, question generation, and chain-of-thought reasoning, all orchestrated through a unified prompt template interface that enables reuse across databases like MySQL, SQLite, and PostgreSQL.
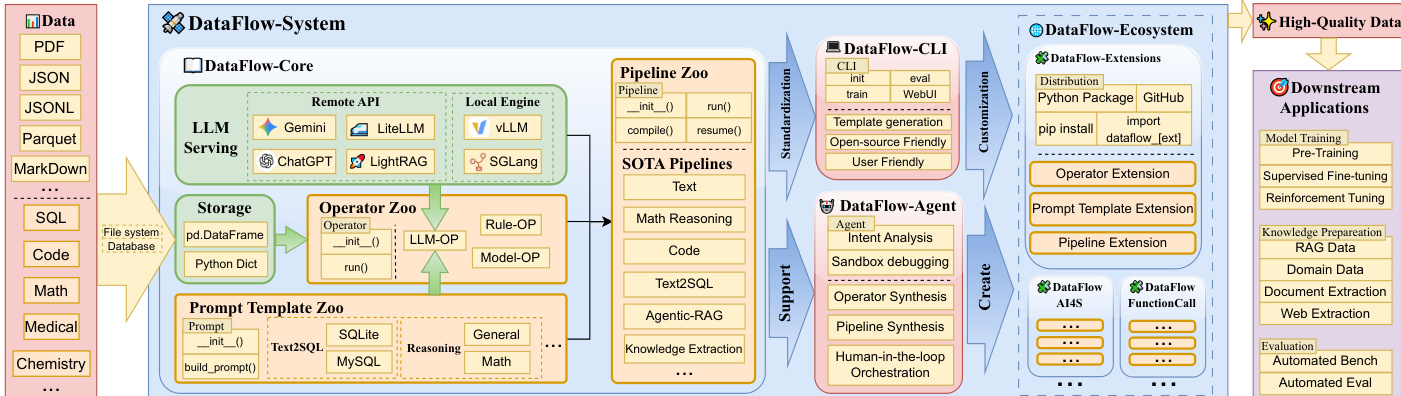
The resulting high-quality, task-aligned datasets integrate seamlessly into downstream LLM applications, including model training, fine-tuning, and evaluation. The framework’s design ensures that data preparation is no longer a post-hoc cleaning step but a first-class, programmable workflow that builds semantically rich corpora through iterative synthesis and refinement.
Experiment
- Text data preparation: DataFlow-30B pre-training filtering achieved 35.69 average score across six benchmarks, surpassing Random (35.26), FineWeb-Edu (35.57), and Kurating (35.02); DataFlow-CHAT-15K boosted general benchmark mean to 28.21 and AlpacaEval to 10.11, outperforming ShareGPT and UltraChat.
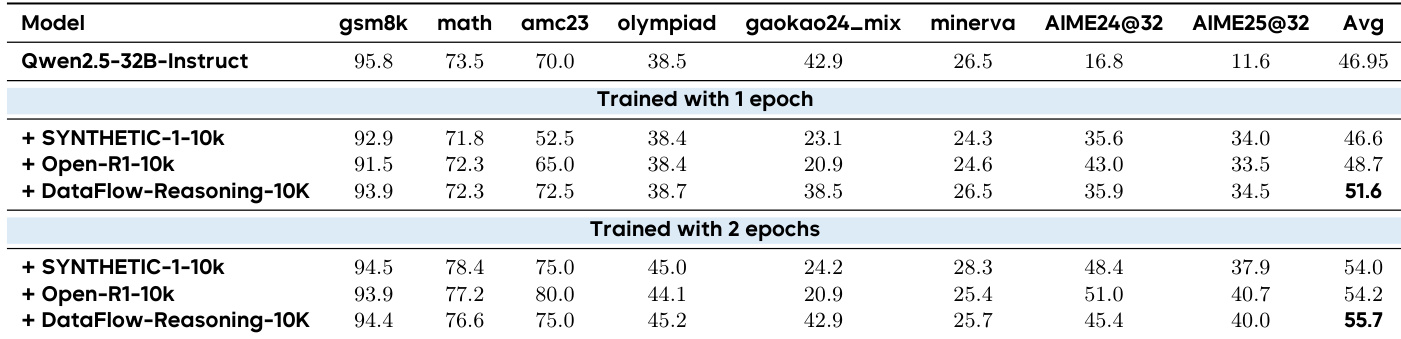
- Math reasoning: DataFlow-synthesized 10k samples achieved 55.7 average score, surpassing Open-R1 (54.2) and Synthetic-1 (54.0), confirming data quality over scale for mathematical reasoning.
- Code generation: DataFlow-CODE-10K reached 46.2 average score on Qwen2.5-7B, exceeding Code Alpaca-1K and SC2-Exec-Filter, with 33.2 LiveCodeBench score for executable correctness.
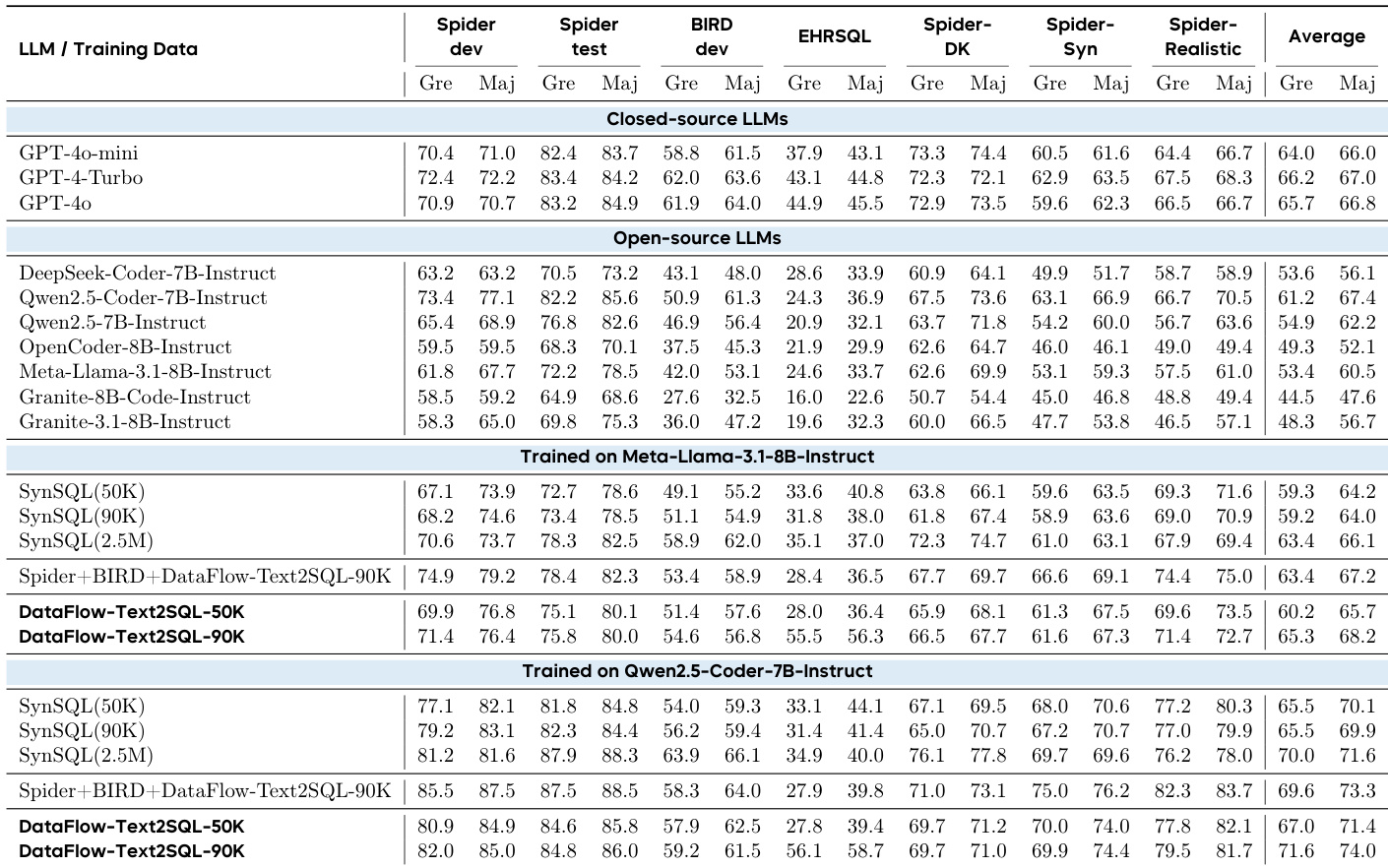
- Text-to-SQL: DataFlow-TEXT2SQL-50K achieved 84.6 Spider-dev and 57.9 BIRD-dev execution accuracy, outperforming SynSQL(50K) (81.8/54.0) and matching SynSQL-2.5M performance at 1/50th data scale.
- AgenticRAG: DF-AgenticRAG-10k surpassed human datasets by +1.2 points over Musique-20k and +2.6 over 2Wiki-30k on out-of-distribution averages for multi-hop reasoning.
- Knowledge extraction: DataFlow-KNOWLEDGE improved PubMedQA and Covert accuracy by 15-20 points over CoT and RAG baselines, demonstrating domain-specific QA enhancement.
- Unified multi-domain: DataFlow-INSTRUCT-10K enabled Qwen2.5-base to achieve 46.7 math score, surpassing Inf-1M (33.3) and nearing Qwen-Instruct (49.8) with 100x less data.
- Agentic orchestration: Achieved 0.80 LLM-Judge score on text specification alignment but 0.49 on code implementation consistency, with performance declining on harder tasks.
The authors use DATAFLOW to filter a 30B-token subset from SlimPajama-627B and train a Qwen2.5-0.5B model from scratch. Results show that DATAFLOW-30B achieves the highest average score (35.69) across six benchmarks, outperforming Random-30B (35.26), Kurating-30B (35.02), and FineWeb-Edu-30B (35.57), indicating its multi-filter approach yields cleaner, more semantically consistent pre-training data.

The authors use DATAFLOW-KNOWLEDGE synthetic data to fine-tune a model for medical question answering, achieving higher accuracy than both zero-shot CoT and RAG baselines across PubMedQA, Covert, and PubHealth. Results show the SFT model outperforms CoT by 15–20 points on PubMedQA and Covert and by 11 points on PubHealth, indicating structured synthetic QA pairs provide stronger supervision than inference-time methods.

The authors use DATAFLOW to filter and synthesize 15K SFT samples, comparing them against random and filtered subsets of Alpaca and WizardLM. Results show that DATAFLOW-SFT-15K consistently outperforms both baselines across Math, Code, and Knowledge benchmarks, with filtered versions delivering only marginal gains over random sampling, indicating the synthesized data is inherently higher quality.

The authors use DATAFLOW to generate Text-to-SQL training data and evaluate its impact on both Meta-Llama-3.1-8B-Instruct and Qwen2.5-Coder-7B-Instruct models. Results show that models trained on DATAFLOW-Text2SQL datasets consistently outperform those trained on SynSQL baselines at comparable scales, with performance on some benchmarks approaching that of models trained on much larger SynSQL datasets. The DATAFLOW-generated data also enables significant gains in execution accuracy across Spider, BIRD, and EHRSQ benchmarks, demonstrating its high quality and training utility.
The authors use a 32B Qwen2.5 model to evaluate math reasoning performance across three 10k synthetic datasets, finding that DataFlow-Reasoning-10K consistently outperforms both Synthetic-1-10k and Open-R1-10k. After two epochs of training, DataFlow-Reasoning-10K achieves the highest average score of 55.7, surpassing Open-R1-10k (54.2) and Synthetic-1-10k (54.0), indicating superior data quality from its verified seed and CoT generation pipeline. Results confirm that data quality, not scale, drives performance gains in mathematical reasoning tasks.