Command Palette
Search for a command to run...
Lois d'échelle pour le code : chaque langage de programmation compte
Lois d'échelle pour le code : chaque langage de programmation compte
Résumé
Les modèles de langage à grande échelle pour le code (Code LLMs) sont puissants, mais leur entraînement est coûteux, les lois d’échelle prédisant la performance en fonction de la taille du modèle, des données et des ressources informatiques. Toutefois, les différents langages de programmation (PLs) n’ont pas le même impact durant l’entraînement préalable, ce qui affecte significativement la performance du modèle de base et conduit à des prédictions de performance inexactes. En outre, les travaux existants se concentrent principalement sur des cadres indépendants du langage, négligeant ainsi la nature intrinsèquement multilingue du développement logiciel moderne. Il est donc nécessaire, en premier lieu, d’étudier les lois d’échelle propres à chaque langage de programmation, puis d’analyser leurs influences mutuelles afin d’établir une loi d’échelle multilingue finale. Dans cet article, nous présentons la première exploration systématique des lois d’échelle pour l’entraînement préalable multilingue du code, menant à plus de 1 000 expériences (équivalent à plus de 336 000 heures sur H800) sur plusieurs langages de programmation, différentes tailles de modèles (de 0,2 milliard à 14 milliards de paramètres) et diverses tailles de jeux de données (jusqu’à 1 milliard de tokens). Nous établissons des lois d’échelle complètes pour les Code LLMs dans plusieurs langages de programmation, révélant que les langages interprétés (par exemple Python) tirent davantage parti d’une augmentation de la taille du modèle et des données que les langages compilés (par exemple Rust). Cette étude démontre que l’entraînement multilingue offre des bénéfices synergiques, particulièrement entre les langages de syntaxe similaire. Par ailleurs, la stratégie d’entraînement par appariement parallèle (concaténation de fragments de code avec leurs traductions) améliore de manière significative les capacités interlingues, tout en présentant de bonnes propriétés d’échelle. Enfin, nous proposons une loi d’échelle multilingue dépendant de la proportion, permettant d’optimiser l’allocation des tokens d’entraînement en privilégiant les langages à forte utilité (par exemple Python), en équilibrant les paires à fort potentiel synergique (par exemple JavaScript-TypeScript), et en réduisant l’attribution aux langages à saturation rapide (comme Rust), ce qui permet d’obtenir une performance moyenne supérieure pour tous les langages par rapport à une répartition uniforme, sous un même budget informatique.
One-sentence Summary
Researchers from Beihang University, Ubiquant, and Renmin University propose a proportion-dependent multilingual scaling law for Code LLMs, revealing language-specific scaling behaviors and synergy between syntactically similar PLs, enabling optimal token allocation to boost cross-lingual performance under fixed compute.
Key Contributions
- We establish the first multilingual scaling laws for code LLMs through 1000+ experiments, revealing that interpreted languages like Python scale more favorably with model size and data than compiled languages like Rust, challenging language-agnostic assumptions in prior work.
- We identify synergistic cross-lingual benefits during multilingual pre-training, particularly between syntactically similar languages, and show that parallel pairing—concatenating code with translations—enhances cross-lingual transfer while maintaining favorable scaling properties.
- We propose a proportion-dependent scaling law that optimally allocates training tokens by prioritizing high-utility languages (e.g., Python), balancing high-synergy pairs (e.g., JavaScript-TypeScript), and deprioritizing fast-saturating ones (e.g., Rust), achieving better average performance than uniform allocation under fixed compute budgets.
Introduction
The authors leverage large-scale empirical analysis to uncover how programming language diversity affects code LLM scaling, addressing a critical gap in prior work that treated code pre-training as language-agnostic. Existing scaling laws for code ignore how different languages—such as Python versus Rust—respond differently to increases in model size and data, leading to suboptimal resource allocation and inaccurate performance forecasts. Their main contribution is a proportion-dependent multilingual scaling law derived from over 1000 experiments, which reveals that interpreted languages scale better with more data and parameters, that syntactically similar languages exhibit cross-lingual synergy, and that parallel pairing of code translations boosts cross-lingual performance. This framework enables optimal token allocation across languages, improving average performance under fixed compute budgets by prioritizing high-utility or high-synergy languages while deprioritizing fast-saturating ones.
Dataset

The authors use a multilingual programming language dataset centered on Python as a pivot, paired with six target languages: Java, JavaScript, TypeScript, C#, Go, and Rust. Here’s how the data is composed and used:
-
Dataset composition:
- 900B tokens of algorithmically equivalent code across 7 languages, with Python ↔ each target language as the only parallel pairs (no direct non-Python ↔ non-Python pairs).
- Augmented with 100B tokens from FineWeb-Edu for natural language understanding, totaling 1T tokens.
- Evaluation set: 50 handpicked Python files from GitHub, manually translated into 6 target languages by engineers, yielding 2,100 translation instances (all 42 directions), average 464 tokens per sample.
-
Key subset details:
- Training data includes only Python-centric parallel pairs (12 directions: 6 into Python, 6 out of Python).
- No training data exists for the 30 non-Python ↔ non-Python directions — these are evaluated zero-shot.
- Evaluation set is curated for semantic equivalence and diversity across algorithmic tasks.
-
How data is used:
- Models are trained on the full 1T token corpus (900B code + 100B natural language) for one epoch.
- Three pre-training strategies are tested: (1) monolingual pre-training, (2) training on seen translation directions, (3) training on Python-centric pairs then evaluating zero-shot on unseen directions.
- Evaluated using translation loss: −E[log P(y|x)] for target code y given source x.
-
Processing and scaling:
- Models range from 0.1B to 3.1B parameters, trained with token budgets from 2B to 64B tokens.
- Five model scales (0.2B, 0.5B, 1.5B, 3B, 7B) are tested under two data organization paradigms.
- No cropping or metadata construction is mentioned — data is used as-is with full sequence lengths.
Method
The authors leverage a proportion-dependent multilingual scaling law to model the performance of large language models across multiple languages, addressing the limitation of traditional scaling laws that treat multilingual data as homogeneous. Instead, they explicitly incorporate language proportions p=(p1,…,pK) into the scaling framework, where each pk represents the fraction of training data in language k. The overall scaling law is expressed as:
L(N,D;p)=A⋅N−αN(p)+B⋅Dx−αD(p)+L∞(p)Here, N denotes the number of model parameters, D is the total training data size, and L represents the model's loss. The exponents αN(p) and αD(p), as well as the asymptotic loss L∞(p), are proportion-weighted averages of language-specific parameters. Specifically, αN(p)=∑kpkαNk, αD(p)=∑kpkαDk, and L∞(p)=∑kpkL∞k, where αNk, αDk, and L∞k are the scaling parameters for language k. This formulation allows the model to adapt its scaling behavior based on the relative contribution of each language in the training mix.
To account for cross-lingual transfer effects, the effective data size Dx is defined as:
Dx=Dall1+γLi=Lj∑pLipLjτijwhere Dall is the total amount of training data across all languages, γ is a scaling factor, and τij is the transfer coefficient between languages Li and Lj, derived from empirical observations. This term captures how data in one language can improve performance on another, reflecting the interdependencies between languages in a multilingual setting. The framework thus enables a more nuanced understanding of how model performance scales with data and parameters when language proportions vary.
Experiment
- Established language-specific scaling laws across 7 PLs: interpreted languages (e.g., Python) show higher scaling exponents than compiled ones (e.g., Rust), with irreducible loss ordering C# < Java ≈ Rust < Go < TypeScript < JavaScript < Python, reflecting syntax strictness and predictability.
- Demonstrated multilingual synergy: most PLs benefit from mixed pre-training, especially syntactically similar pairs (e.g., Java-C# gained 20.5% in validation loss reduction); Python showed limited gains when mixed as target but boosted others as auxiliary.
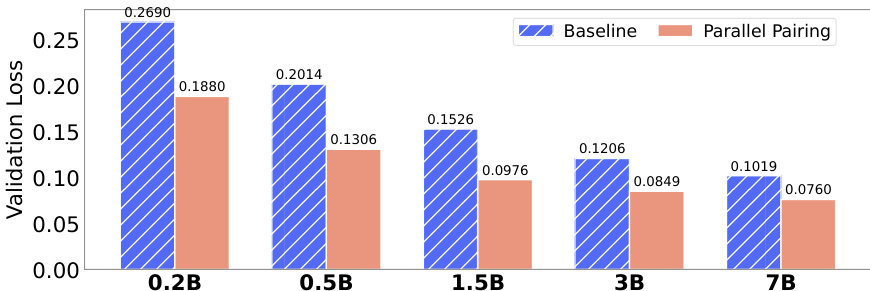
- Evaluated cross-lingual strategies: parallel pairing (explicit code-translation alignment) significantly outperformed shuffled baselines on both seen and unseen translation directions (e.g., BLEU scores improved, zero-shot loss dropped to 0.0524), with high scaling exponent (α=6.404) enabling efficient model capacity use.
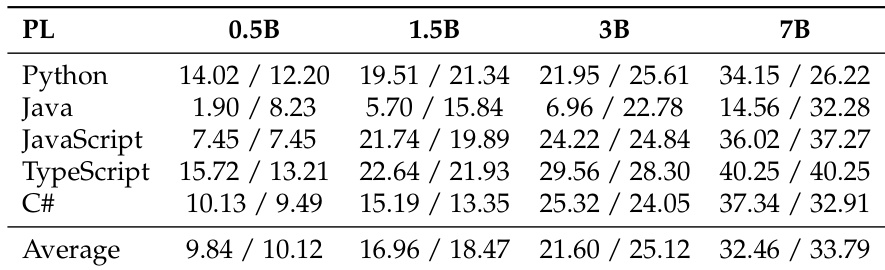
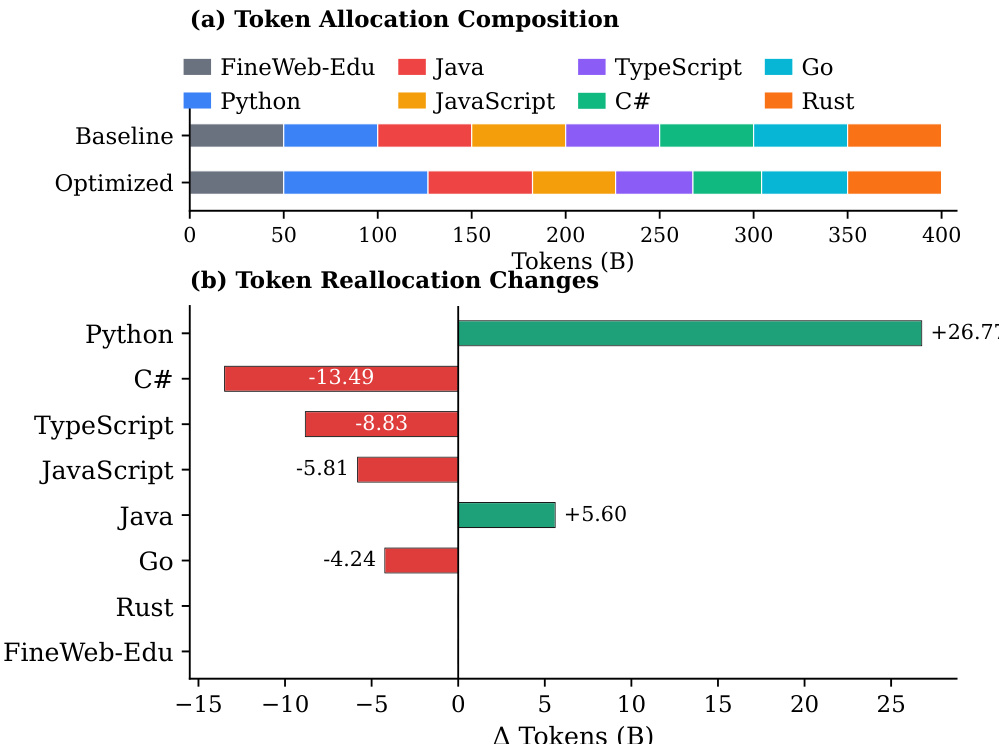
- Proposed proportion-dependent multilingual scaling law: optimized token allocation (more to high-αD languages like Python, balanced for high-synergy pairs like JavaScript-TypeScript, less for fast-saturating ones like Rust) achieved higher average Pass@1 and BLEU scores across all PLs without degrading any single language under fixed 400B-token budget.
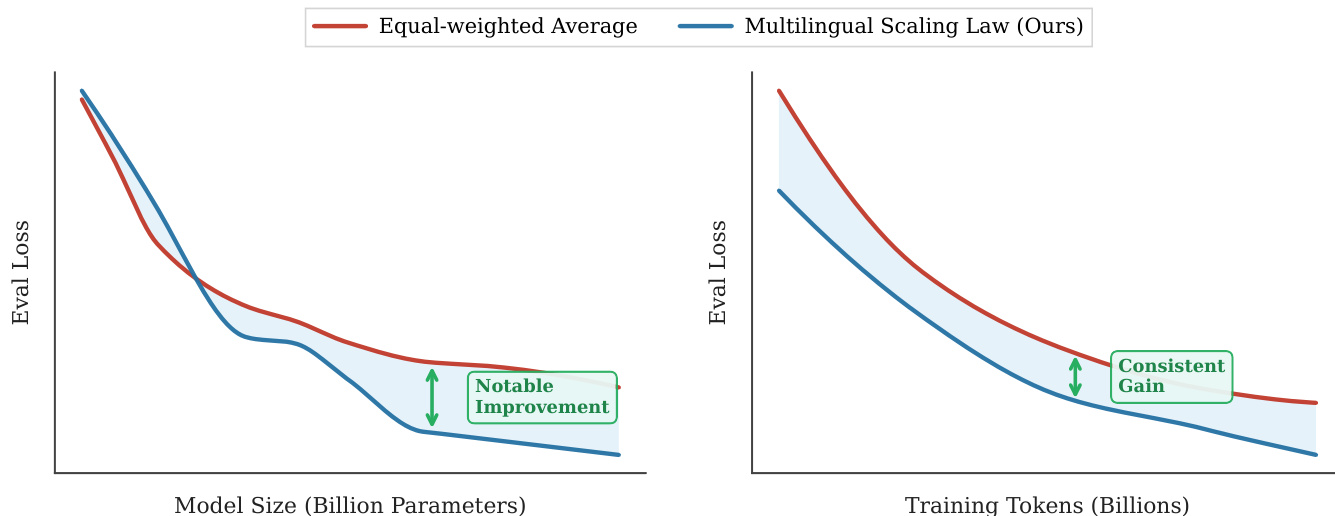
- Confirmed data scaling yields greater gains than model scaling across all PLs, with distinct convergence rates and intrinsic difficulty per language.
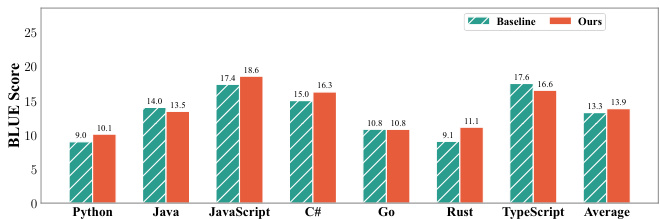
The authors use a multilingual code generation benchmark to evaluate two training strategies—uniform and optimized allocation—on 1.5B parameter models. Results show that the optimized allocation achieves higher average performance across all programming languages without significant degradation in any single language, demonstrating that strategic reallocation based on scaling laws and language synergies outperforms uniform distribution under identical compute budgets.
The authors use a proportion-dependent multilingual scaling law to optimize token allocation across programming languages, redistributing tokens based on language-specific scaling exponents, synergy gains, and irreducible loss. Results show that the optimized strategy increases tokens for high-utility languages like Python and high-synergy pairs such as JavaScript-TypeScript while reducing tokens for fast-saturating languages like Go, achieving higher average performance across all languages without significant degradation in any single language.
The authors use a synergy gain matrix to analyze the effects of mixing different programming languages during pre-training, finding that languages with similar syntax or structure, such as Java and C#, exhibit significant positive transfer, while mixing Python with other languages often results in negative interference. Results show that multilingual pre-training benefits most programming languages, though the gains are asymmetric and depend on the specific language pair, with the highest improvements observed for Java-C# and JavaScript-TypeScript combinations.

The authors compare two data organization strategies for multilingual code pre-training, showing that parallel pairing significantly reduces validation loss across all model sizes compared to the baseline. Results demonstrate that parallel pairing achieves lower validation loss than random shuffling, with the gap increasing as model size grows, indicating more efficient utilization of model capacity for cross-lingual alignment.
The authors compare two data allocation strategies for multilingual code pre-training: a baseline with uniform token distribution and an optimized strategy based on scaling laws and synergy gains. Results show that the optimized strategy achieves higher BLEU scores across all programming languages, with improvements particularly notable in high-synergy pairs and languages benefiting from increased data, while maintaining strong performance in languages with reduced token allocation.