Command Palette
Search for a command to run...
Rapport technique KlingAvatar 2.0
Rapport technique KlingAvatar 2.0
Résumé
Les modèles de génération de vidéos Avatar ont connu des progrès remarquables ces dernières années. Toutefois, les travaux antérieurs présentent une efficacité limitée dans la génération de vidéos longues à haute résolution, souffrant de dérives temporelles, de dégradation de qualité et d’une faible fidélité aux instructions lorsque la durée de la vidéo augmente. Pour relever ces défis, nous proposons KlingAvatar 2.0, un cadre hiérarchique spatio-temporel qui réalise une mise à l’échelle à la fois en résolution spatiale et en dimension temporelle. Ce cadre génère d’abord des images-clés de vidéo à faible résolution capturant les sémantiques globales et le mouvement, puis les affine en sous-segments à haute résolution et cohérents dans le temps grâce à une stratégie basée sur les premières et dernières images, tout en préservant des transitions temporelles fluides dans les vidéos longues. Pour améliorer la fusion et l’alignement multimodaux des instructions dans les vidéos étendues, nous introduisons un Directeur de Co-Raisonnement composé de trois experts spécifiques aux modalités, fondés sur des grands modèles linguistiques (LLM). Ces experts analysent les priorités des modalités et infèrent l’intention sous-jacente de l’utilisateur, transformant les entrées en scénarios détaillés via des dialogues multi-tours. Un Directeur Négatif supplémentaire affine davantage les instructions négatives afin d’améliorer l’alignement avec les instructions. En s’appuyant sur ces composants, nous étendons le cadre pour prendre en charge le contrôle multi-personnage spécifique à une identité. Des expériences approfondies démontrent que notre modèle répond efficacement aux défis de la génération de vidéos longues, à haute résolution, multimodales et bien alignées, offrant une clarté visuelle améliorée, une représentation réaliste des lèvres et des dents avec une synchronisation labiale précise, une forte préservation de l’identité et une fidélité cohérente aux instructions multimodales.
One-sentence Summary
Kuaishou Technology's Kling Team proposes KlingAvatar 2.0, a spatio-temporal cascade framework generating long-duration high-resolution avatar videos by refining low-resolution blueprint keyframes via first-last frame conditioning to eliminate temporal drifting. Its Co-Reasoning Director employs multimodal LLM experts for precise cross-modal instruction alignment, enabling identity-preserving multi-character synthesis with accurate lip synchronization for applications in education, entertainment, and personalized services.
Key Contributions
- Current speech-driven avatar generation systems struggle with long-duration high-resolution videos, exhibiting temporal drifting, quality degradation, and weak prompt adherence as video length increases despite advances in general video diffusion models.
- KlingAvatar 2.0 introduces a spatio-temporal cascade framework that first generates low-resolution blueprint keyframes capturing global motion and semantics, then refines them into high-resolution sub-clips using a first-last frame strategy to ensure temporal coherence and detail preservation in extended videos.
- The Co-Reasoning Director employs three modality-specific LLM experts that collaboratively infer user intent through multi-turn dialogue, converting inputs into hierarchical storylines while refining negative prompts to enhance multimodal instruction alignment and long-form video fidelity.
Introduction
Video generation has advanced through diffusion models and DiT architectures using 3D VAEs for spatio-temporal compression, enabling high-fidelity synthesis but remaining limited to text or image prompts without audio conditioning. Prior avatar systems either rely on intermediate motion representations like landmarks or lack long-term coherence and expressive control for speech-driven digital humans. The authors address this gap by introducing KlingAvatar 2.0, which leverages multimodal large language model reasoning for hierarchical storyline planning and a spatio-temporal cascade pipeline to generate coherent, long-form audio-driven avatar videos with fine-grained expression and environmental interaction.
Method
The authors leverage a spatio-temporal cascade framework to generate long-duration, high-resolution avatar videos with precise lip synchronization and multimodal instruction alignment. The pipeline begins with a Co-Reasoning Director that processes input modalities—reference image, audio, and text—through a multi-turn dialogue among three modality-specific LLM experts. These experts jointly infer user intent, resolve semantic conflicts, and output structured global and local storylines, including positive and negative prompts that guide downstream generation. As shown in the framework diagram, the Director’s output feeds into a hierarchical diffusion cascade: first, a low-resolution Video DiT generates blueprint keyframes capturing global motion and layout; these are then upscaled by a high-resolution Video DiT to enrich spatial detail while preserving identity and composition. Subsequently, a low-resolution diffusion model expands the high-resolution keyframes into audio-synchronized sub-clips using a first-last frame conditioning strategy, augmented with blueprint context to refine motion and expression. An audio-aware interpolation module synthesizes intermediate frames to ensure temporal smoothness and lip-audio alignment. Finally, a high-resolution Video DiT performs super-resolution on the sub-clips, yielding temporally coherent, high-fidelity video segments.
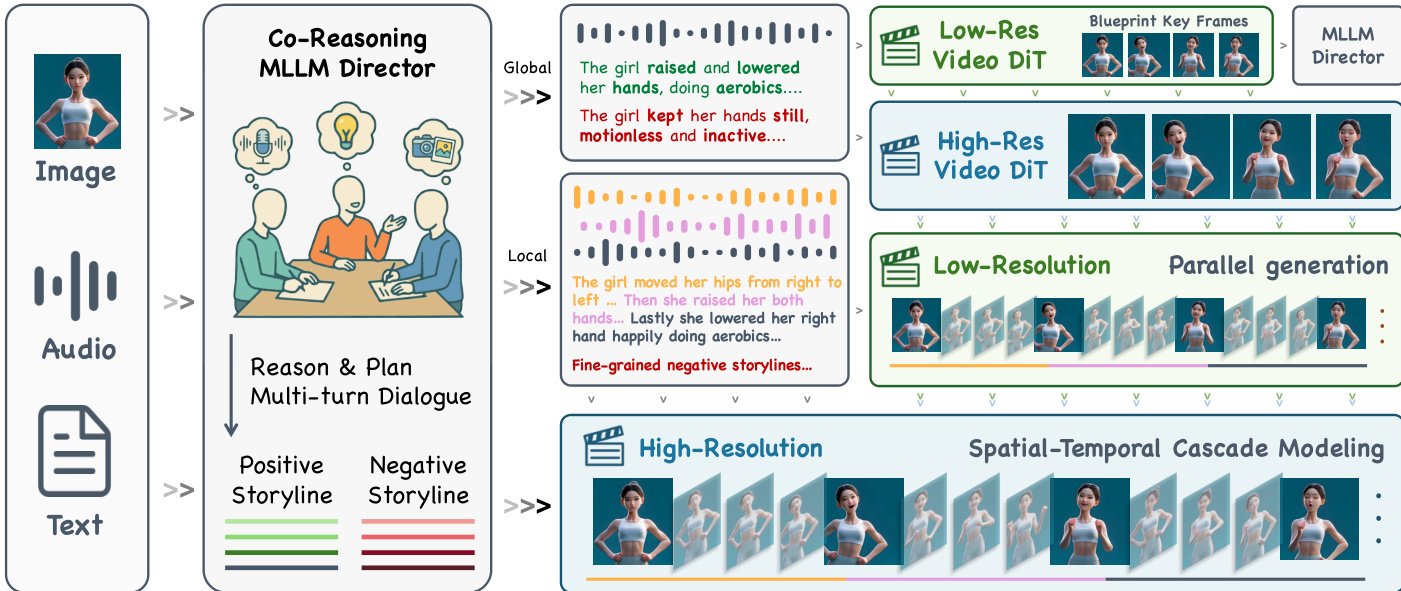
To support multi-character scenes with identity-specific audio control, the authors introduce a mask-prediction head attached to deep layers of the Human Video DiT. These deep features exhibit spatially coherent regions corresponding to individual characters, enabling precise audio injection. During inference, reference identity crops are encoded and cross-attended with video latent tokens to regress per-frame character masks, which gate the injection of character-specific audio streams into corresponding spatial regions. For training, the DiT backbone remains frozen while only the mask-prediction modules are optimized. To scale data curation, an automated annotation pipeline is deployed: YOLO detects characters in the first frame, DWPose estimates keypoints, and SAM2 segments and tracks each person across frames using bounding boxes and keypoints as prompts. The resulting masks are validated against per-frame detection and pose estimates to ensure annotation quality. As shown in the figure, this architecture enables fine-grained control over multiple characters while maintaining spatial and temporal consistency.

Experiment
- Accelerated video generation via trajectory-preserving distillation with custom time schedulers validated improved inference efficiency and generative performance, surpassing distribution matching approaches in stability and flexibility.
- Human preference evaluation on 300 diverse test cases (Chinese/English speech, singing) demonstrated superior (G+S)/(B+S) scores against HeyGen, Kling-Avatar, and OmniHuman-1.5, particularly excelling in motion expressiveness and text relevance.
- Generated videos achieved more natural hair dynamics, precise camera motion alignment (e.g., correctly folding hands per prompt), and emotionally coherent expressions, while per-shot negative prompts enhanced temporal stability versus baselines' generic artifact control.
Results show KlingAvatar 2.0 outperforms all three baselines across overall preference and most subcategories, with particularly strong gains in motion expressiveness and text relevance. The model achieves the highest scores against Kling-Avatar in motion expressiveness (2.47) and text relevance (3.73), indicating superior alignment with multimodal instructions and richer dynamic expression. Visual quality and motion quality also consistently favor KlingAvatar 2.0, though face-lip synchronization scores are closer to baselines.
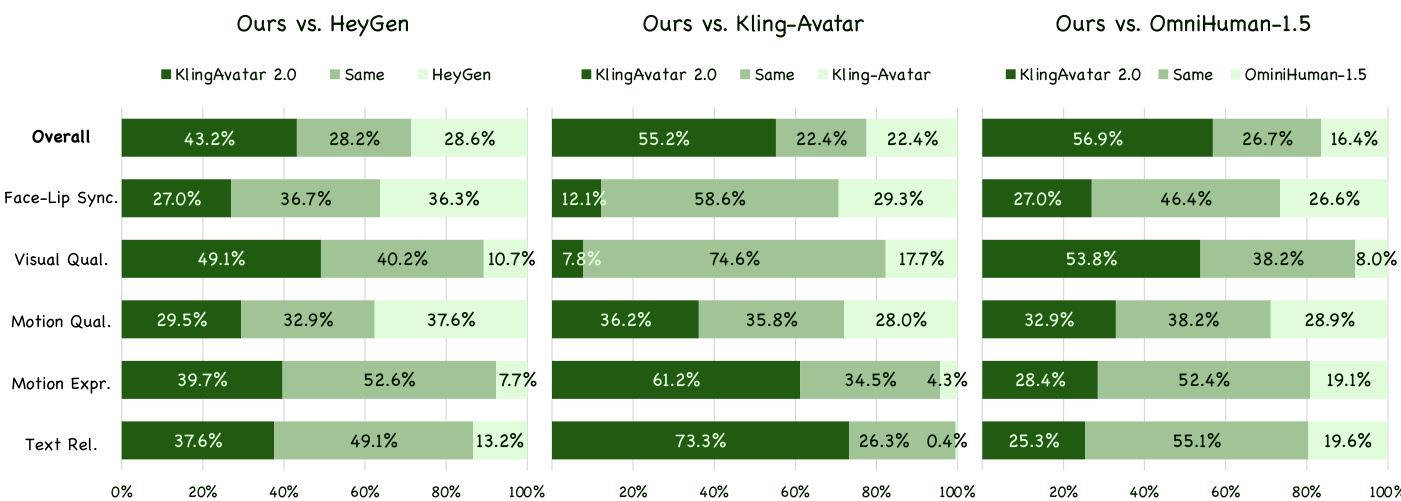
Results show KlingAvatar 2.0 outperforms all three baselines across overall preference and most subcategories, with particularly strong gains in motion expressiveness and text relevance. The model achieves the highest scores against Kling-Avatar in motion expressiveness (2.47) and text relevance (3.73), indicating superior alignment with multimodal instructions and richer dynamic expression. Visual quality and motion quality also consistently favor KlingAvatar 2.0, though face-lip synchronization scores are closer to baselines.
