Command Palette
Search for a command to run...
QwenLong-L1.5 : Recette de post-entraînement pour le raisonnement à longue portée et la gestion de la mémoire
QwenLong-L1.5 : Recette de post-entraînement pour le raisonnement à longue portée et la gestion de la mémoire
Résumé
Nous introduisons QwenLong-L1.5, un modèle qui atteint des capacités de raisonnement de longue portée supérieures grâce à des innovations systématiques en post-entraînement. Les principales avancées techniques de QwenLong-L1.5 sont les suivantes : (1) Pipeline de synthèse de données à longue portée : nous avons développé un cadre systématique de synthèse permettant de générer des tâches de raisonnement exigeantes nécessitant un ancrage multi-sauts sur des preuves réparties à l’échelle mondiale. En décomposant les documents en faits atomiques et leurs relations sous-jacentes, puis en composant de manière programmée des questions de raisonnement vérifiables, notre approche produit à grande échelle des données d’entraînement de haute qualité, dépassant largement les tâches simples de récupération pour permettre des capacités réelles de raisonnement à longue portée. (2) Apprentissage par renforcement stabilisé pour l’entraînement à longue portée : afin de surmonter l’instabilité critique observée dans l’apprentissage par renforcement à longue portée, nous introduisons un échantillonnage équilibré par tâche avec une estimation d’avantage spécifique à chaque tâche, afin de réduire le biais de récompense, et proposons une optimisation de politique à contrôle d’entropie adaptative (AEPO), qui régule dynamiquement le compromis exploration-exploitation. (3) Architecture augmentée par mémoire pour des contextes ultra-longue : reconnaissant que même des fenêtres de contexte étendues ne peuvent accueillir des séquences arbitrairement longues, nous avons conçu un cadre de gestion de mémoire intégrant une formation par renforcement à fusion multi-étapes, permettant une intégration fluide du raisonnement en une seule passe avec un traitement itératif basé sur la mémoire pour des tâches dépassant 4 millions de tokens. Basé sur Qwen3-30B-A3B-Thinking, QwenLong-L1.5 atteint des performances comparables à celles de GPT-5 et Gemini-2.5-Pro sur les benchmarks de raisonnement à longue portée, dépassant son modèle de base de 9,90 points en moyenne. Pour les tâches ultra-longues (1M à 4M tokens), le cadre de mémoire-agent de QwenLong-L1.5 obtient une amélioration de 9,48 points par rapport à la base agent. En outre, la capacité de raisonnement à longue portée acquise se traduit par une performance améliorée dans des domaines généraux tels que le raisonnement scientifique, l’utilisation d’outils mémoire et les dialogues étendus.
One-sentence Summary
Tongyi Lab, Alibaba Group introduces QwenLong-L1.5, featuring a novel long-context data synthesis pipeline for multi-hop reasoning, task-balanced reinforcement learning with Adaptive Entropy-Controlled Policy Optimization (AEPO) for training stability, and a memory-augmented architecture handling contexts up to 4M tokens. It achieves 9.9-point average gains over baselines on long-context benchmarks while enhancing scientific reasoning and extended dialogue capabilities.
Key Contributions
- Addressing the limitation of prior long-context models that rely on simple retrieval tasks rather than genuine multi-hop reasoning, the authors introduce a systematic data synthesis pipeline that deconstructs documents into atomic facts and programmatically composes verifiable reasoning questions requiring globally distributed evidence, enabling scalable training for complex long-range reasoning. This approach moves beyond basic retrieval to generate high-quality synthetic data that directly targets challenging reasoning scenarios.
- To overcome critical instability in long-context reinforcement learning, the method proposes task-balanced sampling with task-specific advantage estimation and Adaptive Entropy-Controlled Policy Optimization (AEPO), which dynamically regulates exploration-exploitation trade-offs and mitigates reward bias. These techniques enable stable training on sequences of progressively increasing length, a key hurdle in scaling long-context capabilities.
- Recognizing inherent context window limitations, the work develops a memory-augmented architecture with multi-stage fusion RL training that integrates single-pass reasoning and iterative memory-based processing for ultra-long contexts exceeding 4M tokens. Evaluated on benchmarks, this framework achieves a 9.48-point improvement over agent baselines on 1M–4M token tasks while matching GPT-5 and Gemini-2.5-Pro performance on standard long-context reasoning.
Introduction
Handling long-context reasoning is critical for real-world applications like legal document analysis or scientific research, where models must process extensive inputs while maintaining coherent reasoning and memory efficiency. Prior approaches faced limitations in data diversity—relying heavily on text-only inputs and short outputs—and struggled with reinforcement learning instabilities caused by coarse reward assignment across entire reasoning steps, leading to brittle training dynamics. The authors introduce QwenLong-L1.5, featuring an automated data synthesis pipeline for complex long-input tasks and AEPO, a refined reinforcement learning algorithm that stabilizes training through gradient clipping to enable more granular credit assignment within reasoning trajectories.
Dataset
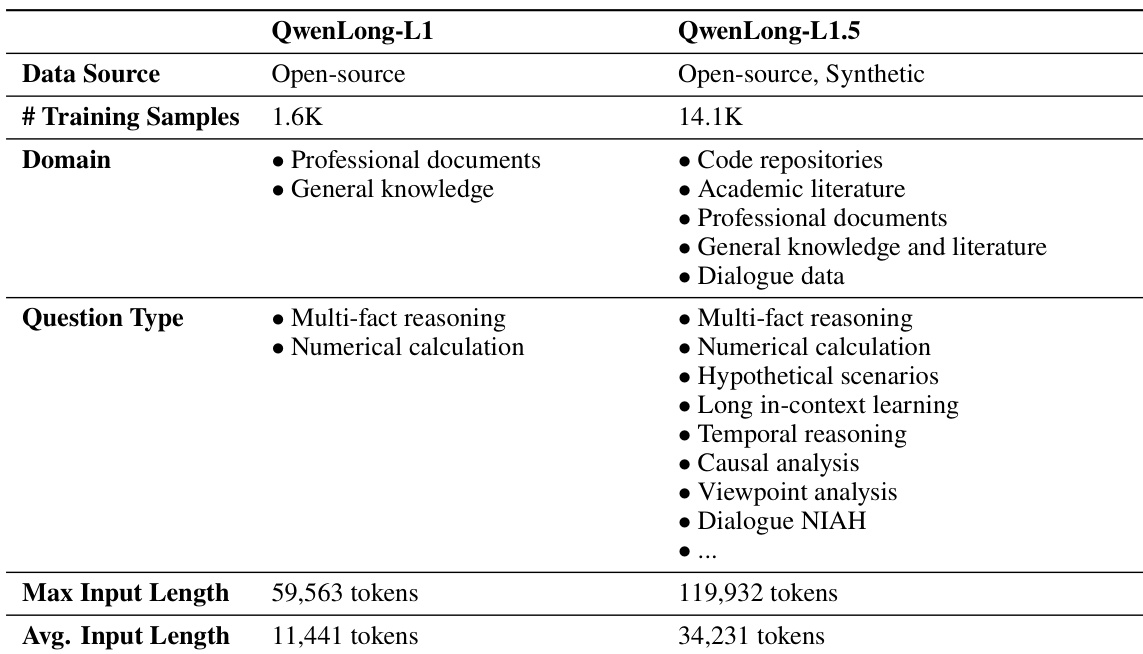
The authors use a synthetically constructed long-context reinforcement learning dataset for QwenLong-L1.5, developed through a three-stage pipeline:
-
Composition and sources:
Built from 82,175 high-quality long documents (9.2B tokens) across five categories:
• Code repositories (high-starred Python projects)
• Academic literature (STEM, medicine, law, arXiv papers)
• Professional documents (financial reports, manuals, government publications)
• General knowledge (novels, Wikipedia)
• Simulated multi-turn dialogues -
Key subset details:
• Initial pool: 42.7k synthesized question-answer pairs
• Final training set: 14.1k samples after rigorous filtering
• Filtering rules:- Knowledge grounding check: Removed samples answerable without context (testing internal knowledge reliance)
- Contextual robustness check: Discarded samples where answers failed when irrelevant documents were added
• Enhanced complexity: Increased samples exceeding 64K tokens versus prior versions
-
Data usage:
• Solely for RL training (no separate validation/test splits described)
• Mixture ratios not specified, but emphasizes domain diversity: multi-hop reasoning, numerical calculation, temporal analysis, viewpoint analysis, and dialogue memory -
Processing strategies:
• Context expansion: Strategically inserted irrelevant documents to force sparse information retrieval
• Difficulty scaling: Used knowledge graphs/tables and multi-agent self-evolution to create challenging questions
• Decontamination: Applied multi-stage deduplication and test set cleaning
• Quality control: Combined rule-based and LLM-as-judge filtering during corpus curation
Method
The authors leverage a comprehensive post-training framework to endow QwenLong-L1.5 with robust long-context reasoning capabilities, integrating a novel data synthesis pipeline, stabilized reinforcement learning, and a memory-augmented architecture. The overall training paradigm is structured as a multi-stage, progressive process designed to scale reasoning capacity while maintaining training stability.
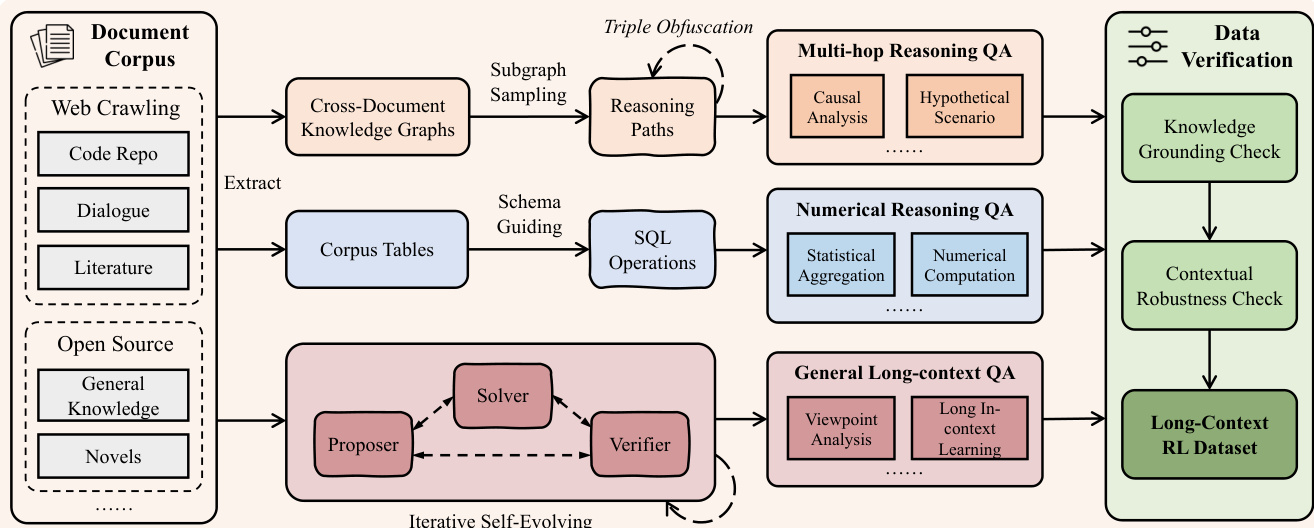
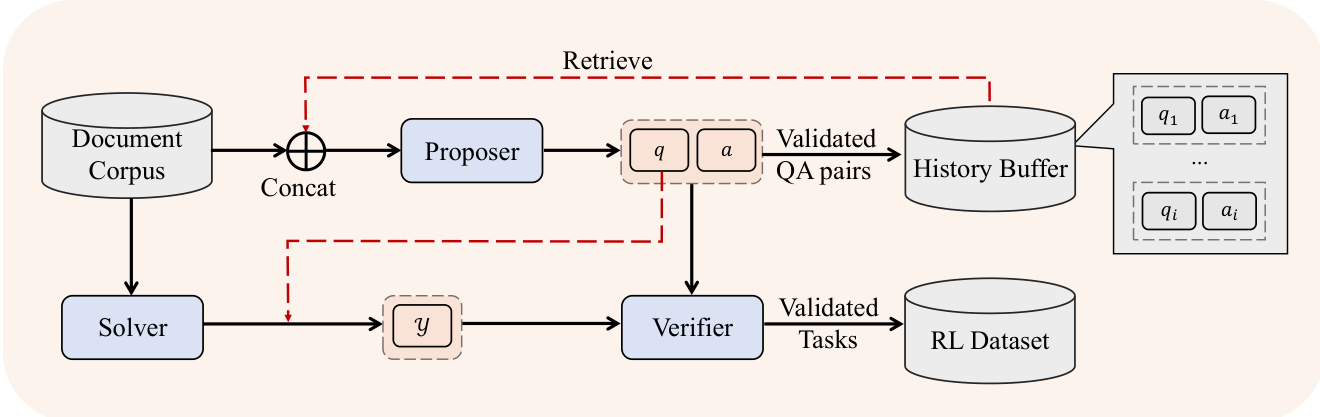
The core of the method begins with the systematic generation of high-quality, complex training data. As shown in the figure below, the data synthesis pipeline is designed to move beyond simple retrieval tasks by constructing challenges that demand multi-hop grounding over globally distributed evidence. The process starts by ingesting a diverse document corpus, including web-crawled content, code repositories, dialogue, and literature. From this corpus, the system extracts structured representations: knowledge graphs are built for multi-hop reasoning tasks, while unstructured documents are parsed into formalized corpus tables to enable numerical reasoning. For general long-context tasks, a multi-agent self-evolving framework is employed, where a proposer agent generates questions, a solver agent attempts to answer them, and a verifier agent validates the correctness of the QA pairs. This iterative process, depicted in the diagram, ensures the generated dataset covers a broad spectrum of reasoning types—including causal analysis, hypothetical scenarios, statistical aggregation, and viewpoint analysis—while undergoing rigorous verification for knowledge grounding and contextual robustness.
To train the model on this data, the authors formulate long-context reasoning as a reinforcement learning problem, optimizing a policy model to maximize a reward function while being regularized against deviation from a reference policy. Given the computational intractability of standard PPO for long sequences, they adopt Group Relative Policy Optimization (GRPO), which estimates advantages via group-wise reward z-score normalization, eliminating the need for a separate value network. To address the instability inherent in multi-task, long-context RL, they introduce two key innovations. First, they implement task-balanced sampling, ensuring each training batch contains an equal number of samples from five distinct task types (e.g., multiple choice, multi-hop QA, numerical calculation). Second, they propose task-specific advantage estimation, which computes the reward standard deviation within each task’s subset of the batch rather than across the entire group, thereby isolating tasks with dense versus sparse reward distributions and yielding a more accurate, less biased advantage signal.
Further stabilizing the training process, the authors introduce Adaptive Entropy-Controlled Policy Optimization (AEPO). This algorithm dynamically regulates the exploration-exploitation trade-off by monitoring the batch-level entropy of the policy. When entropy exceeds a predefined upper bound, AEPO masks all samples with negative advantages, effectively performing advantage-weighted online rejection sampling to reduce entropy. Conversely, when entropy falls below a lower bound, negative gradients are reintroduced to prevent collapse and encourage exploration. This mechanism enables stable training over progressively longer sequences and is critical for scaling the model’s reasoning capabilities.
For tasks exceeding the model’s physical context window, the authors deploy a memory agent framework. As illustrated in the figure below, this architecture reframes long-context reasoning as a sequential decision-making process. The user query is first decomposed into a core question and formatting instructions. The long document is split into chunks, and at each step, the policy observes the current chunk and the historical memory state to update both the memory and a navigational plan for the next chunk. This recurrent mechanism allows the model to “fold” global context into a compact, evolving representation. After processing all chunks, the final answer is generated by integrating the accumulated memory with the original formatting instructions. The policy is optimized end-to-end using GRPO, with trajectory-level rewards computed based on the correctness of the final answer.
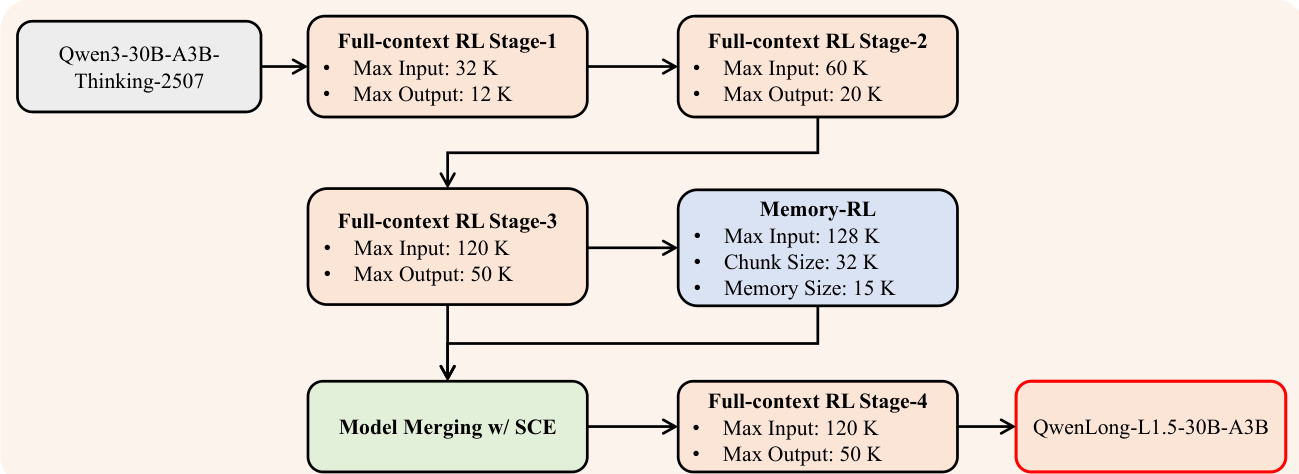
The overall training pipeline, shown in the final figure, is executed in stages. Starting from the Qwen3-30B-A3B-Thinking base model, the authors first perform three stages of full-context RL, progressively increasing the input and output lengths (from 20K/12K to 120K/50K tokens). After Stage 3, they train a specialized memory agent model using the same RL framework but with chunked inputs. This expert model is then merged with the Stage 3 model using the SCE algorithm, and a final stage of full-context RL is applied to the merged model to produce the final QwenLong-L1.5.
This integrated approach—combining scalable data synthesis, stabilized RL, and memory-augmented inference—enables QwenLong-L1.5 to achieve state-of-the-art performance on long-context reasoning benchmarks and generalize effectively to domains requiring extended coherence and multi-hop inference.
Experiment
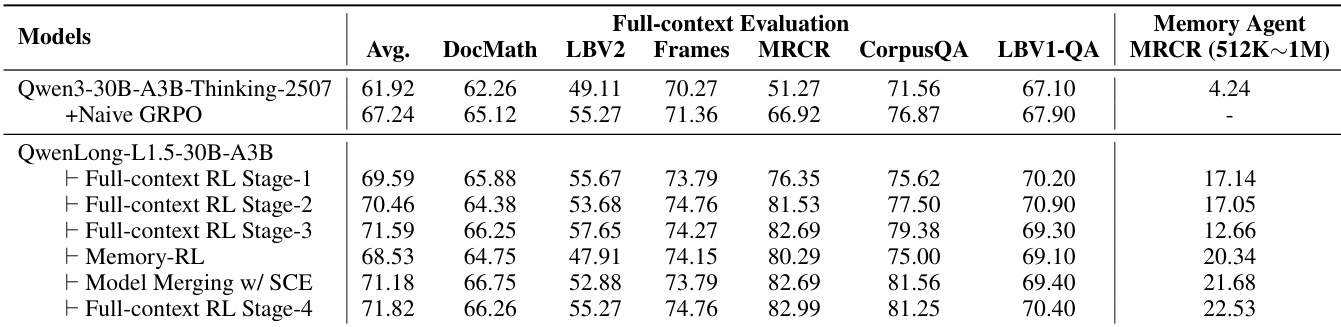
- QwenLong-L1.5-30B-A3B achieved 71.82 average score across long-context benchmarks including LongBench-V2 and MRCR, surpassing DeepSeek-R1-0528 (68.67) and Gemini-2.5-Flash-Thinking (68.73), with 82.99 on MRCR setting state-of-the-art.
- Demonstrated +9.90 point improvement over baseline Qwen3-30B-A3B-Thinking-2507, with largest gains on long-context tasks: MRCR (+31.72), CorpusQA (+9.69), and LongBench-V2 (+6.16).
- Showed generalization to non-training domains, improving AIME25 by +3.65 and LongMemEval by +15.60 without performance degradation on general benchmarks like MMLU-PRO.
- Handled ultra-long contexts up to 4M tokens, scoring 14.29 on CorpusQA 4M subset and outperforming baseline by 18.32 points on MRCR 128K-512K subsets.
- Multi-stage training validated progressive gains: Stage-1 increased average score by +7.67 points, while later stages specifically enhanced long-context reasoning and memory agent capabilities without compromising full-context performance.
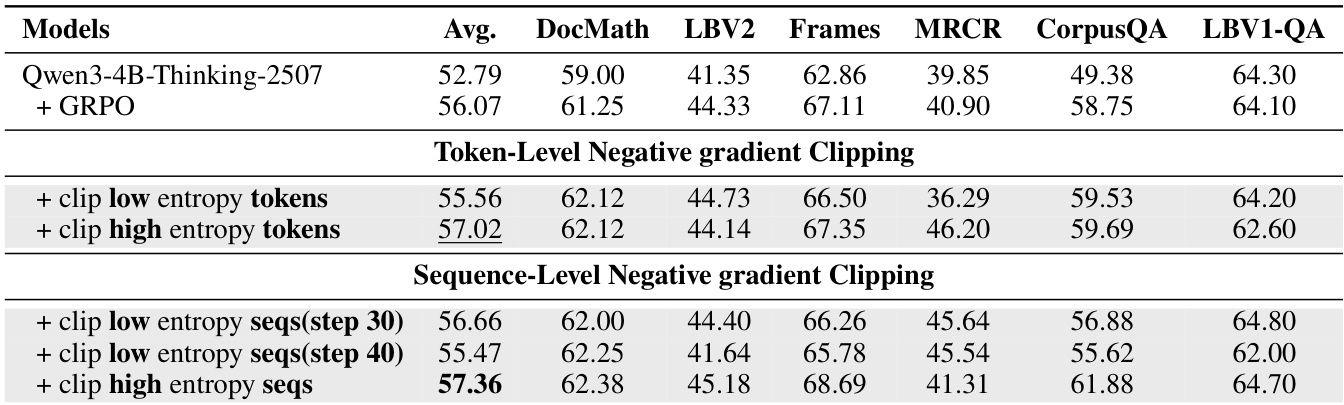
The authors use ablation experiments on Qwen3-4B-Thinking-2507 to evaluate the impact of different negative gradient clipping strategies within the AEPO algorithm. Results show that clipping high-entropy tokens at the token level yields the highest average score (57.02), while clipping high-entropy sequences at the sequence level achieves the best overall performance (57.36), indicating that sequence-level clipping better preserves useful reasoning paths during training.
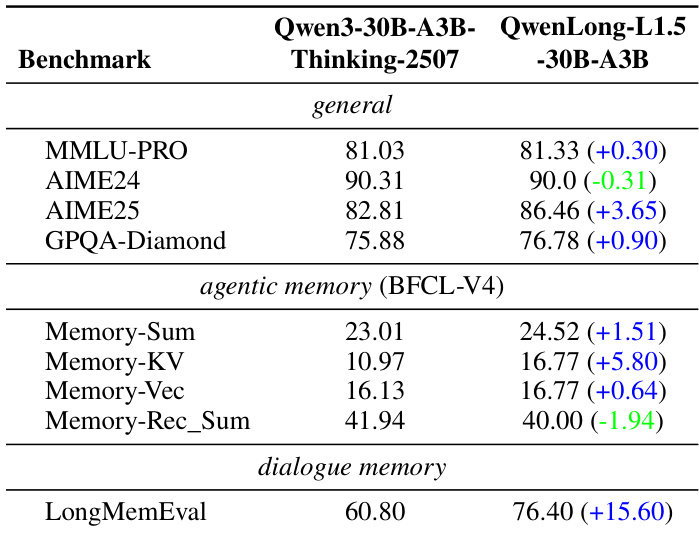
The authors evaluate QwenLong-L1.5-30B-A3B against its baseline Qwen3-30B-A3B-Thinking-2507 on general, agentic memory, and dialogue memory benchmarks. Results show that QwenLong-L1.5 maintains or improves performance across most tasks, with notable gains in AIME25 (+3.65), Memory-KV (+5.80), and LongMemEval (+15.60), indicating effective generalization of long-context reasoning skills to out-of-domain tasks.
The authors evaluate ablations of the AEPO algorithm on Qwen3-4B-Thinking-2507, testing combinations of task-balanced sampling and batch standardization. Results show that adding task-batch standardization yields the highest average score of 58.62, with notable gains on Frames and CorpusQA, while MRCR performance remains lower than with task-balanced sampling alone. This suggests that task-batch standardization improves overall performance but may not uniformly benefit all task types.
The authors evaluate QwenLong-L1.5-30B-A3B against flagship and lightweight reasoning models on LongBench-V1 QA benchmarks, showing it outperforms its baseline Qwen3-30B-A3B-Thinking-2507 by +3.30 points on average. Notable gains are observed on Musique (+7.00) and NarrativeQA (+9.00), while Qasper shows a slight decline (-3.00). The model matches or exceeds top performers like Gemini-2.5-Pro and DeepSeek-R1-0528 on most subtasks, demonstrating competitive multi-hop reasoning capabilities.
The authors use Qwen3-4B-Thinking-2507 as a base model and compare ablation variants of their AEPO algorithm against GRPO. Results show that adding AEPO yields a 3.29-point average improvement over the base model and a 2.29-point gain over GRPO, with consistent performance boosts across all evaluated benchmarks including DocMath, Frames, and CorpusQA.
