Command Palette
Search for a command to run...
MotionEdit : Évaluation et apprentissage de l'édition d'images centrée sur le mouvement
MotionEdit : Évaluation et apprentissage de l'édition d'images centrée sur le mouvement
Yixin Wan Lei Ke Wenhao Yu Kai-Wei Chang Dong Yu
Résumé
Nous introduisons MotionEdit, un nouveau jeu de données dédié à l’édition d’images centrée sur le mouvement — une tâche consistant à modifier les actions et les interactions des sujets tout en préservant leur identité, leur structure et la plausibilité physique. Contrairement aux jeux de données existants, axés sur des changements d’apparence statique ou ne contenant que des modifications de mouvement rares et de faible qualité, MotionEdit fournit des paires d’images de haute fidélité illustrant des transformations de mouvement réalistes, extraites et vérifiées à partir de vidéos continues. Cette tâche nouvelle n’est pas seulement scientifiquement exigeante, mais aussi d’une importance pratique significative, car elle alimente des applications ultérieures telles que la synthèse vidéo contrôlée par image (frame-controlled video synthesis) et l’animation.Pour évaluer la performance des modèles sur cette tâche novatrice, nous proposons MotionEdit-Bench, un benchmark qui met les modèles à l’épreuve en matière d’édition centrée sur le mouvement, et mesure leur performance à l’aide de métriques génératives, discriminatives et basées sur les préférences. Les résultats du benchmark révèlent que l’édition du mouvement reste un défi majeur pour les modèles d’édition par diffusion d’avant-garde actuels. Pour combler ce manque, nous proposons MotionNFT (Motion-guided Negative-aware Fine Tuning), un cadre de post-entraînement qui calcule des récompenses d’alignement du mouvement en fonction de la qualité de correspondance entre le flux de mouvement entre l’image d’entrée et l’image modifiée par le modèle, et le flux de mouvement réel (ground-truth), guidant ainsi les modèles vers des transformations de mouvement plus précises. Des expériences étendues sur FLUX.1 Kontext et Qwen-Image-Edit montrent que MotionNFT améliore de manière cohérente la qualité d’édition et la fidélité du mouvement des modèles de base sur cette tâche, sans compromettre leur capacité générale d’édition, démontrant ainsi son efficacité.
One-sentence Summary
Tencent AI and University of California, Los Angeles researchers introduce MotionEdit, a high-fidelity dataset and benchmark for motion-centric image editing, and propose MotionNFT, a post-training framework that uses motion alignment rewards to improve motion transformation accuracy in diffusion models while preserving identity and structure, enabling precise, instruction-followed motion edits for applications in animation and video synthesis.
Key Contributions
- MotionEdit introduces a high-quality dataset and benchmark for motion-centric image editing, addressing the lack of realistic, instruction-following motion transformations in existing datasets by providing paired image data with accurate, physically plausible action changes extracted from continuous video frames.
- The paper proposes MotionNFT, a post-training framework that uses optical flow-based motion alignment rewards within a negative-aware fine-tuning setup to guide diffusion models toward more accurate and coherent motion edits while preserving identity and scene structure.
- Experiments on FLUX.1 Kontext and Qwen-Image-Edit show that MotionNFT significantly improves motion fidelity and editing accuracy over base and commercial models, with benchmark results on MotionEdit-Bench demonstrating consistent gains across generative, discriminative, and human preference metrics.
Introduction
The authors leverage recent advances in text-guided image editing to address a critical gap: the inability of existing models to accurately modify motion, pose, or interactions in images while preserving visual consistency. While current systems excel at static edits like changing colors or replacing objects, they struggle with dynamic changes such as adjusting a person’s posture or altering object interactions—limitations rooted in datasets that either ignore motion or provide low-quality, incoherent motion edit examples. To tackle this, the authors introduce MOTIONEDIT, a high-quality benchmark with precisely paired image sequences derived from high-resolution videos, enabling faithful and diverse motion editing evaluation across categories like posture, orientation, and interaction. They further propose MotionNFT, a reinforcement learning framework that uses optical flow as a motion-centric reward signal to guide edits toward physically plausible and geometrically accurate outcomes, outperforming existing models in both motion accuracy and visual coherence.
Dataset
- The authors use the MotionEdit dataset, a high-quality collection designed for motion-centric image editing, where the goal is to modify subject actions and interactions while preserving identity, structure, and scene consistency.
- The dataset is built from two synthetic video sources: ShareVeo3 (based on Veo-3) and the KlingAI Video Dataset, both generated by state-of-the-art text-to-video models that provide sharp, temporally coherent videos with stable subjects and backgrounds.
- Frame pairs are extracted by segmenting videos into 3-second clips and sampling the first and last frames, capturing natural motion transitions grounded in real video kinematics.
- Each pair undergoes automated filtering using Google’s Gemini MLLM to ensure: (1) setting consistency (stable background, viewpoint, lighting), (2) meaningful motion change (e.g., “not holding cup → drinking”), (3) subject integrity (no occlusion, distortion, or disappearance), and (4) high visual quality.
- Editing instructions are generated by refining MLLM-produced motion summaries into imperative, user-friendly prompts (e.g., “Make the woman turn her head toward the dog”) using a prompt standardization method adapted from prior work.
- The final dataset contains 10,157 high-fidelity (input image, instruction, target image) triplets—6,006 from Veo-3 and 4,151 from KlingAI—with a 90/10 random split yielding 9,142 training samples and 1,015 evaluation samples.
- The evaluation set forms MotionEdit-Bench, a benchmark for assessing motion editing performance across generative, discriminative, and human preference metrics.
- Data covers six motion edit categories: Pose/Posture, Locomotion/Distance, Object State/Formation, Orientation/Viewpoint, Subject–Object Interaction, and Inter-Subject Interaction.
- The authors use the training split to apply MotionNFT, a fine-tuning framework that computes motion alignment rewards via optical flow, guiding models to better match ground-truth motion direction and magnitude during editing.
- No cropping or spatial resizing is mentioned; processing focuses on metadata construction through MLLM-based validation and instruction generation, ensuring semantic and visual fidelity across pairs.
Method
The authors leverage MotionNFT, a post-training framework built atop Diffusion Negative-aware Finetuning (NFT), to enhance motion editing capabilities in diffusion models. The core innovation lies in integrating optical-flow-based motion alignment signals into the NFT training loop, enabling the model to learn not only what motion to produce but also what motion to avoid, guided by geometrically grounded reward signals.
The framework operates on triplets of input images: the original image, the model-generated edited image, and a ground-truth edited image. As shown in the figure below, the MotionNFT reward pipeline begins with candidate sampling from a Flow Matching Model (FMM) conditioned on an edit prompt. The model’s output is then compared against the ground-truth edit using a pretrained optical flow estimator. Both the predicted motion (between input and edited image) and the ground-truth motion (between input and ground-truth image) are computed as 2D vector fields in RH×W×2, normalized by the image diagonal to ensure scale invariance across resolutions.
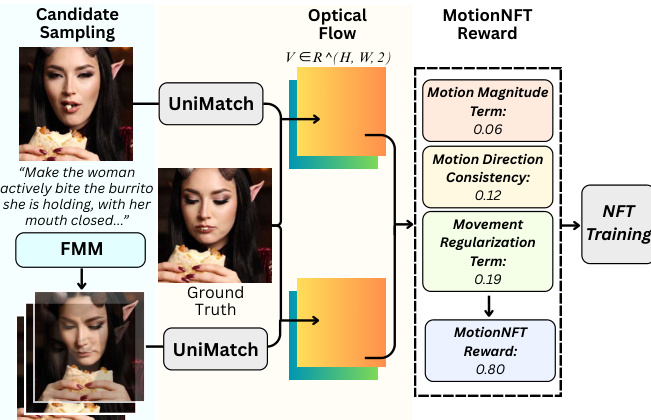
The reward is constructed from three distinct components. First, the motion magnitude consistency term Dmag measures the robust ℓ1 distance between normalized flow magnitudes, using an exponent q∈(0,1) to suppress outlier influence. Second, the motion direction consistency term Ddir computes a weighted cosine error between unit flow vectors, where weights are derived from the relative magnitude of ground-truth motion and thresholded to focus on regions with non-trivial motion. Third, the movement regularization term Mmove introduces a hinge penalty to prevent degenerate edits that exhibit minimal motion, comparing the spatial mean of predicted and ground-truth flow magnitudes with a small margin τ.
These components are aggregated into a composite distance Dcomb=αDmag+βDdir+λmoveMmove, where hyperparameters balance term contributions. The composite distance is then normalized and clipped to [0,1], inverted to form a continuous reward rcont=1−D~, and quantized into six discrete levels {0.0,0.2,0.4,0.6,0.8,1.0} to align with human preference modeling. This scalar reward is transformed into an optimality reward via group-wise normalization, which adjusts for reward distribution shifts across prompts and models.
The resulting reward signal is then fed into the DiffusionNFT training objective. The model learns to predict both a positive velocity vθ+(xt,c,t) — a convex combination of the old and current policy — and a negative velocity vθ−(xt,c,t) — a reflection of the old policy away from the current one. The training loss is a weighted sum of squared errors between these implicit policies and the target velocity v, with weights determined by the optimality reward r. This dual-policy learning mechanism allows the model to steer toward high-reward motion edits while actively avoiding low-reward, geometrically inconsistent ones.
Experiment
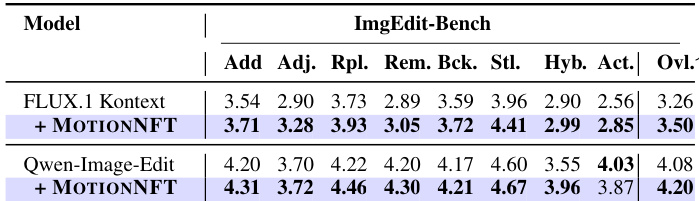
The authors evaluate MOTIONNFT on ImgEdit-Bench and find that applying it to both FLUX.1 Kontext and Qwen-Image-Edit improves or maintains performance across all editing subtasks, including addition, adjustment, replacement, removal, background, style, hybrid, and action categories. Results show that MOTIONNFT enhances general editing capability without sacrificing motion-specific performance, achieving higher overall scores for both base models.
The authors use MotionNFT to enhance FLUX.1 Kontext and Qwen-Image-Edit models, achieving the highest scores across all metrics on MotionEdit-Bench, including Overall, Fidelity, Preservation, Coherence, Motion Alignment Score, and Win Rate. Results show that MotionNFT consistently improves motion editing quality and alignment over both base models and all compared methods, with the Qwen-Image-Edit variant achieving the top performance overall.
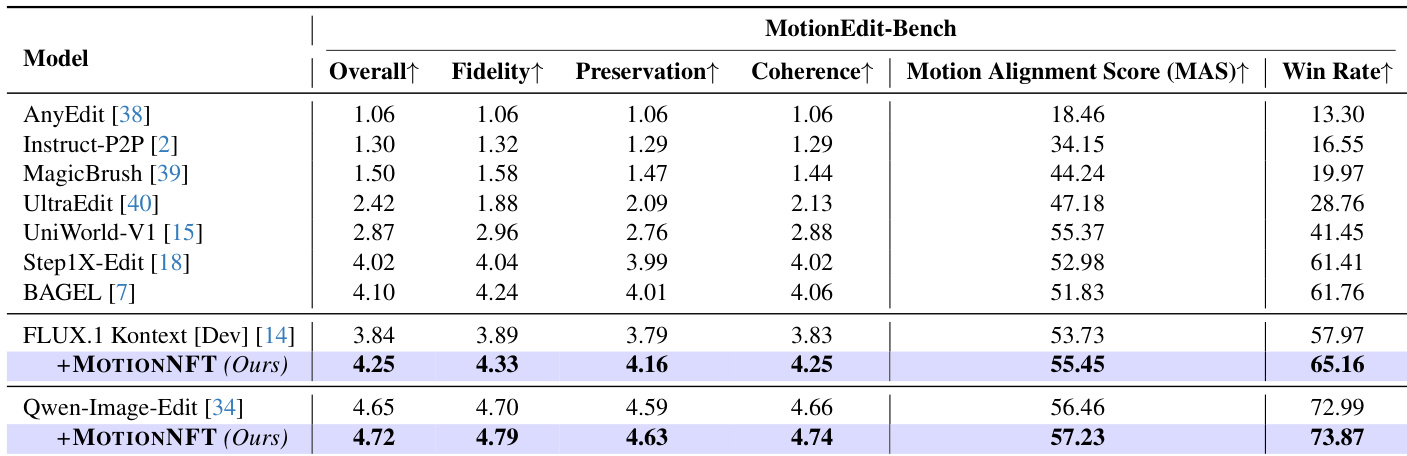
The authors evaluate MotionNFT on MotionEdit-Bench using FLUX.1 Kontext and Qwen-Image-Edit as base models, comparing against UniWorld-V2 and the base models alone. Results show that MotionNFT consistently improves Overall score, Motion Alignment Score (MAS), and Win Rate for both backbones, outperforming UniWorld-V2 and the base models. This demonstrates that incorporating optical flow-based motion guidance enhances motion editing precision without sacrificing overall image quality.

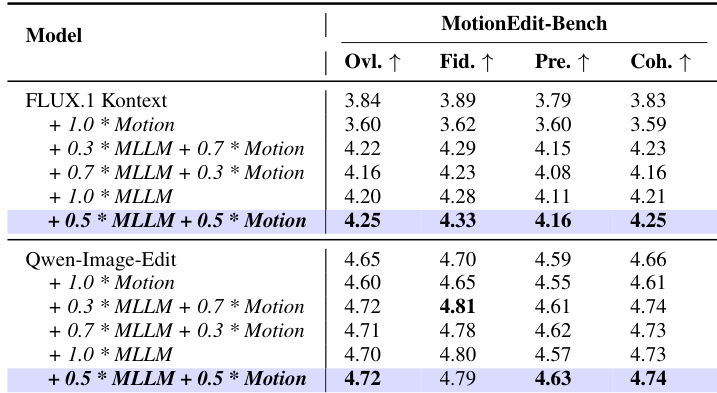
The authors evaluate MotionNFT by comparing different reward weightings between MLLM-based and optical flow-based motion alignment rewards. Results show that a balanced 0.5:0.5 weighting yields the highest overall performance across both FLUX.1 Kontext and Qwen-Image-Edit, outperforming configurations that rely solely on either reward type. This indicates that combining semantic guidance with explicit motion cues produces the most effective motion editing outcomes.