Command Palette
Search for a command to run...
Rapport technique LongCat-Image
Rapport technique LongCat-Image
Résumé
Nous introduisons LongCat-Image, un modèle fondamental novateur, open-source et bilingue (chinois-anglais) pour la génération d’images, conçu pour relever les défis fondamentaux liés à la mise en forme multilingue du texte, au réalisme photographique, à l’efficacité du déploiement et à l’accessibilité pour les développeurs, qui persistent dans les modèles actuels les plus performants. 1) Nous atteignons cet objectif grâce à des stratégies rigoureuses de curations de données tout au long des phases de pré-entraînement, d’entraînement intermédiaire et de fine-tuning supervisé (SFT), complétées par une utilisation coordonnée de modèles de récompense soigneusement sélectionnés durant la phase d’apprentissage par renforcement (RL). Cette approche établit le modèle comme une nouvelle référence (SOTA) en matière de performance, offrant des capacités exceptionnelles de rendu de texte et un réalisme photographique remarquable, tout en améliorant significativement la qualité esthétique. 2) Notamment, il fixe une nouvelle norme industrielle pour le rendu des caractères chinois. En prenant en charge même les caractères complexes et rares, il dépasse à la fois les solutions open-source et commerciales majeures en termes de couverture, tout en atteignant une précision supérieure. 3) Le modèle atteint une efficacité remarquable grâce à sa conception compacte. Avec un modèle de diffusion central de seulement 6 milliards de paramètres, il est nettement plus petit que les architectures courantes dans le domaine, telles que les modèles à mélanges d’experts (MoE) de près de 20 milliards ou plus. Cette caractéristique garantit une utilisation minimale de la mémoire VRAM et une inférence rapide, réduisant considérablement les coûts de déploiement. Au-delà de la génération d’images, LongCat-Image excelle également dans le traitement d’images, obtenant des résultats SOTA sur des benchmarks standards, avec une cohérence d’édition supérieure à celle des autres travaux open-source. 4) Pour pleinement soutenir la communauté, nous avons mis en place l’écosystème open-source le plus complet à ce jour. Nous mettons à disposition non seulement plusieurs versions du modèle pour la génération texte-image et l’édition d’images, y compris des points de contrôle après les phases d’entraînement intermédiaire et post-entraînement, mais aussi l’intégralité de la chaîne d’outils nécessaire au processus d’entraînement. Nous sommes convaincus que la nature ouverte de LongCat-Image fournira un soutien solide aux développeurs et chercheurs, poussant ainsi les frontières de la création de contenus visuels.
One-sentence Summary
The Meituan LongCat Team proposes LongCat-Image, a 6B-parameter bilingual (Chinese-English) diffusion model that achieves state-of-the-art performance in multilingual text rendering, photorealism, and image editing through curated data pipelines and reward-guided training, outperforming larger MoE models in efficiency and Chinese character coverage while enabling low-cost deployment via a comprehensive open-source ecosystem.
Key Contributions
-
LongCat-Image introduces a novel, bilingual (Chinese-English) foundation model for image generation that achieves state-of-the-art performance in text rendering, photorealism, and aesthetic quality through rigorous data curation across pre-training, mid-training, and SFT stages, along with the use of curated reward models during RLHF to guide the model toward real-world visual fidelity.
-
It sets a new standard for Chinese character rendering by supporting complex and rare characters with superior coverage and accuracy, outperforming both open-source and commercial models, thanks to a dedicated data and training strategy tailored for multilingual text fidelity.
-
The model achieves high efficiency with a compact 6B-parameter diffusion architecture—significantly smaller than typical 20B+ MoE models—enabling low VRAM usage, fast inference, and reduced deployment costs, while also delivering SOTA results in image editing with strong consistency on standard benchmarks.
Introduction
The authors introduce LongCat-Image, a lightweight, bilingual (Chinese-English) foundation model for image generation and editing, addressing key challenges in multilingual text rendering, photorealism, and deployment efficiency. Prior work has relied on large-scale models—often 20B or more, including MoE architectures—leading to high computational costs, slow inference, and limited accessibility, despite only marginal gains in quality. Additionally, existing models struggle with accurate rendering of complex Chinese characters and maintaining visual consistency in image editing. The authors’ main contribution is a 6B-parameter diffusion model that achieves state-of-the-art performance across benchmarks while significantly reducing VRAM usage and inference latency. This is enabled by a rigorous, multi-stage data curation pipeline that excludes AIGC-generated content during early training, uses hand-curated synthetic data in SFT, and incorporates an AIGC detection model as a reward signal in RL to boost realism. For Chinese text rendering, they employ character-level encoding and synthetically generated text-in-image data with clean backgrounds, achieving superior coverage and accuracy. In image editing, they use a separate model initialized from mid-training weights, combined with multi-task joint training and high-quality human-annotated data, to achieve SOTA consistency and instruction-following performance. Finally, they release a complete open-source ecosystem, including multiple checkpoints and full training code, to accelerate community-driven innovation.
Dataset
-
The dataset comprises 1.2 billion samples curated from diverse sources, including open-source repositories, synthetic pipelines, video sequences, and web-scale interleaved corpora, forming a large-scale, high-quality training corpus for generative modeling.
-
Key subsets include:
- Open-source datasets (OmniEdit, OmniGen2, NHREdit): rigorously cleaned and instruction-rewritten to produce high-fidelity source-target image pairs.
- Synthesized data: generated via expert models for specific editing tasks (e.g., object manipulation, style transfer, background alteration), with MLLMs crafting instructions and expert models producing target images.
- Interleaved web corpora: mined for implicit editing signals from natural image-text sequences, filtered and rewritten for training suitability, though scale remains limited due to resource intensity.
-
Data is processed through a four-stage pipeline:
- Filtering: removes duplicates via MD5 hashing and SigLIP-based similarity; excludes low-resolution images (shortest edge < 384px), extreme aspect ratios (0.25–4.0), watermarked content, and AI-generated content (AIGC) using an internal detector; retains only images with LAION-Aesthetics scores ≥ 4.5.
- Metadata extraction: five attributes are derived—category, style, named entities, OCR text, and aesthetics—using VLMs and specialized models.
- Multi-granularity captioning: VLMs generate captions ranging from entity-level tags to detailed descriptions, informed by extracted metadata and prompt templates.
- Stratification: data is organized into a pyramid structure based on style quality and content diversity to support progressive, multi-stage training.
-
Aesthetic quality is evaluated through a dual-dimensional framework: Quality (technical fidelity via signal statistics and deep reference-free metrics like MUSIQ and Q-Align) and Artistry (photographic merit via VLM-based analysis of composition, lighting, and tonality, complemented by Q-Align-Aesthetics).
-
For image editing training, a separate high-fidelity SFT dataset is constructed from real photos, professional retouches, and synthetic sources, with strict human-in-the-loop filtering to ensure structural alignment between source and edited images—critical for maintaining generation stability and consistency.
-
The model is trained using a mixture of T2I and editing data, with the editing training split incorporating diverse instruction types and task granularities, including reference-based generation, structural modification, and viewpoint transformation.
-
Text rendering capabilities are enhanced through OCR integration, with extracted text incorporated into captions and validated via human-in-the-loop checks, especially for complex layouts like posters, menus, and signage.
-
The dataset supports evaluation through CEdit-Bench, a new benchmark with 1,464 bilingual editing pairs across 15 fine-grained task categories, designed to overcome limitations in existing benchmarks by improving task coverage, granularity, and instruction diversity.
Method
The authors leverage a hybrid MM-DiT (Multimodal Diffusion Transformer) architecture, building upon the FLUX.1-dev framework, to achieve high-fidelity image generation. The core model is a DiT (Diffusion Transformer) that processes latent representations of images and text. The overall framework design is illustrated in the figure below, which shows the model's structure and data flow.

The model employs a double-stream attention mechanism in its initial layers, which processes both text and image latents separately, before transitioning to a single-stream mechanism in the subsequent layers. This design maintains a parameter balance with a ratio of approximately 1:2 between double-stream and single-stream blocks. For the VAE component, the implementation from FLUX.1-dev is used, which compresses input images by a factor of 8× spatially and then applies 2×2 token merging, resulting in a final sequence length of 16×16H×W before entering the DiT module.
The text encoder, responsible for embedding user prompts into continuous representations, is a unified Qwen2.5VL-7B model. This choice enhances multilingual compatibility, particularly for Chinese, and avoids the conventional injection of text embeddings into timestep embeddings for adaLN modulation, as empirical evidence suggests this provides negligible performance gains. For visual text rendering, a character-level tokenizer is used for content within quotation marks, which improves data efficiency and convergence without the overhead of specialized encoders.
Positional embedding is handled by a 3D variant of Multimodal Rotary Position Embedding (MRoPE). The first dimension of this embedding is used for modality differentiation, distinguishing between noise latents, text latents, and reference image latents in editing tasks. The remaining two dimensions encode 2D spatial coordinates for images, while for text, both coordinates are set to the same value, analogous to 1D-RoPE, enabling flexible generation across arbitrary aspect ratios and seamless interaction with other modalities.
The model's training process is structured into a multi-stage pipeline, as illustrated in the figure below. This pipeline consists of three distinct phases: Pre-training, Mid-training, and Post-training. The pre-training phase uses a progressive multi-resolution strategy to efficiently acquire global semantic knowledge and refine high-frequency details. The mid-training phase acts as a crucial bridge, refining the model's baseline generation quality by training on a high-fidelity, curated dataset to elevate aesthetic priors and visual realism. The post-training phase focuses on alignment and stylization, comprising Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). The SFT stage optimizes for photorealistic attributes and stylistic fidelity using a hybrid dataset of real and synthetic data, while the RL stage employs advanced alignment techniques like DPO and GRPO to enhance instruction adherence and quality.

For image editing, the model architecture is modified to include an image conditioning branch. Reference images are encoded into VAE latents and distinguished from noised latents by manipulating the first dimension of the 3D RoPE embeddings. These reference tokens are then concatenated with noised latents along the sequence dimension to serve as input for the diffusion visual stream. The source image and instructions are fed into the multimodal encoder (Qwen2.5-VL), and a distinct system prompt is used to differentiate editing tasks from standard text-to-image generation. The overall schematic of this model architecture is illustrated in the figure below.

Experiment
- Stratification experiment validates a staged training approach: pre-training with limited artistic data (0.5%) prevents photorealistic generation collapse; mid-training gradually increases stylized data to 2.5% for style enhancement while preserving realism; SFT phase uses curated real and synthetic data to align with human aesthetic preferences, enabling rapid convergence.
- Progressive mixed-resolution training (256px → 512px → 512–1024px) with bucket sampling and dynamic synthetic text data sampling improves training stability and text rendering accuracy, especially for rare Chinese characters, with synthetic data phased out in final pre-training.
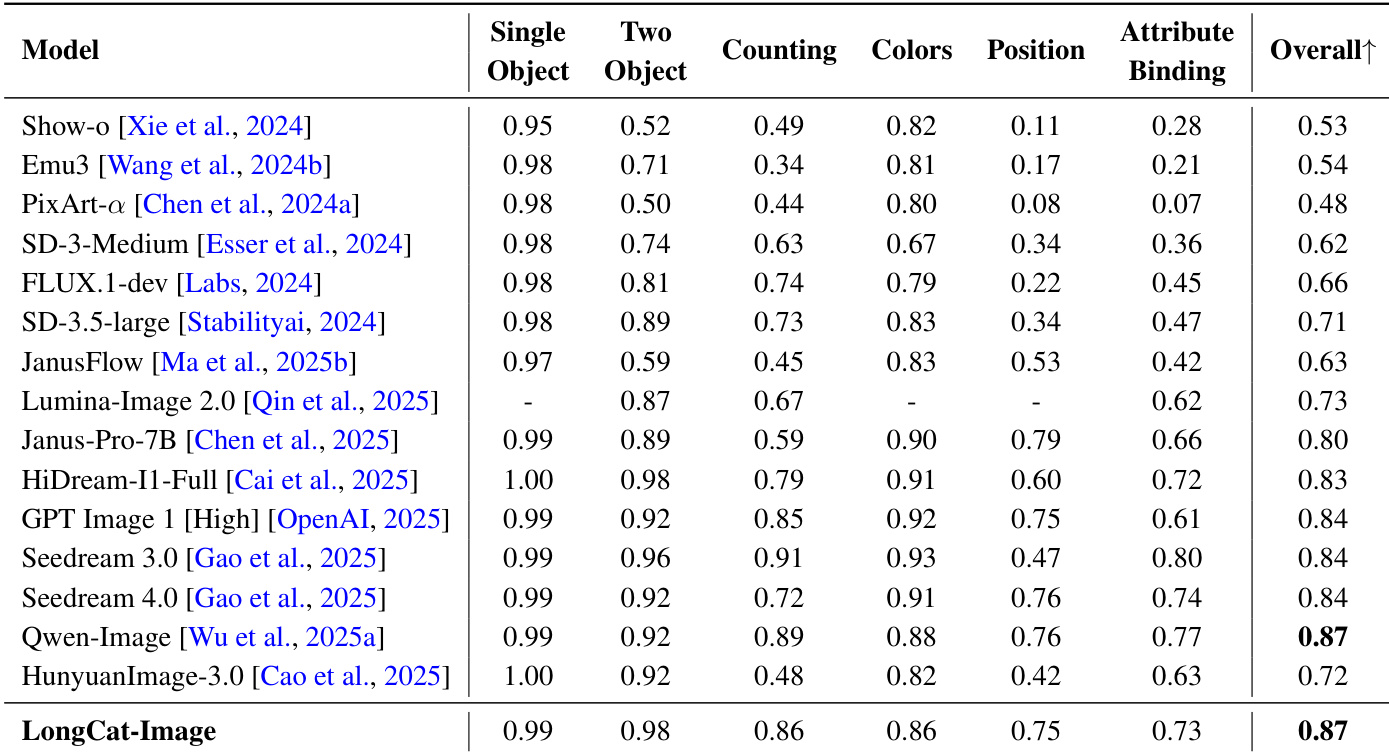
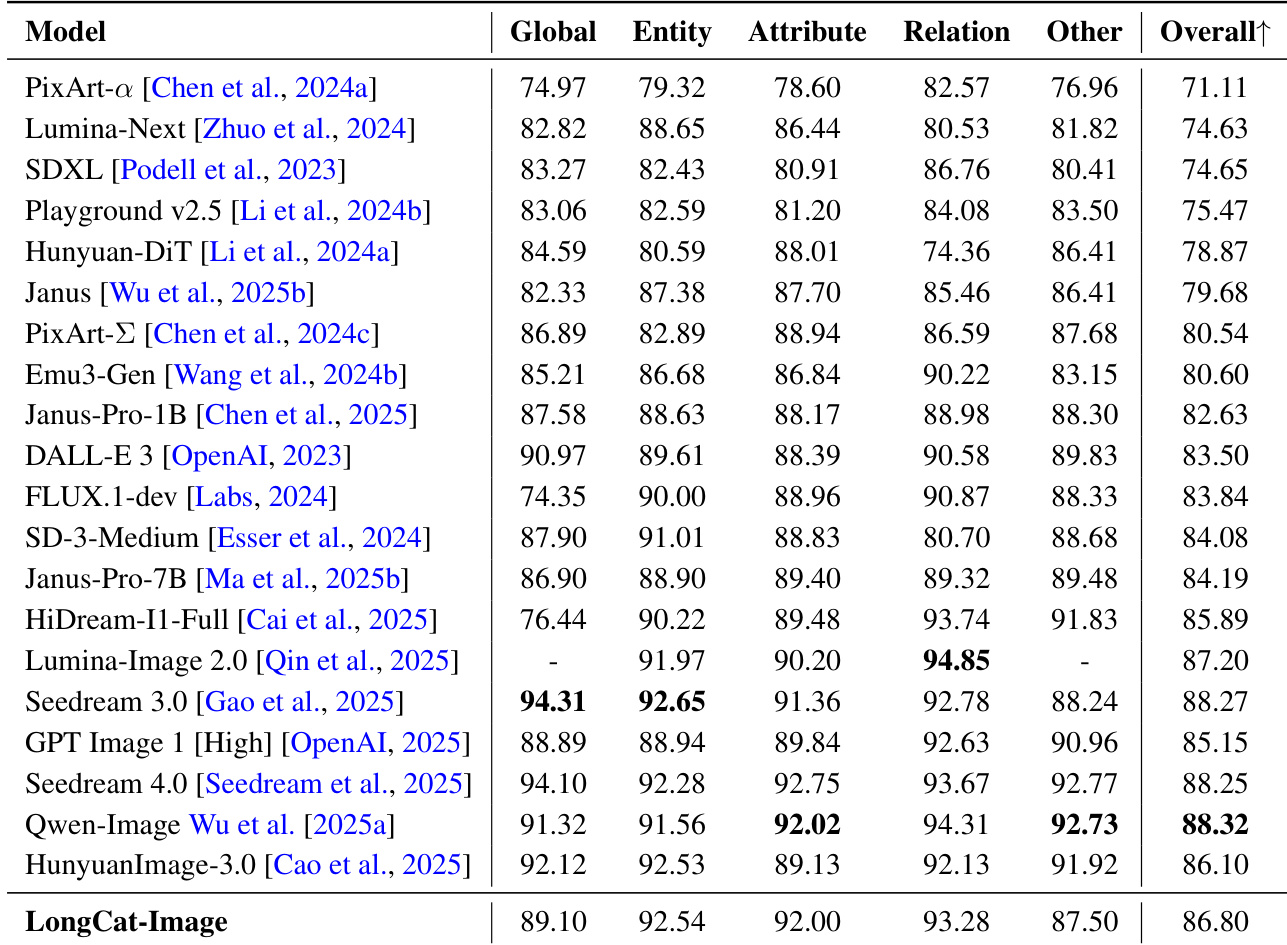
- GenEval, DPG-Bench, and WISE evaluations show LongCat-Image achieves SOTA or competitive performance in text-image alignment, compositional reasoning, and world knowledge, demonstrating strong semantic understanding and fine-grained controllability.
- GlyphDraw2, CVTG-2K, ChineseWord, and Poster&SceneBench evaluations confirm LongCat-Image achieves SOTA results in complex Chinese and English text rendering, including multi-region layouts and long-tail character coverage, with superior performance in intricate character structures and real-world scene integration.
- Human evaluation (MOS) on 400 prompts shows LongCat-Image outperforms HunyuanImage 3.0 across all metrics, matches Qwen-Image in alignment and plausibility, exceeds Qwen-Image and Seedream 4.0 in visual realism, and delivers competitive aesthetic quality.
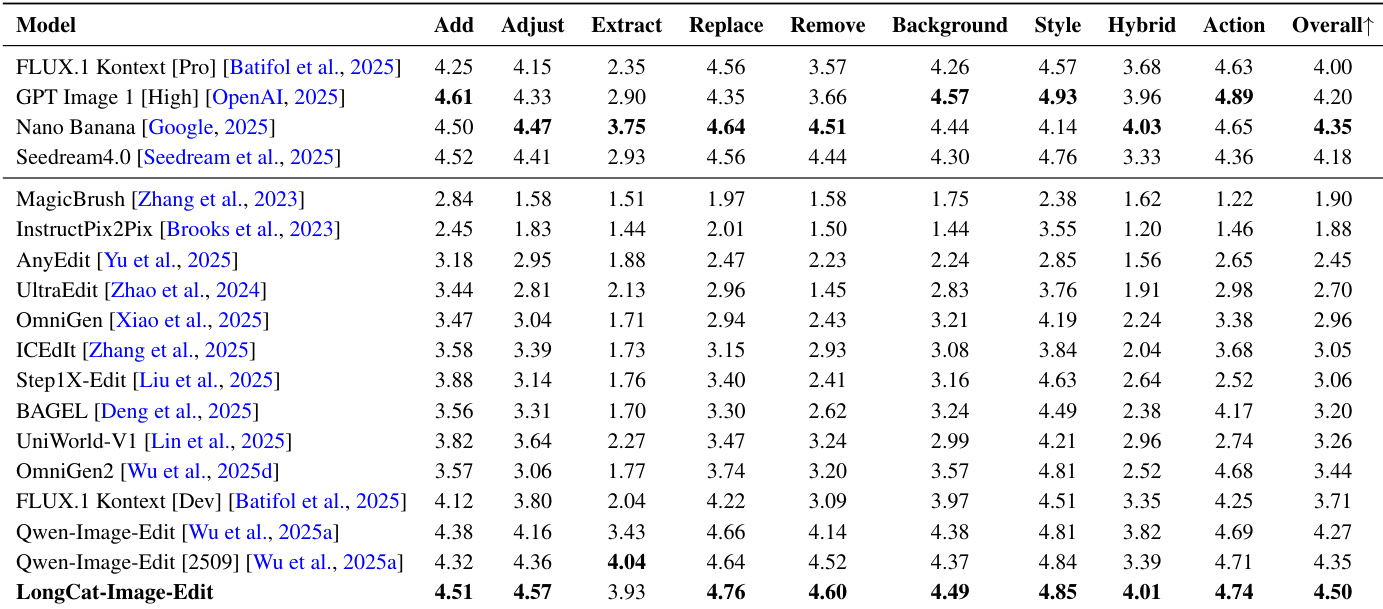
- CEdit-Bench, GEdit-Bench, and ImgEdit-Bench quantitative evaluations demonstrate strong performance in image editing tasks, with LongCat-Image-Edit achieving SOTA results on CEdit-Bench and GEdit-Bench, and outperforming Qwen-Image-Edit and FLUX.1 Kontext [Pro] in both comprehensive quality and consistency.
- Side-by-side human evaluation (SBS) shows LongCat-Image-Edit achieves higher win rates than Qwen-Image-Edit and FLUX.1 Kontext [Pro] in comprehensive quality and consistency, though a gap remains compared to commercial models Nano Banana and Seedream 4.0.
- Qualitative results confirm superior performance in multi-turn editing, portrait and human-centric editing, style transfer, object manipulation, scene text editing, and viewpoint transformation, with consistent preservation of identity, layout, and texture across complex, multi-step edits.
Results show that LongCat-Image-Edit achieves the highest overall score of 4.50 on the CEdit-Bench, outperforming all compared models including commercial systems like FLUX.1 Kontext [Pro] and Qwen-Image-Edit. The model demonstrates strong performance across all editing categories, particularly excelling in action, style, and hybrid editing tasks, with notable improvements in consistency and comprehensive quality.
Results show that LongCat-Image achieves an average score of 0.95 across all evaluated benchmarks, outperforming HunyuanImage-3.0 and approaching the performance of Seedream 4.0, which achieves an average score of 0.97. The model demonstrates strong capabilities in both English and Chinese text rendering tasks, with particularly high scores on the Complex-en and Poster-zh subsets, indicating robust performance in handling complex textual content and bilingual scenarios.

Results show that LongCat-Image achieves the highest average word accuracy of 0.8658, outperforming Seedream 4.0 and Qwen-Image, while also achieving a competitive NED score of 0.9361 and a CLIPScore of 0.7859. The model demonstrates strong performance in multi-region text rendering, particularly in handling complex text layouts, though it lags behind Seedream 4.0 in NED and Qwen-Image in CLIPScore.

The authors use a comprehensive evaluation framework to assess LongCat-Image's performance across multiple dimensions, including text-image alignment, entity recognition, attribute binding, and relational reasoning. Results show that LongCat-Image achieves strong performance across all categories, with particularly high scores in entity and attribute tasks, and ranks among the top models in overall performance, demonstrating its robustness in handling complex compositional and semantic constraints.
Results show that LongCat-Image achieves an overall score of 0.87 on the GenEval benchmark, matching the best-performing model Qwen-Image and outperforming all other models listed. The model demonstrates strong capabilities in attribute binding, counting, and position understanding, with particularly high scores in single-object and two-object tasks, indicating robust fine-grained control over compositional elements.