Command Palette
Search for a command to run...
L'attention à fenêtre courte permet la mémoire à long terme
L'attention à fenêtre courte permet la mémoire à long terme
Loïc Cabannes Maximilian Beck Gergely Szilvasy Matthijs Douze Maria Lomeli Jade Copet Pierre-Emmanuel Mazaré Gabriel Synnaeve Hervé Jégou
Résumé
Des travaux récents montrent que les architectures hybrides combinant des couches d’attention softmax à fenêtre glissante et des couches de réseaux de neurones récurrents (RNN) linéaires surpassent chacune de ces architectures prises séparément. Toutefois, l’impact de la longueur de la fenêtre ainsi que l’interaction entre les couches d’attention softmax et les RNN linéaires restent peu étudiés. Dans ce travail, nous introduisons SWAX, une architecture hybride composée de couches d’attention à fenêtre glissante et de couches RNN linéaires xLSTM.Une découverte contre-intuitive avec SWAX est que des fenêtres glissantes plus grandes n’améliorent pas les performances sur les contextes longs. En réalité, une attention à fenêtre courte encourage le modèle à mieux entraîner la mémoire à long terme de l’xLSTM, en réduisant sa dépendance à l’égard du mécanisme d’attention softmax pour la récupération de contextes longs.Le principal inconvénient des petites fenêtres glissantes réside dans leur impact négatif sur les tâches à contexte court, qui pourraient être améliorées grâce à l’information provenant de fenêtres glissantes de taille modérément plus grande. Pour résoudre ce problème, nous entraînons SWAX en modifiant de manière stochastique la taille de la fenêtre glissante, forçant ainsi le modèle à tirer parti à la fois d’une fenêtre contextuelle plus étendue et de la mémoire de l’xLSTM. L’architecture SWAX entraînée avec des tailles de fenêtre stochastiques surpasse significativement l’attention à fenêtre fixe, tant sur les problèmes à court que sur ceux à long contexte.
One-sentence Summary
Researchers from Meta FAIR, ENS Paris Saclay, and Johannes Kepler University introduce SWAX, a hybrid architecture combining sliding-window attention and xLSTM layers, revealing that shorter windows paradoxically enhance long-context recall by forcing reliance on xLSTM’s memory, and propose stochastic window training to balance short- and long-context performance.
Key Contributions
- SWAX introduces a hybrid architecture combining sliding-window softmax attention with xLSTM linear RNN layers, revealing that shorter attention windows unexpectedly improve long-context retrieval by compelling the model to rely more on the xLSTM’s persistent memory.
- Contrary to intuition, increasing the sliding window size degrades long-context performance in hybrid models, as it reduces pressure on the RNN to develop robust long-term memory, despite helping with short-context tasks.
- Training SWAX with stochastically varying window sizes (e.g., 128/2048) bridges the gap between short- and long-context performance, significantly outperforming fixed-window baselines on benchmarks including RULER Needle-In-A-Haystack and perplexity tasks.
Introduction
The authors leverage hybrid architectures that combine sliding window attention with linear RNNs—specifically xLSTM—to address the tradeoff between memory efficiency and long-context recall in large language models. While softmax attention offers strong recall over long sequences, its unbounded memory and compute costs make it impractical for very long inputs; linear RNNs offer constant cost per token but lag in recall. Prior hybrid designs assumed longer sliding windows improve performance, but the authors show the opposite: short windows actually improve long-context retention by forcing the model to rely more on the RNN’s memory. Their key contribution is SWAX, a model trained with stochastically varying window sizes, which simultaneously boosts performance on both short- and long-context tasks by dynamically balancing attention and recurrent memory usage.
Dataset

- The authors use two code generation benchmarks: HumanEval+ (an extension of HumanEval) and MBPP, both designed to evaluate functional correctness and Python task performance of AI models.
- For common sense and general reasoning, they evaluate across eight benchmarks: HellaSWAG, ARC, PIQA, SIQA, Winogrande, NaturalQuestions, RACE, and TQA — all consisting of question-answer or multiple-choice formats to test natural language understanding and reasoning.
- These benchmarks are not used for training but serve as evaluation tools to measure model performance after training.
- No dataset composition, filtering, or preprocessing details are provided in this section; the focus is strictly on downstream evaluation.
- No cropping, metadata construction, or mixture ratios are mentioned — the data is used in its standard benchmark form for post-training assessment.
Method
The authors leverage a hybrid architecture that combines sliding window attention (SWA) and linear recurrent neural network (RNN) components to address the computational and memory challenges associated with long-context modeling in transformer-based systems. The framework alternates between layers of sliding window attention and linear attention implemented via xLSTM, a scalable RNN architecture. The xLSTM component is selected due to its demonstrated performance on language tasks and availability of efficient Triton kernels, with the matrix memory cell (mLSTM) preferred over the scalar variant (sLSTM) for its superior empirical results. This design enables a balance between local fidelity and long-range memory retention, where the SWA layers provide high-fidelity local reasoning within a fixed window, while the linear attention layers maintain a compressed, unbounded memory state for long-context recall.
As shown in the figure below, the hybrid architecture interleaves SWA and xLSTM layers in a 1:1 ratio, forming a sequence of alternating components. This inter-layer hybridization allows the model to benefit from both the efficiency of sliding window attention and the unbounded memory capacity of linear attention. The sliding window size is varied across experiments, with configurations evaluated at 128, 256, 512, 1024, and 2048 tokens to assess the impact of window length on performance. Additionally, a stochastic training procedure is introduced, where the window size is randomly sampled from either 128 or 2048 for each training batch with equal probability. This strategy aims to reduce over-reliance on SWA layers during training, thereby enhancing the model’s ability to extrapolate to longer sequences by encouraging the linear attention layers to contribute more effectively during inference.
Experiment
- Evaluated hybrid SWA-LA models (1.4B and 7B) on RULER NIAH and short-context benchmarks, confirming hybrids outperform pure architectures in long-context recall despite fewer global layers, due to SWA handling local dependencies and LA specializing in long-range ones.
- Found shorter SWA window sizes (128–512) significantly improve long-context recall (e.g., ~30% accuracy at 131k tokens vs. near 0% for 2048-window models), as they force LA layers to learn long-range dependencies during training.
- Stochastic training (alternating 128/2048 windows, annealed in final 10%) achieves best of both worlds: matches or exceeds 2048-window models on short-context tasks while maintaining strong long-context performance (e.g., 16-point gain over 2048-window on average NIAH accuracy at 1.4B).
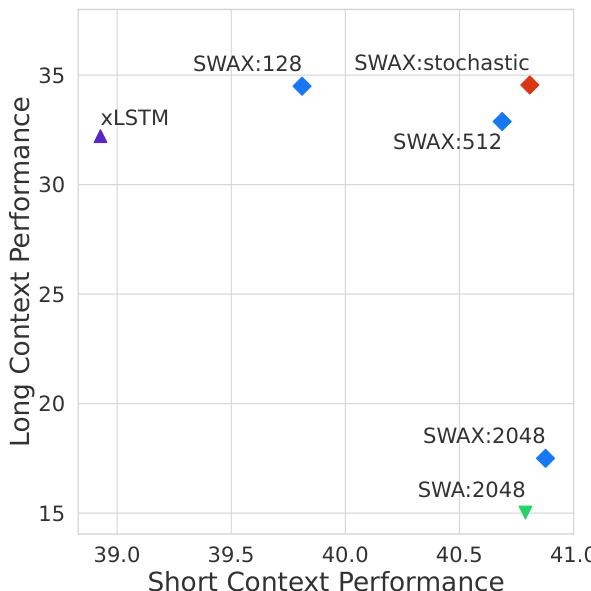
- Validated stochastic training on 7B scale and with Gated DeltaNet, confirming generalizability; also showed improved performance on LongBench, Babilong, and LongBench2 benchmarks.
- Pure SWA models with 2048 windows perform similarly to SWAX-2048, confirming SWAX-2048’s poor long-context recall stems from over-reliance on SWA layers rather than LA.
The authors evaluate the performance of SWAX models with different training window sizes on long-context benchmarks, finding that stochastic training with a small window size (128) outperforms fixed large window training (2048) in most cases. Specifically, the stochastic approach achieves higher average accuracy on LongBench and Babilong tasks compared to both fixed 128 and 2048 window models, indicating that stochastic window training improves both short- and long-context performance.
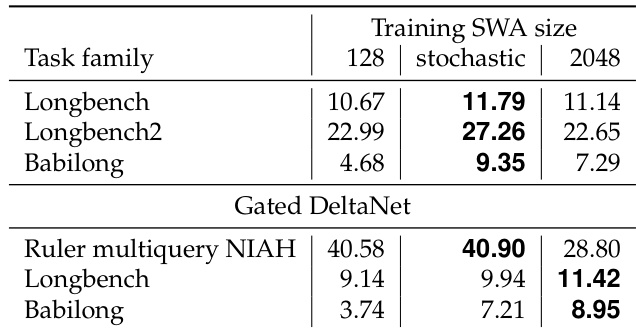
Results show that the SWAX:2048 model achieves high accuracy on short-context tasks but performs poorly on long-context recall, with near-zero accuracy at sequence lengths beyond 65k tokens. In contrast, the SWAX:128 model maintains significantly better long-context performance, outperforming SWAX:2048 by 16 accuracy points on average across RULER NIAH tasks, indicating that shorter window sizes improve extrapolation to longer sequences.
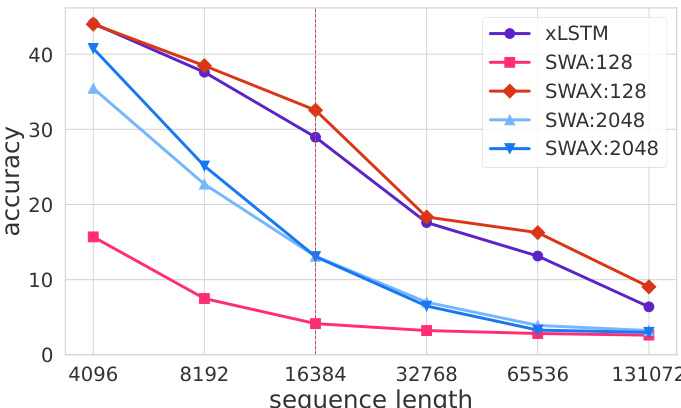
The authors use a hybrid architecture combining softmax sliding window attention (SWA) and linear attention (xLSTM) to investigate the impact of window size on long-context recall. Results show that models trained with a fixed long window of 2048 tokens perform poorly on long-context tasks, while those with shorter windows or stochastic window training achieve significantly better recall, indicating that over-reliance on local attention during training hinders long-context generalization.
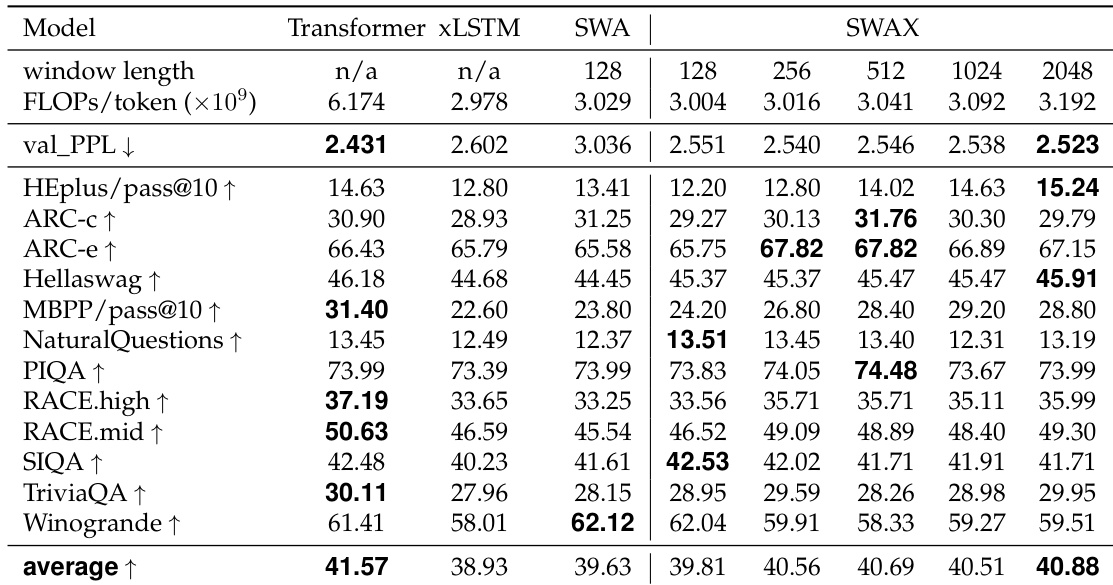
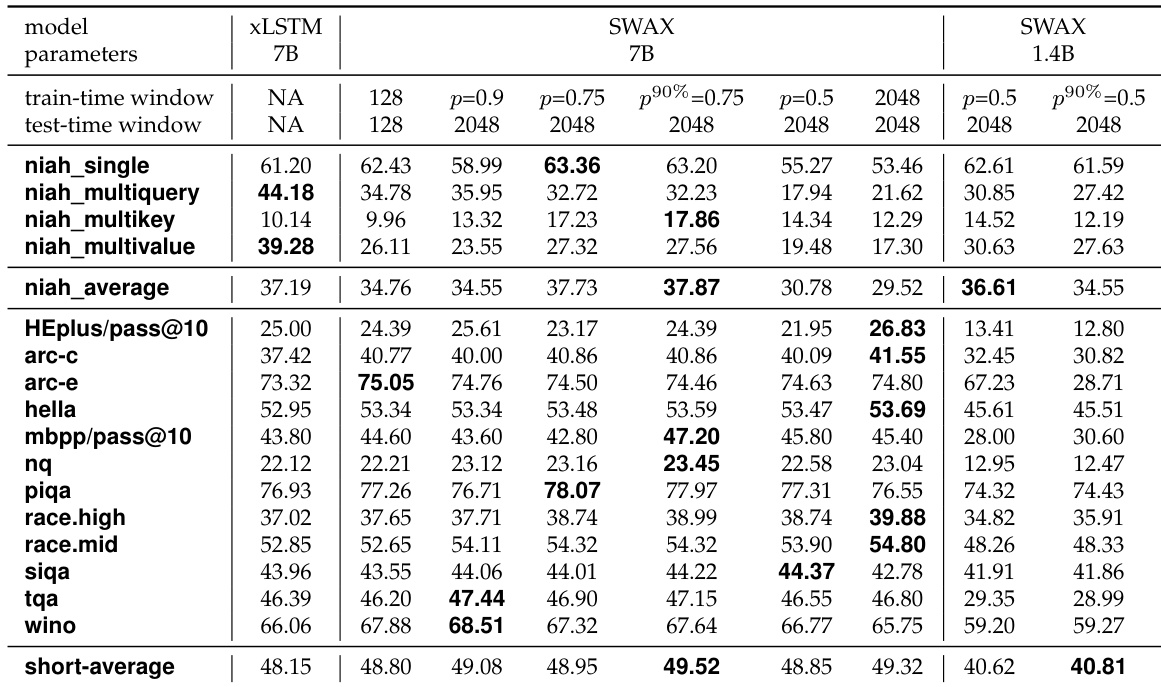
Results show that stochastic window size training improves short-context performance while maintaining strong long-context recall. At both 1.4B and 7B parameter scales, models trained with a stochastic window size achieve higher average performance on short-context tasks compared to fixed-window models, with the 7B model outperforming the fixed 2048 window variant. Long-context performance remains competitive, with stochastic training yielding results comparable to or better than models trained with a fixed short window.

The authors use a stochastic window size during training to balance short-context reasoning and long-context recall performance. Results show that models trained with stochastic window sizes achieve comparable or better short-context performance than those trained with fixed long windows, while maintaining or improving long-context recall, outperforming models trained with fixed long windows on tasks like RULER NIAH.