Command Palette
Search for a command to run...
QwenLong-L1 : Vers des modèles de raisonnement à grande échelle à longue portée grâce à l'apprentissage par renforcement
QwenLong-L1 : Vers des modèles de raisonnement à grande échelle à longue portée grâce à l'apprentissage par renforcement
Résumé
Les récents modèles de raisonnement à grande échelle (LRMs) ont démontré des capacités de raisonnement puissantes grâce à l'apprentissage par renforcement (RL). Ces progrès ont principalement été observés dans les tâches de raisonnement à contexte court. En revanche, étendre les LRMs pour qu’ils traitent efficacement et raisonnent sur des entrées à long contexte via le RL reste un défi critique non résolu. Pour combler cet écart, nous formalisons d’abord le paradigme du raisonnement à long contexte en apprentissage par renforcement, et identifions les principaux défis liés à l’inefficacité d’entraînement sous-optimale et à l’instabilité du processus d’optimisation. Pour relever ces défis, nous proposons QwenLong-L1, un cadre qui adapte les LRMs conçus pour un contexte court à des scénarios à long contexte grâce à une mise à l’échelle progressive du contexte. Plus précisément, nous utilisons une phase de fine-tuning supervisé d’initialisation (SFT) pour établir une politique initiale robuste, suivie d’une technique de RL par phases guidée par un programme pédagogique afin de stabiliser l’évolution de la politique, et enrichie d’une stratégie de tirage rétrospectif consciente de la difficulté afin d’inciter l’exploration de la politique. Des expériences menées sur sept benchmarks de réponse à des questions sur des documents à long contexte montrent que QwenLong-L1-32B surpassent des LRMs phares tels qu’OpenAI-o3-mini et Qwen3-235B-A22B, atteignant des performances comparables à celles de Claude-3.7-Sonnet-Thinking, ce qui démontre une performance leader parmi les LRMs les plus avancés actuellement disponibles. Ce travail contribue significativement au développement de LRMs pratiques à long contexte capables de raisonnement robuste dans des environnements riches en informations.
One-sentence Summary
The authors from Tongyi Lab propose QWENLONG-L1, a novel framework that enables long-context reasoning in large models via progressive context scaling, combining warm-up supervised fine-tuning, curriculum-guided phased reinforcement learning, and difficulty-aware retrospective sampling to overcome training inefficiency and instability—achieving state-of-the-art performance on seven long-context QA benchmarks, rivaling Claude-3.7-Sonnet-Thinking and outperforming models like OpenAI-o3-mini and Qwen3-235B-A22B.
Key Contributions
- Long-context reasoning in large reasoning models (LRMs) remains a critical challenge despite advances in short-context reinforcement learning (RL), primarily due to suboptimal training efficiency and unstable optimization caused by reduced output entropy and increased variance in longer sequences.
- The proposed QWENLONG-L1 framework addresses these issues through progressive context scaling, combining a warm-up supervised fine-tuning stage, curriculum-guided phased RL, and difficulty-aware retrospective sampling to stabilize policy evolution and enhance exploration.
- On seven long-context document question-answering benchmarks, QWENLONG-L1-32B achieves state-of-the-art performance, outperforming models like OpenAI-o3-mini and Qwen3-235B-A22B, and matching the performance of Claude-3.7-Sonnet-Thinking.
Introduction
Large reasoning models (LRMs) have made significant strides in short-context reasoning tasks through reinforcement learning (RL), enabling sophisticated problem-solving behaviors like chain-of-thought reasoning. However, extending these models to long-context scenarios—where they must ground reasoning in extensive, information-dense inputs—remains a major challenge due to suboptimal training efficiency and unstable optimization, caused by reduced output entropy and increased variance in longer sequences. Prior approaches lack structured frameworks for long-context RL, limiting their ability to scale effectively. The authors introduce QWENLONG-L1, the first RL framework specifically designed for long-context reasoning, which enables stable adaptation from short to long contexts via progressive context scaling. It combines a warm-up supervised fine-tuning stage, curriculum-guided phased RL, and a difficulty-aware retrospective sampling strategy to enhance exploration and stability. The framework leverages hybrid reward functions and group-relative RL algorithms to improve both precision and recall. Experiments on seven long-context document question-answering benchmarks show that QWENLONG-L1-32B outperforms leading models like OpenAI-o3-mini and Qwen3-235B-A22B, achieving performance on par with Claude-3.7-Sonnet-Thinking, demonstrating a significant advance in practical long-context reasoning.
Dataset
- The dataset consists of two main components: a reinforcement learning (RL) dataset and a supervised fine-tuning (SFT) dataset, designed to support long-context reasoning in language models.
- The RL dataset, DOCQA-RL-1.6K, contains 1,600 document-question-answer problems across three reasoning domains:
- Mathematical Reasoning: 600 problems sourced from DocMath, involving numerical reasoning over long, specialized documents such as financial reports.
- Logical Reasoning: 600 synthetic multiple-choice questions generated using DeepSeek-R1, based on real-world documents from legal, financial, insurance, and production domains.
- Multi-Hop Reasoning: 400 examples—200 from MultiHopRAG and 200 from Musique—focused on cross-document inference and information integration.
- The SFT dataset comprises 5,300 high-quality question-document-answer triplets distilled from DeepSeek-R1, carefully curated for quality, complexity, and diversity. Documents are filtered to ensure appropriate length and contextual precision.
- The authors use the SFT dataset as a strong initialization for the model before RL optimization, while the RL dataset is used for training with a mixture ratio that balances the three reasoning domains.
- All data is processed using the Qwen tokenizer to measure sequence length; documents are retained in their original form with minimal preprocessing to preserve context.
- No explicit cropping is applied, but metadata such as document source, reasoning type, and section references are constructed to support training and evaluation.
- Grounding behavior is demonstrated through step-by-step reasoning that references specific document sections, such as Note 7 or Note 14, showing how the model locates and verifies information across long texts.
Method
The authors leverage a reinforcement learning (RL) framework to train language models for long-context reasoning tasks, where the policy model must ground information from a long context c to generate accurate reasoning chains and answers to a given question x. The overall training process is structured around a progressive context scaling strategy, which divides the optimization into multiple phases to stabilize training from short to long contexts. In each phase, the policy model πθ is trained on inputs with context lengths within a specific range, gradually increasing the input length from an initial L1 to a maximum LK. This curriculum-guided approach ensures that the model learns to handle increasingly complex long-context scenarios in a controlled manner.

As shown in the figure below, the framework begins with a policy model that takes as input a question x and a context c, which can be either short (cshort) or long (clong), depending on the current training phase. The policy model generates a group of G outputs {yi}i=1G for a given input. These outputs are then evaluated by a hybrid reward mechanism that combines rule-based verification and LLM-as-a-judge components. The rule-based verification ensures strict correctness by performing exact string matching on the extracted answer, while the LLM-as-a-judge assesses semantic equivalence between the generated and gold answers, thereby mitigating false negatives from rigid string matching. The rewards from both components are combined using a maximum selection to form the final reward ri for each output.
The rewards are then used to compute advantages for policy updating. The framework employs group-relative RL algorithms, such as GRPO and DAPO, to estimate advantages without requiring a separate value network, which is computationally prohibitive for long-context inputs due to the quadratic complexity of attention mechanisms. In GRPO, the advantage for each token is computed by normalizing the group-level rewards, while DAPO introduces additional techniques for stability, including a dynamic sampling strategy to filter out examples with zero reward variance, a token-level loss to mitigate length bias, and overlong reward shaping to penalize excessively long outputs. The policy model is updated using the clipped surrogate objective of the chosen RL algorithm, with the updated policy serving as the new policy for the next iteration.
To further stabilize the training process, the authors incorporate a warm-up supervised fine-tuning (SFT) phase prior to RL training. This phase initializes the policy model with high-quality demonstrations distilled from a teacher model, enabling the model to develop fundamental capabilities in context comprehension and reasoning chain generation before engaging in the more unstable RL optimization. The SFT model serves as the initial policy for RL training, providing robust starting parameters. Additionally, a difficulty-aware retrospective sampling mechanism is employed to prioritize the exploration of challenging instances by sampling from previous phases based on difficulty scores derived from the inverse mean reward of generated outputs. This ensures that the model continues to learn from the most difficult examples throughout the training process.
Experiment
- Evaluated on seven long-context document question answering (DocQA) benchmarks, including multi-hop reasoning tasks (2WikiMultihopQA, HotpotQA, Musique, NarrativeQA, Qasper, Frames) and mathematical reasoning (DocMath), using DeepSeek-V3 as the judge model with temperature 0.0.
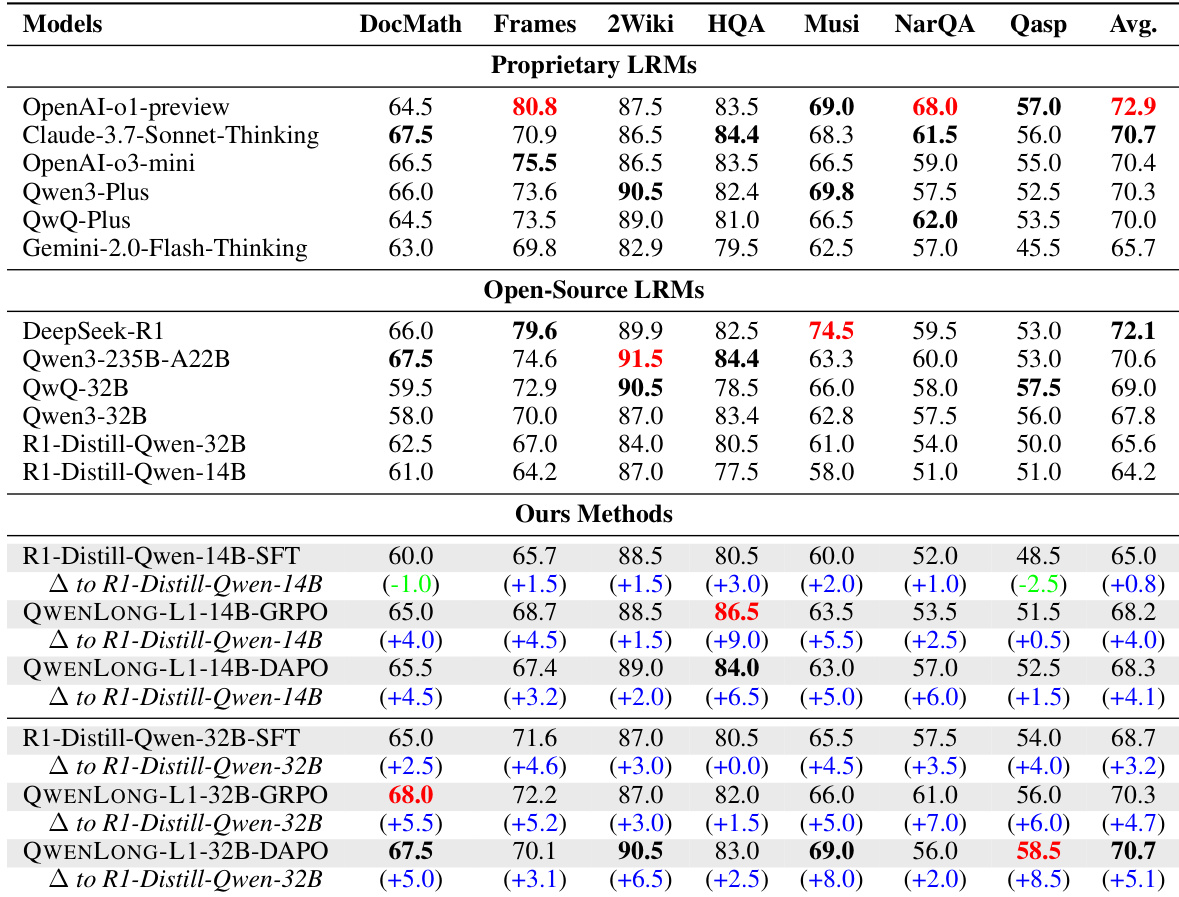
- QWENLONG-L1-14B achieved an average score of 68.3 across benchmarks, surpassing Gemini-2.0-Flash-Thinking, R1-Distill-Qwen-32B, Qwen3-32B, and matching QwQ-32B.
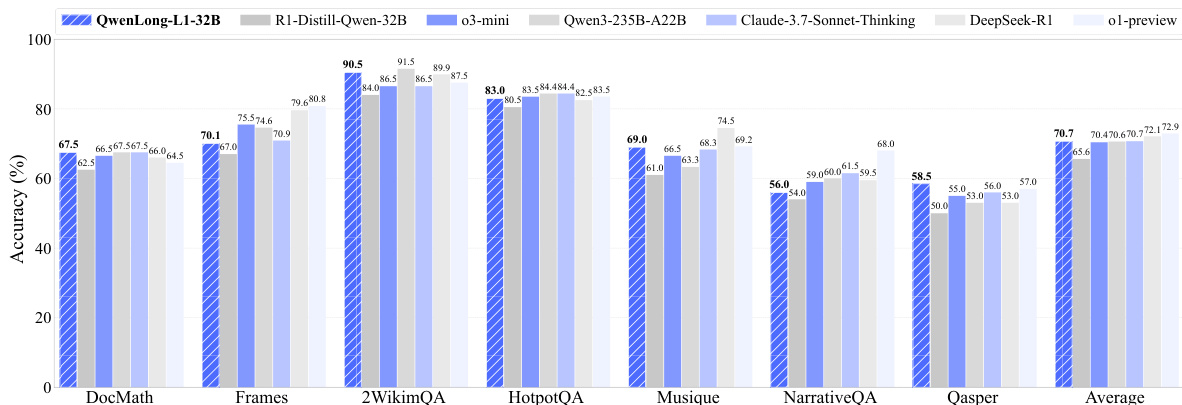
- QWENLONG-L1-32B achieved an average score of 70.7, exceeding QwQ-Plus, Qwen3-Plus, Qwen3-235B-A22B, OpenAI-o3-mini, and matching Claude-3.7-Sonnet-Thinking.
- RL integration led to significant improvements: QWENLONG-L1-14B gained 4.1 and 4.0 points over the base model with DAPO and GRPO, outperforming the 0.4-point gain from SFT.
- Test-time scaling with 16 samples improved Pass@K performance, with QWENLONG-L1-14B achieving 73.7 Pass@2, surpassing DeepSeek-R1 (72.1) and OpenAI-o1-preview (72.9).
- Ablation studies confirmed the effectiveness of warm-up SFT, curriculum-guided phased RL, and difficulty-aware retrospective sampling in enhancing stability and performance.
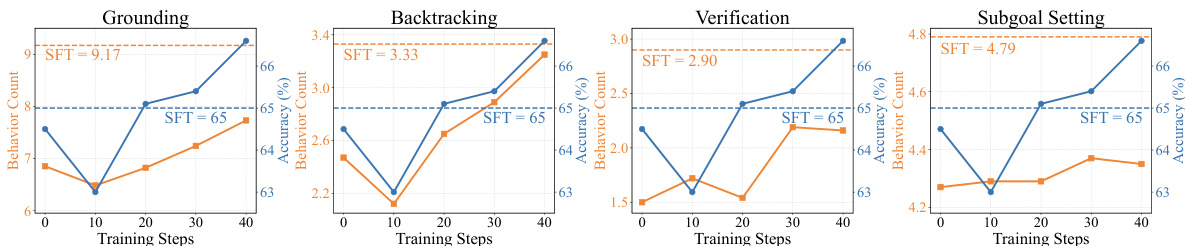
- RL training significantly amplified core reasoning behaviors (grounding, subgoal setting, backtracking, verification), while SFT alone failed to improve performance despite increasing behavior frequency.
The authors use a diverse set of seven long-context document question answering benchmarks to evaluate QWENLONG-L1, with dataset statistics showing significant variation in example count, average length, and maximum length across tasks. The test datasets include DocMath, Frames, 2Wiki, HQA, Musi, NarQA, and Qasp, each with distinct characteristics, while the training datasets for supervised fine-tuning and reinforcement learning differ substantially in size and context length.

The authors use a set of seven long-context document question answering benchmarks to evaluate QWENLONG-L1, comparing it against state-of-the-art proprietary and open-source large reasoning models. Results show that QWENLONG-L1 achieves superior performance, with QWENLONG-L1-14B averaging 68.3 and QWENLONG-L1-32B averaging 70.7, outperforming several leading models including Gemini-2.0-Flash-Thinking and Qwen3-Plus.
The authors use a set of seven long-context document question answering benchmarks to evaluate QWENLONG-L1, with results showing that QWENLONG-L1-32B achieves the highest average accuracy of 70.7%, outperforming several state-of-the-art proprietary and open-source models. The model demonstrates strong performance across individual benchmarks, particularly excelling in 2WikiMultihopQA and HotpotQA, where it achieves scores of 90.5% and 83.0% respectively.
The authors use the provided charts to analyze the evolution of four core reasoning behaviors—grounding, backtracking, verification, and subgoal setting—during training. Results show that while supervised fine-tuning (SFT) increases the frequency of these behaviors, the improvements do not translate into better performance, as the SFT model's accuracy remains low. In contrast, reinforcement learning (RL) training leads to a progressive increase in all four behaviors, which correlates with significant gains in accuracy, indicating that RL effectively refines the model's reasoning patterns.