Command Palette
Search for a command to run...
Évolution de la génération d’images et de vidéos par recherche évolutionnaire à l’époque du test
Évolution de la génération d’images et de vidéos par recherche évolutionnaire à l’époque du test
Résumé
Alors que le coût marginal de l’extension de la computation (données et paramètres) lors de l’entraînement préalable des modèles continue d’augmenter de manière significative, l’extension à l’inference (test-time scaling, TTS) s’est imposée comme une voie prometteuse pour améliorer les performances des modèles générateurs en allouant davantage de ressources computationnelles au moment de l’inférence. Bien que la TTS ait démontré un succès marqué sur plusieurs tâches linguistiques, un écart notable subsiste dans la compréhension du comportement de l’extension à l’inference des modèles générateurs d’images et de vidéos (modèles basés sur la diffusion ou sur les flux). Bien que des travaux récents aient initié l’exploration de stratégies d’inférence pour les tâches visuelles, ces approches sont confrontées à des limitations critiques : elles sont souvent cantonnées à des domaines spécifiques, présentent une mauvaise évolutivité, ou tombent dans une sur-optimisation du reward au détriment de la diversité des échantillons générés.Dans cet article, nous proposons EvoSearch, une nouvelle méthode générale et efficace de TTS, qui améliore de manière significative l’évolutivité de la génération d’images et de vidéos sur des modèles basés sur la diffusion et les flux, sans nécessiter d’entraînement supplémentaire ni d’expansion du modèle. EvoSearch reformule le problème de l’extension à l’inference pour les modèles de diffusion et de flux comme un problème de recherche évolutionnaire, en s’appuyant sur des principes d’évolution biologique pour explorer et affiner efficacement la trajectoire de débruitage. En intégrant des mécanismes de sélection et de mutation soigneusement conçus pour le processus de débruitage basé sur les équations différentielles stochastiques, EvoSearch génère itérativement des descendants de meilleure qualité tout en préservant la diversité de la population. À travers une évaluation approfondie sur diverses architectures de diffusion et de flux pour les tâches de génération d’images et de vidéos, nous démontrons que notre méthode surpasse de manière cohérente les approches existantes, atteint une diversité supérieure et présente une forte généralisation face à des métriques d’évaluation inédites. Le projet est disponible à l’adresse suivante : https://tinnerhrhe.github.io/evosearch.
One-sentence Summary
The authors from Hong Kong University of Science and Technology and Kuaishou Technology propose EvoSearch, a generalist test-time scaling framework that reformulates image and video generation as an evolutionary search problem, using selective mutation in denoising trajectories to enhance quality and diversity without retraining; it enables Stable Diffusion 2.1 to surpass GPT4o and a 1.3B model to outperform 14B and 13B counterparts with 10× fewer parameters.
Key Contributions
- Test-time scaling (TTS) for image and video generative models remains underexplored despite its success in language models, with existing methods limited by poor scalability, task-specific constraints, or reward over-optimization that reduces sample diversity.
- EvoSearch introduces a generalist TTS framework that reformulates denoising as an evolutionary search process, using denoising-aware selection and mutation mechanisms to iteratively improve sample quality while preserving diversity across diffusion and flow models.
- Extensive evaluations show EvoSearch significantly outperforms baselines, enabling Stable Diffusion 2.1 to surpass GPT4o and a 1.3B model to exceed 14B and Hunyuan 13B models with 10× fewer parameters, demonstrating strong generalization and efficiency.
Introduction
Test-time scaling (TTS) has emerged as a critical approach to enhance generative model performance without additional training, particularly as training-time scaling faces rising costs and data limitations. While TTS has shown success in language models, applying it to image and video generation—especially diffusion and flow models—remains challenging due to the high-dimensional, complex denoising trajectories these models traverse. Prior methods like best-of-N sampling and particle sampling suffer from inefficiency, limited exploration, and poor scalability, often failing to generate diverse, high-quality samples because they rely on fixed initial candidates and lack mechanisms to actively discover new, high-reward states.
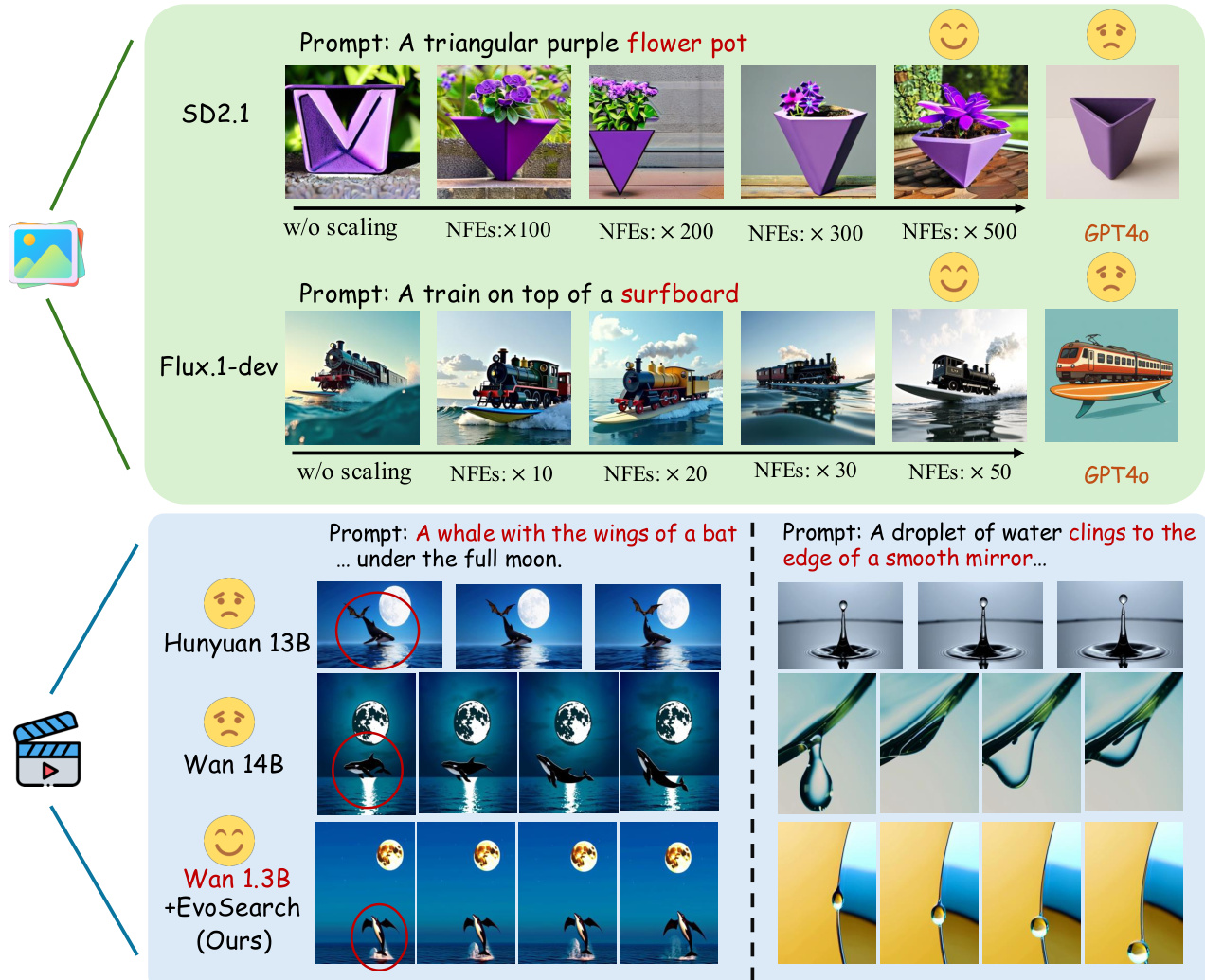
The authors propose Evolutionary Search (EvoSearch), a generalist TTS framework that reframes test-time scaling as an evolutionary search problem. By leveraging selection and mutation mechanisms tailored to the denoising process, EvoSearch iteratively evolves a population of samples, enabling active exploration of the latent space while preserving diversity. It dynamically allocates computation along the denoising trajectory, reducing cost over time, and works across both diffusion and flow models without requiring model updates or gradient access. The method achieves state-of-the-art results, enabling smaller models to outperform larger ones and allowing Stable Diffusion 2.1 to surpass GPT4o in human preference evaluations, demonstrating strong scalability, generalizability, and efficiency.
Method
The authors leverage a unified framework for test-time scaling that reformulates the sampling process from a target distribution as an active evolutionary optimization problem, applicable to both diffusion and flow models. The core of this approach, termed Evolutionary Search (EvoSearch), reinterprets the denoising trajectory as an evolutionary path, where the initial noise and intermediate states are actively evolved to discover higher-quality generations. This framework operates by progressively moving forward along the denoising trajectory, starting from the initial Gaussian noise xT, and applying evolutionary operations at specific timesteps to refine and explore new states. The overall process is guided by a reward model that evaluates the quality of generated samples, enabling a dynamic search for high-reward regions in the state space.
The framework is structured around a cascade of evolutionary generations. It begins with an initial population of kstart randomly sampled Gaussian noises at timestep T. This population is then processed through a series of evolutionary operations—selection, mutation, and fitness evaluation—according to a predefined evolution schedule T. The evolution schedule specifies the timesteps at which these operations are performed, allowing the method to focus computational resources on key points in the denoising process rather than at every step, thereby improving efficiency. The population size schedule K further adapts the number of samples at each generation, enabling a flexible trade-off between computational cost and exploration.

At each evolution timestep ti, the fitness of each parent state xti is evaluated using a reward model r, which is computed based on the fully denoised output x0. This direct evaluation on the clean output provides high-fidelity reward signals, avoiding the inaccuracies associated with prediction-based estimators. The selection process employs tournament selection to identify high-quality parents, ensuring that the best candidates are propagated to the next generation. To maintain population diversity and prevent premature convergence, a specialized mutation strategy is employed. This strategy preserves a set of elite parents with the highest fitness scores and mutates the remaining parents to explore the neighborhoods around them. The mutation operation is tailored to the nature of the state: for initial noise xT, a Gaussian-preserving mutation is used, while for intermediate denoising states xt, a mutation inspired by the reverse-time SDE is applied to preserve the intrinsic structure of the latent state.
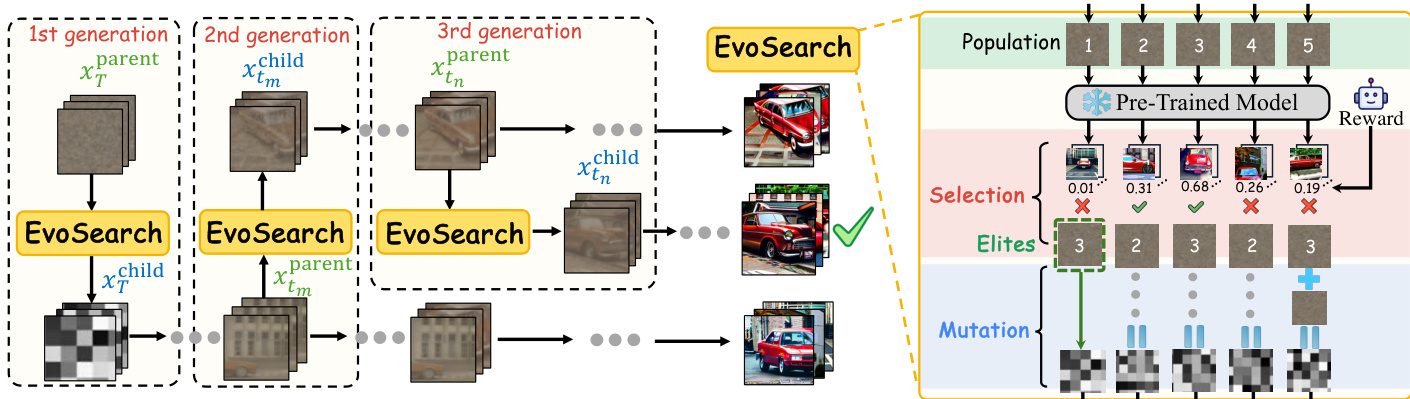
The framework is designed to be a generalist solution, encompassing existing methods like best-of-N and particle sampling as special cases. By setting the evolution schedule to only include the initial noise timestep, EvoSearch degenerates to best-of-N. Conversely, by eliminating both the initial noise search and mutation operations, it reduces to particle sampling. This unified design allows EvoSearch to achieve efficient and effective test-time scaling across a range of image and video generation tasks.
Experiment
- Evaluated EvoSearch on large-scale text-conditioned image and video generation tasks using DrawBench, VBench, and Videogen-Eval datasets, with models including Stable Diffusion 2.1 (865M) and Flux.1-dev (12B) for images, and HunyuanVideo and Wan models for videos.
- On DrawBench, EvoSearch achieved superior performance over baselines (Best-of-N and Particle Sampling) across both diffusion and flow models, with improvements of up to 32.8% and 14.1% on Wan 1.3B and 23.6% and 20.6% on HunyuanVideo 13B, respectively, using VideoReward as guidance.
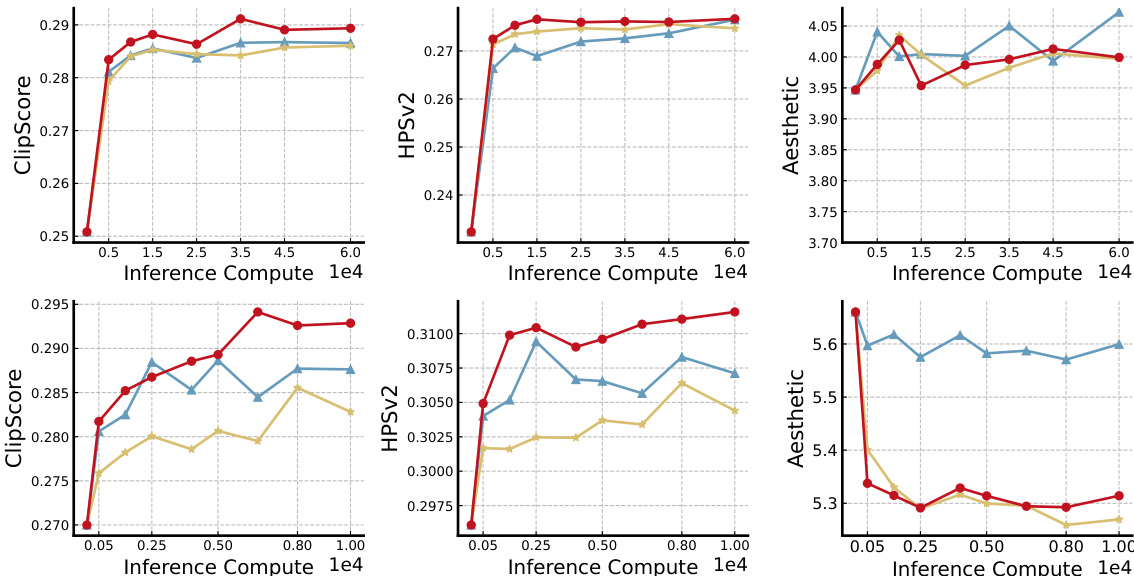
- EvoSearch demonstrated monotonic performance gains with increasing inference-time computation (NFEs), outperforming baselines that plateaued after ~1e4 NFEs, particularly on the 12B Flux.1-dev model.
- EvoSearch generalized effectively to unseen reward functions, maintaining stable performance on out-of-distribution metrics such as Aesthetic and Physics, with minimal degradation compared to baselines that suffered significant drops.
- Human evaluation showed EvoSearch achieved higher win rates than baselines across Visual Quality, Motion Quality, Text Alignment, and Overall Quality.
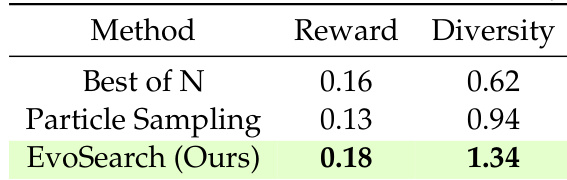
- EvoSearch achieved the highest diversity (measured by CLIP feature L2 distance) and reward simultaneously, outperforming baselines in both quality and diversity.
- EvoSearch enabled smaller models to surpass larger ones: SD2.1 with EvoSearch outperformed GPT4o under 30 seconds inference time, and Wan 1.3B with 5× scaled computation matched or exceeded Wan 14B’s performance on equivalent hardware.
The authors use EvoSearch to evaluate image generation performance on Stable Diffusion 2.1 and Flux.1-dev models, comparing it against baselines Best of N and Particle Sampling. Results show that EvoSearch consistently outperforms both baselines across increasing inference-time computation, achieving higher ImageReward and ClipScore values, and surpassing GPT4o in quality even with significantly lower computational cost.
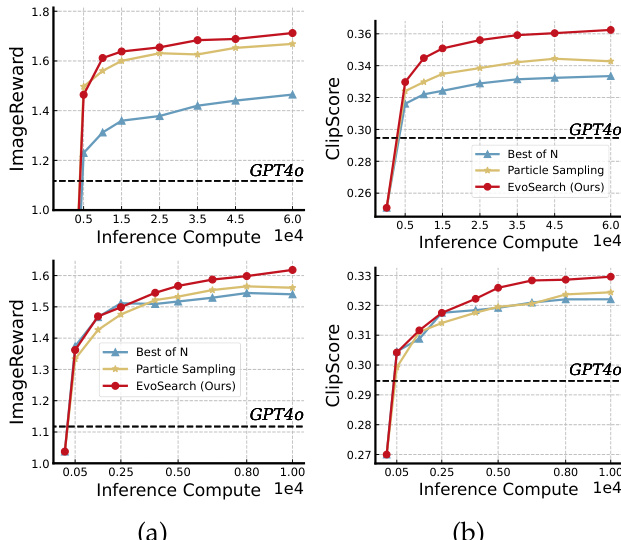
The authors use EvoSearch to evaluate image generation on Stable Diffusion 2.1 and Flux.1-dev, measuring performance across multiple metrics including ClipScore, HPSv2, and Aesthetic as inference-time computation increases. Results show that EvoSearch consistently improves generation quality with higher inference compute, outperforming baseline methods which plateau, and achieves superior performance across all metrics while maintaining higher diversity.
The authors use EvoSearch to evaluate video generation performance on HunyuanVideo 13B and Wan2.1 1.3B models, comparing it against Best of N and Particle Sampling. Results show EvoSearch achieves higher normalized VideoReward scores than both baselines across both models, with improvements of 1.54 and 1.35 for HunyuanVideo 13B and Wan2.1 1.3B respectively, while the baselines show lower or comparable performance.
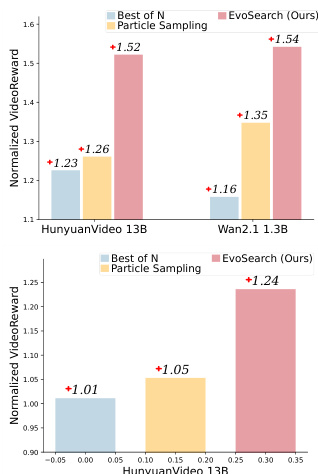
The authors evaluate EvoSearch on video generation tasks using the Wan 1.3B and Wan 14B models, with VideoReward as the guidance metric. Results show that Wan 1.3B enhanced with EvoSearch achieves a significantly higher VideoReward score compared to the larger Wan 14B model, demonstrating that EvoSearch enables smaller models to outperform larger ones under equivalent inference time.

The authors use EvoSearch to evaluate its performance against baseline methods in terms of reward and diversity. Results show that EvoSearch achieves the highest reward and diversity scores, outperforming Best of N and Particle Sampling.