Command Palette
Search for a command to run...
Direct3D-S2 : La génération 3D gigascale simplifiée grâce à l'attention spatialement creuse
Direct3D-S2 : La génération 3D gigascale simplifiée grâce à l'attention spatialement creuse
Résumé
La génération de formes 3D à haute résolution à l’aide de représentations volumiques telles que les fonctions de distance signée (SDF) soulève des défis computationnels et mémoire importants. Nous introduisons Direct3D-S2, un cadre de génération 3D évolutif basé sur des volumes creux, qui atteint une qualité de sortie supérieure tout en réduisant de façon drastique les coûts d’entraînement. Notre innovation principale est le mécanisme d’attention creuse spatiale (SSA, Spatial Sparse Attention), qui améliore considérablement l’efficacité des calculs du Diffusion Transformer (DiT) sur des données volumiques creuses. Le SSA permet au modèle de traiter efficacement de grands ensembles de tokens au sein de volumes creux, réduisant fortement la charge computationnelle et offrant un accélération de 3,9× dans le passage avant et de 9,6× dans le passage arrière. Notre cadre inclut également un auto-encodeur variationnel (VAE) qui maintient un format volumique creux cohérent à travers les étapes d’entrée, latente et sortie. Contrairement aux méthodes précédentes utilisant des représentations hétérogènes dans les VAE 3D, cette architecture unifiée améliore significativement l’efficacité et la stabilité de l’entraînement. Notre modèle est entraîné sur des jeux de données publics, et les expériences montrent que Direct3D-S2 dépasse non seulement les méthodes de pointe en qualité et efficacité de génération, mais permet également l’entraînement à une résolution de 1024 avec seulement 8 GPU — une tâche habituellement requérant au moins 32 GPU pour des représentations volumiques à 256 de résolution — rendant ainsi la génération 3D de l’ordre du gigascale à la fois pratique et accessible. Page du projet : https://www.neural4d.com/research/direct3d-s2.
One-sentence Summary
The authors from Nanjing University, DreamTech, Fudan University, and the University of Oxford propose Direct3D-S2, a scalable 3D generation framework using sparse volumes and Spatial Sparse Attention (SSA) to enable efficient Diffusion Transformer computation, achieving up to 9.6× speedup in backpropagation and supporting 1024³ resolution generation on just 8 GPUs—making gigascale 3D generation practical and accessible.
Key Contributions
- Generating high-resolution 3D shapes from sparse volumetric representations has been hindered by the prohibitive computational cost of full attention in diffusion transformers, especially at resolutions like 10243, which typically require dozens of GPUs due to quadratic memory growth.
- The paper introduces Spatial Sparse Attention (SSA), a novel mechanism that redefines block partitioning and integrates learnable compression and selection modules to efficiently process unstructured sparse 3D tokens, achieving a 3.9× speedup in forward pass and 9.6× in backward pass via a custom Triton kernel.
- By maintaining a consistent sparse volumetric format across input, latent, and output stages through a unified VAE design, Direct3D-S2 enables training at 10243 resolution using only 8 GPUs—demonstrating state-of-the-art quality and efficiency while making gigascale 3D generation practical and accessible.
Introduction
The authors leverage sparse volumetric representations and a novel Spatial Sparse Attention (SSA) mechanism to enable efficient, high-resolution 3D shape generation at gigascale, addressing the critical bottleneck of computational cost in existing diffusion-based 3D generative models. Prior work in 3D latent diffusion faces two main challenges: implicit methods suffer from inefficient training due to asymmetric, non-scalable architectures, while explicit voxel-based methods are limited by cubic memory growth and the prohibitive cost of full attention in diffusion transformers, restricting them to low resolutions or requiring hundreds of GPUs. The key contribution is Direct3D-S2, a unified framework that uses a symmetric sparse SDF VAE to maintain consistent sparse volumetric representation across input, latent, and output stages, eliminating cross-modality translation overhead. By introducing SSA—a redesigned, learnable compression and selection module adapted for irregular 3D sparse data—the method achieves up to 9.6× speedup in backward pass over FlashAttention-2 at 1024³ resolution, enabling training on 1024³ outputs with just 8 GPUs, a major leap in scalability and efficiency for explicit 3D diffusion models.
Dataset
- The dataset comprises approximately 452k 3D assets curated from publicly available sources, primarily Objaverse [9], Objaverse-XL [8], and ShapeNet [5], with a focus on high-quality, non-redundant models.
- To ensure geometric consistency, all original non-watertight meshes are converted into watertight representations using standard preprocessing pipelines.
- Ground-truth Signed Distance Function (SDF) volumes are computed for each mesh, serving as both input and supervision signal for the SS-VAE component of the model.
- For training the image-conditioned DiT, 45 high-resolution (1024 × 1024) RGB renderings are generated per mesh using randomized camera parameters: elevation angles between 10° and 40°, azimuth angles spanning 0° to 180°, and focal lengths ranging from 30mm to 100mm.
- A challenging evaluation benchmark is constructed using highly detailed images from professional 3D communities such as Neural4D [3], Meshy [2], and CivitAI [1], designed to test geometric fidelity under realistic conditions.
- Quantitative evaluation leverages multiple state-of-the-art metrics—ULIP-2 [44], Uni3D [52], and OpenShape [20]—to measure shape-image alignment between generated meshes and input images, enabling rigorous comparison with existing 3D generation methods.
- The training data is used in a mixture of ratios across the different sources, with filtering applied to exclude low-quality or corrupted meshes, ensuring robustness and generalization.
Method
The Direct3D-S2 framework employs a two-stage architecture for high-resolution 3D shape generation, comprising a symmetric Sparse SDF Variational Autoencoder (SS-VAE) and a diffusion transformer (DiT) conditioned on image inputs. The overall system processes 3D shapes as sparse Signed Distance Function (SDF) volumes, enabling efficient representation and generation. The SS-VAE operates as a fully end-to-end encoder-decoder network, designed to encode high-resolution sparse SDF volumes into compact latent representations and subsequently reconstruct them. The encoder utilizes a hybrid architecture combining residual sparse 3D convolutional neural networks (CNNs) with transformer layers. It processes the input sparse voxels through a series of sparse 3D CNN blocks and 3D mean pooling operations to progressively downsample the spatial resolution. The resulting sparse voxels are treated as variable-length tokens, which are then processed by shifted window attention layers to capture local contextual information. To preserve spatial information, the feature of each valid voxel is augmented with positional encoding based on its 3D coordinates before being fed into the attention layers. This hybrid design outputs sparse latent representations at a reduced resolution. The decoder mirrors the encoder's structure, employing attention layers and sparse 3D CNN blocks to upsample the latent representation and reconstruct the original SDF volume. The framework incorporates multi-resolution training, where the input SDF volume is randomly interpolated to one of several target resolutions (2563, 3843, 5123, 10243) during each training iteration, enhancing the model's ability to handle diverse scales. The training objective for the SS-VAE includes a reconstruction loss that supervises the SDF values across all decoded voxels, including both the original input and any additional valid voxels generated during decoding. To improve geometric fidelity, an additional loss is applied to voxels near sharp edges, and a KL-divergence regularization term is used to constrain the latent space.
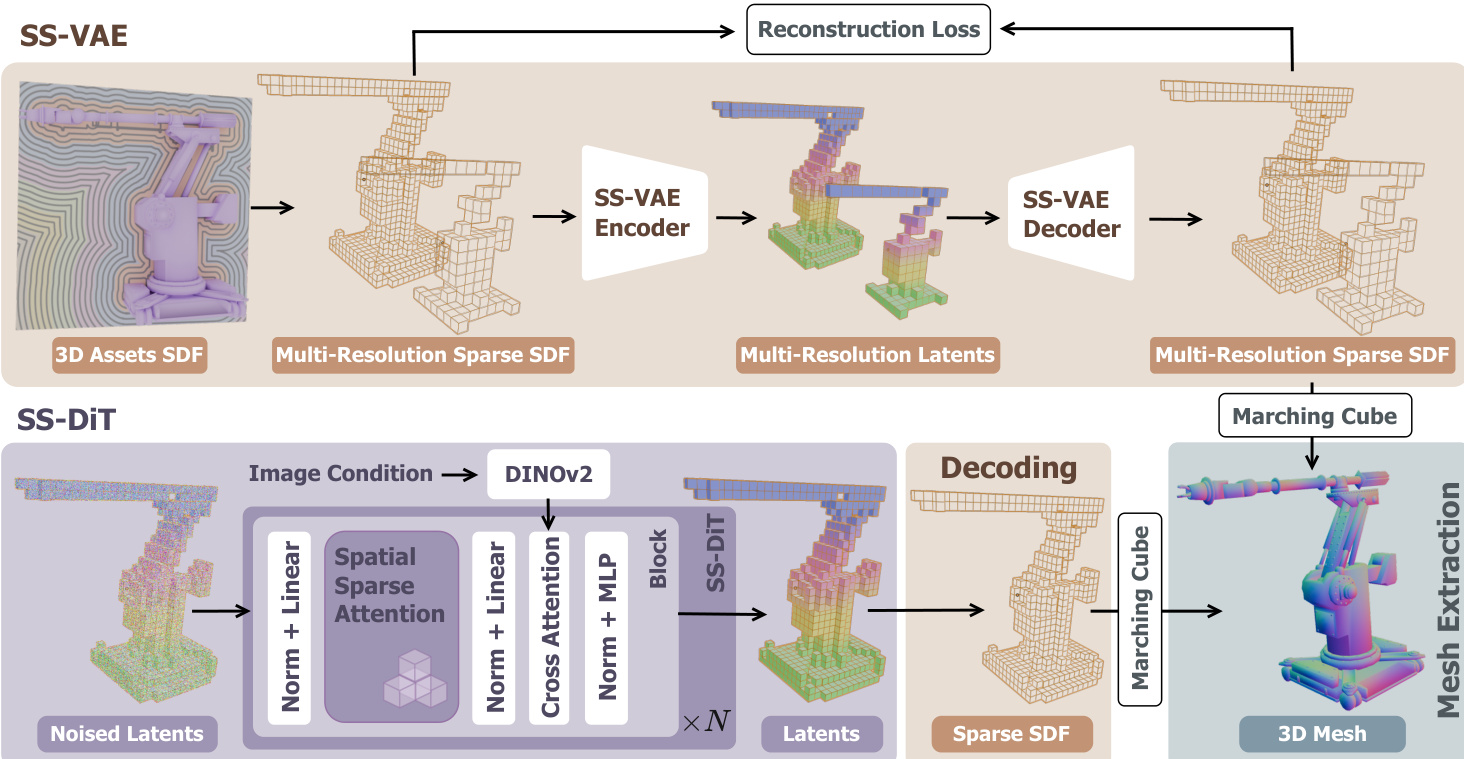
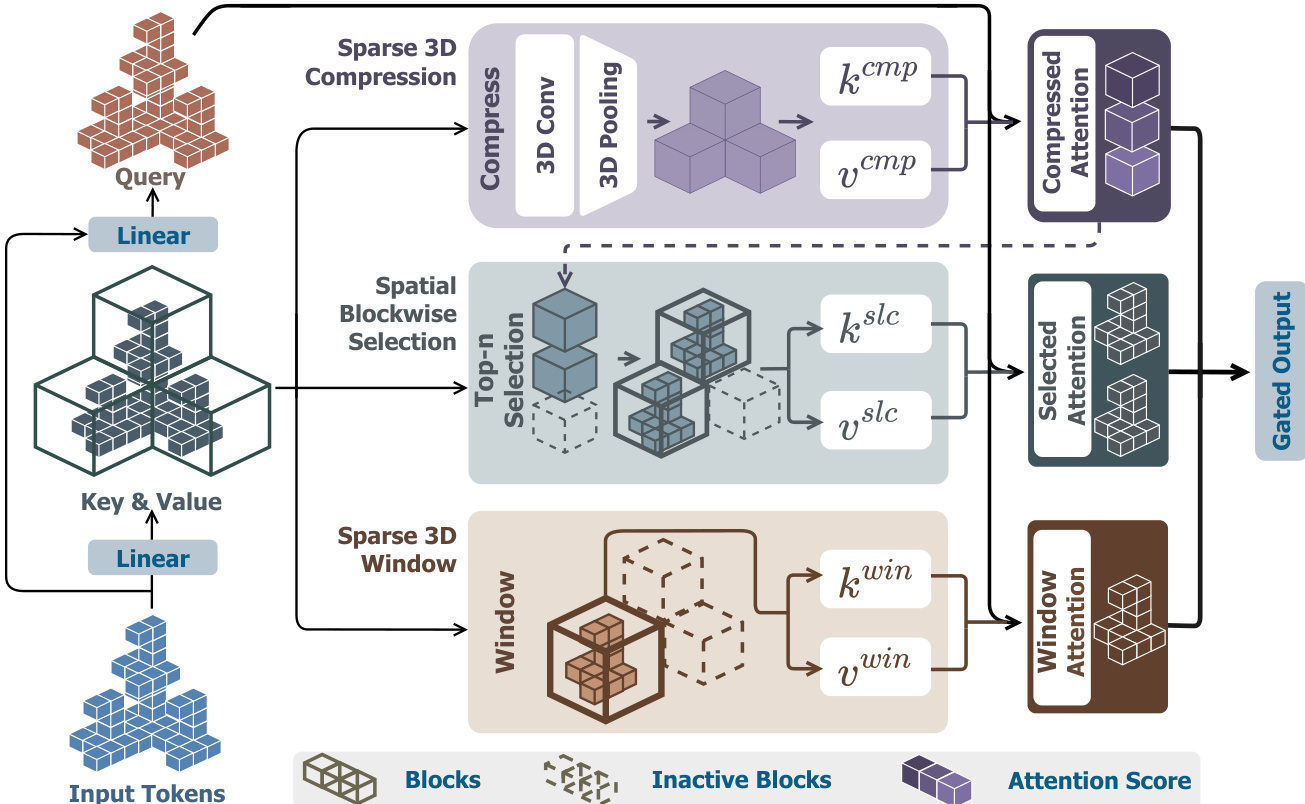
Following the SS-VAE, the latent representations are processed by a diffusion transformer (SS-DiT) to generate 3D shapes conditioned on input images. The SS-DiT is trained using a rectified flow objective, where the model learns to predict the velocity field from noisy latent representations to the data distribution. The training process involves a progressive strategy, gradually increasing the resolution from 2563 to 10243 to accelerate convergence. To efficiently handle the large number of tokens in high-resolution sparse volumes, the authors introduce a novel Spatial Sparse Attention (SSA) mechanism. This mechanism is designed to substantially accelerate both training and inference by reducing the computational cost of attention operations. The standard full attention mechanism, which computes pairwise interactions between all tokens, becomes prohibitively expensive as the number of tokens grows, reaching over 100k at a 10243 resolution. The SSA mechanism addresses this by partitioning the input tokens into spatially coherent blocks based on their 3D coordinates, rather than using a naive 1D index-based partitioning that can lead to unstable training. The attention computation proceeds through three core modules: sparse 3D compression, spatial blockwise selection, and sparse 3D window. The sparse 3D compression module first groups tokens into blocks of size mcmp3 and uses sparse 3D convolution and mean pooling to generate a compressed, block-level representation of the key and value tokens. This captures global information while reducing the token count. The spatial blockwise selection module then uses the attention scores between the query and the compressed blocks to select the top-k blocks with the highest relevance. All tokens within these selected blocks are then used to compute a second attention, capturing fine-grained features. The sparse 3D window module further enhances the model by explicitly incorporating localized feature interactions. It partitions the input tokens into non-overlapping windows of size mwin3 and performs self-attention only within each window, ensuring that local context is preserved. The outputs from these three modules are aggregated and weighted by predicted gate scores to produce the final output of the SSA mechanism. This design allows the model to effectively process large token sets within sparse volumes, achieving significant speedups.
To further improve efficiency, a sparse conditioning mechanism is employed to process the input image. Instead of using all pixel-level features from the image, which can be dominated by background regions, the model selectively extracts sparse foreground tokens. This is achieved by using a DINO-v2 encoder to extract features and then applying a mask to retain only the foreground tokens. These sparse conditioning tokens are then used in the cross-attention operation with the noisy latent tokens, reducing computational overhead and improving the alignment between the generated mesh and the input image. The final 3D mesh is extracted from the generated sparse SDF volume using the Marching Cubes algorithm.
Experiment
- Direct3D-S2 outperforms state-of-the-art methods on image-to-3D generation, achieving superior alignment with input images across three metrics and demonstrating statistically significant advantages in user studies (40 participants, 75 meshes) for both image consistency and geometric quality.
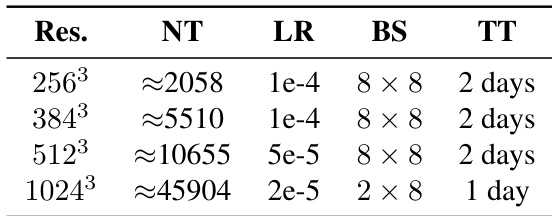
- SS-VAE achieves high-fidelity reconstruction at 5123 and 10243 resolutions, with notable improvements on complex geometries, and requires only 2 days of training on 8 A100 GPUs, significantly less than competing methods.
- Ablation studies show that increasing resolution from 2563 to 10243 progressively improves mesh quality, with 10243 yielding sharper edges and better detail alignment.
- The SSA mechanism enhances mesh quality and smoothness: the spatial blockwise selection module is critical for global focus, while sparse 3D windowing enables efficient local interaction, and the full SSA design outperforms full attention and NSA variants in both stability and detail preservation.
- SSA achieves up to 3.9× faster forward and 9.6× faster backward computation than FlashAttention-2 at 128k tokens, demonstrating strong scalability and efficiency.
- The sparse conditioning mechanism improves image-to-mesh alignment by filtering out non-foreground tokens, leading to more accurate geometric outputs.
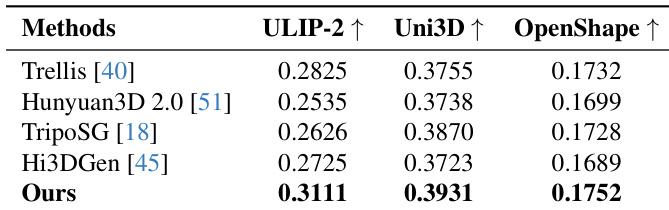
Results show that the proposed method outperforms all compared approaches across the three metrics—ULIP-2, Uni3D, and OpenShape—achieving the highest scores in each case, indicating superior alignment between generated meshes and input images. The authors use these quantitative results to demonstrate that their Direct3D-S2 framework produces more accurate and consistent 3D reconstructions compared to state-of-the-art methods.
The authors use the table to show that training time decreases significantly as resolution increases, with the 1024³ resolution requiring only one day compared to two days for lower resolutions. This reduction is achieved despite a substantial increase in the number of tokens and a lower learning rate, indicating improved training efficiency at higher resolutions.
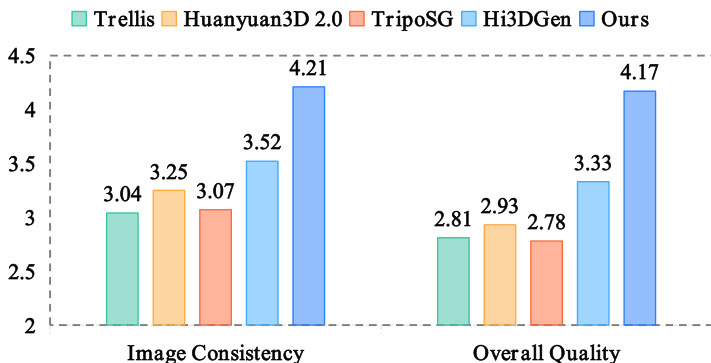
Results show that the proposed Direct3D-S2 framework achieves the highest scores in both image consistency and overall geometric quality compared to competing methods in the user study. The authors use a user study with 40 participants to evaluate 75 unfiltered meshes, and the bar chart indicates that Direct3D-S2 outperforms all other approaches, scoring 4.21 for image consistency and 4.17 for overall quality.