Command Palette
Search for a command to run...
UniversalRAG : Génération augmentée par récupération sur des corpus de modalités et de granularités diverses
UniversalRAG : Génération augmentée par récupération sur des corpus de modalités et de granularités diverses
Woongyeong Yeo Kangsan Kim Soyeong Jeong Jinheon Baek Sung Ju Hwang
Résumé
Le modèle Retrieval-Augmented Generation (RAG) a démontré un potentiel considérable pour améliorer la précision factuelle en ancrant les réponses des modèles dans des connaissances externes pertinentes par rapport aux requêtes. Toutefois, la plupart des approches existantes se limitent à des corpus exclusivement textuels. Bien que des travaux récents aient étendu le cadre du RAG à d'autres modalités telles que les images et les vidéos, ces méthodes opèrent généralement sur un seul corpus spécifique à une modalité. En revanche, les requêtes du monde réel exigent souvent des types de connaissances très variés, ce que ne peut pas couvrir une seule source de connaissance. Pour répondre à ce défi, nous proposons UniversalRAG, conçu pour récupérer et intégrer des connaissances provenant de sources hétérogènes, aux modalités et granularités diverses. Plus précisément, motivés par l’observation selon laquelle forcer toutes les modalités à coexister dans un espace de représentation unifié dérivé d’un corpus agrégé unique entraîne un « écart modal », où la récupération tend à privilégier les éléments de la même modalité que la requête, nous introduisons une stratégie de routage consciente de la modalité. Cette approche identifie dynamiquement le corpus spécifique à la modalité le plus adapté, puis effectue une récupération ciblée au sein de ce dernier. Nous justifions également son efficacité par une analyse théorique. En outre, au-delà de la modalité, nous organisons chaque modalité en plusieurs niveaux de granularité, permettant ainsi une récupération affinée, adaptée à la complexité et à l’étendue de la requête. Nous validons UniversalRAG sur 10 benchmarks couvrant plusieurs modalités, démontrant ainsi son avantage par rapport à diverses méthodes de référence spécifiques à une modalité ou unifiées.
One-sentence Summary
The authors from KAIST and DeepAuto.ai propose UniversalRAG, a modality-aware retrieval framework that dynamically routes queries to relevant modality-specific corpora and leverages multi-granularity indexing to improve cross-modal retrieval accuracy, outperforming unified and modality-specific baselines across 10 multimodal benchmarks.
Key Contributions
- Existing Retrieval-Augmented Generation (RAG) systems are typically limited to single-modality corpora, leading to poor performance on queries requiring knowledge from diverse sources like text, images, or videos, due to inherent modality gaps in unified embedding spaces.
- UniversalRAG introduces modality-aware routing to dynamically direct queries to the most relevant modality-specific corpora, avoiding cross-modal embedding biases and enabling targeted retrieval without requiring a unified representation space, supported by theoretical analysis.
- The framework further incorporates multiple granularity levels within each modality—such as paragraphs, clips, and images—allowing fine-grained retrieval tailored to query complexity, and achieves state-of-the-art results across 10 multimodal benchmarks while improving efficiency and robustness.
Introduction
Retrieval-Augmented Generation (RAG) enhances factual accuracy by grounding LLM responses in external knowledge, but prior approaches are largely limited to text-only corpora or single-modality retrieval, failing to handle real-world queries that require diverse knowledge types—such as text, images, videos, or combinations thereof. A key challenge is the modality gap, where unified embedding spaces bias retrieval toward the query’s modality, causing relevant cross-modal content to be overlooked. Additionally, fixed granularity in retrieval—whether full documents or short passages—limits precision for queries with varying complexity. The authors introduce UniversalRAG, a framework that overcomes these limitations through modality-aware routing, dynamically directing queries to the most appropriate modality-specific corpus without relying on a unified embedding space. This approach avoids modality bias and enables seamless integration of new modalities. Furthermore, each modality is organized into multiple granularity levels—paragraphs, clips, sections, etc.—allowing fine-grained retrieval tailored to query complexity. The system is validated across 10 diverse benchmarks, demonstrating superior performance over both modality-specific and unified baselines, while also improving efficiency and robustness.
Dataset

- The dataset comprises in-domain and out-of-domain benchmarks, with each split into 3:7 training-to-testing ratios.
- In-domain datasets include:
- MMLU: Uses all development split questions (no retrieval needed), covering diverse tasks like math, law, and world knowledge.
- Natural Questions: 2,000 randomly sampled QA pairs from dev split; Wikipedia corpus segmented into 100-word paragraphs.
- HotpotQA: 2,000 QA pairs from test split; multi-hop reasoning queries with corpora formed by grouping related documents (up to 4K+ tokens).
- HybridQA: 2,000 dev split QA pairs; separated into distinct table and text corpora to support modality-specific retrieval.
- MRAG-Bench: 1,353 multi-modal questions (text + image); single image corpus built from all images across questions.
- WebQA: 2,000 filtered QA pairs requiring image retrieval; GPT-4o used to ensure questions aren’t image-grounded; separate text and image corpora constructed.
- InfoSeek: 2,000 dev split QA pairs; text and image evidence collected per question for separate corpora.
- LVBench: Short-timestamp queries rephrased into text-only format using GPT-4o; used as clip-level training data; evaluation on available videos.
- VideoRAG-Wiki and VideoRAG-Synth: Full-video retrieval queries identified via GPT-4o; used as video-level training data.
- Out-of-domain datasets are used only for evaluation:
- TruthfulQA: Multiple-choice questions testing avoidance of false beliefs; single correct answer per question.
- TriviaQA: 2,000 dev split QA pairs; categorized by GPT-4o whether retrieval is needed; evidence segmented into 100-word paragraphs.
- SQuAD: 2,000 dev split QA pairs; full Wikipedia corpus used, segmented into 100-word paragraphs.
- 2WikiMultiHopQA: 2,000 dev split QA pairs; document-level corpus built from aggregated paragraph-level contexts.
- Visual-RAG: Full query set used; five images per category sampled for image retrieval pool.
- CinePile: 144 videos, 10 randomly selected test questions per video; GPT-4o used to classify granularity (clip-level vs. full-video).
- The authors use the training split for model training with a mixture of in-domain datasets, applying modality-specific routing and processing.
- Processing includes:
- Text corpora segmented into 100-word paragraphs.
- Multi-hop and multi-modal queries processed with document grouping or modality separation.
- Video queries rephrased into text-only format and classified by granularity using GPT-4o.
- Image corpora constructed by aggregating evidence across questions.
- GPT-4o used for filtering, rephrasing, and granularity classification to ensure alignment with the experimental setup.
Method
The authors introduce UniversalRAG, a framework designed to dynamically route queries to the most appropriate modality and granularity for targeted retrieval, addressing the limitations of existing retrieval systems that either operate over a single modality or a fixed granularity. The core challenge addressed is the modality gap, which arises when heterogeneous corpora—spanning different modalities such as text, images, and videos—are aggregated into a unified corpus and embedded into a shared space. In such a setup, textual queries tend to align more closely with text-based items, regardless of the modality required by the query, leading to suboptimal retrieval performance. To circumvent this, UniversalRAG decomposes the retrieval process into two stages: modality-aware routing followed by granularity-aware retrieval.
Refer to the framework diagram, which illustrates the limitations of prior approaches and the proposed solution. In the first stage, a routing module is employed to predict the most relevant modality or modality-granularity pair for a given query. This module operates by analyzing the query and determining the optimal set of modalities and granularities from which to retrieve information. The routing decision is made without forcing all data into a unified embedding space, thereby preserving the distinct characteristics of each modality-specific corpus. Instead, retrieval is restricted to the selected corpora, using modality-specific retrievers that are tailored to the respective data types. This approach avoids the modality gap issue inherent in unified embedding schemes.
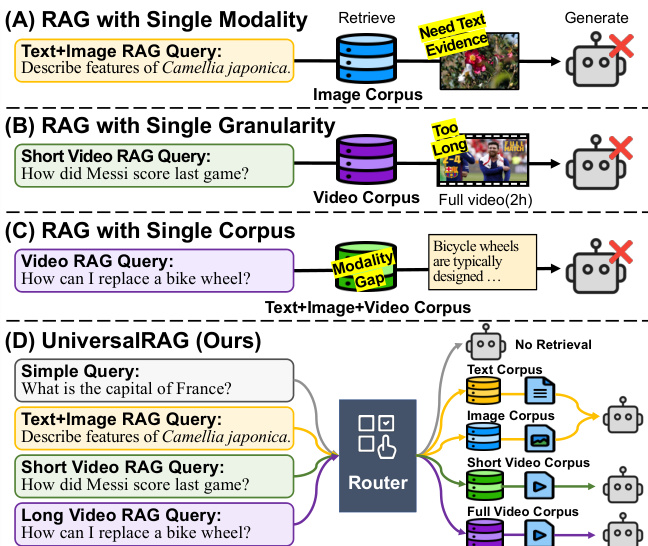
To further enhance flexibility, UniversalRAG extends the routing mechanism to account for varying levels of granularity within each modality. This enables the system to retrieve either fine-grained details or broader context, depending on the query's requirements. The routing module is thus expanded to predict not only the modality but also the granularity level, including a no-retrieval option for queries that do not require external knowledge. This allows the framework to adapt to the diverse complexity and information scope of different queries, providing a more nuanced and effective retrieval strategy.
The routing module is implemented in two ways: a training-based approach and a training-free approach. In the training-based variant, the router is trained using a multi-hot label representation and cross-entropy loss, leveraging inductive biases from existing benchmarks to automatically generate labeled data. The model is trained to predict the appropriate modality-granularity pair for each query, with inference decisions made based on a predefined threshold. In contrast, the training-free approach leverages the reasoning capabilities of large language models, such as Gemini, to act as a router by prompting the model with a carefully designed template that includes task objectives and few-shot examples. This eliminates the need for supervised training and allows the system to adapt to new domains without additional data.
Experiment
- Evaluated UniversalRAG across seven modalities and granularities using diverse datasets: MMLU (no-retrieval), Natural Questions (text, paragraph-level), HotpotQA (text, document-level), HybridQA (text + tables), MRAG-Bench (image), WebQA and InfoSeek (cross-modal text-image), and LVBench, VideoRAG-Wiki, VideoRAG-Synth (video).
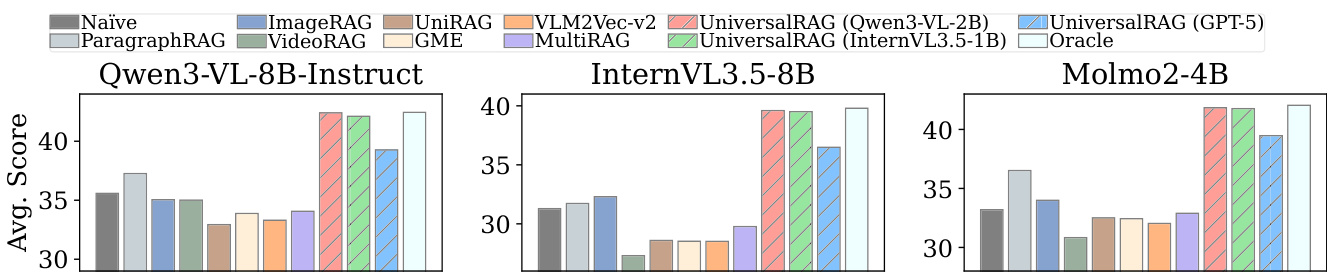
- Demonstrated that UniversalRAG consistently outperforms unimodal RAGs, unified embedding multimodal RAGs (e.g., VLM2Vec-V2, GME), and MultiRAG across all benchmarks, achieving the highest average performance on Qwen3-VL-8B-Instruct, with ROUGE-L and BERTScore metrics surpassing all baselines.
- Showed that cross-modal retrieval significantly improves performance over uni-modal approaches, especially on HybridQA and WebQA, where complementary evidence from multiple modalities is essential.
- Validated the effectiveness of multigranularity routing: UniversalRAG with granularity-aware selection achieves higher accuracy than fixed-granularity baselines, with gains observed in both training-free and training-based variants.
- Proved that modality-aware routing reduces retrieval latency sub-linearly with corpus size, outperforming unified embedding methods at large scales (beyond 10M entries), due to reduced search space and efficient routing.
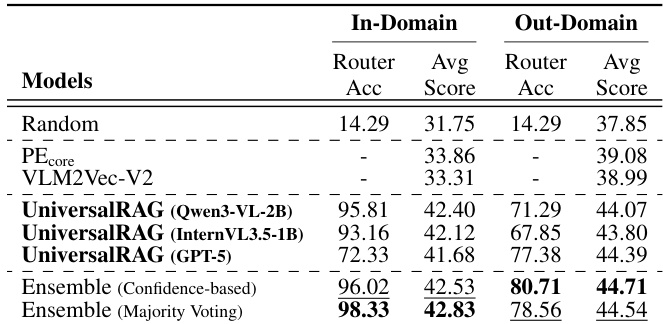
- Confirmed that smaller router models (e.g., 1B parameters) achieve ~90% routing accuracy, enabling efficient deployment without sacrificing performance.
- Demonstrated strong generalization to out-of-domain datasets: training-free routers (e.g., GPT-5) outperform trained routers in OOD settings, while ensemble strategies combining both achieve robust performance across domains.
- Case studies confirmed UniversalRAG’s ability to correctly route queries to appropriate modalities and granularities, enabling accurate cross-modal and fine-grained reasoning, even when unimodal methods fail.
The authors use UniversalRAG to evaluate its performance across diverse RAG tasks involving multiple modalities and granularities, comparing it against a range of baselines including unimodal, unified embedding, and multi-corpus multimodal methods. Results show that UniversalRAG consistently achieves the best average performance across all benchmarks, with its training-free router variants often matching or approaching the oracle performance, demonstrating the effectiveness of modality-aware and granularity-aware routing.
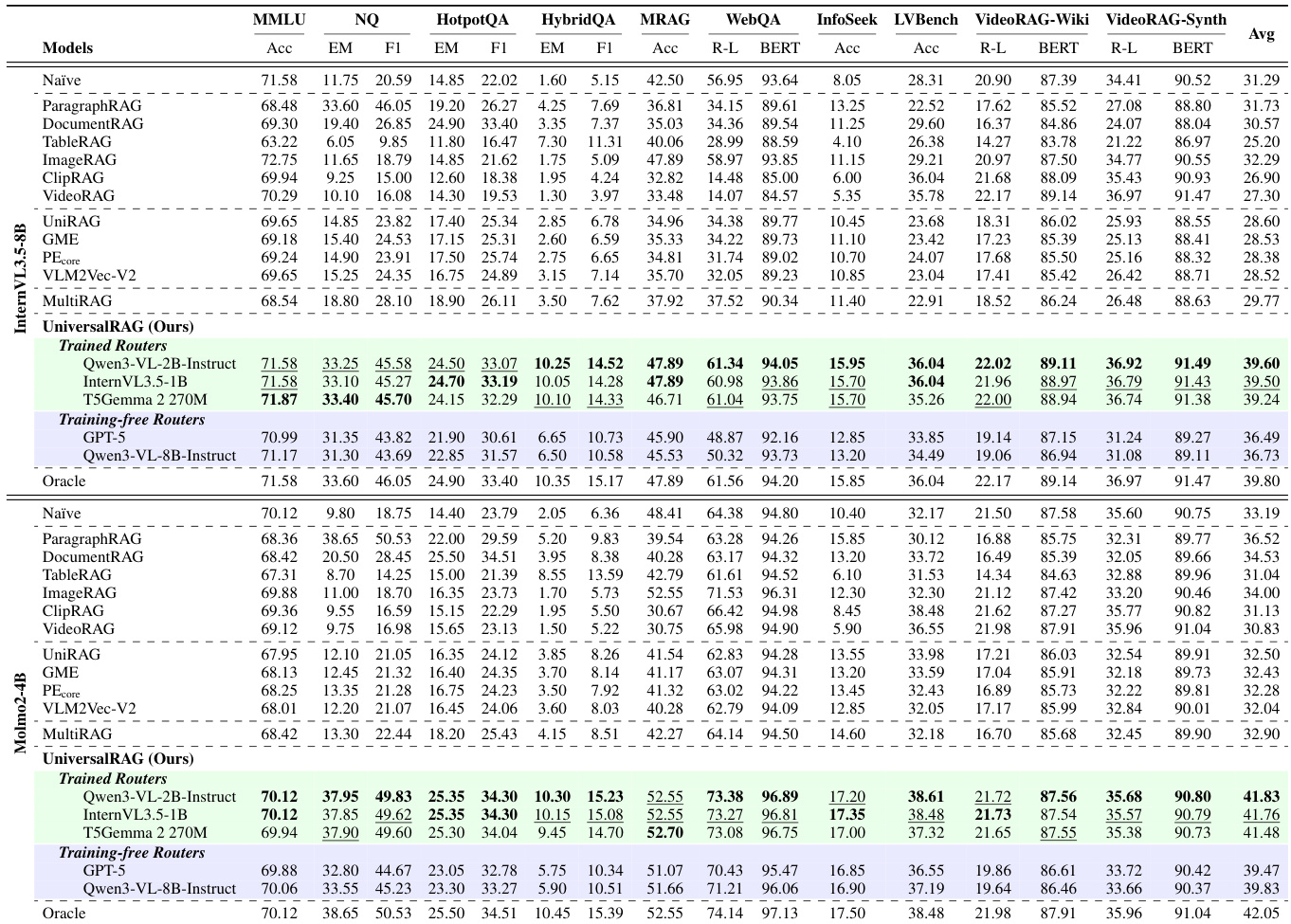
The authors use UniversalRAG to evaluate its performance across diverse RAG tasks involving multiple modalities and granularities, comparing it against a range of baselines including unimodal, unified embedding, and multi-corpus multimodal methods. Results show that UniversalRAG consistently achieves the best average performance, with its trained router variants outperforming all baselines and approaching oracle-level accuracy, while the training-free router also demonstrates strong generalization and robustness across different scenarios.
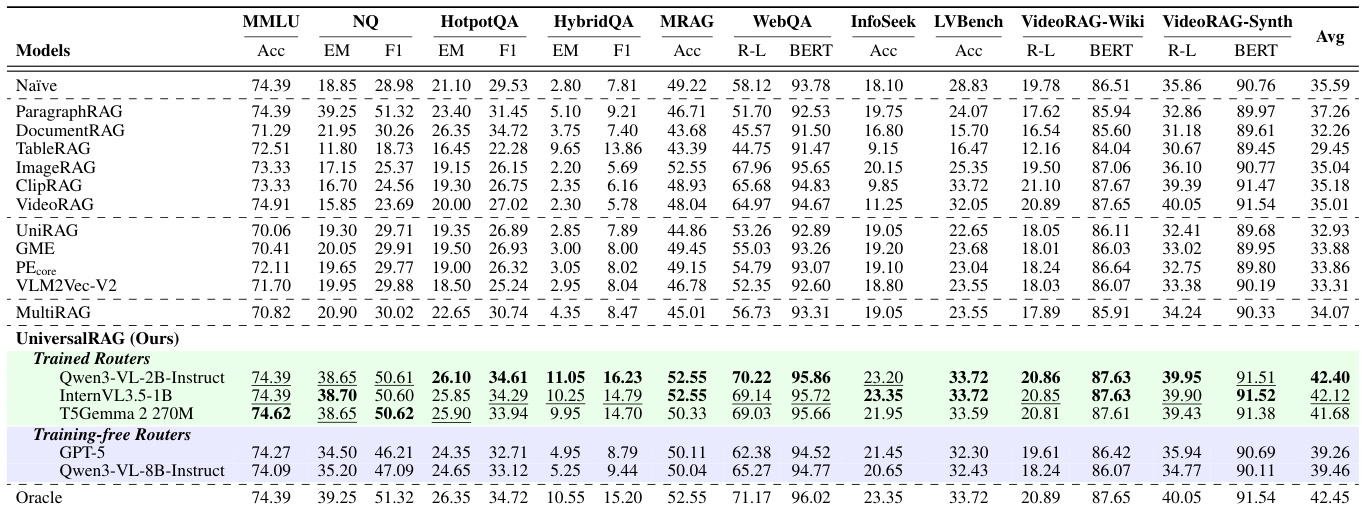
Results show that UniversalRAG consistently achieves the highest average scores across all three large vision-language models (Qwen3-VL-8B-Instruct, InternVL3.5-8B, and Molmo2-4B), outperforming all baseline methods including unimodal RAGs, unified embedding models, and MultiRAG. The performance gains are particularly pronounced compared to models like GME and VLM2Vec-v2, which exhibit strong modality bias and lower retrieval accuracy, while UniversalRAG's adaptive routing enables effective cross-modal and multi-granularity retrieval.
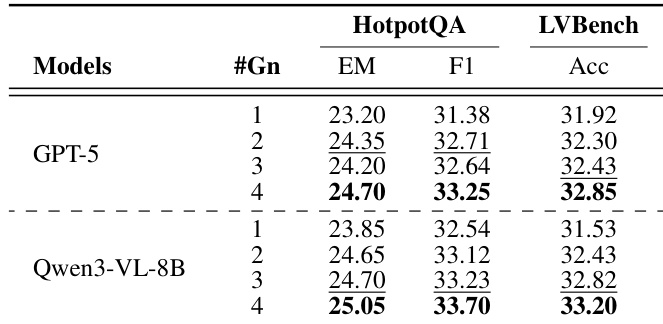
Results show that UniversalRAG with a training-free router (GPT-5) achieves the best performance across different granularity levels on HotpotQA and LVBench, with the highest EM and F1 scores on HotpotQA and the highest accuracy on LVBench. The model with Qwen3-VL-8B performs competitively, but GPT-5 consistently outperforms it across all granularity settings, indicating the effectiveness of the training-free routing approach.
The authors use UniversalRAG with training-free routers to evaluate its performance on out-of-domain datasets, comparing it against trained router variants and baseline methods. Results show that the training-free router achieves the highest average score in the out-domain setting, while the ensemble strategies combining trained and training-free routers achieve the best overall performance, demonstrating robustness and generalization across unseen data.