Command Palette
Search for a command to run...
YOLOE : Vision en temps réel de tout ce qui est visible
YOLOE : Vision en temps réel de tout ce qui est visible
Ao Wang Lihao Liu Hui Chen Zijia Lin Jungong Han Guiguang Ding
Résumé
La détection d’objets et la segmentation sont largement utilisées dans les applications de vision par ordinateur. Toutefois, les modèles classiques tels que la série YOLO, bien qu’efficaces et précis, sont limités par des catégories prédéfinies, ce qui entrave leur adaptabilité dans des scénarios ouverts. Les méthodes récentes pour les scénarios ouverts exploitent des prompts textuels, des indices visuels ou des paradigmes sans prompt afin de surmonter cette contrainte, mais elles compromettent souvent les performances et l’efficacité en raison de contraintes computationnelles élevées ou d’une complexité de déploiement importante. Dans ce travail, nous introduisons YOLOE, un modèle hautement efficace intégrant à la fois la détection et la segmentation dans diverses mécaniques de prompt ouvertes, permettant ainsi une vision en temps réel de tout objet (seeing anything). Pour les prompts textuels, nous proposons une stratégie appelée Alignement Région-Texte Réparamétrisable (RepRTA). Elle affine les embeddings textuels préentraînés grâce à un réseau auxiliaire léger réparamétrisable, tout en améliorant l’alignement visuel-textuel sans surcharge d’inférence ni de transfert. Pour les prompts visuels, nous présentons un encodeur de prompt visuel activé sémantiquement (SAVPE), qui utilise des branches découplées pour la sémantique et l’activation afin d’obtenir des embeddings visuels améliorés et une précision accrue avec une complexité minimale. Dans le cas de scénarios sans prompt, nous introduisons la stratégie de contraste régional à prompt différé (LRPC), qui exploite un vocabulaire intégré de grande taille et des embeddings spécialisés pour identifier tous les objets, évitant ainsi la dépendance coûteuse vis-à-vis des modèles linguistiques. Des expériences étendues montrent que YOLOE atteint des performances exceptionnelles en zéro-shot, une grande transférabilité, une efficacité d’inférence élevée et un coût d’entraînement faible. Notamment, sur LVIS, avec un coût d’entraînement 3 fois inférieur et une accélération de l’inférence de 1,4 fois, YOLOE-v8-S dépasse YOLO-Worldv2-S de 3,5 points d’AP. Lors du transfert vers COCO, YOLOE-v8-L obtient des gains de 0,6 APb et 0,4 APm par rapport à YOLOv8-L en mode fermé, avec presque 4 fois moins de temps d’entraînement. Le code source et les modèles sont disponibles à l’adresse suivante : https://github.com/THU-MIG/yoloe.
One-sentence Summary
The authors from Tsinghua University propose YOLOE, a highly efficient unified model for open-set object detection and segmentation, integrating Re-parameterizable Region-Text Alignment, Semantic-Activated Visual Prompt Encoder, and Lazy Region-Prompt Contrast to enable real-time performance across text, visual, and prompt-free scenarios with minimal overhead, outperforming prior methods in zero-shot accuracy and training efficiency.
Key Contributions
- YOLOE addresses the limitation of closed-set object detection and segmentation models by enabling real-time, unified detection and segmentation across diverse open prompt mechanisms—text, visual, and prompt-free—without sacrificing efficiency or accuracy.
- It introduces three novel components: RepRTA for efficient text prompt alignment via a re-parameterizable lightweight network, SAVPE for low-complexity visual prompt encoding with decoupled semantic and activation branches, and LRPC for prompt-free detection using a built-in large vocabulary and specialized embedding.
- Extensive evaluations show YOLOE achieves state-of-the-art zero-shot performance on LVIS and COCO, surpassing YOLO-Worldv2 and YOLOv8 with up to 3.5 AP gain, 1.4× faster inference, and 4× less training time, while maintaining minimal model overhead.
Introduction
The authors address the growing need for real-time, flexible object detection and segmentation in open-world scenarios where models must respond to diverse prompts—text, visual, or none—without relying on predefined categories. While prior work has made progress in open-vocabulary detection, existing solutions often specialize in one prompt type, leading to inefficiencies: text-prompted methods suffer from high computational costs due to cross-modal fusion, visual-prompted approaches rely on heavy transformers or external encoders, and prompt-free methods depend on large language models, increasing latency and memory usage. The authors introduce YOLOE, a unified, efficient model that supports all three prompt types within a single architecture. They propose three key innovations: a re-parameterizable region-text alignment module that enhances text prompt performance with zero inference overhead, a lightweight semantic-activated visual prompt encoder that generates prompt-aware features with minimal complexity, and a lazy region-prompt contrast strategy that enables prompt-free detection without language models. As a result, YOLOE achieves state-of-the-art performance across all prompt types while significantly reducing training cost and inference latency—outperforming YOLO-Worldv2 and T-Rex2 with up to 3.5 AP gain and 1.4× faster inference on edge devices.
Dataset
- The dataset for YOLOE training combines Objects365, GoldG (which includes GQA and Flickr30k), providing diverse and large-scale image data for object detection and segmentation tasks.
- Objects365 contributes general-purpose object instances, while GoldG enhances visual-linguistic understanding through image-caption pairs from GQA and Flickr30k.
- High-quality segmentation masks are generated using SAM-2.1-Hiera-Large with ground truth bounding boxes as prompts; masks with insufficient area are filtered out to ensure quality.
- Mask smoothing is applied using a 3×3 Gaussian kernel for small masks and a 7×7 kernel for large ones to improve edge continuity.
- Mask refinement follows a method from prior work, iteratively simplifying contours to reduce noise while preserving the overall shape and structure.
- The training pipeline uses AdamW optimizer with an initial learning rate of 0.002, batch size of 128, and weight decay of 0.025.
- Data augmentation includes color jittering, random affine transformations, random horizontal flipping, and mosaic augmentation to improve model robustness.
- During transfer to COCO for linear probing and full tuning, the same optimizer and hyperparameters are used, but with a reduced learning rate of 0.001.
Method
The authors leverage a unified YOLO-based architecture to integrate object detection and segmentation under diverse open prompt mechanisms. As shown in the framework diagram, the model begins with a backbone network that processes the input image, followed by a PAN (Path Aggregation Network) to generate multi-scale feature maps at different levels (P3, P4, P5). These features are then fed into three parallel heads: a regression head for bounding box prediction, a segmentation head for producing prototype and mask coefficients, and an embedding head for generating object embeddings. The embedding head is adapted from the classification head in standard YOLOs, with its final convolution layer's output channel count adjusted to match the embedding dimension instead of the class count in closed-set scenarios.
For text prompts, the model employs a Re-parameterizable Region-Text Alignment (RepRTA) strategy. This involves using a pretrained text encoder to obtain textual embeddings, which are then refined during training by a lightweight auxiliary network. This network, as illustrated in the figure below, consists of a single feed-forward block and is designed to enhance the textual embeddings without introducing significant computational overhead. The refined embeddings serve as classification weights, which are contrasted with the object embeddings from the anchor points to determine category labels. The process is formalized as Label=O⋅PT, where O represents the object embeddings and P represents the prompt embeddings.
For visual prompts, the model introduces a Semantic-Activated Visual Prompt Encoder (SAVPE). This encoder features two decoupled branches: a semantic branch and an activation branch. The semantic branch processes the multi-scale features from the PAN to generate prompt-agnostic semantic features. The activation branch, as shown in the figure below, takes the visual prompt (e.g., a mask) and image features, processes them through convolutions, and outputs prompt-aware weights. These weights are then used to modulate the semantic features, and their aggregation produces the final visual prompt embedding. This design allows for efficient processing of visual cues with minimal complexity.
In the prompt-free scenario, the model utilizes a Lazy Region-Prompt Contrast (LRPC) strategy. This approach reformulates the task as a retrieval problem. A specialized prompt embedding is trained to identify anchor points corresponding to objects. Only these identified points are then matched against a built-in large vocabulary to retrieve category names, bypassing the costly computation for irrelevant points. This lazy retrieval mechanism ensures high efficiency without sacrificing performance. The overall framework is designed to support all three prompt types within a single, highly efficient model, enabling real-time performance across various open-set scenarios.
Experiment
- YOLOE validates superior zero-shot detection and segmentation performance on LVIS, achieving 33.0% AP with YOLOE-v8-L, outperforming YOLOv8-Worldv2 by 3.5–0.4 AP across scales, with 1.2–1.6× faster inference on T4 and iPhone 12.
- YOLOE-v8-M / L achieves 20.8 / 23.5 AP^m in zero-shot segmentation, surpassing fine-tuned YOLO-Worldv2-M / L by 3.0 / 3.7 AP^m, demonstrating strong generalization without LVIS data.
- In prompt-free evaluation, YOLOE-v8-L achieves 27.2 AP and 23.5 AP_r, outperforming GenerateU with Swin-T by 0.4 AP and 3.5 AP_r, while using 6.3× fewer parameters and 53× faster inference.
- YOLOE exhibits strong transferability to COCO: with less than 2% training time, YOLOE-11-M / L reaches over 80% of YOLO11-M / L performance in linear probing, and with 3× less training time, YOLOE-v8-S outperforms YOLOv8-S in both detection and segmentation.
- Ablation studies confirm the effectiveness of SAVPE (1.5 AP gain over mask pooling) and LRPC (1.7× speedup with minimal AP drop), while multi-task learning enables segmentation at the cost of minor detection performance loss.
- Visualizations across zero-shot, text prompt, visual prompt, and prompt-free settings demonstrate YOLOE’s robustness and versatility in diverse real-world scenarios.
The authors use a multi-dataset evaluation to demonstrate YOLOE's capability in both detection and segmentation tasks, showing that it supports both box and mask outputs across different datasets. The results indicate that YOLOE can effectively handle diverse data types, including detection and grounding tasks, with varying image and annotation counts.

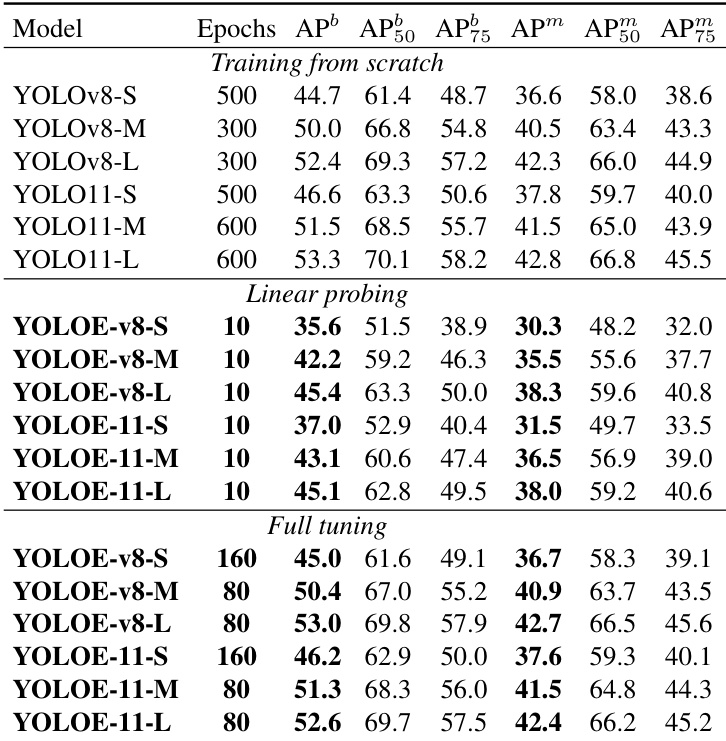
The authors evaluate the effectiveness of SAVPE by varying the number of groups in the activation branch, showing that performance remains stable across different group counts. Specifically, increasing the group number from 1 to 16 leads to a marginal improvement in AP, with the model achieving 31.9 AP at A = 16, indicating a favorable balance between performance and complexity.
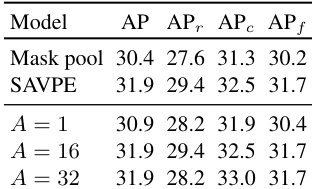
Results show that YOLOE-v8-S achieves 21.0 AP and 95.8 FPS, outperforming GenerateU-Swin-T in AP while using significantly fewer parameters and achieving much higher inference speed. YOLOE-11-L achieves 26.3 AP and 34.9 FPS, demonstrating strong performance with a more efficient backbone compared to YOLOE-v8-L.
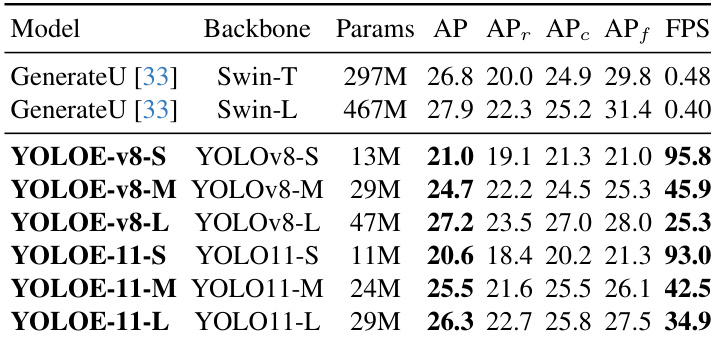
Results show that the inclusion of LRPC significantly improves inference speed without compromising performance, as demonstrated by the 1.7× and 1.3× speedups on T4 and iPhone 12 for YOLOE-v8-S and YOLOE-v8-L, respectively, while maintaining comparable AP and APf values. The effectiveness of LRPC is further confirmed by the substantial reduction in the number of retained anchor points with increasing threshold δ, which lowers computational overhead.
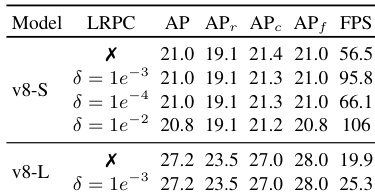
The authors use a table to compare the performance of YOLOE models with YOLOv8 and YOLO11 under different training strategies, including training from scratch, linear probing, and full tuning. Results show that YOLOE achieves competitive or superior performance across all settings, with YOLOE-v8-L and YOLOE-11-L achieving the highest AP and APm values in full tuning, while also demonstrating significant inference speedups compared to YOLOv8 and YOLO11 models.