Command Palette
Search for a command to run...
UniDepthV2 : Une estimation universelle de la profondeur métrique à partir d'une seule image simplifiée
UniDepthV2 : Une estimation universelle de la profondeur métrique à partir d'une seule image simplifiée
Luigi Piccinelli Christos Sakaridis Yung-Hsu Yang Mattia Segu Siyuan Li Wim Abbeloos Luc Van Gool
Résumé
L'estimation précise de la profondeur métrique monoculaire (MMDE) est essentielle pour résoudre des tâches ultérieures en perception et modélisation 3D. Toutefois, la précision remarquable des méthodes récentes de MMDE est limitée à leurs domaines d'entraînement. Ces méthodes échouent à généraliser à des domaines inconnus, même en présence d'écart de domaine modéré, ce qui entrave leur application pratique. Nous proposons un nouveau modèle, UniDepthV2, capable de reconstruire des scènes 3D métriques à partir d'images simples, indépendamment des domaines. À la différence du paradigme existant de MMDE, UniDepthV2 prédit directement des points 3D métriques à partir de l'image d'entrée au moment de l'inférence, sans aucune information supplémentaire, visant ainsi à offrir une solution universelle et flexible pour la MMDE. En particulier, UniDepthV2 intègre un module de caméra auto-promptable qui prédit une représentation dense de la caméra afin de conditionner les caractéristiques de profondeur. Notre modèle exploite une représentation de sortie pseudo-sphérique, qui déconnecte les représentations de la caméra et de la profondeur. En outre, nous proposons une perte d'invariance géométrique, qui favorise l'invariance des caractéristiques de profondeur conditionnées par la caméra. UniDepthV2 améliore son prédécesseur, UniDepth, grâce à une nouvelle perte guidée par les contours, qui améliore la localisation et la netteté des contours dans les sorties de profondeur métrique, à une architecture révisée, simplifiée et plus efficace, ainsi qu'à une sortie supplémentaire de niveau d'incertitude, permettant aux tâches ultérieures nécessitant une estimation de confiance. Des évaluations approfondies sur dix jeux de données de profondeur, dans un cadre zéro-shot, démontrent de manière cohérente les performances supérieures et la capacité de généralisation d'UniDepthV2. Le code et les modèles sont disponibles à l'adresse suivante : https://github.com/lpiccinelli-eth/UniDepth
One-sentence Summary
The authors, affiliated with ETH Zürich, the Max Planck ETH Center for Learning Systems, and Toyota Motor Europe, propose UniDepthV2, a universal monocular metric depth estimation model that directly predicts metric 3D points from a single image without requiring camera parameters at inference. The model introduces a self-promptable camera module and a pseudo-spherical output representation to disentangle camera and depth optimization, enabling robust generalization across diverse domains. A novel edge-guided loss enhances depth sharpness and edge localization, while a geometric invariance loss improves consistency under geometric augmentations. The architecture is simplified and more efficient than its predecessor, achieving state-of-the-art performance in zero-shot settings across ten datasets, with applications in robotics, autonomous driving, and 3D modeling.
Key Contributions
-
UniDepthV2 addresses the critical challenge of generalizable monocular metric depth estimation (MMDE) by enabling universal depth prediction from a single image without relying on external camera parameters or domain-specific training, thus overcoming the poor generalization of prior methods to unseen scenes and camera setups.
-
The model introduces a self-promptable camera module with a pseudo-spherical output representation that disentangles camera and depth dimensions, along with a geometric invariance loss that enforces consistency across different view augmentations, improving robustness and enabling accurate metric 3D reconstruction in diverse environments.
-
UniDepthV2 enhances depth accuracy and edge sharpness through a novel edge-guided loss and introduces a pixel-level uncertainty output, achieving state-of-the-art zero-shot performance across ten diverse datasets while maintaining a simplified, efficient architecture.
Introduction
Monocular metric depth estimation (MMDE) is essential for 3D perception in robotics, autonomous driving, and 3D modeling, but prior methods struggle with generalization across domains due to reliance on specific camera intrinsics and scene scales during training. Existing approaches often fail in real-world, uncontrolled settings where camera parameters and scene geometry vary significantly, and they are further limited by noisy, sparse ground-truth depth data that leads to blurry, inaccurate predictions. The authors introduce UniDepthV2, a universal MMDE framework that predicts metric 3D points from a single image without requiring any external information such as camera parameters. The key innovation lies in a self-promptable camera module that generates a dense, non-parametric camera representation, combined with a pseudo-spherical output space that decouples camera and depth optimization. This design, along with a geometric invariance loss and a novel edge-guided loss, enables sharper depth predictions and robust generalization across diverse domains. UniDepthV2 also introduces a pixel-level uncertainty output for confidence-aware downstream tasks, and achieves state-of-the-art performance in zero-shot evaluations across ten datasets, including the KITTI benchmark.
Dataset
-
The dataset comprises 23 publicly available sources totaling 16 million images, used for training UniDepthV2. These include A2D2, Argoverse2, ARKit-Scenes, BEDLAM, BlendedMVS, DL3DV, DrivingStereo, DynamicReplica, EDEN, HOI4D, HM3D, Matterport3D, Mapillary-PSD, MatrixCity, MegaDepth, Ni-anticMapFree, PointOdyssey, ScanNet, ScanNet++, TartanAir, Taskonomy, Waymo, and WildRGBD.
-
Each dataset contributes based on its number of scenes, with training sampling weighted by scene count. The data undergoes geometric and photometric augmentations: random resizing, cropping, translation, brightness, gamma, saturation, and hue shifts. Image aspect ratios are randomly sampled between 2:1 and 1:2 per batch.
-
The model is trained using a weighted mixture of all 23 datasets, with no test-time augmentations applied during evaluation. The training pipeline uses a ViT backbone initialized from DINO-pretrained weights, trained with AdamW (β₁ = 0.9, β₂ = 0.999), an initial learning rate of 5×10⁻⁵, weight decay of 0.1, and cosine annealing scheduling. Training runs for 300k iterations with a batch size of 128 on 16 NVIDIA 4090 GPUs using half precision, taking approximately 6 days.
-
Three model variants are trained—UniDepthV2-Small, -Base, and -Large—each using a different ViT backbone. Ablation studies use a shorter 100k-step schedule with only the ViT-S backbone, making the ablation final model not directly comparable to the main UniDepthV2-Small results.
-
For evaluation, models are tested in zero-shot settings on ten unseen datasets grouped into three domains: indoor (SUN-RGBD, IBims, TUM-RGBD), outdoor (ETH3D, Sintel, DDAD, NuScenes), and challenging (HAMMER, Booster, FLSea). Models are evaluated using δ₁^SSI (depth accuracy), F_A (F1-AUC up to 1/20 of max depth), and ρ_A (AUC of angular error up to 15°), with no fine-tuning on KITTI or NYU-Depth V2.
-
Confidence predictions are assessed using AUSE and nAUSE (normalized AUSE) to measure uncertainty ranking quality under progressive masking, and Spearman’s ρ to evaluate monotonicity between predicted uncertainty and true error. These metrics are computed without parametric assumptions on camera parameters, ensuring consistency across diverse camera models and unrectified images.
-
The final model is also evaluated after fine-tuning on KITTI and NYU-Depth V2 for in-domain performance, following standard practice.
Method
The authors leverage a modular architecture for UniDepthV2, designed to jointly estimate depth and camera intrinsics from a single monocular image without relying on external calibration information. The framework, illustrated in the diagram below, consists of an encoder backbone, a camera module, and a depth module. The encoder, based on a Vision Transformer (ViT), processes the input image to generate multi-scale feature maps Fi∈Rh×w×C, which are then used by both the camera and depth modules. The camera module, initialized with class tokens from the ViT backbone, processes these tokens through self-attention layers to predict the intrinsic parameters of a pinhole camera, specifically the focal lengths fx,fy and principal points cx,cy. These parameters are used to compute camera rays, which are then normalized to a unit sphere and converted into a dense angular representation C. This representation is further embedded via Sine encoding to produce the camera embeddings E, which serve as a prompt for the depth module. The depth module conditions its processing on these embeddings by applying a cross-attention mechanism between the encoder features Fi and the camera embeddings E, resulting in camera-prompted depth features Fi∣E. These conditioned features are then processed by a Feature Pyramid Network (FPN)-style decoder to produce a log-depth prediction Zlog, which is upsampled to the original image resolution. The final 3D output O is formed by concatenating the predicted camera rays C and the depth values Z, where Z is the element-wise exponentiation of Zlog.
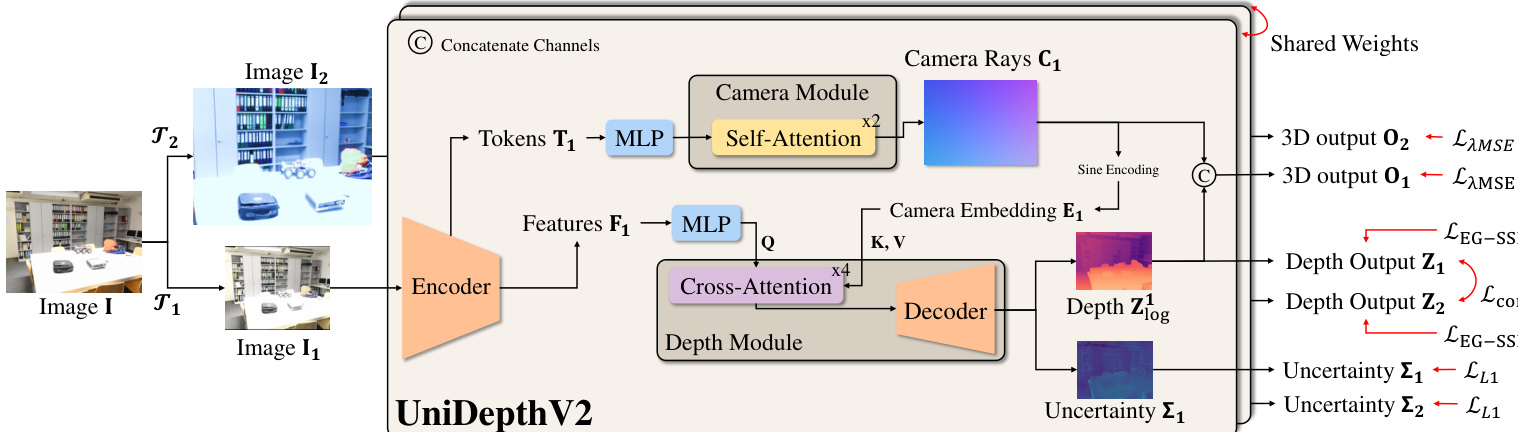
The model's output space is defined by a pseudo-spherical representation (θ,ϕ,zlog), which decouples the camera's angular information (azimuth θ and elevation ϕ) from the depth information (zlog). This design choice, as shown in the framework diagram, ensures that the camera and depth components are orthogonal by design, in contrast to the entangled nature of Cartesian coordinates (x,y,z). The backprojection operation in this space involves concatenating the camera and depth representations, rather than the multiplication of homogeneous rays and depth as in Cartesian space. The camera module's output, a dense tensor C∈RH×W×2, represents the azimuth and elevation for each pixel, which is then embedded to form the conditioning prompt E.
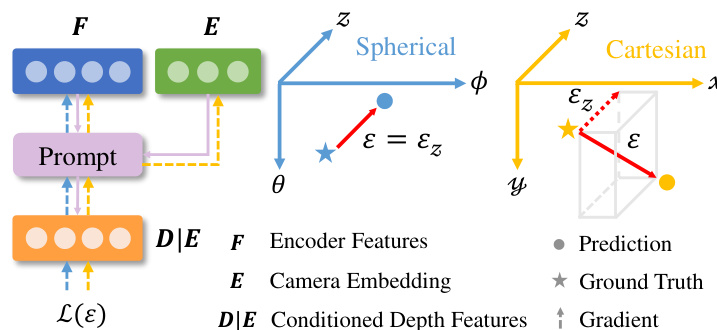
To ensure robust and consistent depth predictions, the authors introduce a geometric invariance loss. This loss enforces that the depth features remain consistent when the input image is geometrically augmented, such as through rescaling and translation, which simulates viewing the same scene from different cameras. The loss is computed on the camera-aware depth outputs Z1 and Z2 from two augmented views, and is formulated as a bidirectional L1 distance between the transformed depth map of one view and the stop-gradient version of the other. This mechanism promotes the model to learn depth predictions that are invariant to the specific camera parameters, thereby enhancing its generalization. Additionally, an edge-guided normalized loss (LEG-SSI) is employed to improve local geometric precision. This loss focuses on high-contrast regions in the image, where depth discontinuities are likely to occur, and applies a local normalization to both the predicted and ground-truth depth maps within these patches. This normalization makes the loss robust to variations in depth scale and shift, ensuring that the model learns to distinguish between genuine geometric edges and spurious texture variations. The overall optimization is guided by a re-formulated Mean Squared Error (MSE) loss in the pseudo-spherical output space, which incorporates scale and shift invariance terms for the depth dimension, and is augmented with the geometric invariance loss, the edge-guided loss, and a loss for uncertainty prediction.
Experiment
- Evaluated on ten zero-shot validation sets across indoor, outdoor, and challenging domains (underwater, transparent objects); UniDepthV2 outperforms or matches all baselines, including methods requiring ground-truth camera parameters, achieving up to 18.1% improvement in F_A over the second-best method.
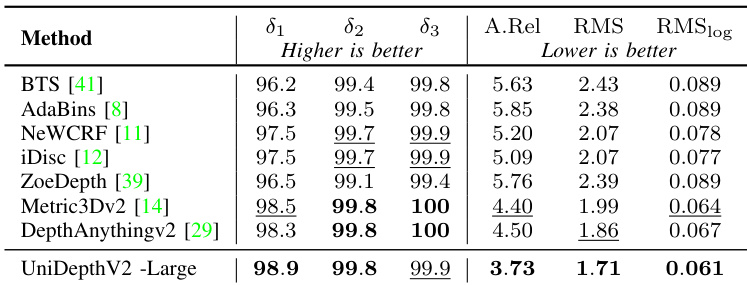
- On NYU and KITTI benchmarks, UniDepthV2 demonstrates strong fine-tuning performance, surpassing models pre-trained on large diverse datasets when adapted to specific domains, particularly in outdoor settings (KITTI).
- Achieves state-of-the-art edge detection F_1 on ETH3D, IBims-1, and Sintel, remaining competitive even under stricter evaluation conditions with fixed high resolution.
- UniDepthV2 is among the fastest models in inference efficiency, being up to 2× faster than baselines at resolutions up to ~2 Megapixels, with comparable memory usage, despite adding a camera prediction module.
- Ablation studies show that architectural changes—removing spherical harmonics encoding and attention, replacing MLP decoder with ResNet blocks, and adding multi-resolution feature fusion—reduce computation by two-thirds while maintaining performance.
- The proposed LEG−SSI loss improves δ1 by 4.7% and F_A by 1.8%, enhancing depth accuracy and 3D estimation, with indirect benefits to camera parameter estimation.
- Camera conditioning applied at multiple decoder scales improves performance more than single-point conditioning, and applying the geometry consistency loss in the output space is sufficient and simpler.
- The pseudo-spherical output representation in UniDepthV2 improves depth, 3D, and camera accuracy compared to Cartesian regression.
- Uncertainty estimation is well-calibrated in-domain (nAUSE: 0.199–0.221, ρ: 0.68–0.74), though degrades under zero-shot conditions (nAUSE: 0.54–0.65, ρ: 0.29), indicating informative but less reliable predictions in novel domains.
- Failure cases include non-pinhole cameras, mirrors, optical illusions, and distorted paintings; UniDepthV2 fails to rectify non-pinhole distortions due to its pinhole-based camera representation and struggles with ambiguous mirror interpretations.
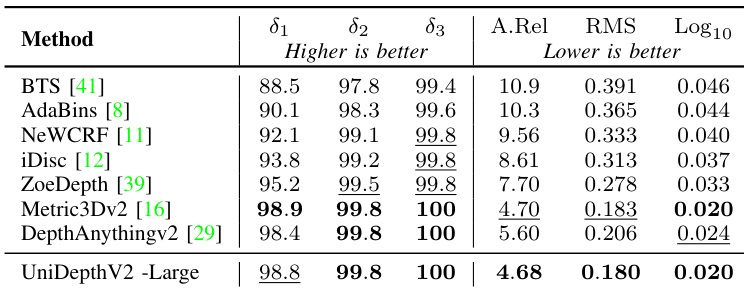
Results show that UniDepthV2 -Large achieves the highest performance across all metrics compared to other methods, with the best scores in δ₁, δ₂, δ₃, and A.Rel, while also delivering the lowest RMS and RMSlog errors. The model outperforms all baselines, including those requiring ground-truth camera parameters, demonstrating its effectiveness in zero-shot depth estimation.
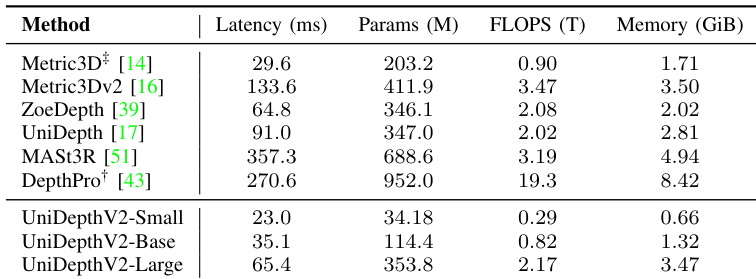
The authors compare the inference efficiency of UniDepthV2 variants with several state-of-the-art methods, showing that UniDepthV2-Small achieves the lowest latency and memory usage while maintaining a competitive parameter count and FLOPS. UniDepthV2-Large, despite higher computational requirements, remains efficient and outperforms most baselines in terms of speed and memory footprint.
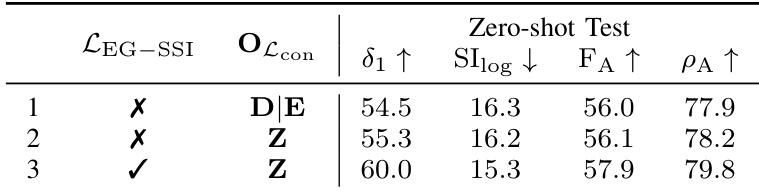
Results show that adding the LEG−SSI loss and applying the consistency loss in the output space (Z) significantly improves depth accuracy and 3D estimation, with the best performance achieved when both components are used. The combination leads to a 5.5% increase in δ1 and a 1.9% improvement in FA compared to the baseline.
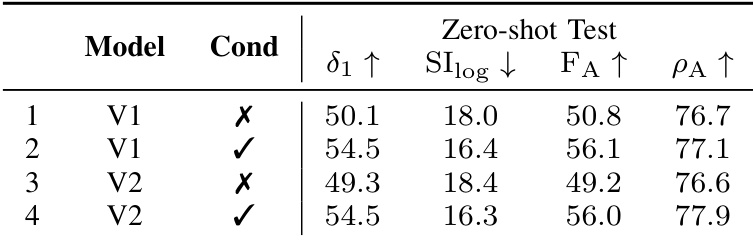
The authors use a controlled ablation study to evaluate the impact of camera conditioning and model version on depth estimation performance. Results show that adding camera conditioning significantly improves all metrics, with the best performance achieved by UniDepthV2 with conditioning, which attains the highest values in δ₁, F_A, and ρ_A.
Results show that UniDepthV2 -Large achieves the best performance across all metrics, outperforming or matching all baselines on the zero-shot validation set. It achieves the highest scores in δ₁, δ₂, δ₃, and Log10, while also setting the lowest values for A.Rel, RMS, and Log10, indicating superior depth accuracy and scale-invariant performance.